Flink部署之Yarn
Posted Joker_Jiang3
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink部署之Yarn相关的知识,希望对你有一定的参考价值。
Flink部署之Yarn
一、环境准备
1、Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。 需要准备 3 台 Linux 机器。具体要求如下:
- 系统环境为 CentOS 7.5 版本。
- 安装 Java 8。
- 安装 Hadoop 集群,Hadoop 建议选择 Hadoop 2.7.5 以上版本。
- 配置集群节点服务器间时间同步以及免密登录,关闭防火墙。 三台服务器的具体设置如下:
- 节点服务器 1,IP 地址为 192.168.88.102,主机名为 hadoop102。
- 节点服务器 2,IP 地址为 192.168.88.103,主机名为 hadoop103。
- 节点服务器 3,IP 地址为 192.168.88.104,主机名为 hadoop104。
2、进入 Flink 官网,下载 1.13.0 版本安装包 flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对 应 scala 版本为 scala 2.12 的安装包。
3、在 hadoop102 节点服务器上创建安装目录/opt/module,将 flink 安装包放在该目录下,并 执行解压命令,解压至当前目录。
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
4、进入解压后的目录,执行启动命令,就可以直接本地启动flink服务。
$ cd flink-1.13.0/
$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
$ jps
10369 StandaloneSessionClusterEntrypoint
10680 TaskManagerRunner
10717 Jps
5、 启动成功后,访问 http://hadoop102:8081,可以对 flink 集群和任务进行监控管理 。如果物理机没有配置IP地址映射,就用IP访问http://192.168.88.102:8081。
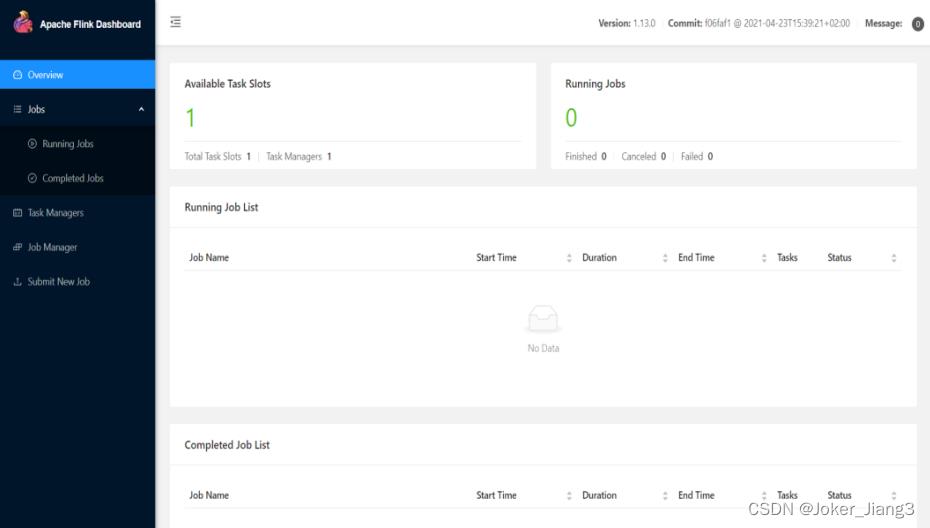
二、 集群启动
Flink 本地启动非常简单,直接执行 start-cluster.sh 就可以了。如果我们想要扩 展成集群,其实启动命令是不变的,主要是需要指定节点之间的主从关系。 Flink 是典型的 Master-Slave 架构的分布式数据处理框架,其中 Master 角色对应着 JobManager,Slave 角色则对应 TaskManager。
我们对三台节点服务器的角色分配如 下:
| 节点服务器 | Hadoop102 | Hadoop103 | Hadoop104 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
1、修改集群配置
进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为 hadoop102
这就指定了 hadoop102 节点服务器为 JobManager 节点。
$ cd conf/
$ vim flink-conf.yaml
# JobManager 节点地址.
jobmanager.rpc.address: hadoop102
修改 flink-conf.yaml 文件
$ cd /opt/module/flink-1.13.0-yarn/conf/
$ vim flink-conf.yaml
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 1
增加环境变量配置如下 :
$ sudo vim /etc/profile
HADOOP_HOME=/opt/module/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点, 具体修改如下:
$ vim workers
hadoop103
hadoop104
这样就指定了 hadoop103 和 hadoop104 为 TaskManager 节点。
2、 分发安装目录
$ scp -r ./flink-1.13.0 atguigu@hadoop103:/opt/module
$ scp -r ./flink-1.13.0 atguigu@hadoop104:/opt/module
3、 启动集群
在启动flink集群前要先启动HDFS和Yarn。
YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署 JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业 所需要的 Slot 数量动态分配 TaskManager 资源。
在 可以在任一节点服务器上执行 bin/yarn-session.sh -nm test 启动 Flink 集群
如果报以下错误,添加yarn-site.xml配置
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
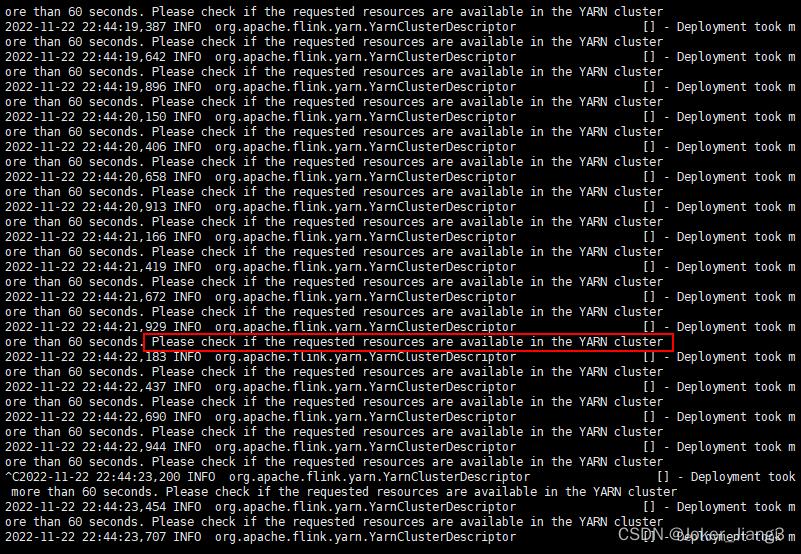
成功启动如下:
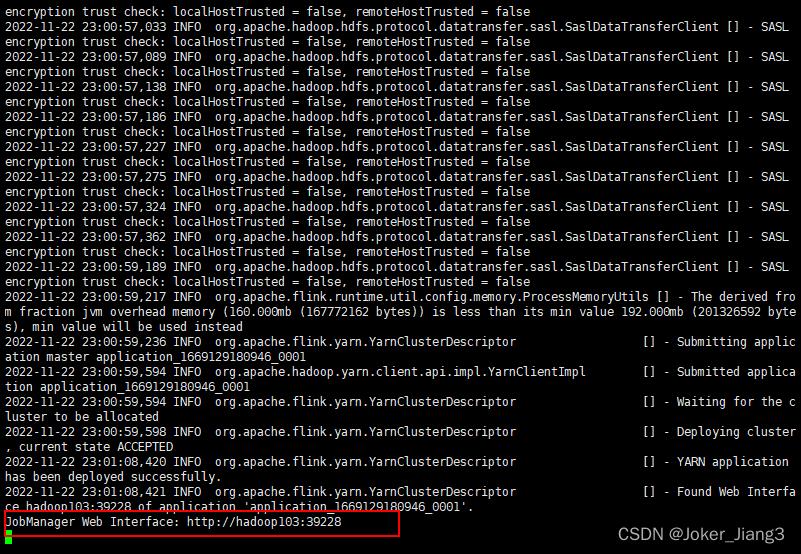
通过上图的链接可以进行Web UI访问, YARN 会按照需求动态分配 TaskManager 和 slot,所以开始时是0TaskManager。
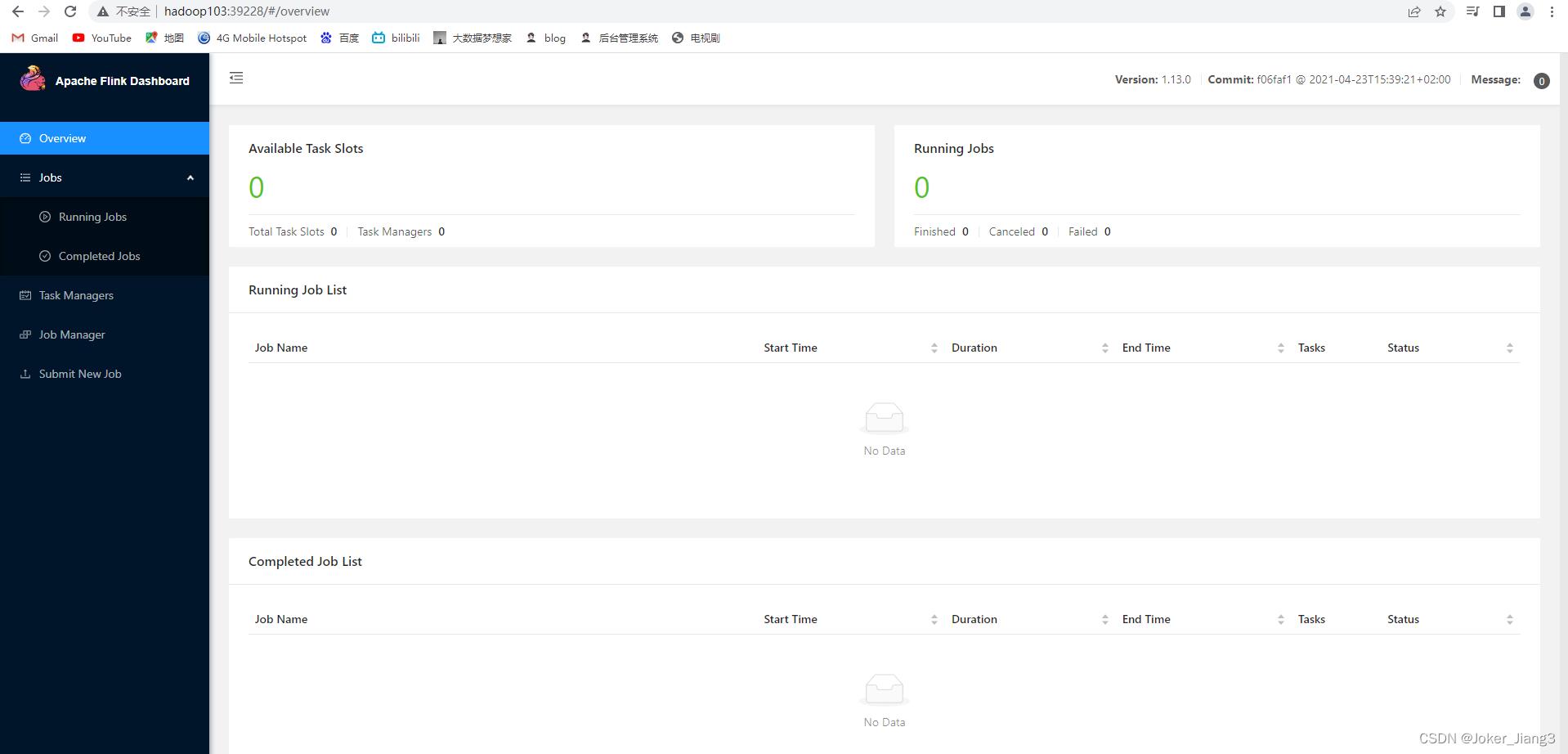
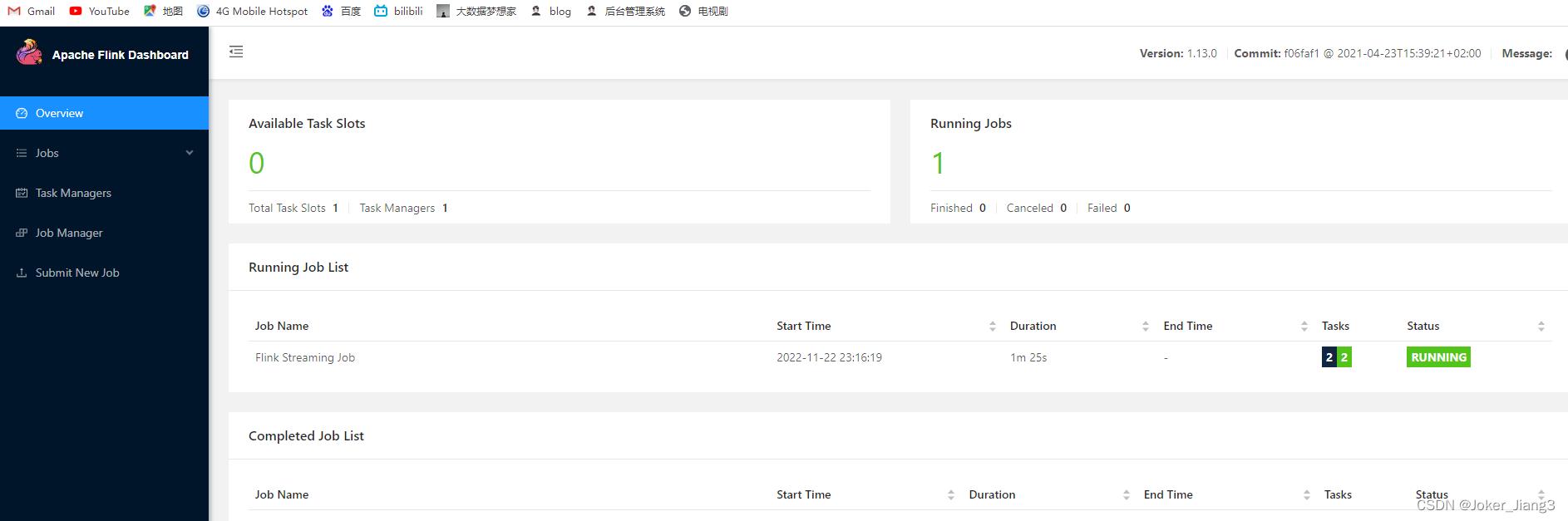
运行一个WordCount任务
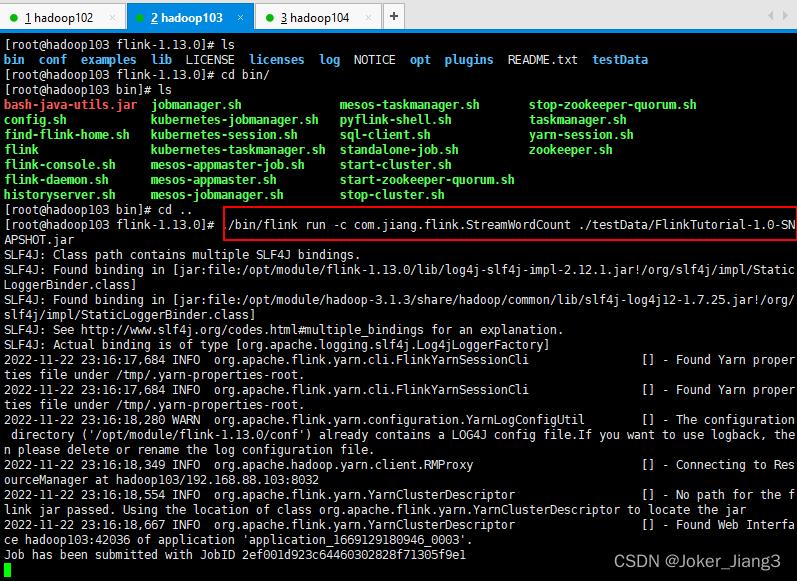
任务运行后Yarn会动态分配一个资源
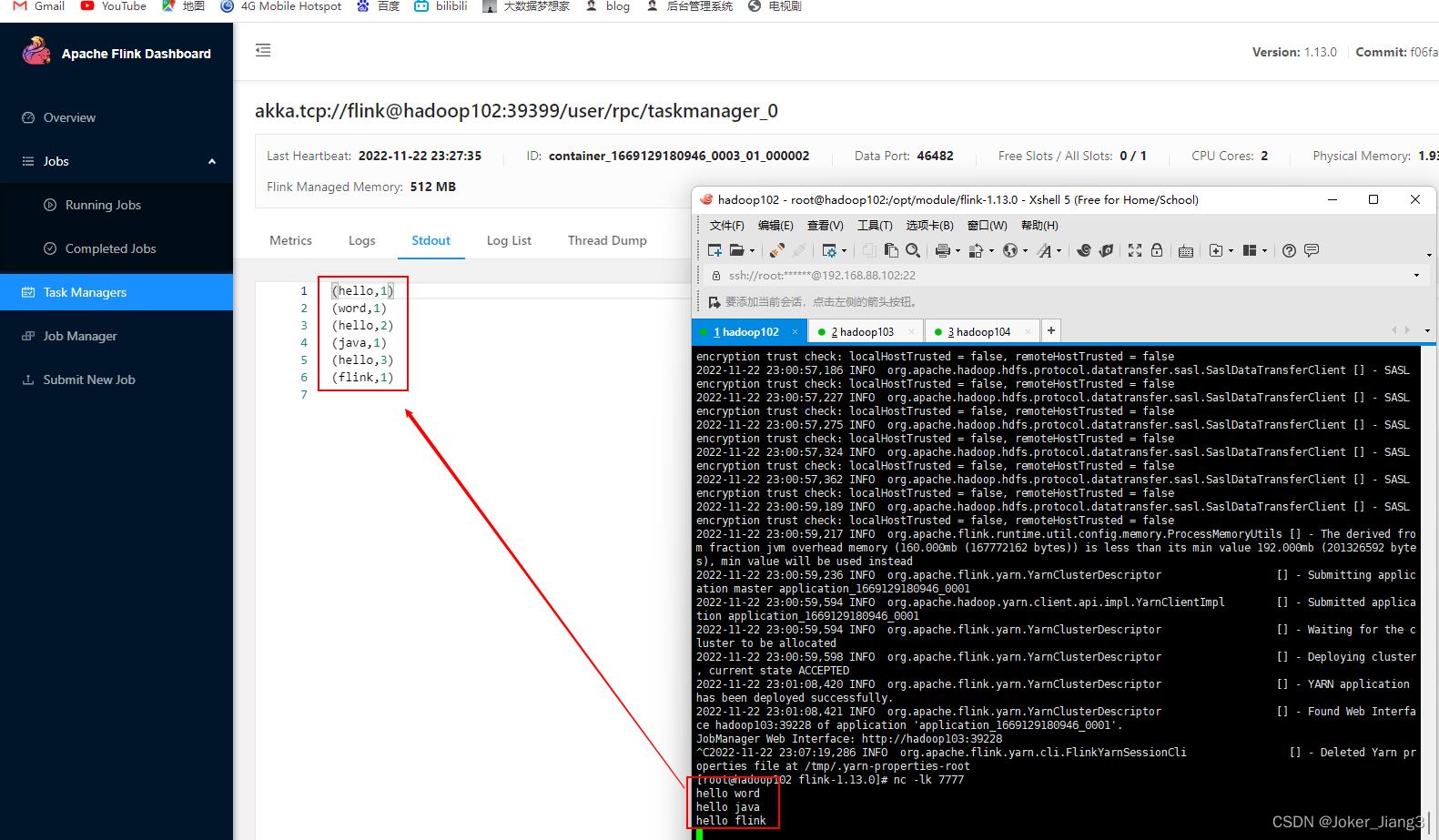
进行wordcount测试
以上是关于Flink部署之Yarn的主要内容,如果未能解决你的问题,请参考以下文章