Flink Yarn Session模式安装部署指南
Posted xingoo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink Yarn Session模式安装部署指南相关的知识,希望对你有一定的参考价值。
最近升级Flink到1.10.1时发现又忘记怎么部署了,赶紧整理下完整流程。本篇会从下载开始(以Flink1.10.1为例),教你怎么部署Flink集群,并包含hive的集成、Kafka、HBase、mysql的对接。在部署前需要你有一套完整的Hadoop环境,包含hdfs、yarn、hive等。
1 下载相关资源
首先去官网下载二进制包:
https://flink.apache.org/downloads.html
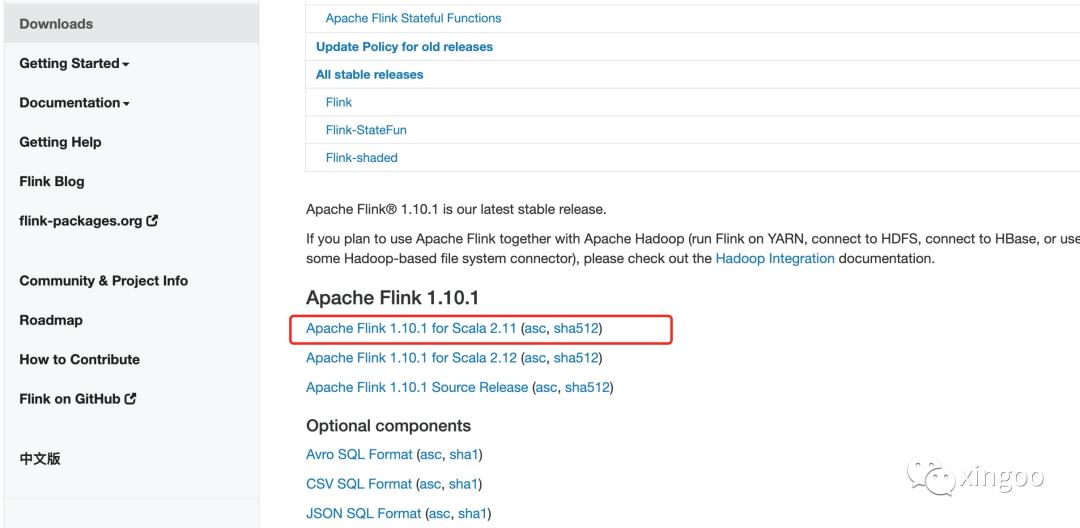
完成后上传部署Hadoop环境的集群上,配置两个环境变量:FLINK_HOME即解压后的文件目录,HADOOP_CONF_DIR为hadoop相关的配置文件目录。
如果想要集成Hive,需要下载hadoop-shaded包,如果不想集成可以直接忽略。如果你的Hive是标准版本,那么可以直接在刚才的下载列表中查找需要的版本,如果是特殊的版本如cdh之类的,可以自行下载代码编译(下面的连接就在上面的download页面)。

关于flink与hive的版本可以参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/hive/
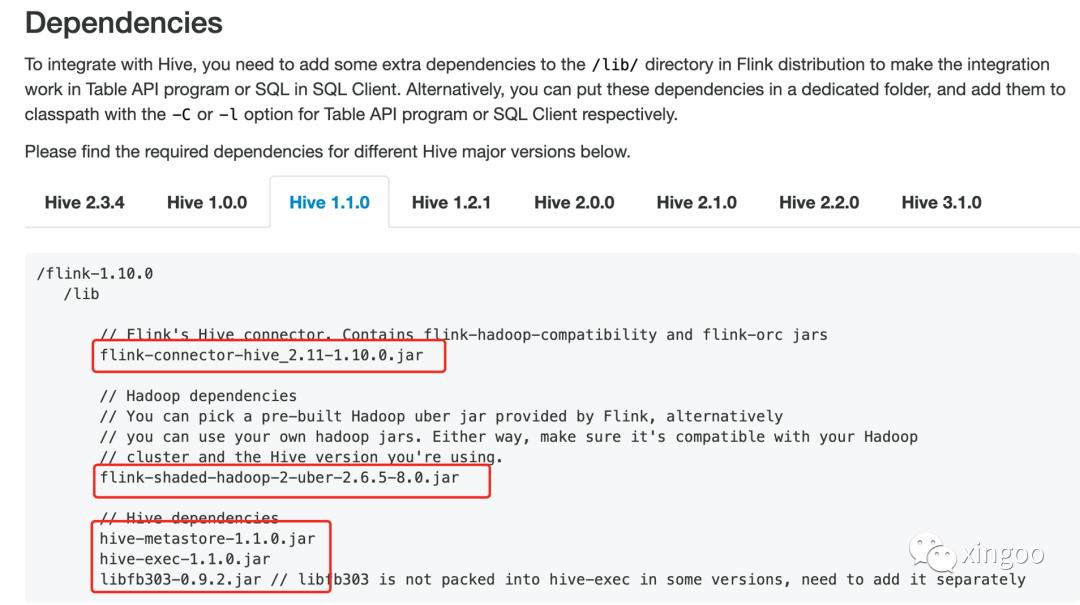
我的版本是cdh-1.1.0-5.7.2就需要自己下载代码自行编译,下载代码后进入根目录:
mvn clean install -Dhadoop.version=2.6.0-cdh5.7.2
执行上面的编译命令,把编译出来的jar包拷贝到lib下就行了。
其他的jar包则可以通过maven仓库下载:
https://mvnrepository.com/
准备好相关的jar包之后,就可以配置启动了。附一张我这边的完成图:
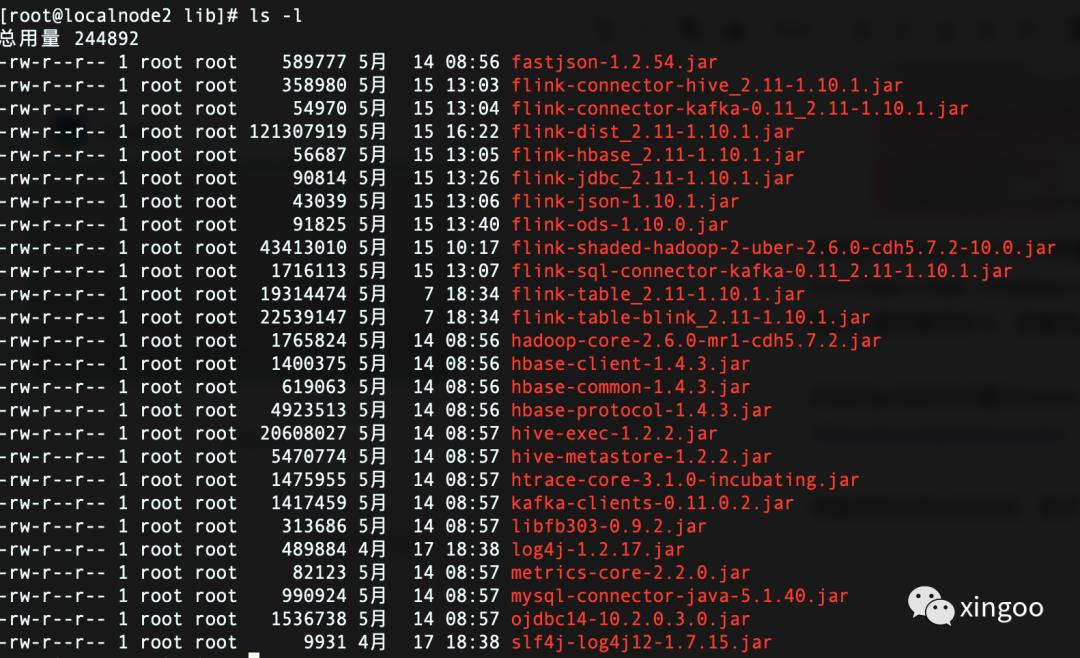
除了dist、table、table-blink、slf4j、log4j其他的都需要自己下载拷贝进来。
2 配置关键属性
启动flink之前确保两个环境变量的配置:FLINK_HOME和HADOOP_CONF_DIR。其他的配置可以参考:
1 配置默认的并行度:parallelism.default: 5 (之后flink如果使用sql之类的操作,无论是join还是sink,默认的并行度都是5,这样避免在session模式中资源占用过多)
2 配置执行模式:execution.target: yarn-session (session模式必须的参数)
3 修改yarn配置文件:yarn.properties-file.location: /var/flink/yarn (这个配置一定要加上,不然默认yarn app文件会写入/tmp中,如果/tmp目录定时被清理掉,session模式就无法工作了)
4 开启hive自动推断:table.exec.hive.infer-source-parallelism: true (如果开启这个参数,读取hive中的数据时会根据底层文件做并行度推断,当然还会跟下面的参数比较,选择最小值作为并行度)
5 配置最大的hive并行度:table.exec.hive.infer-source-parallelism.max: 5(这个参数一般搭配上面的参数共同使用)
其他的配置可以都暂时忽略,有需要再调整。
3 启动集群
接下来基于下面的命令启动即可:
bin/yarn-session.sh -jm 1024 -tm 1024 -s 1 -nm flink-1.10 -d
解释下其中的参数:
Usage:
Optional
-D <arg> Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-nm,--name Set a custom name for the application on YARN
-at,--applicationType Set a custom application type on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for HA mode-d为后台启动,启动后脚本自动结束;-jm配置jobmanager的内存;-tm配置taskmanager的内存;-s配置taskmanager上的slot数量;-nm配置appmaster进程的名字。提交后,在yarn的控制台就可以看到对应的master进程了:
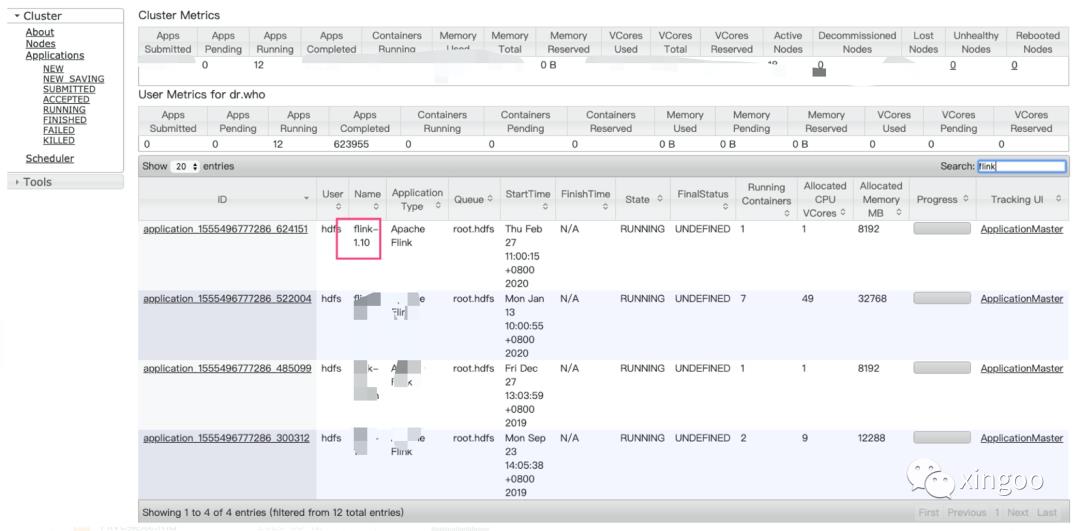
点击对应的master url就可以直接进入flink ui:
4 Flink Yarn Session的使用
启动后可以直接使用flink run运行
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar5 Yarn Session的工作模式
Session模式具体的工作流程为:
1 客户端使用yarn-session命令把相关的资源和配置上传到hdfs
2 根据配置文件向yarn申请资源创建AppMaster
3 Yarn根据申请的配置拉起容器
4 当用户使用Flink run命令执行程序时,程序会被编译成jobgraph,提交到AppMaster
5 AppMaster接收到命令,基于Dispatcher拉起JobManagerRunner,并根据JobGraph创建执行图,申请Slot相关资源
6 Slot资源通过 AppMaster 内部的 ResourceManager 跟Yarn进行通信,申请 TM
7 TM与JobManager内部的SlotPool通信,协调task的分发执行
8 程序执行结束后,对应的slot回收,释放taskmanager。
以上是关于Flink Yarn Session模式安装部署指南的主要内容,如果未能解决你的问题,请参考以下文章