LevelDB 源码剖析SSTable模块:SSTableBlock布隆过滤器LRU Cache
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LevelDB 源码剖析SSTable模块:SSTableBlock布隆过滤器LRU Cache相关的知识,希望对你有一定的参考价值。
文章目录
SSTable(Sorted Strings Table,有序字符串表),在各种存储引擎中得到了广泛的使用,包括 LevelDB、HBase、Cassandra 等。SSTable 会根据 Key 进行排序后保存一系列的 K-V 对,这种方式不仅方便进行范围查找,而且便于对 K-V 对进行更加有效的压缩。
SSTable Format
SSTable 文件由一个个块组成,块中可以保存数据、数据索引、元数据或者元数据索引。整体的文件格式如下图:
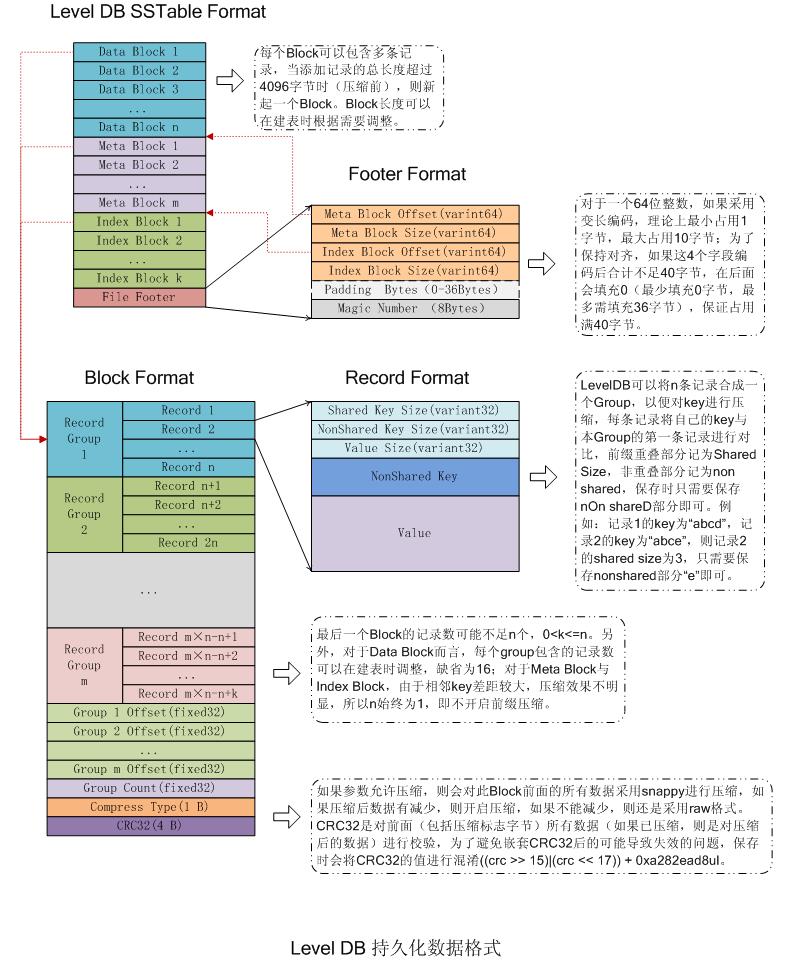
如上图,SSTable 文件整体分为 4 个部分:
-
Data Block(数据区域):保存具体的键-值对数据。
-
Meta Block(元数据区域):保存元数据,例如布隆过滤器。
-
Index Block(索引区域):分为数据索引和元数据索引。
- 数据索引:数据索引块中的键为前一个数据块的最后一个键(即一个数据块中最大的键,因为键是有序排列保存的)与后一个数据块的第一个键(即一个数据块中的最小键)的最短分隔符。
- 元数据索引:元数据索引块可指示如何查找该布隆过滤器的数据。
-
File Footer(尾部):总大小为48个字节。
BlockHandle
BlockHandle在SSTable中是经常使用的一个结构,其定义如下:
// https://github.com/google/leveldb/blob/master/table/format.h
class BlockHandle
public:
// Maximum encoding length of a BlockHandle
enum kMaxEncodedLength = 10 + 10 ;
BlockHandle();
// The offset of the block in the file.
uint64_t offset() const return offset_;
void set_offset(uint64_t offset) offset_ = offset;
// The size of the stored block
uint64_t size() const return size_;
void set_size(uint64_t size) size_ = size;
void EncodeTo(std::string* dst) const;
Status DecodeFrom(Slice* input);
private:
uint64_t offset_;
uint64_t size_;
;
BlockHandler 本质就是封装了 offset 和 size,用于定位某些区域。
Block Format
SSTable 中一个块默认大小为 4 KB,由 4 部分组成:
-
键-值对数据:即我们保存到 LevelDB 中的多组键-值对。
-
重启点数据:最后 4 字节为重启点的个数,前边部分为多个重启点,每个重启点实际保存的是偏移量。并且每个重启点固定占据 4 字节的空间。
-
压缩类型:在 LevelDB 的 SSTable 中有两种压缩类型:
- kNoCompression:没有压缩。
- kSnappyCompression:Snappy压缩。
-
校验数据:4 字节的 CRC 校验字段。
Block读写流程
生成Block
块生成主要在 BlockBuilder 中实现,下面先看看它的结构:
// https://github.com/google/leveldb/blob/master/table/block_builder.h
class BlockBuilder
public:
explicit BlockBuilder(const Options* options);
BlockBuilder(const BlockBuilder&) = delete;
BlockBuilder& operator=(const BlockBuilder&) = delete;
void Reset();
void Add(const Slice& key, const Slice& value);
Slice Finish();
size_t CurrentSizeEstimate() const;
bool empty() const return buffer_.empty();
private:
const Options* options_;
std::string buffer_; // Destination buffer
std::vector<uint32_t> restarts_; // Restart points
int counter_; // Number of entries emitted since restart
bool finished_; // Has Finish() been called?
std::string last_key_;
;
- 成员变量
- options_:在 BlockBuilder 类构造函数中传入,表示一些配置选项。
- buffer_:块的内容,所有的键-值对都保存到 buffer_ 中。
- restarts_:每次开启新的重启点后,会将当前 buffer_ 的数据长度保存到 restarts_ 中,当前 buffer_ 中的数据长度即为每个重启点的偏移量。
- counter_:开启新的重启点之后加入的键-值对数量,默认保存 16 个键-值对,之后会开启一个新的重启点。
- finished_:指明是否已经调用了
Finish方法,BlockBuilder 中的Add方法会将数据保存到各个成员变量中,而Finish方法会依据成员变量的值生成一个块。 - last_key_:上一个保存的键,当加入新键时,用来计算和上一个键的共同前缀部分。
介绍完了结构,下面来看具体的生成方法。当需要保存一个键-值对时,需要调用 BlockBuilder 类中的 Add 方法:
// https://github.com/google/leveldb/blob/master/table/block_builder.cc
void BlockBuilder::Add(const Slice& key, const Slice& value)
//保存上一个加入的key
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() // No values yet?
|| options_->comparator->Compare(key, last_key_piece) > 0);
size_t shared = 0;
//判断counter_是否大于block_restart_interval
if (counter_ < options_->block_restart_interval)
const size_t min_length = std::min(last_key_piece.size(), key.size());
//计算相同前缀的长度
while ((shared < min_length) && (last_key_piece[shared] == key[shared]))
shared++;
else
//如果键-值对数量超过block_restart_interval,则开启新的重启点,清空计数器
restarts_.push_back(buffer_.size());
counter_ = 0;
const size_t non_shared = key.size() - shared;
//将共同前缀长度、非共享部分长度、值长度追加到buffer_中
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
//将key的非共享数据追加到buffer_中_
buffer_.append(key.data() + shared, non_shared);
//将Value数据追加到buffer_中
buffer_.append(value.data(), value.size());
//更新状态
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
执行流程如下:
- 判断 counter_ 是否大于 block_restart_interval,如果大于,则开启新的重启点,清空计数器并保存 buffer_ 中数据长度的值(该值即每个重启点的偏移量)压到 restarts_ 数组中。
- 如果 counter_ 未超出配置的每个重启点可以保存的键-值对数值,则计算当前键和上一次保存键的共同前缀,然后将键-值对按格式保存到 buffer_ 中。
- 更新状态,将 last_key_ 置为当前保存的 key,并且将 counter_ 加 1。
从上面的代码中可以看出,Add 中将所有的键-值对按格式保存到成员变量 buffer_ 中。实际生成 Block 的其实是 Finish 。代码如下:
// https://github.com/google/leveldb/blob/master/table/block_builder.cc
Slice BlockBuilder::Finish()
//将重启点偏移量写入buffer_中
for (size_t i = 0; i < restarts_.size(); i++)
PutFixed32(&buffer_, restarts_[i]);
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
Finish 首先将所有重启点偏移量的值依次以 4 字节大小追加到 buffer_ 字符串,最后将重启点个数继续以 4 字节大小追加到 buffer_ 后部,此时返回的结果就是一个完整的 Block。
读取Block
读取 Block 由 Block 类实现,其主要依靠 NewIterator 生成一个 Block 迭代器,再借助迭代器的 Seek 来查找对应的 Key。首先来看看 Block 的结构:
// https://github.com/google/leveldb/blob/master/table/block.h
class Block
public:
// Initialize the block with the specified contents.
explicit Block(const BlockContents& contents);
Block(const Block&) = delete;
Block& operator=(const Block&) = delete;
~Block();
size_t size() const return size_;
Iterator* NewIterator(const Comparator* comparator);
private:
class Iter;
uint32_t NumRestarts() const;
const char* data_;
size_t size_;
uint32_t restart_offset_; // Offset in data_ of restart array
bool owned_; // Block owns data_[]
;
读取一个块通过在 NewIterator 中生成一个迭代器来实现,代码如下:
// https://github.com/google/leveldb/blob/master/table/block.cc
Iterator* Block::NewIterator(const Comparator* comparator)
if (size_ < sizeof(uint32_t))
return NewErrorIterator(Status::Corruption("bad block contents"));
const uint32_t num_restarts = NumRestarts();
if (num_restarts == 0)
return NewEmptyIterator();
else
return new Iter(comparator, data_, restart_offset_, num_restarts);
这里的逻辑比较简单,就不多作介绍了。
核心的查找逻辑主要是迭代器中的 Seek 下面直接看代码:
// https://github.com/google/leveldb/blob/master/table/block.cc
void Seek(const Slice& target) override
uint32_t left = 0;
uint32_t right = num_restarts_ - 1;
int current_key_compare = 0;
if (Valid())
current_key_compare = Compare(key_, target);
if (current_key_compare < 0)
left = restart_index_;
else if (current_key_compare > 0)
right = restart_index_;
else
return;
//通过重启点进行二分查找
while (left < right)
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr =
DecodeEntry(data_ + region_offset, data_ + restarts_, &shared,
&non_shared, &value_length);
if (key_ptr == nullptr || (shared != 0))
CorruptionError();
return;
Slice mid_key(key_ptr, non_shared);
//如果key小于target,则将left置为mid
if (Compare(mid_key, target) < 0)
left = mid;
//如果key大于等于target,则将right置为mid-1
else
right = mid - 1;
assert(current_key_compare == 0 || Valid());
//在块中线性查找,依次遍历每一个K-V对,将key与target对比,直到找到第一个大于等于target的后返
bool skip_seek = left == restart_index_ && current_key_compare < 0;
if (!skip_seek)
SeekToRestartPoint(left);
while (true)
if (!ParseNextKey())
return;
if (Compare(key_, target) >= 0)
return;
查找逻辑如下:
- 对重启点数组进行二分查找,找到可能包含数据的重启点。
- 在块中线性查找,依次遍历每一个 K-V 对,将 key 与 target 对比。
- 找到第一个 key 大于等于 target 的后将该 K-V 对存储后返回。
SSTable读写流程
生成SSTable
SSTable 的生成主要在 TableBuilder 中实现,下面先看看它的结构:
// https://github.com/google/leveldb/blob/master/include/leveldb/table_builder.h
class LEVELDB_EXPORT TableBuilder
public:
TableBuilder(const Options& options, WritableFile* file);
TableBuilder(const TableBuilder&) = delete;
TableBuilder& operator=(const TableBuilder&) = delete;
~TableBuilder();
Status ChangeOptions(const Options& options);
void Add(const Slice& key, const Slice& value);
void Flush();
Status status() const;
Status Finish();
void Abandon();
uint64_t NumEntries() const;
uint64_t FileSize() const;
private:
bool ok() const return status().ok();
void WriteBlock(BlockBuilder* block, BlockHandle* handle);
void WriteRawBlock(const Slice& data, CompressionType, BlockHandle* handle);
struct Rep;
Rep* rep_;
;
在介绍该 TableBuilder 的核心逻辑之前,首先我们要看看里面的一个结构体 Rep。其结构如下:
struct TableBuilder::Rep
Rep(const Options& opt, WritableFile* f)
: options(opt),
index_block_options(opt),
file(f),
offset(0),
data_block(&options),
index_block(&index_block_options),
num_entries(0),
closed(false),
filter_block(opt.filter_policy == nullptr
? nullptr
: new FilterBlockBuilder(opt.filter_policy)),
pending_index_entry(false)
index_block_options.block_restart_interval = 1;
Options options;
Options index_block_options;
WritableFile* file;
uint64_t offset;
Status status;
BlockBuilder data_block;
BlockBuilder index_block;
std::string last_key;
int64_t num_entries;
bool closed; // Either Finish() or Abandon() has been called.
FilterBlockBuilder* filter_block;
bool pending_index_entry;
BlockHandle pending_handle; // Handle to add to index block
std::string compressed_output;
;
我们需要注意的关键变量如下:
- file:SSTable 生成的文件。
- data_block:用于生成 SSTable 的数据区域。
- index_block:用于生成 SSTable 的索引区域。
- pending_index_entry:决定是否需要写数据索引。
- pending_handle: 写数据索引的方法。SSTable中每次完整写入一个块后需要生成该块的索引,索引中的键是当前块最大键与即将插入的键的最短分隔符,例如一个块中最大键为 abceg,即将插入的键为 abcqddh,则二者之间的最小分隔符为 abcf。
了解完结构后,接着就看看生成 SSTable 的核心函数 Add 和 Finish。
首先来看 Add,其代码如下:
// https://github.com/google/leveldb/blob/master/table/table_builder.cc
void TableBuilder::Add(const Slice& key, const Slice& value)
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0)
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
//判断是否需要写入数据索引块中
if (r->pending_index_entry)
assert(r->data_block.empty());
//找到最短分隔符,即大于等于上一个块最大的键,小于下一个块最小的键
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
//在数据索引块中写入key和BlockHandle
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
//写入元数据块中
if (r->filter_block != nullptr)
r->filter_block->AddKey(key);
//修改last_key为当前要插入的key
r->last_key.assign(key.data(), key.size());
r->num_entries++;
//写入数据块中
r->data_block.Add(key, value);
//判断数据块大小是否大于配置的块大小,如果大于则调用Flush写入SSTable文件并刷新到硬盘
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size)
Flush();
Add 主要就是调用生成数据块与数据索引块的方法 BlockBuilder::Add 以及生成元数据块的方法 FilterBlockBuilder::Add 依次将键值对加入数据索引块、元数据块以及数据块。
可以看到,最后会判断数据块大小是否大于配置的块大小,如果大于则调用 Flush 写入 SSTable 文件并刷新到硬盘中。我们接着来看看 Flush 的执行逻辑:
// https://github.com/google/leveldb/blob/master/table/table_builder.cc
void TableBuilder::Flush()
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return;
assert(!r->pending_index_entry);
//写入数据块以上是关于LevelDB 源码剖析SSTable模块:SSTableBlock布隆过滤器LRU Cache的主要内容,如果未能解决你的问题,请参考以下文章
LevelDB 源码剖析SSTable模块:SSTableBlock布隆过滤器LRU Cache
LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption
LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption
LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption