LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption相关的知识,希望对你有一定的参考价值。
文章目录
源码结构
LevelDB 的源码托管在 GitHub 上:LevelDB,其中与程序实现源码相关的主要有以下几项:
- db:包含数据库的一些基本接口操作与内部实现。
- table:为排序的字符串表 SSTable(Sorted String Table)的主体实现。
- helpers:定义了 LevelDB 底层数据部分完全运行于内存环境的实现方法,主要用于相关的测试或某些全内存的运行场景。
- util:包含一些通用的基础类函数,如内存管理、布隆过滤器、编码、CRC 等相关函数。
- include:包含 LevelDB 库函数、可供外部访问的接口、基本数据结构等。
- port:定义了一个通用的底层文件,以及多个进程操作接口,还有基于操作系统移植性实现的各平台的具体接口。
具体的环境搭建流程在前面的实战章节就讲过,这里就不过多介绍了。
整体架构
LevelDB 总体模块架构主要包括接口 API(DB API 与 POSIX API)、Utility 公用基础类、LSM 树(Log、MemTable、SSTable)3个部分,如下图:
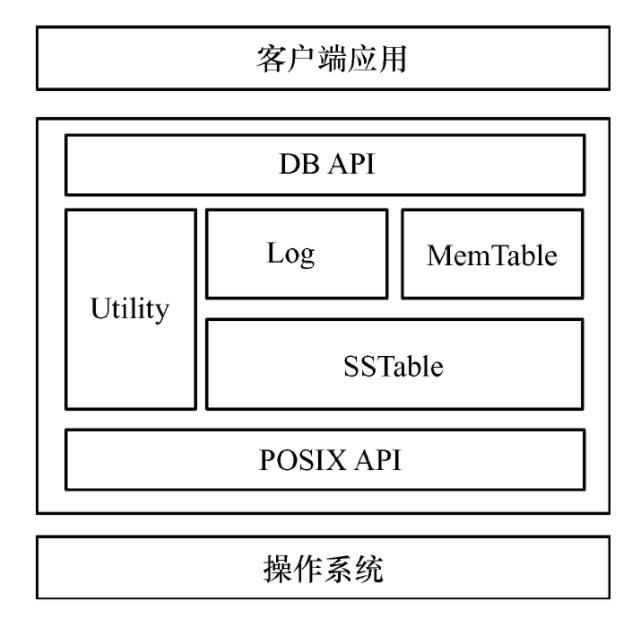
- 接口 API:接口 API 主要包括客户端调用的 DB API 以及针对操作系统底层的统一接口 POSIX API:
- DB API:主要用于封装一些供客户端应用进行调用的接口,即头文件中的相关 API 函数接口,客户端应用可以通过这些接口实现数据引擎的各种操作。
- POSIX API:实现了对操作系统底层相关操作的接口封装,主要用于保证 LevelDB 的可移植性,从而实现 LevelDB 在各 POSIX 操作系统的跨平台特性
- Utility 公用基础类:主要用于实现主体功能所依赖的各种对象功能,例如内存管理 Arena、布隆过滤器、缓存、CRC 校验、哈希表、测试框架等。
- LSM 树:LSM 树是 LevelDB 最重要的组件,也是实现其他功能的核心。一般而言,在常规的物理硬盘存储介质上,顺序写比随机写速度要快,而 LSM 树正是充分利用了这一物理特性,从而实现对频繁、大量数据写操作的支持。
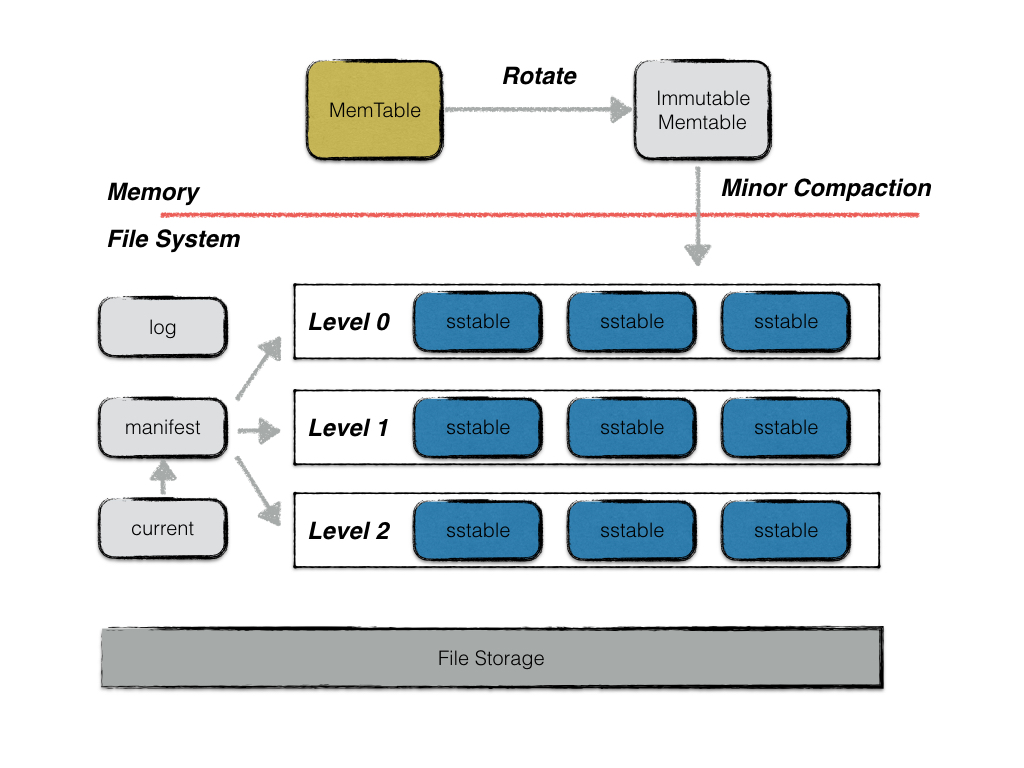
LSM 架构如下:
-
MemTable:内存数据结构,具体实现是 SkipList。接受用户的读写请求,新的数据修改会首先在这里写入。
-
Immutable MemTable :当 MemTable 的大小达到设定的阈值时,会变成 Immutable MemTable,只接受读操作,不再接受写操作,后续由后台线程
Flush到磁盘上。 -
SSTable:Sorted String Table Files,磁盘数据存储文件。分为 Level0 到 LevelN 多层,每一层包含多个 SST 文件,文件内数据有序。Level0 直接由 Immutable Memtable Flush 得到,其它每一层的数据由上一层进行 Compaction 得到。
-
Manifest :Manifest 文件中记录 SST 文件在不同 Level 的分布,单个 SST 文件的最大、最小 key,以及其他一些 LevelDB 需要的元信息。由于 LevelDB 支持 snapshot,需要维护多版本,因此可能同时存在多个 Manifest 文件。
-
Current :由于 Manifest 文件可能存在多个,Current 记录的是当前的 Manifest 文件名。
-
Log :用于防止 MemTable 丢数据的日志文件。
基本组件
Slice
Slice 是 LevelDB 中的一种基本的、以字节为基础的数据存储单元,既可以存储 key,也可以存储 data。Slice 对数据字节的大小没有限制,其内部采用一个const char* 的常量指针存储数据,具有两个接口 data() 和size(),分别返回其表示的数据及数据的长度。
此外,为了方便使用,其内部封装了 compare 函数,以及重载了用于比较的运算符 ==、!=,同时其可以与标准库中的 string 相互转换。
为什么 C++ 中已经有 string 了,还需要实现一个 Slice 呢?
- string 默认语意为拷贝,传参和返回时会损失性能(在可预期的条件下,指针传递即可)。
- Slice 不以 ’ \\0’ 作为字符的终止符,可以存储值为 ‘\\0’ 的数据。
- string 不支持
remove_prefix和starts_with等前缀操作函数,使用不方便。
具体实现代码如下:
// https://github.com/google/leveldb/blob/master/include/leveldb/slice.h
class LEVELDB_EXPORT Slice
public:
Slice() : data_(""), size_(0)
Slice(const char* d, size_t n) : data_(d), size_(n)
Slice(const std::string& s) : data_(s.data()), size_(s.size())
Slice(const char* s) : data_(s), size_(strlen(s))
Slice(const Slice&) = default;
Slice& operator=(const Slice&) = default;
const char* data() const return data_;
size_t size() const return size_;
bool empty() const return size_ == 0;
char operator[](size_t n) const
assert(n < size());
return data_[n];
void clear()
data_ = "";
size_ = 0;
void remove_prefix(size_t n)
assert(n <= size());
data_ += n;
size_ -= n;
std::string ToString() const return std::string(data_, size_);
int compare(const Slice& b) const;
bool starts_with(const Slice& x) const
return ((size_ >= x.size_) && (memcmp(data_, x.data_, x.size_) == 0));
private:
const char* data_;
size_t size_;
;
inline bool operator==(const Slice& x, const Slice& y)
return ((x.size() == y.size()) &&
(memcmp(x.data(), y.data(), x.size()) == 0));
inline bool operator!=(const Slice& x, const Slice& y) return !(x == y);
inline int Slice::compare(const Slice& b) const
const size_t min_len = (size_ < b.size_) ? size_ : b.size_;
int r = memcmp(data_, b.data_, min_len);
if (r == 0)
if (size_ < b.size_)
r = -1;
else if (size_ > b.size_)
r = +1;
return r;
Status
在 LevelDB 中,为了便于抛出异常,定义了一个 Status 类。Status 主要用于记录 LevelDB 中的状态信息,保存错误码和对应的字符串错误信息。(写死的,不支持拓展)
对于错误代码,LevelDB 中定义了 6 种状态码在一个枚举类型 Code 中,如下所示:
// https://github.com/google/leveldb/blob/master/include/leveldb/status.h
class LEVELDB_EXPORT Status
private:
enum Code
kOk = 0,
kNotFound = 1,
kCorruption = 2,
kNotSupported = 3,
kInvalidArgument = 4,
kIOError = 5
;
其中 KoK 代表正常;kNotFound 代表未找到 ;kCorruption 代表数据异常崩溃;kNotSupported 代表不支持;kInvalidArgument 代表参数非法;kIOError 代表 I/O 错误;
// https://github.com/google/leveldb/blob/master/include/leveldb/status.h
class LEVELDB_EXPORT Status
private:
// OK status has a null state_. Otherwise, state_ is a new[] array
// of the following form:
// state_[0..3] == length of message
// state_[4] == code
// state_[5..] == message
const char* state_;
在 Status 类中,所有状态信息,包括状态码与具体描述,都保存在一个私有的成员变量 const char*state_ 中。其具体表示方法如下。
- 当状态为 OK 时,
state_为 NULL,说明当前操作一切正常。 - 否则,
state_为一个 char 数组,即state[0...3]为 msg 的长度,state[4]为状态码 code,state[5...]为具体的 msg。
如下图: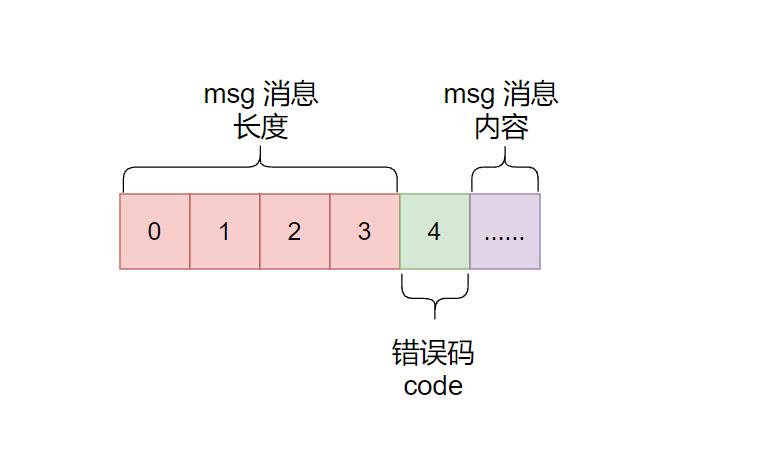
具体的处理逻辑如下:
// https://github.com/google/leveldb/blob/master/util/status.cc
Status::Status(Code code, const Slice& msg, const Slice& msg2)
assert(code != kOk);
const uint32_t len1 = static_cast<uint32_t>(msg.size());
const uint32_t len2 = static_cast<uint32_t>(msg2.size());
const uint32_t size = len1 + (len2 ? (2 + len2) : 0);
char* result = new char[size + 5];
std::memcpy(result, &size, sizeof(size));
result[4] = static_cast<char>(code);
std::memcpy(result + 5, msg.data(), len1);
if (len2)
result[5 + len1] = ':';
result[6 + len1] = ' ';
std::memcpy(result + 7 + len1, msg2.data(), len2);
state_ = result;
Comparator
LevelDB 是按 key 排序后进行存储,因无论是插入还是删除,都必然少不了对 key 的比较。于是乎 LevelDB 抽象出了一个纯虚类 Comparator。
具体定义如下:
// https://github.com/google/leveldb/blob/master/include/leveldb/comparator.h
class LEVELDB_EXPORT Comparator
public:
virtual ~Comparator();
virtual int Compare(const Slice& a, const Slice& b) const = 0;
virtual const char* Name() const = 0;
virtual void FindShortestSeparator(std::string* start,
const Slice& limit) const = 0;
virtual void FindShortSuccessor(std::string* key) const = 0;
;
在 LevelDB 中,有两个实现 Comparator 的类:一个是 BytewiseComparatorImpl,另一个是InternalKeyComparator。
-
BytewiseComparatorImpl:默认比较器,主要采用字典序对两个字符串进行比较。
-
InternalKeyComparator:内部调用的也是 BytewiseComparatorImpl。
Iterate
LevelDB 具有迭代器遍历功能,设计人员只需要调用相应的接口,就可以实现对容器数据类型的遍历访问。
迭代器定义了一个纯虚类的接口,LevelDB 中的任何集合类型对象的迭代器均基于这一纯虚类进行实现。具体代码如下:
// https://github.com/google/leveldb/blob/master/include/leveldb/iterator.h
class LEVELDB_EXPORT Iterator
public:
Iterator();
Iterator(const Iterator&) = delete;
Iterator& operator=(const Iterator&) = delete;
virtual ~Iterator();
virtual bool Valid() const = 0;
virtual void SeekToFirst() = 0;
virtual void SeekToLast() = 0;
virtual void Seek(const Slice& target) = 0;
virtual void Next() = 0;
virtual void Prev() = 0;
virtual Slice key() const = 0;
virtual Slice value() const = 0;
virtual Status status() const = 0;
using CleanupFunction = void (*)(void* arg1, void* arg2);
void RegisterCleanup(CleanupFunction function, void* arg1, void* arg2);
private:
struct CleanupNode
bool IsEmpty() const return function == nullptr;
void Run()
assert(function != nullptr);
(*function)(arg1, arg2);
CleanupFunction function;
void* arg1;
void* arg2;
CleanupNode* next;
;
CleanupNode cleanup_head_;
;
从上面的接口可以看出,LevelDB 实现的是双向迭代器,并且支持 Seek 定位功能。同时还嵌套了一个子结构 CleanupNode 用于释放链表,其中的 CleanupFunction 即用户自定义的清除函数。当用户需要释放资源时,就会通过遍历 CleanupNode 中的 next 链表,并对每一个节点调用一次 CleanupFunction 将资源释放。
Option
头文件 options.h 中定义了一系列与数据库操作相关的选项参数类型,例如与数据库操作相关的 Options,与读操作相关的 ReadOptions,与写操作相关的 WriteOptions。这几个类型均为结构体,在进行数据库的初始化、数据库的读写等操作时,这些参数直接决定了数据库相关的性能指标。
- Options(DB 参数)
- Comparator:被用来表中 key 比较,默认是字典序。
- create_if_missing:打开数据库,如果数据库不存在,是否创建新的。默认为 false。
- error_if_exists:打开数据库,如果数据库存在,是否抛出错误。默认为 false。
- paranoid_checks:默认为 false。如果为 true,则实现将对其正在处理的数据进行积极检查,如果检测到任何错误,则会提前停止。 这可能会产生不可预见的后果:例如,一个数据库条目的损坏可能导致大量条目变得不可读或整个数据库变得无法打开。
- env:环境变量,封装了平台相关接口。
- info_log:db 日志句柄。
- write_buffer_size:memtable 的大小(默认 4mb)
- 值大有利于性能提升
- 但是内存可能会存在两份,太大需要注意 oom
- 过大刷盘之后,不利于数据恢复
- max_open_files:允许打开的最大文件数。
- block_cache:block 的缓存。
- block_size:每个 block 的数据包大小(未压缩),默认是4k。
- block_restart_interval:block 中记录完整 key 的间隔。
- max_file_size:生成新文件的阈值(对于性能较好的文件系统可以调大该阈值,但会增加数据恢复的时间),默认 2k
- compression:数据压缩类型,默认是 kSnappyCompression,压缩速度快
- kSnappyCompression 在 Intel® Core™2 2.4GHz 上的典型速度:
- ~200-500MB/s 压缩
- ~400-800MB/s 解压
- kSnappyCompression 在 Intel® Core™2 2.4GHz 上的典型速度:
- reuse_logs:是否复用之前的 MANIFES 和 log files。
- filter_policy:block 块中的过滤策略,支持布隆过滤器。
- ReadOptions(读操作参数)
- verify_checksums:是否对从磁盘读取的数据进行校验。
- fill_cache:读取到 block 数据,是否加入到 cache 中。
- snapshot:记录的是当前的快照。
- WriteOptions(写操作参数)
- sync:是否同步刷盘,也就是调用完 write 之后是否需要显式
fsync。
- sync:是否同步刷盘,也就是调用完 write 之后是否需要显式
以上是关于LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption的主要内容,如果未能解决你的问题,请参考以下文章
LevelDB 源码剖析整体架构与基本组件:ComparatorSliceStatusIteratorOption
LevelDB 源码剖析DBImpl模块:OpenGetPutDeleteWrite
LevelDB 源码剖析DBImpl模块:OpenGetPutDeleteWrite
LevelDB 源码剖析DBImpl模块:OpenGetPutDeleteWrite
LevelDB 源码剖析Compaction模块:Minor CompactionMajor Compaction文件选取执行流程垃圾回收
LevelDB 源码剖析Compaction模块:Minor CompactionMajor Compaction文件选取执行流程垃圾回收