LevelDB 源码剖析Compaction模块:Minor CompactionMajor Compaction文件选取执行流程垃圾回收
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LevelDB 源码剖析Compaction模块:Minor CompactionMajor Compaction文件选取执行流程垃圾回收相关的知识,希望对你有一定的参考价值。
文章目录
LevelDB 中的 Level 代表层级,有 0~6 共 7 个层级,每个层级都由一定数量的 SSTable 文件组成。其中,高层级文件是由低层级的一个文件与高层级中与该文件有键重叠的所有文件使用归并排序算法生成,该过程称为 Compaction。
LevelDB 通过 Compaction 将冷数据逐层下移,并且在 Compaction 过程中重复写入的键只会保留一个最终值,已经删除的键不再写入,因此可以减少磁盘空间占用。
结构
// https://github.com/google/leveldb/blob/master/db/version_set.h
class Compaction
public:
~Compaction();
int level() const return level_;
VersionEdit* edit() return &edit_;
int num_input_files(int which) const return inputs_[which].size();
FileMetaData* input(int which, int i) const return inputs_[which][i];
uint64_t MaxOutputFileSize() const return max_output_file_size_;
bool IsTrivialMove() const;
void AddInputDeletions(VersionEdit* edit);
bool IsBaseLevelForKey(const Slice& user_key);
bool ShouldStopBefore(const Slice& internal_key);
void ReleaseInputs();
private:
friend class Version;
friend class VersionSet;
Compaction(const Options* options, int level);
int level_;
uint64_t max_output_file_size_;
Version* input_version_;
VersionEdit edit_;
std::vector<FileMetaData*> inputs_[2]; // The two sets of inputs
std::vector<FileMetaData*> grandparents_;
size_t grandparent_index_; // Index in grandparent_starts_
bool seen_key_; // Some output key has been seen
int64_t overlapped_bytes_; // Bytes of overlap between current output
// and grandparent files
size_t level_ptrs_[config::kNumLevels];
;
在 LevelDB 中,Compaction 共有两种,分别叫 Minor Compaction 和 Major Compaction。
- Minor Compaction:将 Immtable dump 到 SStable 。
- Major Compaction:Level 之间的 SSTable Compaction。
这两类compaction负责在不同的场景下进行不同的数据整理。
Minor Compaction
定义
Minor Compaction 非常简单,其本质就是将一个内存数据库(Memtable)中的所有数据持久化到一个磁盘文件中(SSTable)。整体流程如下图:
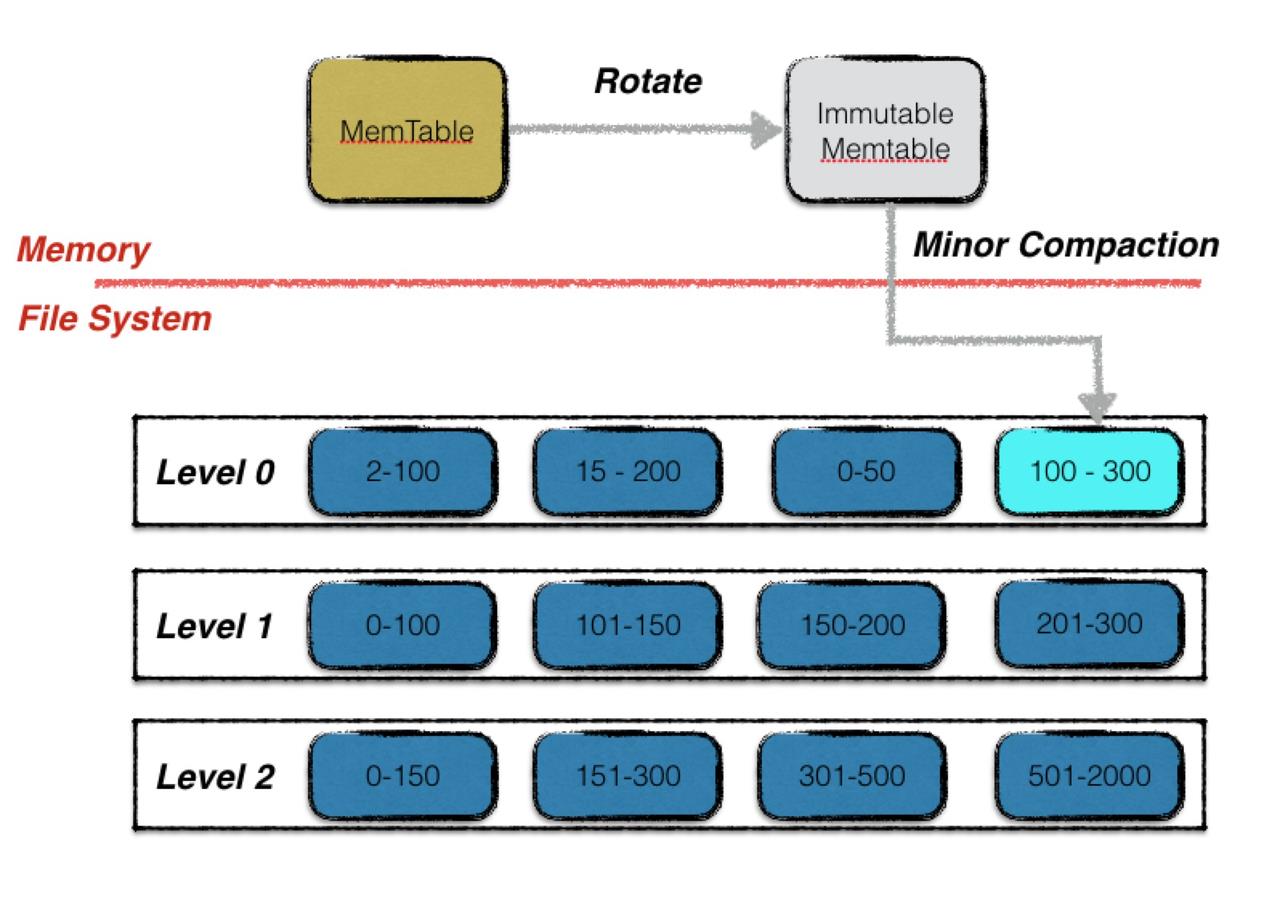
触发时机
在 LSM 树的实现中,会先将数据写入 MemTable,当 MemTable 大小超过 options_.write_buffer_size (默认 4M)时,需要将其作为 SSTable 写入磁盘,此时就会采取 Minor Compaction。
核心要点
-
每次 Minor Compaction 结束后,都会生成一个新的 SSTable 文件,也意味着 Leveldb 的版本状态发生了变化,会进行一个版本的更替。
-
Minor Compaction 是一个时效性要求非常高的过程,要求其在尽可能短的时间内完成,否则就会堵塞正常的写入操作,因此 Minor Compaction 的优先级高于 Major Compaction。当进行 Minor Compaction 的时候有 Major Compaction正在进行,则会首先暂停 Major Compaction。
Major Compaction
定义
Major Compaction 是将不同层级的 SSTable 文件进行合并。
如下图,可以看出其比 Minor Compaction 复杂的多。
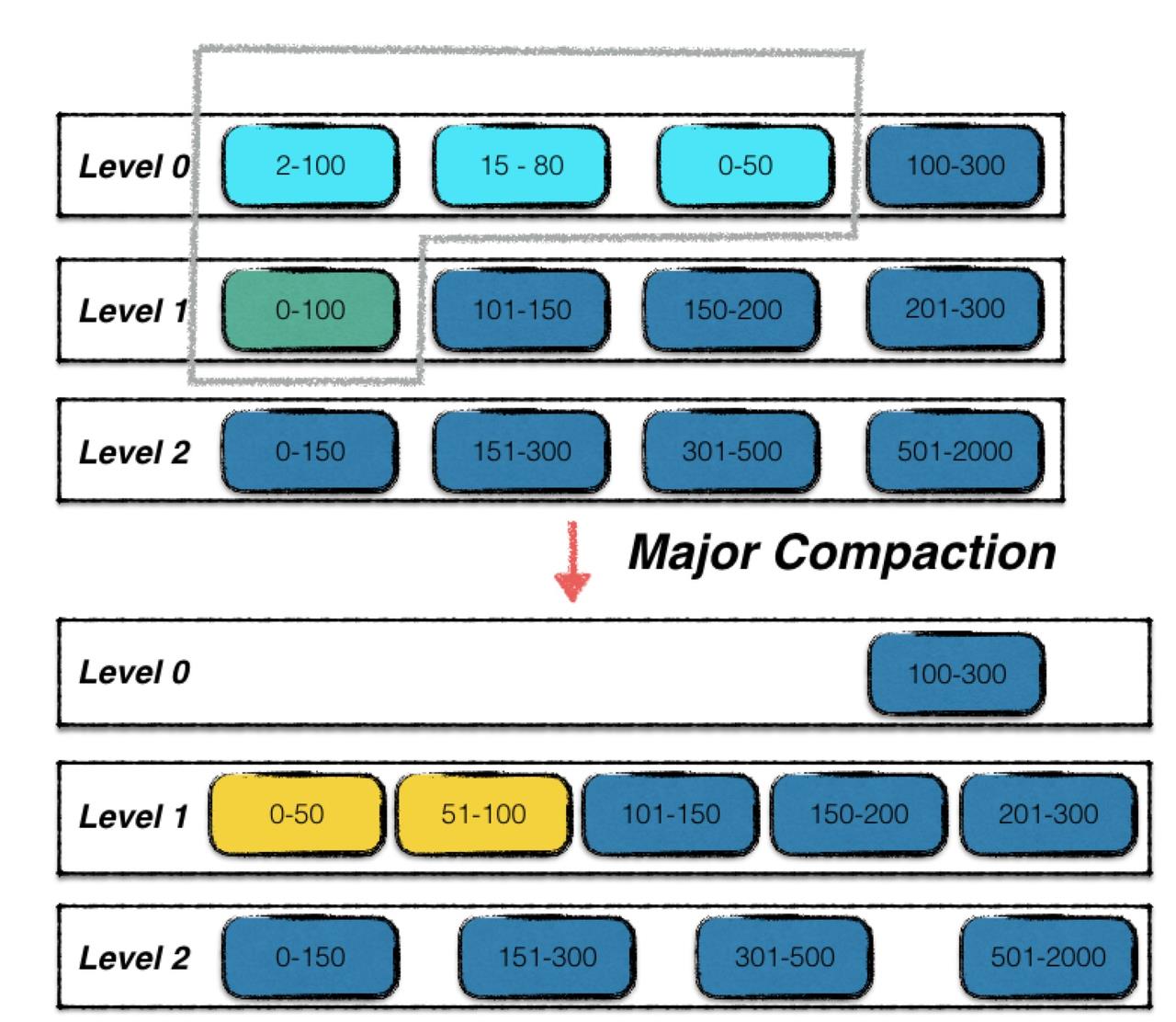
触发时机
那么什么时候,会触发 LevelDB 进行 Major Compaction 呢?总的来说为以下三个条件:
- 当 0 层文件数超过预定的上限(默认为 4 个)。
- 当 Level i 层文件的总大小超过 10 ^ i MB。
- 当某个文件无效读取的次数过多。
这也就引出了 Size Compaction 与 Seek Compaction 两种判断策略。LevelDB 先按 Size Compaction 判断是否需要进行 Compaction ,如果 Size Compaction 不满足则通过 Seek Compaction 继续判断,如果仍不满足,则表明暂时不需要进行 Compaction。
Size Compaction
size_compaction 通过判断 Level 0 中的文件个数(Level 0 会被频繁访问)或者 Level 1 ~ Level 5 的文件总大小来计算得出需要进行 Compaction 的 Level。
该赋值逻辑位于 VersionSet 中的 Finalize,代码如下:
// https://github.com/google/leveldb/blob/master/db/version_set.cc
void VersionSet::Finalize(Version* v)
int best_level = -1;
double best_score = -1;
for (int level = 0; level < config::kNumLevels - 1; level++)
double score;
//对于Level 0来说,其分数为文件个数 / 4
if (level == 0)
score = v->files_[level].size() /
static_cast<double>(config::kL0_CompactionTrigger);
else
//对于Level 1~5的分数由该层所有文件总大小除以每层允许的最大大小决定
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =
static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
//选取最高分的一个level
if (score > best_score)
best_level = level;
best_score = score;
//更新level与score
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
compaction_score_ 的赋值逻辑如下:
- Level 0:将当前 Level 0 包含的文件个数除以 4 并赋值给 compaction_score_ ,如果 Level 0 的文件个数大于等于 4,则此时 compaction_score_ 会大于等于 1。
- Level 1~Level 5:通过该层文件的总大小除以该层文件允许的最大大小并赋值给 compaction_score_。
每次当版本中的 compaction_score_ 大于等于 1 时,则需要进行一次 Compaction 操作。
Seek Compaction
Seek compaction 主要通过记录某个 SSTable 的 Seek 次数,当其无效读取次数到达阈值(allowed_seeks)之后,将会记录下它的 level,参与下一次压缩。
阈值 allowed_seeks 是每个文件允许的最大无效读取次数,该值的计算代码在 VersionSet::Build 中的 Apply,代码如下:
f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
allowed_seeks 计算逻辑为文件大小除以 16384 后取值。但如果计算得到的值小于 100,则将其设置为 100。
为什么是除以16384呢?LevelDB作者给出了这样的解释:
- 硬盘中的一次查找操作耗费10ms。
- 硬盘读取速度为100MB/s,因此读取或者写入1MB数据需要10ms。
- 执行Compaction操作时,1MB的数据需要25MB数据的I/O,因为从当前层级读取1MB后,相应地需要从下一个层级读取10MB~12MB(因为每一层的最大大小为前一层的10倍,并且考虑到边界重叠的情况,因此执行Compaction操作时需要读取下一层的10MB~12MB数据),然后执行归并排序后写入的10MB~12MB的数据到下一个层级,因此读取加写入最大需要25MB数据的I/O。
- 因此25次查找(约耗费250ms)约略等于一次执行Compaction操作时处理1MB数据的时间(1MB的当前层读取加10MB~12MB的下一层读取,再加10MB~12MB的下一层写入,约为25MB的数据读取和写入总量,因此也是消耗250ms)。那么一次查找的数据量约略等于处理Compaction操作时的40KB数据(1MB除以25)。进一步保守处理,取16384(16K)这个值,即当查找次数超出allowed_seeks时,执行一次Compaction操作是一个更加合理的选择。
file_to_compact_level_ 的赋值逻辑位于 Version 的 UpdateStats,代码如下:
// https://github.com/google/leveldb/blob/master/db/version_set.cc
bool Version::UpdateStats(const GetStats& stats)
//此时的f为无效查找的文件
FileMetaData* f = stats.seek_file;
if (f != nullptr)
//当前查找无效,allowed_seeks-1
f->allowed_seeks--;
//如果此时allowed_seeks小于等于0,则说明此时到达阈值,则将当前层级记录下来,待进行Compaction
if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr)
file_to_compact_ = f;
file_to_compact_level_ = stats.seek_file_level;
return true;
return false;
假设进行无效查找的文件为f(FileMetaData结构),先将 f 的 allowed_seeks 次数减 1,此时判断如果allowed_seeks 变量已经小于等于 0 且 Version 中的 file_to_compact_ 成员变量为空,则将 f 赋值给file_to_compact_ ,并且将 f 所属层级赋值给 file_to_compact_level_ 变量。
Manual Compaction
Manual Compaction 是指人工触发的 Compaction,由外部接口调用产生。
实际其内部触发调用的接口是 DBImpl 中的 CompactRange,代码如下:
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
void DBImpl::CompactRange(const Slice* begin, const Slice* end)
int max_level_with_files = 1;
MutexLock l(&mutex_);
Version* base = versions_->current();
for (int level = 1; level < config::kNumLevels; level++)
if (base->OverlapInLevel(level, begin, end))
max_level_with_files = level;
//略过所有没有重叠的文件
TEST_CompactMemTable();
//一层层压缩存在重叠的文件
for (int level = 0; level < max_level_with_files; level++)
TEST_CompactRange(level, begin, end);
在 Manual Compaction 中会指定的 begin 和 end,它将会一个层层的分次的 Compact 所有 Level 中与 begin 和 end 有重叠(overlap)的 SSTable 文件。
文件选取
每次进行 Compaction 时,首先决定在哪个层级进行该次操作,假设为Level n,接着选取 Level n 层参与的文件,然后选取 Level n+1 层需要参与的文件,最后对选中的文件使用归并排序生成一个新文件。
PickCompaction
决定层级 n 以及选取 Level n 层参与文件的方法为 VersionSet 中的 PickCompaction。
// https://github.com/google/leveldb/blob/master/db/version_set.cc
Compaction* VersionSet::PickCompaction()
Compaction* c;
int level;
//根据current_判断是size_compaction还是seek_compaction
const bool size_compaction = (current_->compaction_score_ >= 1);
const bool seek_compaction = (current_->file_to_compact_ != nullptr);
/*
如果根据size_compaction触发,则根据每个层级的compact_pointer_选取本次Compaction的
level n层文件(记录每个层级下一次开始进行Compaction操作时需要从哪个键开始。)
*/
if (size_compaction)
//获取当前层级
level = current_->compaction_level_;
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
c = new Compaction(options_, level);
//选出第一个在compact_pointer_之后的文件
for (size_t i = 0; i < current_->files_[level].size(); i++)
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0)
c->inputs_[0].push_back(f);
break;
//如果通过compact_pointer_没有选取到文件(Compaction已遍历本层),则选取本层第一个文件
if (c->inputs_[0].empty())
// Wrap-around to the beginning of the key space
c->inputs_[0].push_back(current_->files_[level][0]);
else if (seek_compaction)
//如果根据seek_compaction触发,则直接将无效查找次数超限的文件选取为本次的Level n层文件
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
else
return nullptr;
c->input_version_ = current_;
c->input_version_->Ref();
//对level 0特殊处理
if (level == 0)
InternalKey smallest, largest;
//取出Level 0中参与本次Compaction操作的文件的最小键和最大键
GetRange(c->inputs_[0], &smallest, &largest);
//根据最小键和最大键对比Level 0中的所有文件,如果存在文件与[Lkey,Hkey]有重叠,则扩大最小键和最大键范围,并继续查找。
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
assert(!c->inputs_[0].empty());
//调用SetupOtherInputs选取level n+1层需要参与的文件
SetupOtherInputs(c);
return c;
执行逻辑如下:
- 根据 current_ 判断是 size_compaction 还是 seek_compaction:
- 根据 size_compaction 触发:则根据每个层级的 compact_pointer_ 选取本次 Compaction 的
level n 层文件(记录每个层级下一次开始进行 Compaction 时需要从哪个键开始)。 - 根据 seek_compaction 触发:则直接将无效查找次数超限的文件选取为本次的 Level n 层文件。
- 根据 size_compaction 触发:则根据每个层级的 compact_pointer_ 选取本次 Compaction 的
- 对 level 0 特殊处理:
- 取出 Level 0 中参与本次 Compaction 的文件的最小键和最大键,假设其范围为 [Lkey,Hkey]。
- 根据最小键和最大键对比 Level 0 中的所有文件,如果存在文件与 [Lkey,Hkey] 有重叠,则扩大最小键和最大键范围,并继续查找。
- 调用
SetupOtherInputs选取 level n+1 层需要参与的文件。
为何Level 0中需要扩展有键重叠的文件呢?
举例说明,假设Level 0有4个文件:f1、f2、f3、f4,每个文件的键范围分别为[c,e],[a,f],[a,b],[i,z]。
通过第一步选取的inputs_ [0]文件是f1,f1中的键范围和f2有重叠,则扩大最小键和最大键范围到[a,f],此时发现f3的键范围也和f2有重叠,因此最终inputs_[0]中的文件包括f1、f2、f3三个文件。
假设有这样一种情况,我们首先写了d这个键,在f2中的序列号为10,然后删除了d,删除操作在f1中的序列号为100,假设Compaction操作时只是选取了f1,则下次查找d这个键时先从Level 0选取,会读取到f2中序列号为10的值(实际上该键已经删除),此时会出现错误。
SetupOtherInputs
PickCompaction 会选定进行 Compaction 操作的层级 n 以及 Level n 层的参与文件,之后会调用SetupOtherInputs 进行 Level n+1 层文件的选取,SetupOtherInputs 的代码如下:
// https://github.com/google/leveldb/blob/master/db/version_set.cc
void VersionSet::SetupOtherInputs(Compaction* c)
const int level = c->level();
InternalKey smallest, largest;
AddBoundaryInputs(icmp_, current_->files_[level], &c->inputs_[0]);
//获取input_[0]所有文件的最大键和最小键
GetRange(c->inputs_[0], &smallest, &largest);
//根据input_[0]中的最大键/最小键查找level n+1层的文件,并分别赋值到input_[1]中
current_->GetOverlappingInputs(level + 1, &smallest, &largest,
&c->inputs_[1]);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
InternalKey all_start, all_limit;
//继续获取input_[0]和[1]的所有文件的最大键和最小键
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
//在不扩大level n+1层的前提下,尝试扩大level n层的文件,并且扩大后的文件总大小不超过50M
if (!c->inputs_[1].empty())
std::vector<FileMetaData*> expanded0;
current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0);
AddBoundaryInputs(icmp_, current_->files_[level], &expanded0);
const int64_t inputs0_size = TotalFileSize(c->inputs_[0]);
const int64_t inputs1_size = TotalFileSize(c->inputs_[1]);
const int64_t expanded0_size = TotalFileSize(expanded0);
if (expanded0.size() > c->inputs_[0].size() &&
inputs1_size + expanded0_size <
ExpandedCompactionByteSizeLimit(options_))
InternalKey new_start, new_limit;
GetRange(expanded0, &new_start, &new_limit);
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit,
&expanded1);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &expanded1);
if (expanded1.size() == c->inputs_[1].size())
Log(options_->info_log,
"Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\\n",
level, int(c->inputs_[0].size()), int(c->inputs_[1].size()),
long(inputs0_size), long(inputs1_size), int(expanded0.size()),
int(expanded1.size()), long(expanded0_size), long(inputs1_size));
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0;
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
if (level + 2 < config::kNumLevels)
current_->GetOverlappingInputs(level + 2, &all_start, &all_limit,
&c->grandparents_);
//将本次Compaction的最大键保存到compact_pointer_中,下次Compaction时根据该值选取level n层文件
compact_pointer_[level] = largest.Encode().ToString();
c->edit_.SetCompactPointer(level, largest);
当 Level n 层和 Level n+1 层的文件都已经选定,LevelDB 的实现中有一个优化点,即判断是否可以在不扩大 Level n+1 层文件个数的情况下,将 Level n 层的文件个数扩大,优化逻辑如下:
-
inputs_ [1] 选取完毕之后,首先计算 inputs_ [0] 和 inputs_ [1] 所有文件的最大/最小键范围,然后通过该范围重新去 Level n 层计算 inputs_ [0],此时有可能选取到新的文件进入 inputs_ [0]。
-
通过新的 inputs_ [0] 的键范围重新选取 inputs_ [1] 中的文件,如果 inputs_ [1] 中的文件个数不变并且扩大范围后所有文件的总大小不超过50MB,则使用新的 inputs_ [0] 进行本次 Compaction ,否则继续使用原来的inputs_ [0]。50 MB 的限制是防止执行一次 Compaction 导致大量的 I/O 操作,从而影响系统性能。
-
如果扩大 Level n 层的文件个数之后导致 Level n+1 层的文件个数也进行了扩大,则不能进行此次优化。因为Level 1到 Level 6 的所有文件键范围不能有重叠,如果继续执行该优化,会导致 Compaction 之后 Level n+1 层的文件有键重叠的情况产生。
整体流程
其代码实现在 DBImpl 中的 DoCompactionWork,其代码如下:
// https://github.com/google/leveldb/blob/master/db/db_impl.cc
Status DBImpl::DoCompactionWork(CompactionState* compact)
//...
//计算最小序列号,如果Compaction中存在重复写入或者删除的键,则根据序列号判断是否需要删除
//如果没有快照,则将当前版本的last_sequence赋值为最小的序列号
if (snapshots_.empty())
compact->smallest_snapshot = versions_->LastSequenceLevelDB 源码剖析Compaction模块:Minor CompactionMajor Compaction文件选取执行流程垃圾回收
LevelDB 源码剖析MemTable模块:SkipListMemTable持久化