使用StanfordCoreNLP的句法树以及NLTK的Tree建立DGL的图数据结构
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用StanfordCoreNLP的句法树以及NLTK的Tree建立DGL的图数据结构相关的知识,希望对你有一定的参考价值。
文章目录
前言
因为其实Tree-LSTM的数据类型构造起来也是比较麻烦的,还是要记录一下,以防之后忘记
构建思路
因为前面一篇写的Tree-LSTM是用DGL实现的,那么图数据结构自然也要用DGL来操作一下,不然喂不进去啊。
构建数据集的样子是按照DGL自带的SSTDataset(mode=‘tiny’)来的,因为这样我就可以直接放进去训练了。
我是使用句法树来构建的,因为句法树并不止二叉,因此模型使用Child-sum Tree-LSTM会比较合适。
例如:
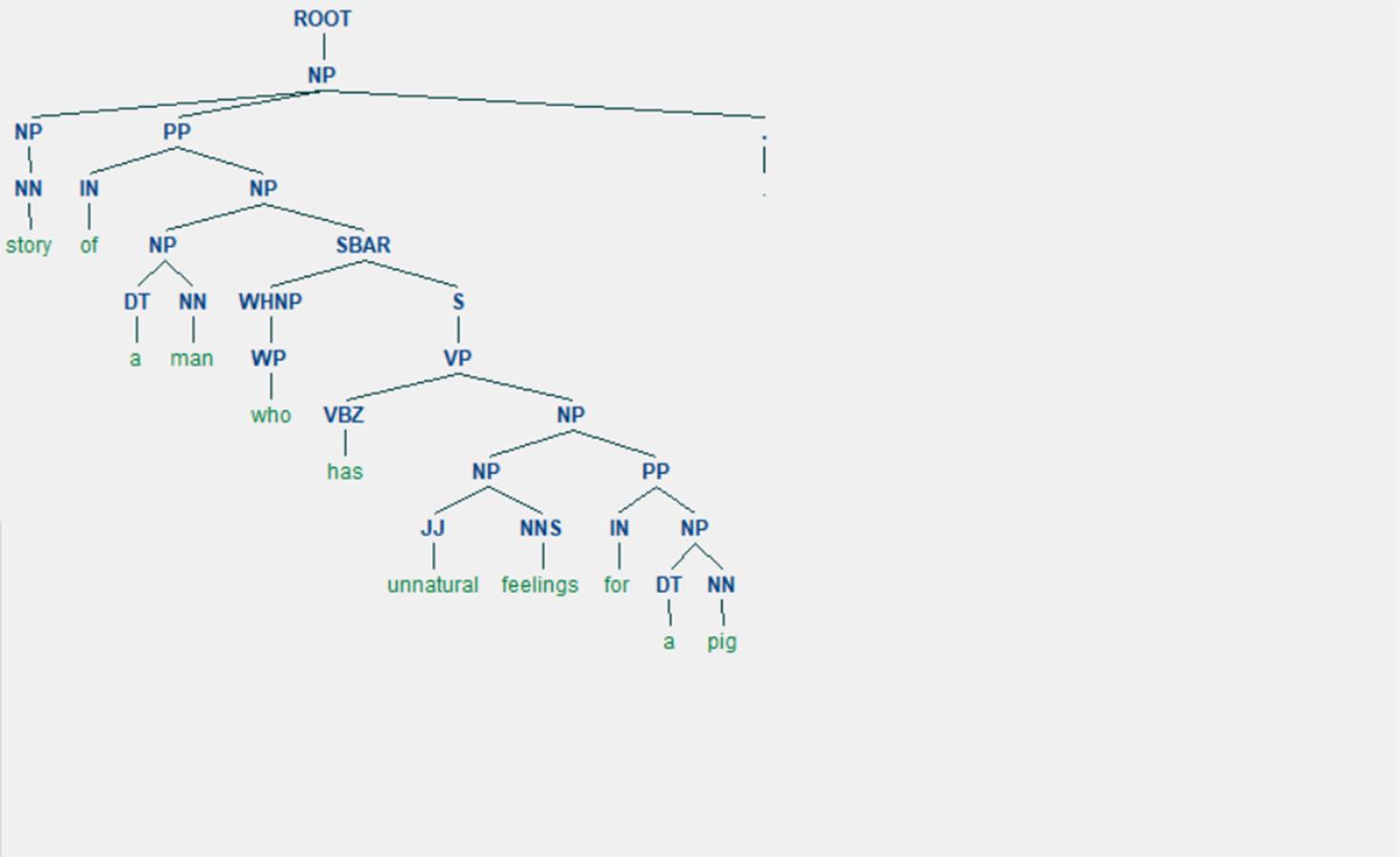
这么一颗句法树,因为DGL使用序号来标注节点的,那么其实我也需要转成序号才方便赋值,因此使用NLTK的Tree操作一下,可以将句法树变成这样:
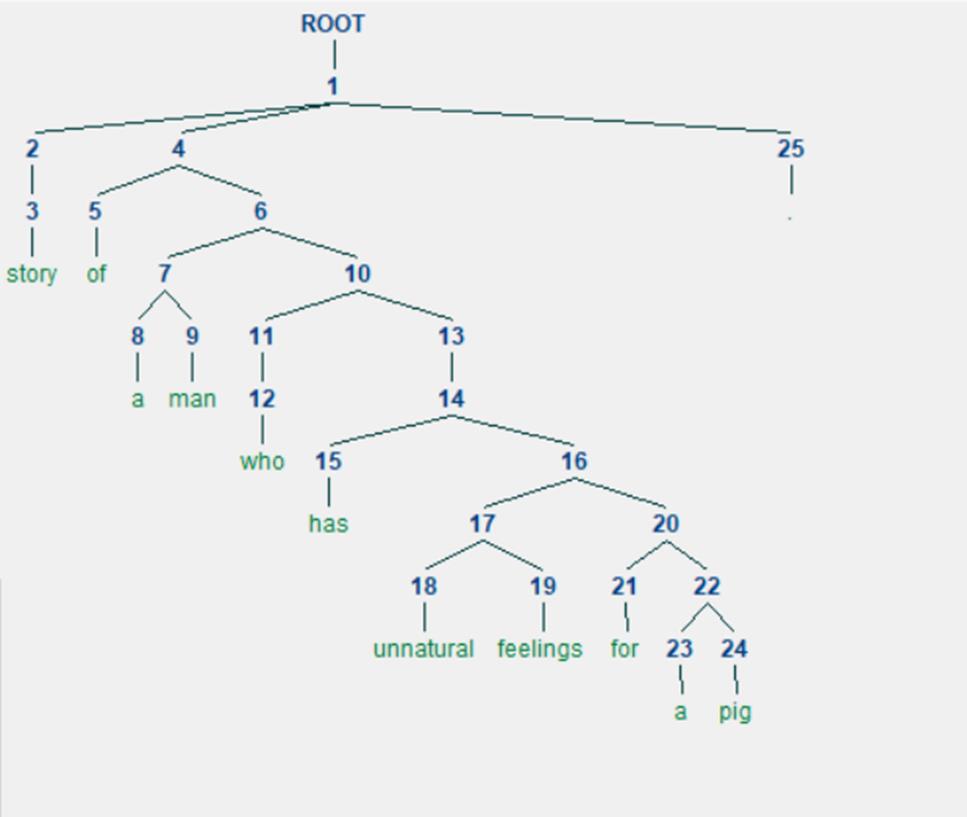
然后我再从叶子节点往上加入边,知道根节点停止,那么一个图就建立完成了。
但是,这只是一句话,我需要对一段话进行情感分类,而句法树只能分析一句话,那么我可以把一段话切句,然后将每句话的根节点连接到一个假想的节点上,然后用这个节点的信息作为最终的分类输出,代表整段话的含义,然后用来分类即可。
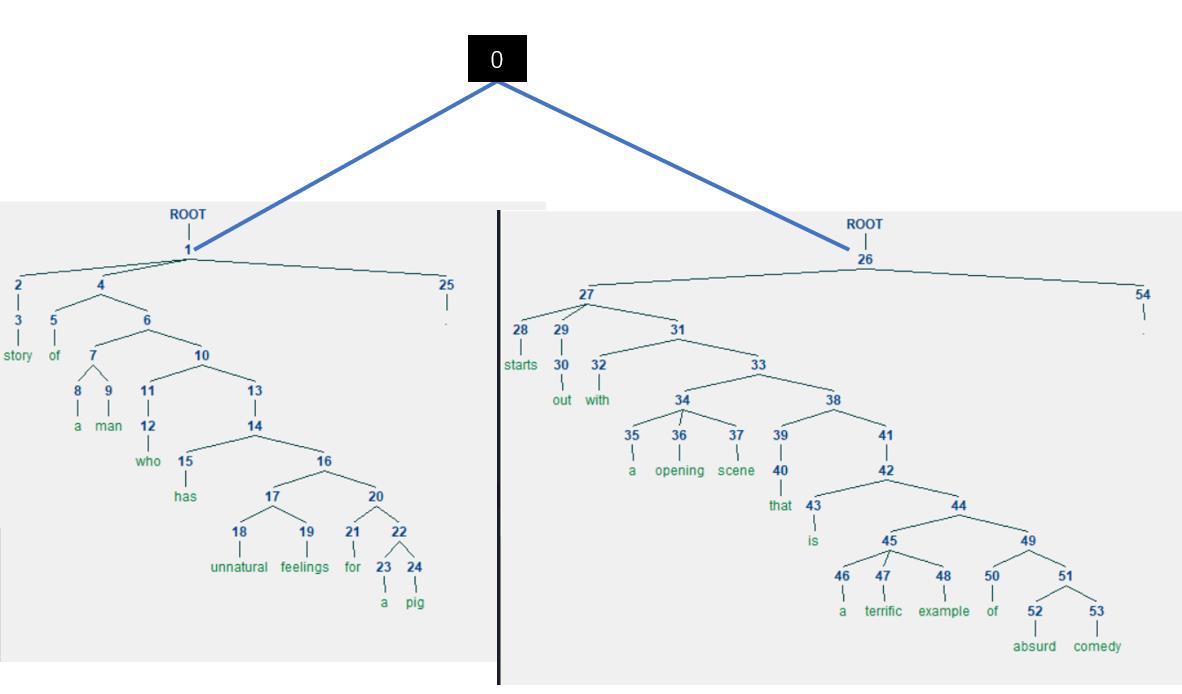
就像这样,构造一片句法森林,然后用0节点的信息来分类即可。
代码如下:
首先获取图数据结构,以及记录每段话叶子节点的词
from stanfordcorenlp import StanfordCoreNLP
from nltk import Tree
from nltk.tokenize import sent_tokenize
import dgl
import torch
import pandas as pd
from tqdm import tqdm
nlp = StanfordCoreNLP(r'D:\\stanfordnlp\\stanford-corenlp-4.4.0', lang="en")
row_data_path = "demo.tsv" # 每段话的tsv文件
data = pd.read_csv(row_data_path, sep="\\t")
graph_data = [] # 存放句法树组成的图
tree_word = [] # 存放句法树的叶子节点
for index, d in tqdm(data.iterrows()):
sentence = sent_tokenize(d["text"])
j = 1 # 节点编号,取下面那个为根节点,标号为1
tree = [] # 存u->v的元组
leaves_pos = [] # 存叶子节点的位置信息
leaves_word = [] # 存叶子节点的词
node_sum = -1 # 节点数
for sen in sentence:
tree.append((j, 0)) # 每句话句法树连到0节点
parse = nlp.parse(sen)
t = Tree.fromstring(parse)
# t.draw()
pos = t.treepositions() # 所有节点的位置
leaves = t.treepositions('leaves') # 所有叶子节点的位置
num = len(pos) - len(leaves) # 非叶子节点的位置
for i in range(len(pos)): # 给节点打标号,跳过ROOT
if i == 0:
continue
if type(t[pos[i]]) == str:
continue
else:
t[pos[i]].set_label(j)
j += 1
# t.draw()
# for pos in t.treepositions('leaves'): # 获取所有叶子节点的位置
# print(t[pos[:-1]].label())
for pos in t.treepositions('leaves'): # 获取所有叶子节点的位置
leaves_word.append(t[pos]) # 存叶子节点的词
node_num = len(pos)
labels = [] # 存此叶子节点到根节点的所有节点的序号
for i in range(1, node_num, 1):
labels.append(t[pos[:-i]].label())
leaves_pos.append(labels[0]) # 第一个为叶子节点
for k in range(len(labels)):
if labels[k] > node_sum: # 记录最大节点编号
node_sum = labels[k]
try:
u_v = (labels[k], labels[k+1])
if u_v not in tree:
tree.append(u_v)
else:
break
except:
break
# print(tree)
# print(leaves_pos)
# print(node_sum)
# print(leaves_word)
tree_graph = dgl.graph(tree)
mask = torch.zeros(node_sum + 1) # 不是叶子节点的被遮掩
mask[leaves_pos] = 1
tree_graph.ndata["mask"] = mask.long() # 节点给上掩码
node_pos = torch.arange(0, node_sum + 1)
tree_graph.ndata["node_pos"] = node_pos # 节点标记位置
if d["label"] == 0:
label = torch.zeros(node_sum + 1) # 存句子的标签0
else:
label = torch.ones(node_sum + 1) # 存句子的标签1
tree_graph.ndata["y"] = label.long()
tree_graph.ndata["x"] = label.long()
# print(tree_graph)
graph_data.append(tree_graph)
tree_word.append("#$#".join(leaves_word))
if index % 1000 == 0: # 每隔1000次保存一次
print(index)
torch.save(graph_data, "graph_data_" + str(index) + ".pt") # 存图数据
pd.DataFrame(tree_word).to_csv("tree_word_" + str(index) + ".tsv", sep="\\t", index=0) # 存叶子节点的词
nlp.close()
当所有数据分析完成后(没有完成的话字典是建立不出来的,下面代码没有建立字典的过程,需要自己补充),通过叶子节点的记录建立对应的字典,然后将图数据结构中的叶子节点对应的词等等特征补充完整
graph_data = torch.load("graph_data_0.pt")
import json
with open("train_data_dic.json") as f:
dic = json.load(f)
import pandas as pd
import torch
f = pd.read_csv(r"tree_word_0.tsv", sep="\\t")
for i in range(len(f)): # 赋值叶子节点(node_pos)
words = f.loc[i][0].split("#$#")
mask = graph_data[i].ndata["mask"]
wordid = torch.zeros(len(mask))
k = 0 # 词的下标
for j in range(len(mask)):
if mask[j] == 1: # 没被mask就是对应的词
try:
wordid[j] = dic[words[k]]
except:
wordid[j] = dic["<unk>"]
k += 1
graph_data[i].ndata["x"] = wordid.long()
print(graph_data)
torch.save(graph_data, "graph_data.pt")
例如:
demo.tsv:
text label
although i am not a golf fan, i attended a sneak preview of this movie and absolutely loved it. 1
运行完成后得到的图数据graph_data如下:
[Graph(num_nodes=38, num_edges=37,
ndata_schemes='mask': Scheme(shape=(), dtype=torch.int64), 'node_pos': Scheme(shape=(), dtype=torch.int64), 'y': Scheme(shape=(), dtype=torch.int64), 'x': Scheme(shape=(), dtype=torch.int64)
edata_schemes=)]
元素0为这个段话的图,共38个节点,37条边,节点的特征中有mask(用于屏蔽不是叶子节点的位置),node_pos节点标记位置 ,x存词的id, y存标签。
以上是关于使用StanfordCoreNLP的句法树以及NLTK的Tree建立DGL的图数据结构的主要内容,如果未能解决你的问题,请参考以下文章
Stanford CoreNLP超简单安装及简单使用,句法分析及依存句法分析
Stanford CoreNLP句法分析可视化及保存在json文件中