不羞涩社区图片爬取,我真的不是为了看小姐姐私照,从未这么渴望过知识!
Posted 普通网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不羞涩社区图片爬取,我真的不是为了看小姐姐私照,从未这么渴望过知识!相关的知识,希望对你有一定的参考价值。
不羞涩社区图片爬取
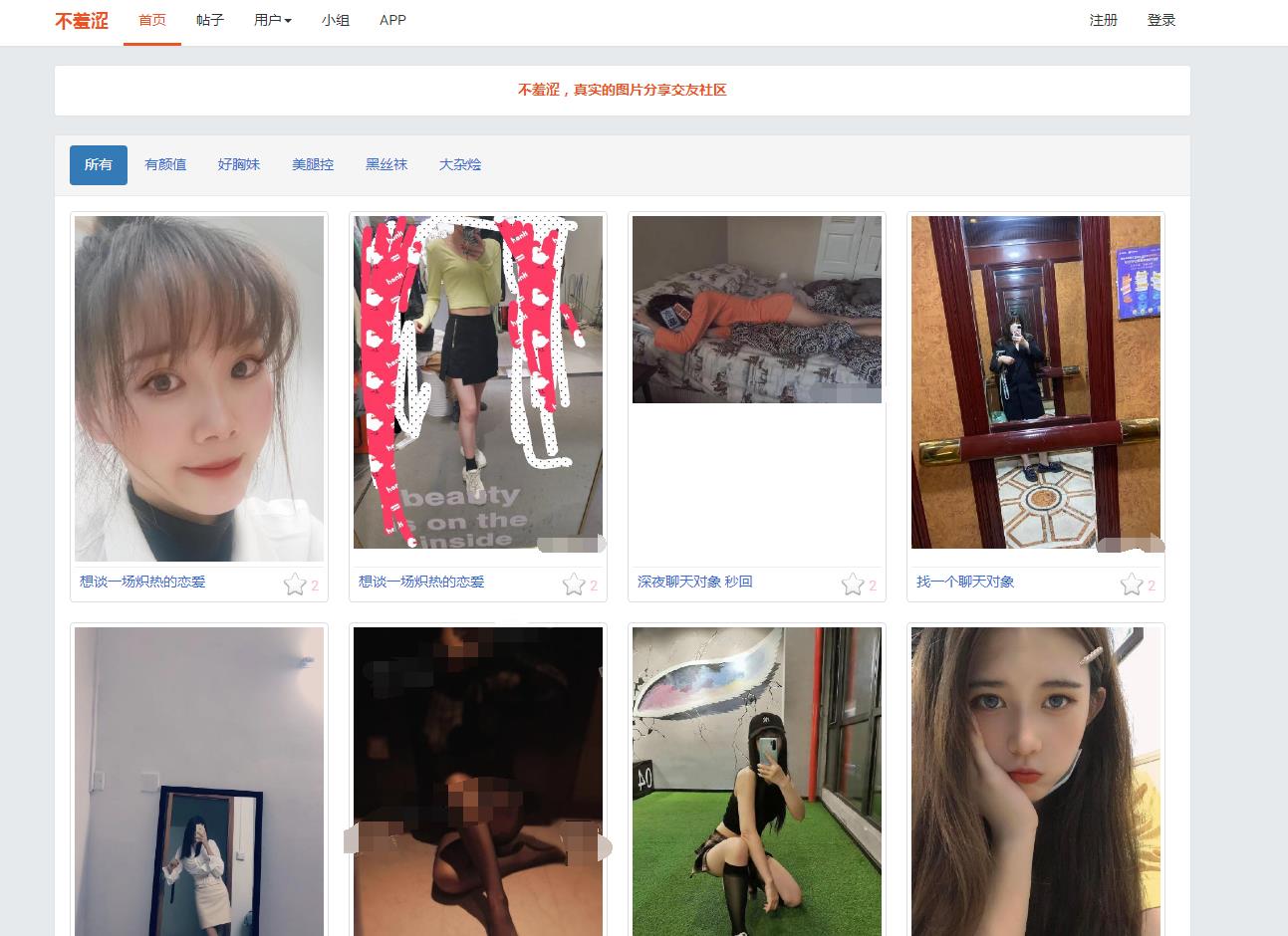
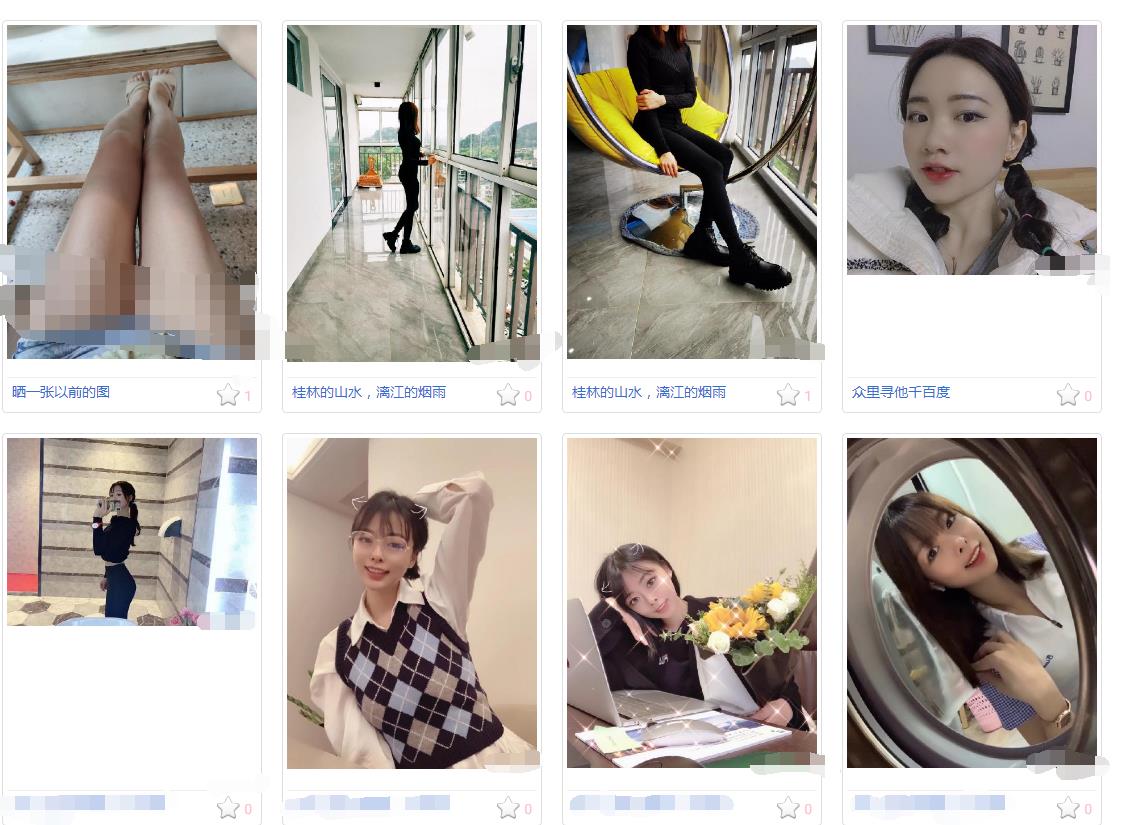
展示效果
PS:仅供学习交流,侵删。
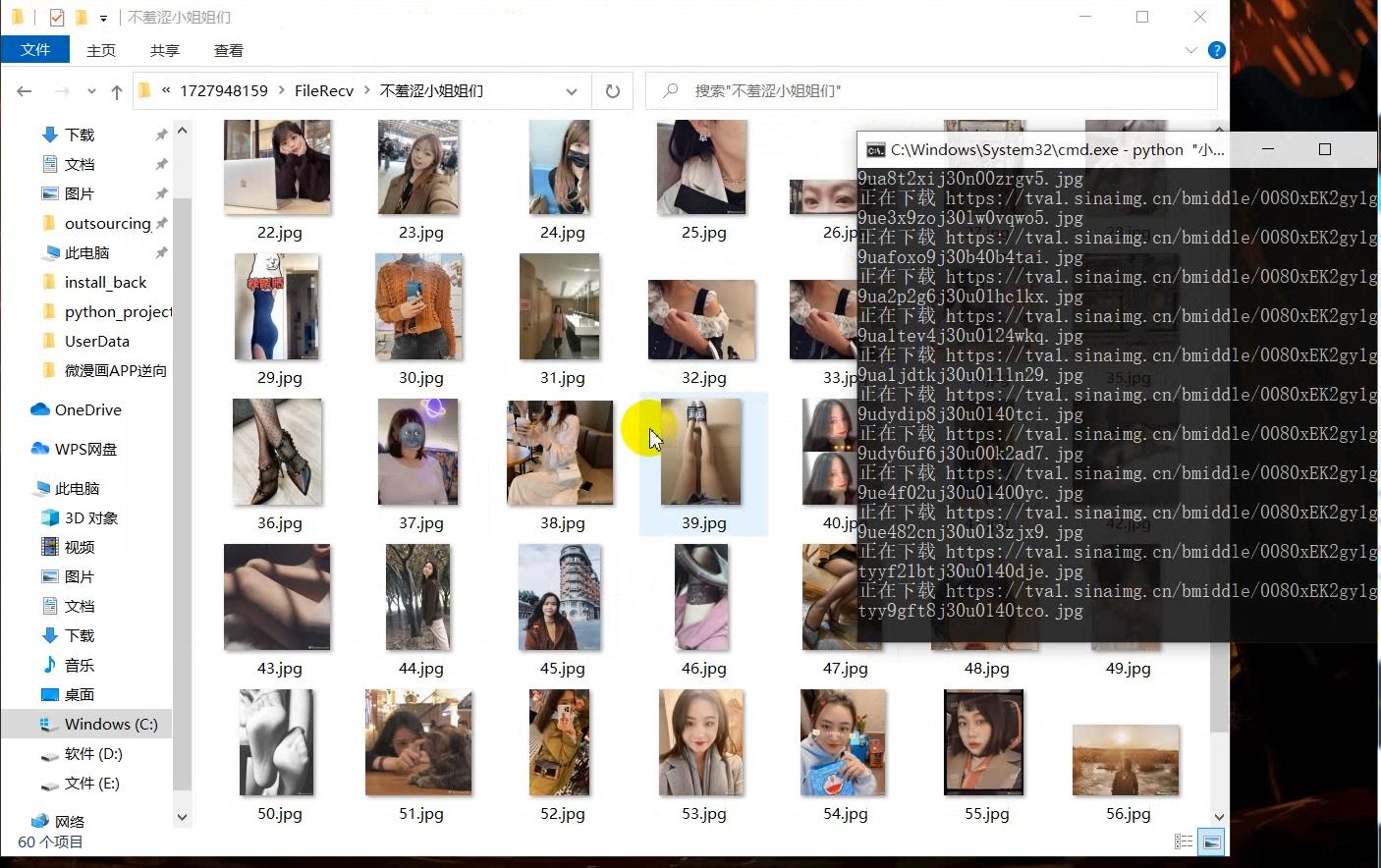
请求头
我下面就不一一解释了,小白没有基础的看不懂没关系,拿代码是可以直接运行的了,至于懂的也都懂了,没有基础的朋友建议可以从Python基础开始看看,我专栏也有写过Python基础的内容,感兴趣的话自己去看看吧。
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
获取网站的请求数据
def RequestIndex(page):
url = 'https://www.buxiuse.com/?page='.format(page)
response = requests.get(url,headers=headers).text
# print(response.text)
return response
提取数据
def dataEX(index):
"""数据提取 获取到在HTML里面的图片URL"""
# 数据初始化 学习资料领取关注左上角wx公众号点击福利即可领取
doc = pq(index)
height_min = doc('.height_min').items()# 转换成数据集
for i in height_min:
imgUrl = (i.attr('src'))
print("正在下载", imgUrl)
保存数据
def ImgSave(imgUrl):
global count
response = requests.get(imgUrl,headers=headers)
with open("./不羞涩小姐姐们/.jpg".format(count),"ab") as f:
f.write(response.content)
count += 1
完整代码
# 1.获取网站的请求数据
import requests
from pyquery import PyQuery as pq
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
count = 1
# 1.获取网站的请求数据
def RequestIndex(page):
# url 网址
url = 'https://www.buxiuse.com/?page='.format(page)
# headers#
# response 发送请求,返回响应
response = requests.get(url,headers=headers).text
# print(response.text)
return response
# 2.提取数据
def dataEX(index):
"""数据提取 获取到在HTML里面的图片URL"""
# 数据初始化
doc = pq(index)
# 图片url的提取
height_min = doc('.height_min').items()# 转换成数据集
for i in height_min:
imgUrl = (i.attr('src'))
print(imgUrl)
ImgSave(imgUrl)
# 图片保存
# 请求图片地址 并且保存到本地 ab不覆盖保存 wb 二进制写入
def ImgSave(imgUrl):
global count
response = requests.get(imgUrl,headers=headers)
with open("./不羞涩小姐姐们/.jpg".format(count),"ab") as f:
f.write(response.content)
count += 1
if __name__ == '__main__':
for page in range(1,10):
index = RequestIndex(page)
dataEX(index)
以上是关于不羞涩社区图片爬取,我真的不是为了看小姐姐私照,从未这么渴望过知识!的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫实战为何如此痴迷Python?还不是因为爱看小姐姐图
Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片
Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片