爬虫经典教学,爬取小姐姐图片,太好看了!
Posted 不想秃头的里里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫经典教学,爬取小姐姐图片,太好看了!相关的知识,希望对你有一定的参考价值。
最近奇思妙想写了个爬虫教程,给大家送点福利,教大家爬取某站的小姐姐高清图片。(嘿嘿~我可能是个老se批,其实女生真的比男生更喜欢看美女)
先说好啊,技术无罪;这只是一个小案例教大家方法,当然也可以用这种方法爬取其他网站的图片。
本次爬取的网站地址在代码图片里有,这里就不放出来了。(狗头保命)。
效果预览
我们先来看看效果,最后运行爬取的结果是什么:
我这里用开发环境:
· 系统是Windows10 64位
· Python版本:Python3.6.5(Python3以上版本即可)
· 用的是Pycharm编辑器,主要用到的第三方库:requests、jsonpath 。

正式教程
一、 第三方库安装
在确保你正确安装了Python解释器之后,我们还需要安装几个第三方库,命令如下:
HTTP请求库:pip install requests
Xpath:pip install lxml
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。lxml是XML和html的解析器, 其主要功能是解析和提取XML和HTML中的数据。
fake-useragent:pip install fake-useragent
UserAgent是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换UserAgent可以避免触发相应的反爬机制。fake-useragent对频繁更换UserAgent提供了很好的支持,可谓防反扒利器。
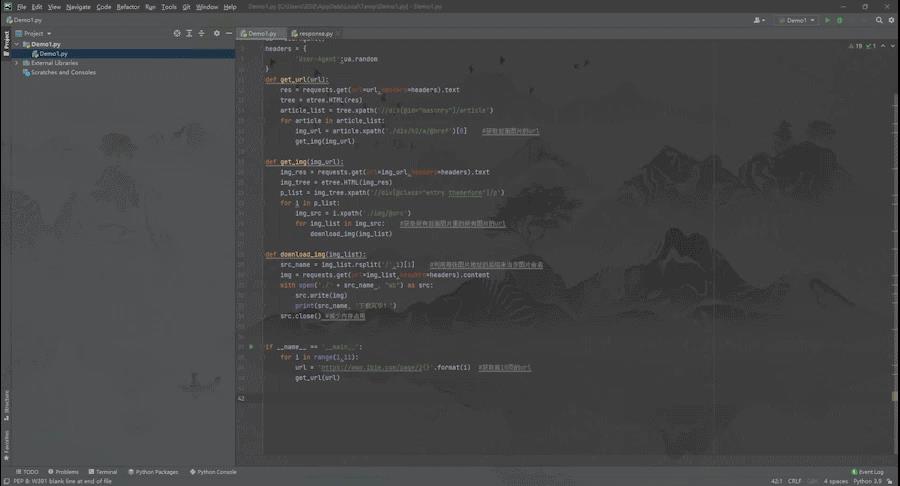
我把要导入的库先放出来

二、 爬虫的基本套路
请求数据 → 获取响应内容 → 解析内容 → 保存数据

1.分析站点:
检索网页发现每一张封面包括图片地址都在页面源代码中:
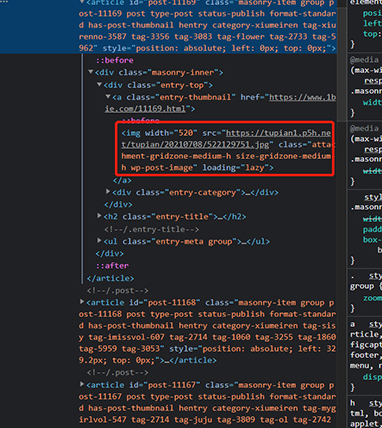
那么思路就很简单了,我们可以用xpath去获取每个封面的url,接着去访问每个封面的url去下载图片就可以啦。
2.请求网站获取数据:
编写代码请求资源,由于要下载多张图片,这里我们做个小措施,用fake-useragent模块去获取随机请求头。

上面说过了,我们要获取封面的url,那么我们把它封装在一个get_url函数中
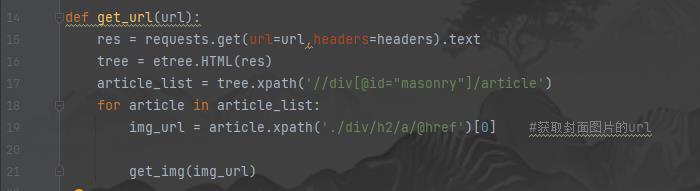
接着,我们把这些url去传入下一个函数,让下一个函数去访问这些地址,并获取所有图片的url

接下来就调用下一个函数来下载图片啦,用每个图片地址的后缀作为每张照片的命名:
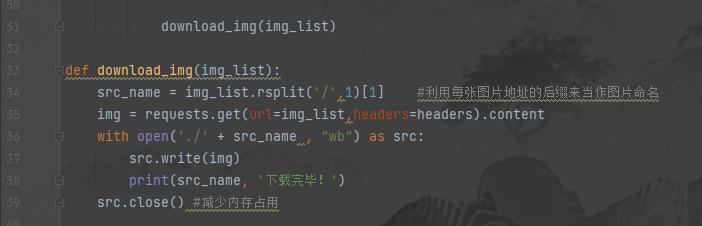
最后就用一个main函数来调用使得程序运行并下载图片,这里展示的是下载网页1-10页的所有照片:

到这里爬虫就写完了,这个只是一个小网站在练手而已,遇到别的网站的话,就具体情况具体分析,思路还是不变的,代码就因人而异啦,各人有个人的代码风格,这就是采用传统风格来下载图片。
有需要源码的伙伴们一键三连后,可以在评论区评论“源码”后私信我。

感谢每一位愿意读完我文章的人,对于新媒体创作我也在不断学习中。创作是一件非常值得持续投入的事情,因为你们每一次的支持都是对我极大的肯定!
再次感谢大家的支持,在此我整理了一些适合大多数人学习的资料,免费给大家下载领取!
看!干货在这里↓ ↓ ↓

有需要的读者可以直接拿走,在我的QQ学习交流群。有学习上的疑问、或者代码问题需要解决的,想找到志同道合的伙伴也可以进群,记住哦仅限学习交流!!!
裙号是:298154825。
以上是关于爬虫经典教学,爬取小姐姐图片,太好看了!的主要内容,如果未能解决你的问题,请参考以下文章