scrapy框架中的Request对象以及Response对象的介绍python爬虫入门进阶(19)
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy框架中的Request对象以及Response对象的介绍python爬虫入门进阶(19)相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当,持续更新中 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

文章目录
前言
这篇文章主要是简单介绍一下Request对象以及Response对象。
Request对象
Request对象主要是用来请求数据,爬取一页的数据重新发送一个请求的时候调用,其源码类的位置如下图所示:
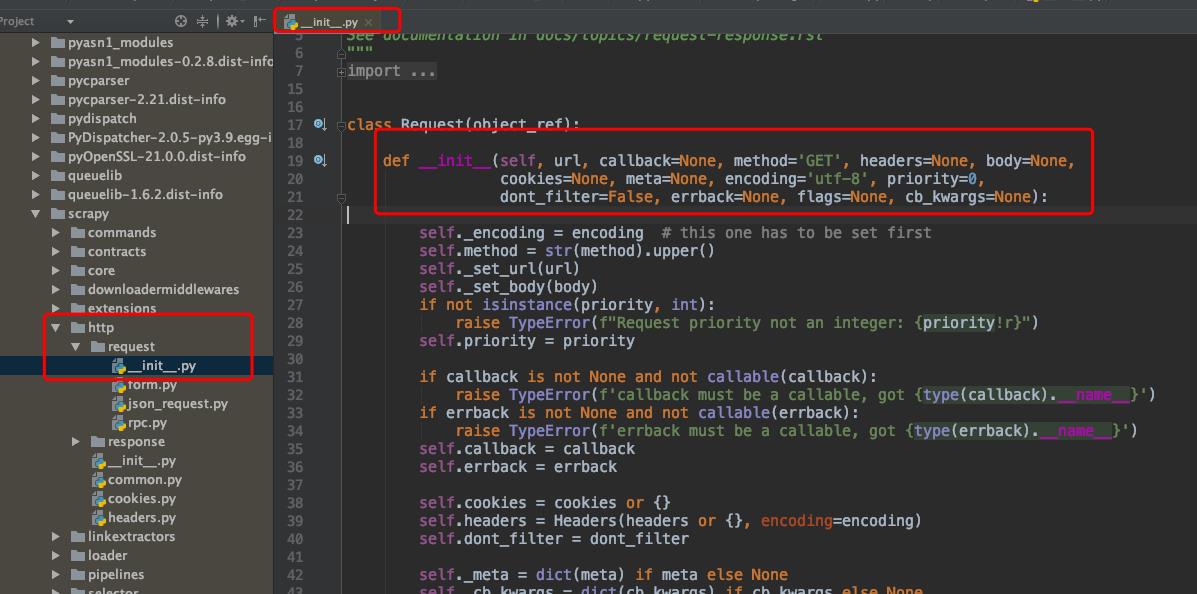
这里给出其的源码,该方法有很多参数。
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
if not isinstance(priority, int):
raise TypeError(f"Request priority not an integer: priority!r")
self.priority = priority
if callback is not None and not callable(callback):
raise TypeError(f'callback must be a callable, got type(callback).__name__')
if errback is not None and not callable(errback):
raise TypeError(f'errback must be a callable, got type(errback).__name__')
self.callback = callback
self.errback = errback
self.cookies = cookies or
self.headers = Headers(headers or , encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
self._cb_kwargs = dict(cb_kwargs) if cb_kwargs else None
self.flags = [] if flags is None else list(flags)
这里对各个做一个简单的解释:
- url :这个request对象发送请求的url。
- callback: 在下载器下载相应的数据后执行的回调函数。
- method:请求的方法,默认为GET方法,可以设置为其他方法。
- headers:请求头,对于一些固定的设置,放在settings.py中指定就可以了, 对于那些非固定的,可以在发送请求的时候指定。
- body:请求体,传入的是请求参数。
- meta:比较常用。用于在不同的请求之间传递数据用。
- encoding:编码。默认为utf-8,使用默认的就可以了。
- dont_filter: 表示不由调度器过滤,在执行多次重复的请求的时候用得比较多。
- errback:在发生错误的是有执行的函数。
发送POST请求
有时候我们想要在请求数据的时候发送post请求,那么这时候需要使用Request的子类FormRequest来实现。如果想要在爬虫一开始就发送POST请求,那么需要在爬虫类中重写start_requests(self) 方法,并且不在调用 start_urls 里的url。
Response对象
Response对象一般是由scrapy给你自动构建的,因此开发者不需要关心如何创建Response对象。而是如何使用它。Response对象有很多属性,可以用来提取数据的。主要有以下属性:
- meta: 从其他请求传过来的meta属性,可以用来保持多个请求之间的数据连接。
- encoding: 返回字符串编码和解码的格式。
- text: 将返回来的数据作为unicode字符串返回
- body: 将返回来的数据作为bytes 字符串返回。
- xpath: xpath 选择器
- css : css选择器。
总结
本文简单的介绍了下scrapy框架中的Request对象以及Response对象。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于scrapy框架中的Request对象以及Response对象的介绍python爬虫入门进阶(19)的主要内容,如果未能解决你的问题,请参考以下文章
调度 engine._next_request_from_scheduler() 取出request交给handler,结果是request,执行engine.craw(),结果是resp/fail,