CS231N课程作业Assignment1--KNN
Posted 鲁棒最小二乘支持向量机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS231N课程作业Assignment1--KNN相关的知识,希望对你有一定的参考价值。
Assignment1–KNN
作业要求见这里.
主要需要完成 KNN,SVM,Softmax分类器,还有一个两层的神经网络分类器的实现。
数据集CIFAR-10.
KNN原理
K近邻算法(KNN)算法是一种简单但也很常用的分类算法,它也可以应用于回归计算。KNN是无参数学习,这意味着它不会对底层数据的分布做出任何假设。它是基于实例,即该算法没有显式地学习模型。相反,它选择的是记忆训练实例,并在一个有监督的学习环境中使用。KNN算法的实现过程主要包括距离计算方式的选择、K值得选取以及分类的决策规则三部分。
距离计算方式的选择:一般选择欧氏距离或曼哈顿距离。
K值的选取:在计算测试数据与各个训练数据之间的距离之后,首先按照距离递增次序进行排序,然后选取距离最小的k个点。 一般会先选择较小的k值,然后进行交叉验证选取最优的k值。k值较小时,整体模型会变得复杂,且对近邻的训练数据点较为敏感,容易出现过拟合。k值较大时,模型则会趋于简单,此时较远的训练数据点也会起到预测作用,容易出现欠拟合。
分类的决策规则:常用的分类决策规则是取k个近邻训练数据中类别出现次数最多者作为输入新实例的类别。即首先确定前k个点所在类别的出现频率,对于离散分类,返回前k个点出现频率最多的类别作预测分类;对于回归则返回前k个点的加权值作为预测值。
构建KNN分类器
程序整体框架如下:包括classifiers和datasets文件夹,knn.py、data_utils.py和k_nearest_neighbor.py
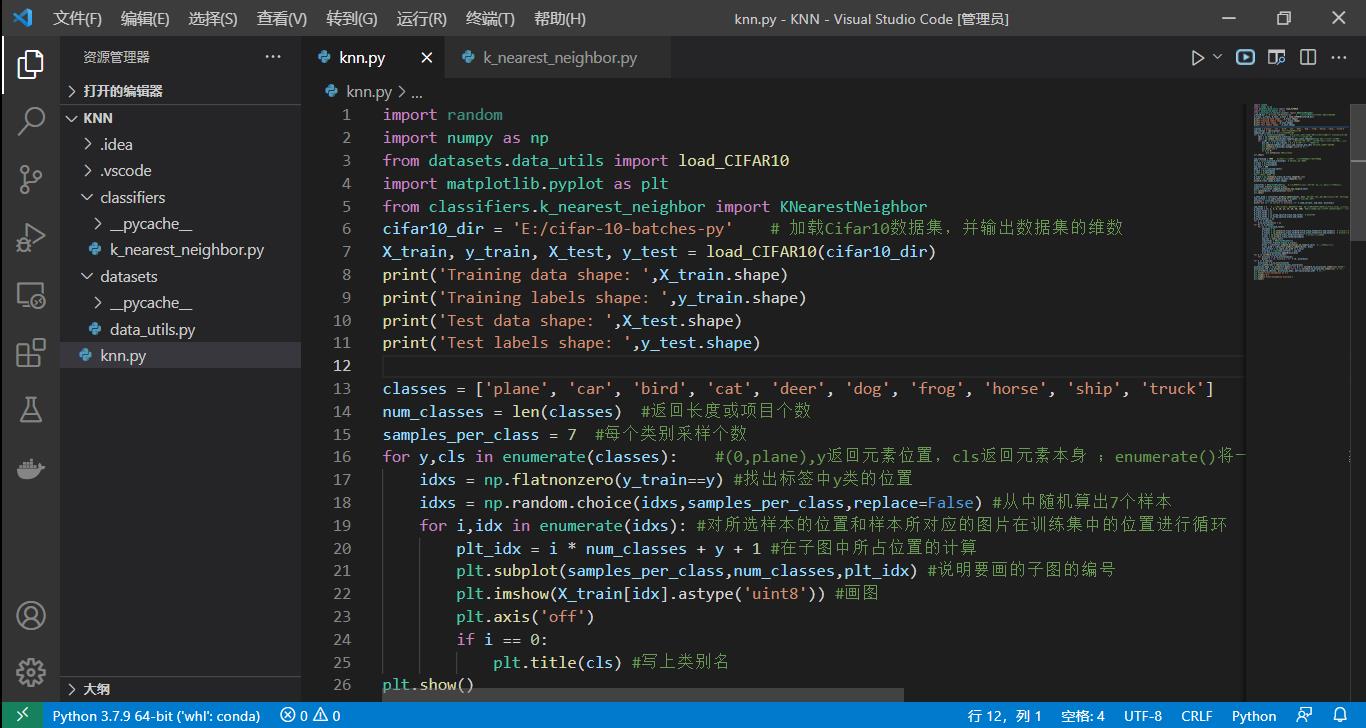
knn.py
import random
import numpy as np
from datasets.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
from classifiers.k_nearest_neighbor import KNearestNeighbor
cifar10_dir = 'E:/cifar-10-batches-py' # 加载Cifar10数据集,并输出数据集的维数
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
print('Training data shape: ',X_train.shape)
print('Training labels shape: ',y_train.shape)
print('Test data shape: ',X_test.shape)
print('Test labels shape: ',y_test.shape)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes) #返回长度或项目个数
samples_per_class = 7 #每个类别采样个数
for y,cls in enumerate(classes): #(0,plane),y返回元素位置,cls返回元素本身 ;enumerate()将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标
idxs = np.flatnonzero(y_train==y) #找出标签中y类的位置
idxs = np.random.choice(idxs,samples_per_class,replace=False) #从中随机算出7个样本
for i,idx in enumerate(idxs): #对所选样本的位置和样本所对应的图片在训练集中的位置进行循环
plt_idx = i * num_classes + y + 1 #在子图中所占位置的计算
plt.subplot(samples_per_class,num_classes,plt_idx) #说明要画的子图的编号
plt.imshow(X_train[idx].astype('uint8')) #画图
plt.axis('off')
if i == 0:
plt.title(cls) #写上类别名
plt.show()
num_training = 5000 #选取后续实验子集 训练集5000张,测试集500张
mask = list(range(num_training)) # 将元组转换为列表
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
#将图像数据转置成二维
X_train = np.reshape(X_train,(X_train.shape[0],-1))
X_test = np.reshape(X_test,(X_test.shape[0],-1))
print(X_train.shape,X_test.shape)
classifier = KNearestNeighbor() # 创建KNN分类器对象,并测试一下使用双层循环计算欧氏距离
classifier.train(X_train,y_train)
dists = classifier.compute_distances_two_loops(X_test)
plt.imshow(dists, interpolation='none')
plt.show()
y_test_pred = classifier.predict_labels(dists, k=1) #K设置为1(也就是最邻近法)测试一下准确率
num_correct = np.sum(y_test_pred == y_test) # sum()求和运算
accuracy = float(num_correct)/num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
num_folds = 5 # 使用交叉验证选出最优的超参数K 将训练数据切分,存储在X_train_folds和y_train_folds中
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100] #交叉验证就是将训练集分为N等分,取其中一份作为验证集,其他作为训练集。每个等分分别做一次验证集,实现交叉验证。交叉验证可以减少过拟合
X_train_folds = []
y_train_folds = []
X_train_folds = np.array_split(X_train,num_folds) # 均等分割
y_train_folds = np.array_split(y_train,num_folds)
k_to_accuracies =
for i in k_choices:
k_to_accuracies[i] = []
for ki in k_choices:
for fi in range(num_folds):
valindex = fi
X_traini = np.vstack((X_train_folds[0:fi]+X_train_folds[fi+1:num_folds])) # vstack():次外层垂直方向堆叠
y_traini = np.hstack((y_train_folds[0:fi]+y_train_folds[fi+1:num_folds])) # hstack():次外层水平方向堆叠
X_vali = np.array(X_train_folds[valindex]) # array():创建数组
y_vali = np.array(y_train_folds[valindex])
num_val = len(y_vali)
classifier = KNearestNeighbor()
classifier.train(X_traini,y_traini)
dists = classifier.compute_distances_no_loops(X_vali) # 使用0层循环距离
y_val_pred = classifier.predict_labels(dists, k=ki)
num_correct = np.sum(y_val_pred == y_vali)
accuracy = float(num_correct) / num_val
k_to_accuracies[ki].append(accuracy)
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies),accuracies)
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())]) #平均值
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())]) #标准差
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std) # 误差图
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
k_nearest_neighbor.py
import numpy as np #导入numpy的库函数
class KNearestNeighbor(object): # 使用L2距离的KNN分类器
def _init_(self):
pass
def train(self, X, y): # KNN 训练:读取数据并存储;不对训练集做处理,单纯保存下来
self.X_train = X # X : 是一个numpy类型的数组,维数是(num_train,D)
self.y_train = y # y : 是一个numpy类型的数组,维数是(N,)
def predict(self, X, k=1, num_loops=0): # 选择计算距离的循环的方式来预测y的值;X :一个numpy类型的数组,维数是(num_test,D);k : 选择距离最小的数量;num_loops : 循环的方式
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_no_loops(X)
elif num_loops == 2:
dists = self.compute_distances_no_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k=k) # 返回 y : 一个numpy类型的数组(num_test,)
def compute_distances_two_loops(self, X): #使用两层循环来计算测试数据与每一个训练数据之间的距离
num_test = X.shape[0] # X :一个numpy类型的数组,维数(num_test,D) shape函数:查看矩阵或者数组的维数
num_train = self.X_train.shape[0] # shape(0)读取矩阵第一维度的长度,相当于行数
dists = np.zeros((num_test, num_train)) #zeros()创建数组,数组元素类型是浮点型
for i in range(num_test): # range()函数:数字迭代器,代表一组数字序列
for j in range(num_train):
train = self.X_train[j,:]
test = X[i,:]
distances = np.sqrt(np.sum((test-train)**2)) #L2距离
dists[i,j] = distances
return dists # 返回 dists : 一个numpy类型的数组,维数(num_test,num_train),dists[i,j]存储了test[i]到train[j]之间的距离
def compute_distances_one_loops(self, X): #使用一层循环来计算测试数据与每一个训练数据之间的距离
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
distances = np.sqrt(np.sum(np.square(self.X_train - X[i]), axis=1))
dists[i, :] = distances
return dists
def compute_distances_no_loops(self, X): #计算距离不使用循环
M = np.dot(X, self.X_train.T)
nrow = M.shape[0]
ncol = M.shape[1]
te = np.diag(np.dot(X, X.T)) # diag()构造一个对角矩阵;dot()矩阵乘法
tr = np.diag(np.dot(self.X_train, self.X_train.T))
te = np.reshape(np.repeat(te, ncol), M.shape) # reshap()重新定义了原张量的阶数;shape()表示张量的形状
tr = np.reshape(np.repeat(tr, nrow), M.T.shape) # repeat() 将数组重复n次
sq = -2 * M + te + tr.T
dists = np.sqrt(sq)
return dists
def predict_labels(self, dists, k=1): #根据距离和K的数量来预测测试数据的标签
num_test = dists.shape[0] #输入 dists : 一个numpy类型的数组,维数(num_test,num_train);k : 根据 k 个最小距离进行预测
y_pred = np.zeros(num_test)
for i in range(num_test):
distances = dists[i, :]
indexes = np.argsort(distances) #argsort()函数:返回的是数组值从小到大的索引值,升序排列
closest_y = self.y_train[indexes[:k]]
count = np.bincount(closest_y) #bincount()函数:计算非负int数组中每个值的出现次数
y_pred[i] = np.argmax(count) #argmax()函数:取出最大值对应的索引
return y_pred # y : 一个numpy类型的数组,维数(num_test,)
data_utils.py
from __future__ import print_function
from builtins import range
from six.moves import cPickle as pickle
import numpy as np
import os
from imageio import imread
import platform
def load_pickle(f):
version = platform.python_version_tuple() # 获取计算机Python的版本信息
if version[0] == '2':
return pickle.load(f)
elif version[0] == '3':
return pickle.load(f, encoding='latin1')
raise ValueError("invalid python version: ".format(version))
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb') as f: # 二进制形式打开文件
datadict = load_pickle(f)
X = datadict['data']
Y = datadict['labels']
X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y = np.array(Y)
return X, Y
def load_CIFAR10(ROOT):
""" load all of cifar """
xs = []
ys = []
for b in range(1,6):
f = os.path.join(ROOT, 'data_batch_%d' % (b, ))
X, Y = load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
Xtr = np.concatenate(xs)
Ytr = np.concatenate(ys)
del X, Y
Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch'))
return Xtr, Ytr, Xte, Yte
本文希望对大家有帮助,当然上文若有不妥之处,欢迎指正。
分享决定高度,学习拉开差距
以上是关于CS231N课程作业Assignment1--KNN的主要内容,如果未能解决你的问题,请参考以下文章
全球名校课程作业分享系列(10)--斯坦福CS231n之Network visualization
全球名校课程作业分享系列(10)--斯坦福CS231n之Network visualization