深度理解特斯拉自动驾驶解决方案 2:向量空间
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度理解特斯拉自动驾驶解决方案 2:向量空间相关的知识,希望对你有一定的参考价值。
从理论到现实,分析特斯拉全自动驾驶的演变

这是我深入了解特斯拉FSD系列的第二篇文章。
在前一篇文章中,我们讨论了特斯拉神经网络HydraNet的架构。目前HydraNet只能处理来自单个摄像机的输入。
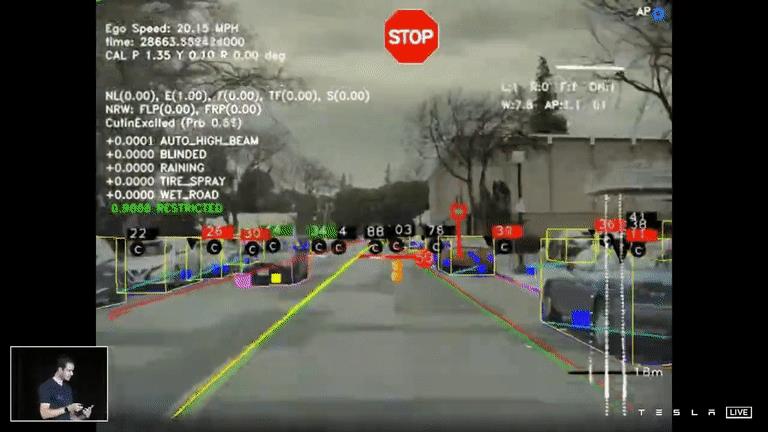
向量空间
当特斯拉的AI团队致力于FSD时,他们很快发现这是不够的。他们需要更多的摄像机,感知系统的预测结果必须转化为三维空间,这也是Plan & Control系统的基础。特斯拉将这种3D空间称为“向量空间”。将车辆及其所在空间的位置、速度、车道、标志、信号灯、周围物体等信息数字化,并在该空间中可视化。

入住率追踪
他们用c++开发了一个名为“入住率跟踪”的系统。该系统从图像中拼接出路缘检测,跨越摄像机场景、摄像机边界和时间。但是这个设计有两个问题:
问题1:跨摄像机融合和跟踪器很难明确写入。调整占用跟踪器及其所有超参数是极其复杂的。手工调优c++程序对每个程序员来说都是一场噩梦。
问题2:图像空间不是正确的输出空间。你应该在向量空间中而不是在图像空间中进行预测。

如上所述,采用逐相机检测然后融合的方法,问题是每个相机都有很好的预测结果,但将它们抛到向量空间后,精度损失严重。(见上图底部投影中的红蓝线)。这样做的根本原因是,你需要有一个非常精确的每像素深度来做这个投影。要在如此微小的图像中精确地预测深度是非常困难的。
在图像空间(逐镜头检测然后融合)中,无法解决以下两种场景:
- 预测被遮挡区域
- 预测更大的物体(一个物体跨越两个以上的相机,最多五个相机)。
对这两种情况的预测都非常糟糕。如果处理不当,它们甚至会导致致命的交通事故。
现在是改变设计理念的时候了:“我们想把所有的图像同时输入到一个单一的神经网络中,然后直接输出到向量空间中。”我很钦佩特斯拉的AI团队,他们能想出这样一个简单而优雅的解决方案。也许这正是埃隆·马斯克倡导的第一原则思想的结果。
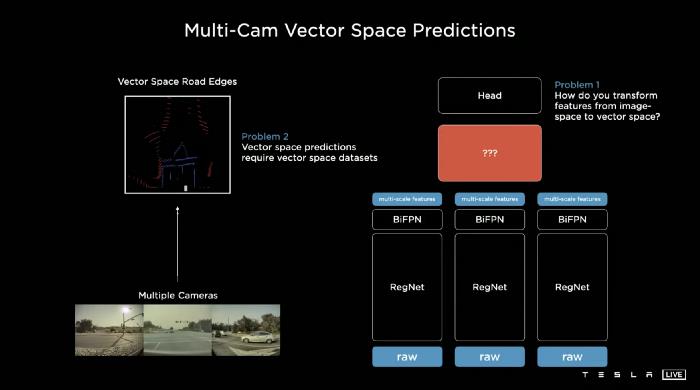
一般来说,特斯拉人工智能团队想要布局一个神经网络,如上图右侧所示。它对每一个具有主干的图像进行处理,并将其从图像空间特征重新表示为向量特征,最后进入头部解码。
这里有两个难点:
- 如何将特征从图像空间转换到向量空间?以及如何将其区分开来,使端到端的培训成为可能。深度学习算法被建模为针对我们试图学习的函数的凸优化问题。我们所有的优化方法只有在函数是可微的情况下才有效。
- 如果你想从你的神经网络中预测向量空间,你需要基于特定向量的数据集。我将在下一篇文章中详细讨论这个问题。
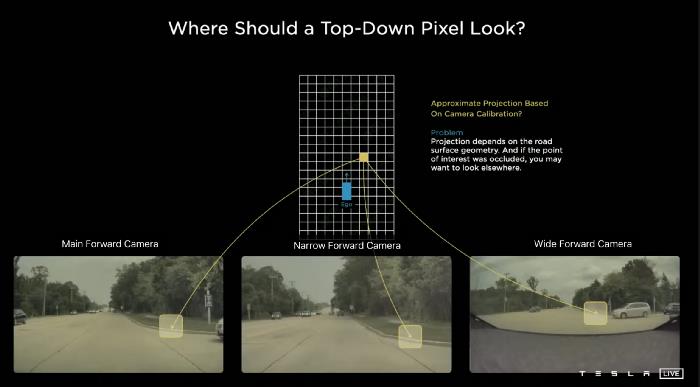
特斯拉的人工智能团队使用的是鸟瞰图(BEW)预测,而不是图像空间预测。例如,在上图中,输出空间中的一个黄色像素来自于特斯拉前面的三个摄像头(主前向摄像头、窄前向摄像头、宽前向摄像头)检测到的道路边缘的投影。这种投影取决于路面的几何形状,如果感兴趣的点被遮挡,您可能想要查看其他地方。对于这个组件,实际上很难得到正确的和固定的转换。
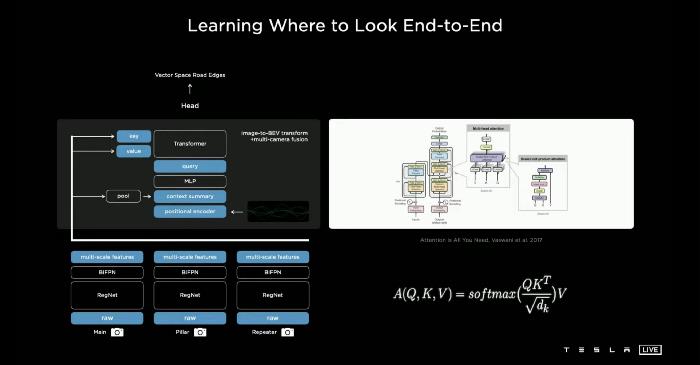
为了解决这个问题,特斯拉人工智能团队使用了一个Transformer来代表这个空间,这个Transformer使用了多头自我注意,并将其隔开。
Transformer

这个Transformer不是动画片《变形金刚》里的机器人。这是近年来最受关注的深度学习模型。它在谷歌论文《Attention Is All You Need》中首次被提到,主要用于自然语言处理(NLP)领域。
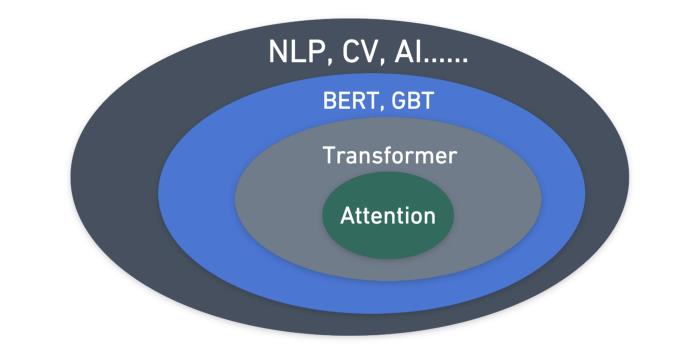
Transformer的核心是注意力机制。BERT、GPT和其他模型都基于Transformer。这些以注意机制为核心的模型广泛应用于自然语言处理、CV、人工智能等任务中。
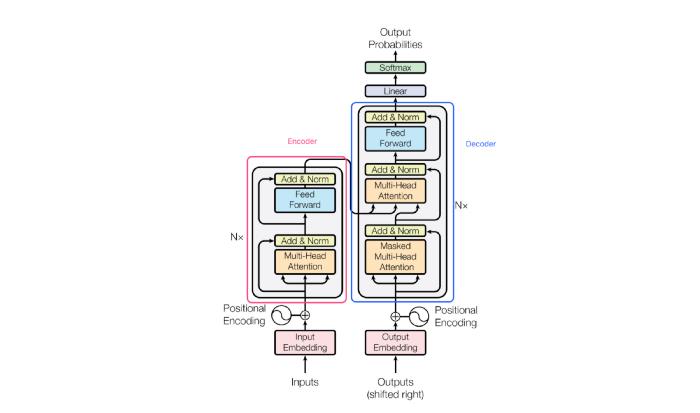
通常,Transformer有一个编码器-解码器结构。编码器/解码器由一组相同的层组成。每个编码器层主要包括多头注意层和前馈层;每个解码器层包含两个多头注意层和一个前馈层。
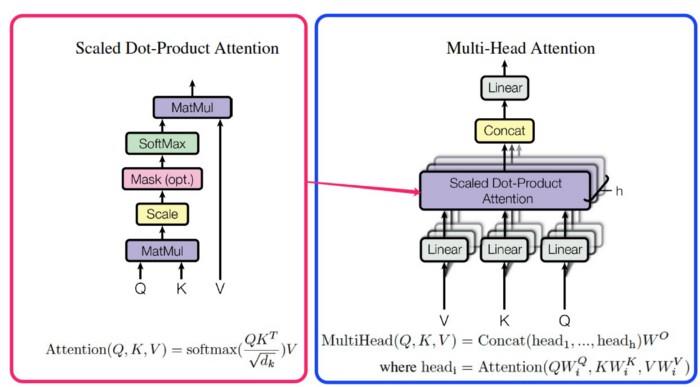
注意函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是通过查询与相应键的兼容性函数计算的。
注意有很多种类型:软注意、硬注意、自我注意、点积注意、单一注意、多头注意。本文的注意机制是由多个点积注意组成的。
回到特斯拉案例
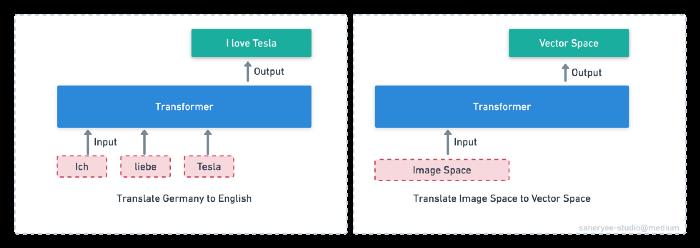
从图像空间到向量空间,我们可以类比从一种语言到另一种语言的翻译过程。如上所示,由于Transformer在自然语言翻译方面有如此优异的性能,我们是否可以用它来将Image Space“翻译”为Vector Space?
如何训练这个Transformer?
结合Andrej的讲解和Transform Paper,下图是我对这种Transformer培训过程的理解。
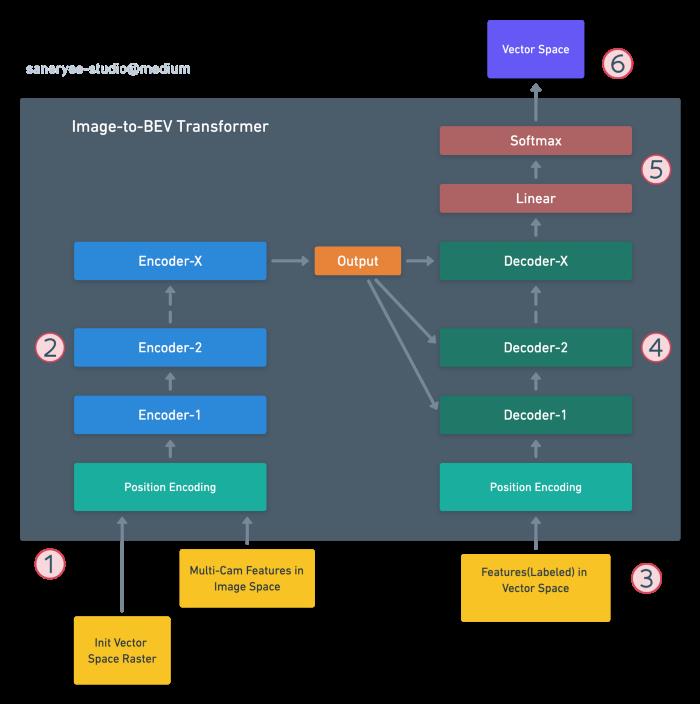
Image-to-BEV Transformer的训练过程如下:
- 初始化一个输出空间大小的光栅:Output Space Raster,位置编码输出空间光栅上的点和所有的图像及其特征,并馈送给编码器。
- 编码器堆栈(带有多头自注意)处理这个过程,并生成Init Vector Space光栅的编码表示。
- 目标BEV(具有向量空间特征)通过位置编码进行转换并馈送给解码器。
- 解码器堆栈与编码器堆栈的编码表示一起处理它,以产生目标BEV的编码表示。
- 输出层将其转换为BEV特征和输出向量空间(BEV)。
- Transformer的Loss函数将输出序列与训练数据中的目标序列进行比较,计算损失用于产生梯度,通过反向传播来训练Transformer。
推理
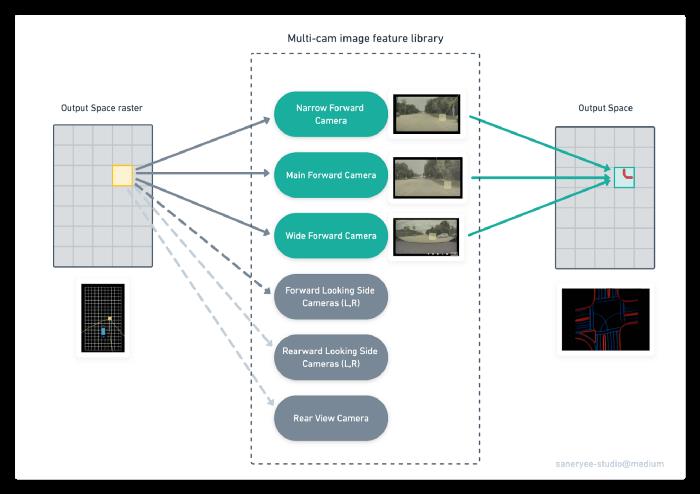
在特斯拉的实践中,如上面的例子所示,使用Transformer将Image Space转换为Vector Space的过程可以简单总结为以下步骤:
- 初始化一个栅格大小的输出空间:Output Space Raster
- 对输出空间光栅上的点进行了位置编码。接下来,用多层感知器(MLP)编码成一组查询向量。例如黄色的点。
- 所有的图像(来自8个摄像头)和它们的功能也会发出它们自己的键和值。(图中多凸轮图像特征库部分)
- 这些键和查询进行乘法(Transformer中的点积注意)交互,在Multi-Cam图像特征库中进行搜索,并将结果输出到向量空间。
您可以这样理解它:首先,您问Transformer网络,我是输出空间(向量空间)中这个位置的一个像素(黄色点)。我正在寻找这种类型的特征。你(8个摄像机)看到了什么?此时,有三个摄像头响应这个位置是道路边缘。经过更多的处理,最后,在向量空间中输出该位置的道路边缘。
初始向量空间栅格上的每个像素都是这样处理的,所有转换后的像素构成一个完整的向量空间谜题。
特斯拉的AI团队已经证明了这种转变是非常有效的。
虚拟摄像头
因为特斯拉的8相机的参数是不同的:焦距,视角,景深,安装位置是不同的,同一对象在不同的相机是不一样的,这样的数据不能直接用于训练,在训练之前,我们需要规范8相机成一个合成虚拟摄像机。
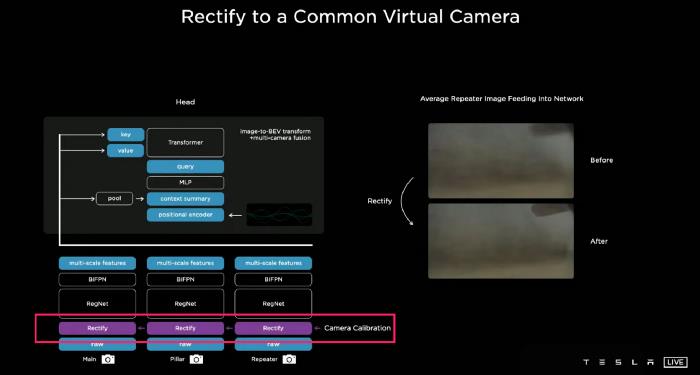
他们在图像校正层的正上方插入一个新层,这是相机校准的功能,它将所有的图像转换成一个虚拟的普通相机。经过校正变换后,之前模糊的图像会变得清晰。这大大提高了性能。
比较

面的图片是一些结果,直接来自神经网络的预测有明显的改进。这是一个多摄像机网络直接在向量空间预测。多摄像头网络的另一个好处是,它改善了目标检测,特别是当你只看到一辆车的一小部分,或者在一个狭小的空间里,汽车跨越摄像头的边界。
视频神经网络体系结构
上面我们得到了一个基于矢量空间的多摄像头网络解决方案,但为了实现最终的自动驾驶,我们需要在网络中添加另一个维度:时间。
在自动驾驶中,除了检测车辆、信号灯、道路边缘、标志和其他物体外,我们还需要预测:这辆车是否停在那里,它是否在移动,移动速度有多快,即使暂时被遮挡,它是否仍然在那里。有时候,我们也需要记住开车的情况。
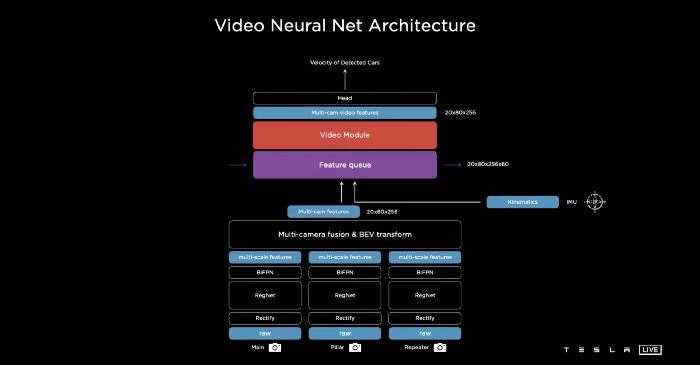
因此,特斯拉的人工智能团队试图在神经网络架构中插入两个模块:一个是特征队列模块,它将随着时间的推移缓存一些特征,另一个是视频模块,它将暂时融合这些信息。除了来自8个摄像机的信息外,它们还将运动学、惯性测量单元(IMU)输入网络。运动学信息基本上是速度和加速度。从这里我们可以看到这个版本的特斯拉AI只使用了8个摄像头和IMU。
特征队列

如上所示,它是Feature Queue的布局。基本上有三种队列:自我运动学、多凸轮特性和位置编码。它被连接、编码并存储在一个特征队列中,并将被视频所消耗。正如我们所知,队列的操作使其成为先进先出(FIFO)的数据结构。在特斯拉的AI案例中,队列的弹出和推送机制非常重要。特别是什么时候将数据推入特征队列?
有两种队列推送机制:基于时间的队列(内存时间序列上的信息)和基于空间的队列(内存空间上的信息)。
基于时间的队列
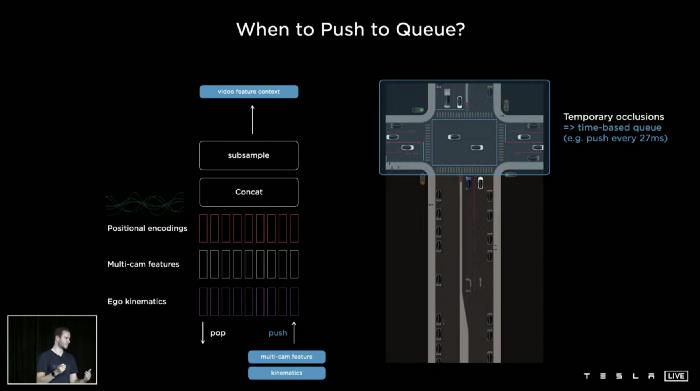
如上图所示,自我车来到十字路口,前面的交通开始过马路,它会暂时阻塞前面的一些车。我的车在这个十字路口停了一会儿,等着轮到我们。
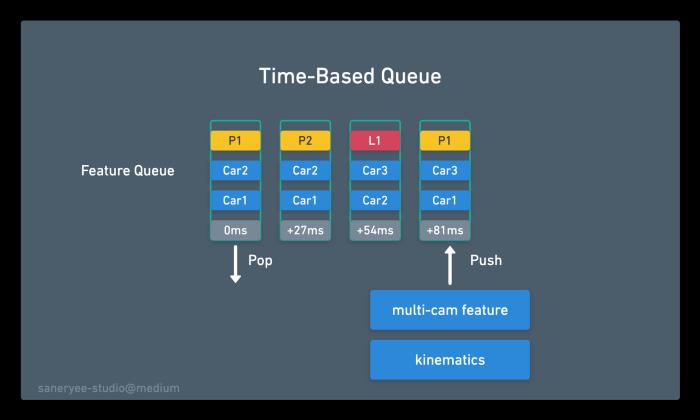
那时,我们需要某种基于时间的队列,例如,我们每27毫秒输入一个特性到队列中。(每帧采样,特斯拉相机参数为1280x960@36Hz,每帧间隔为1/36 = 0.0277秒= 27毫秒)。如果一辆汽车暂时被遮挡,神经网络有能力及时查看和引用记忆。即使这个东西现在看起来是被遮挡的,在之前的特征中有它的记录,神经网络仍然可以使用它来进行检测。
基于空间的队列
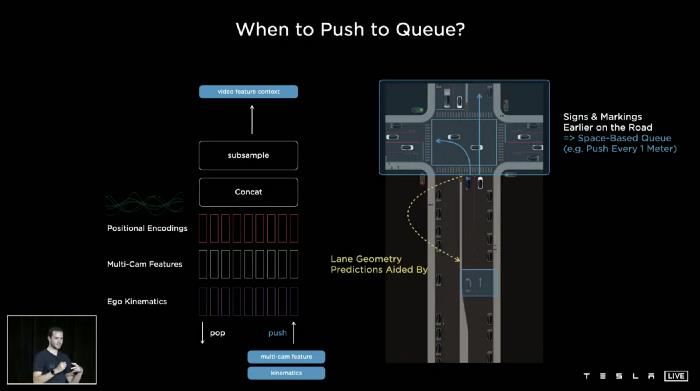
如上图所示,你试图预测你在转弯车道上,而你旁边的车道是直的。那时,真的有必要了解线路标记和标志(车道几何,左转标志)。有时候,它们发生在很久以前,如果你只有一个基于时间的队列,你可能会在等待红灯的时候忘记这些特征。因此,特斯拉的人工智能团队使用了一种基于空间的队列,每当汽车行驶一定距离(每1米)时,就会推送队列。
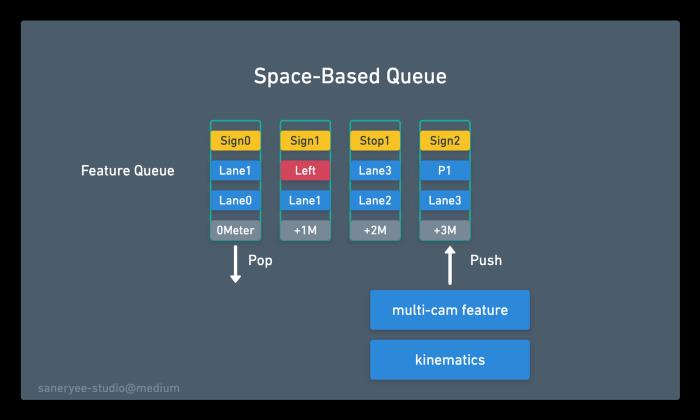
因此,特斯拉AI团队有一个基于时间的队列和一个基于空间的队列来缓存功能,并继续进入视频模块。
视频模块
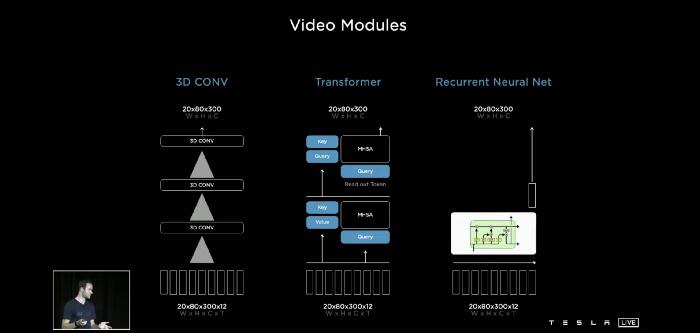
对于视频模块,有很多可能的方法来融合这些信息:3d卷积、Transformer、Axial Transformers、循环神经网络和空间RNN。在其中,特斯拉AI团队实际上也非常喜欢空间循环神经网络(Spatial RNN)。
RNN & LSTM & GRU
在介绍空间RNN之前,我们首先了解了循环神经网络(RNN)、长短期记忆(LSTM)和门控循环单元(GRU)。
递归神经网络(RNN)是一种处理顺序数据的神经网络。主要用于自然语言处理(NLP)。RNN是一种具有环状结构的神经网络。
虽然RNN使网络有记忆,但它只有短期记忆,不能记住“远距离”的信息。因为长时记忆需要RNN使用更多的RNN单元,这会导致梯度消失问题,使其不能有长时记忆。
门控循环单元(Gated Recurrent Unit, GRU)是对RNN隐藏层的修改,使其在捕获远程连接时表现得更好,并在很大程度上帮助解决渐变消失问题。
另一种可以同时拥有长期和短期记忆的记忆单元是LSTM,也就是长短期记忆。它甚至比GRU更强大。
GRU和LSTM都是RNN的变体。它们都有门控机制,而GRU可以看作是LSTM的简化版本。
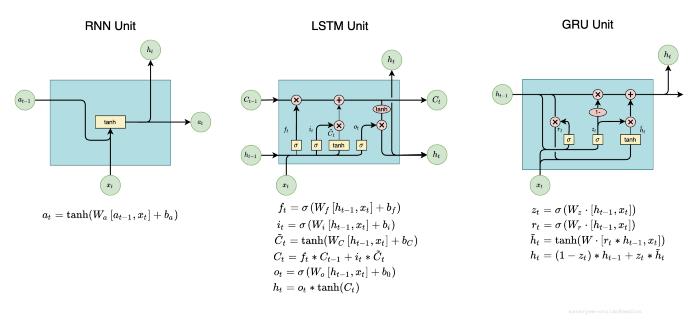
有关RNN的更多详细信息,请阅读文章:理解LSTM网络。
空间RNN
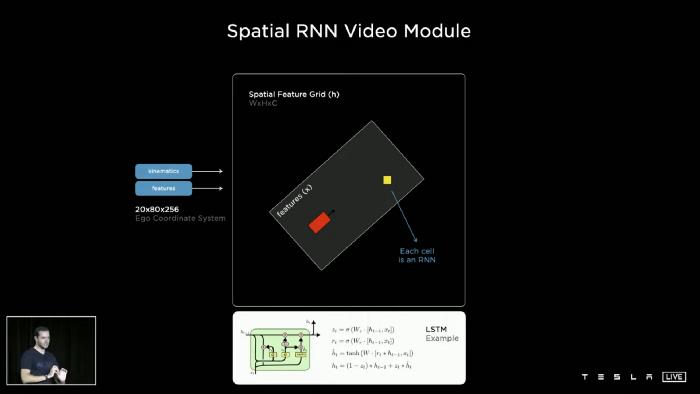
回到特斯拉AI日,因为网络也需要有长期记忆,所以需要使用rnn。从上面的截图中,我们可以看到Spatial RNN的单元看起来像使用了GRU单元结构。
为什么特斯拉使用GRU而不是LSTM?
我想对于LSTM来说,GRU的参数更少,收敛速度更快,所以实际上花费的时间更少,计算能力也更低。而这部分需要在板载芯片上快速完成,计算能力有限。因此,在这个阶段,特斯拉AI团队选择了一个相对简单的GRU,而不是一个LSTM或更复杂的结构。
具体来说,在特斯拉的自动驾驶结构中,我们是在二维平面上驾驶。Telsa AI团队实际上将隐藏状态组织成一个二维格子。当汽车在周围行驶时,网络只更新汽车附近的部分以及汽车可见的位置。他们使用运动学来整合汽车在隐藏特征网格中的位置并且只在我们附近的点更新RNN。
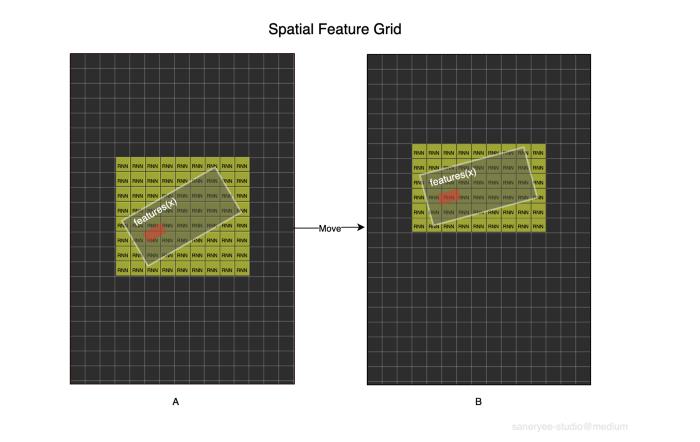
如图所示,每个格子都有一个RNN网络,红色矩形表示自我车,白色矩形表示自我车周围一定范围内的特征。当自我车从A位置移动到B位置时,特征框也随之移动。此时,我们只需要更新feature框所覆盖的黄色框中的rnn。
Spatial RNN的实际性能很好,见下图。
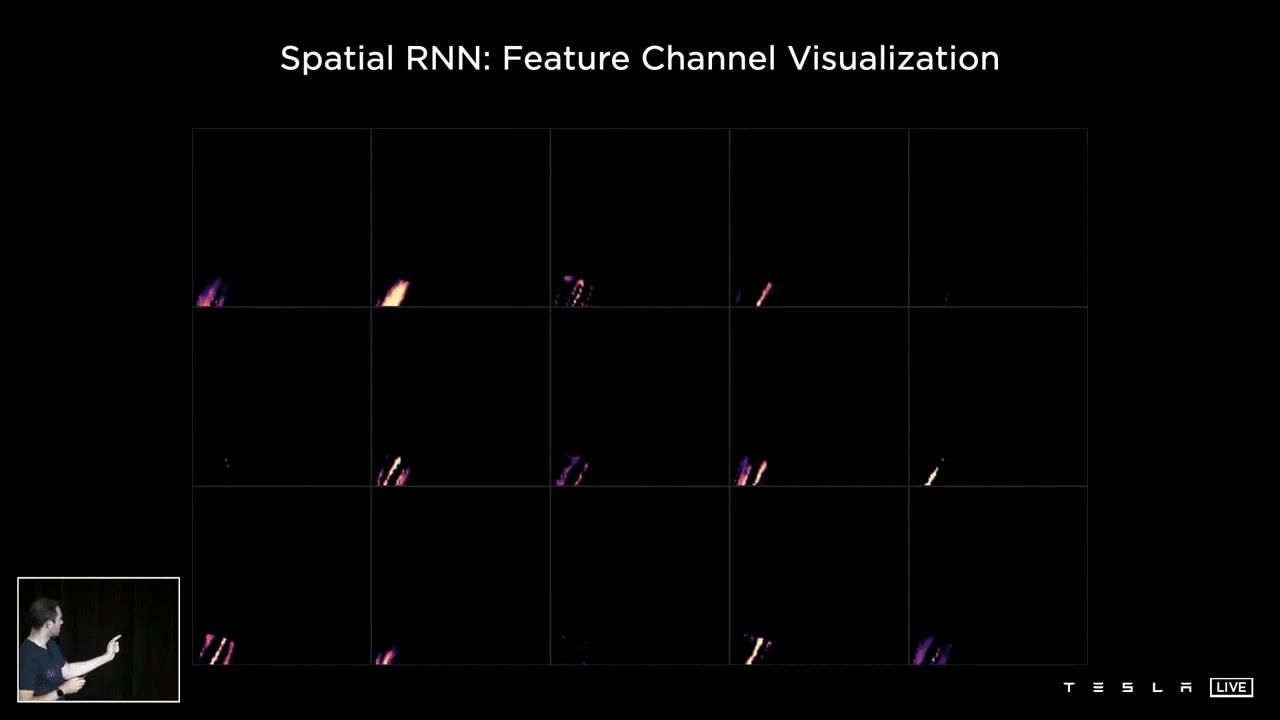
这个例子显示了不同的通道在空间RNN的隐藏状态。在这15个通道中,你可以看到道路的中心、边缘、线条、路面等等。
这是一个例子,我们在看这个RNN的隐藏状态,这些是隐藏状态下的不同通道,所以你可以看到,这是优化和训练这个神经网络之后,你可以看到一些通道跟踪道路的不同方面,比如道路的中心,边缘,线条,路面等等。
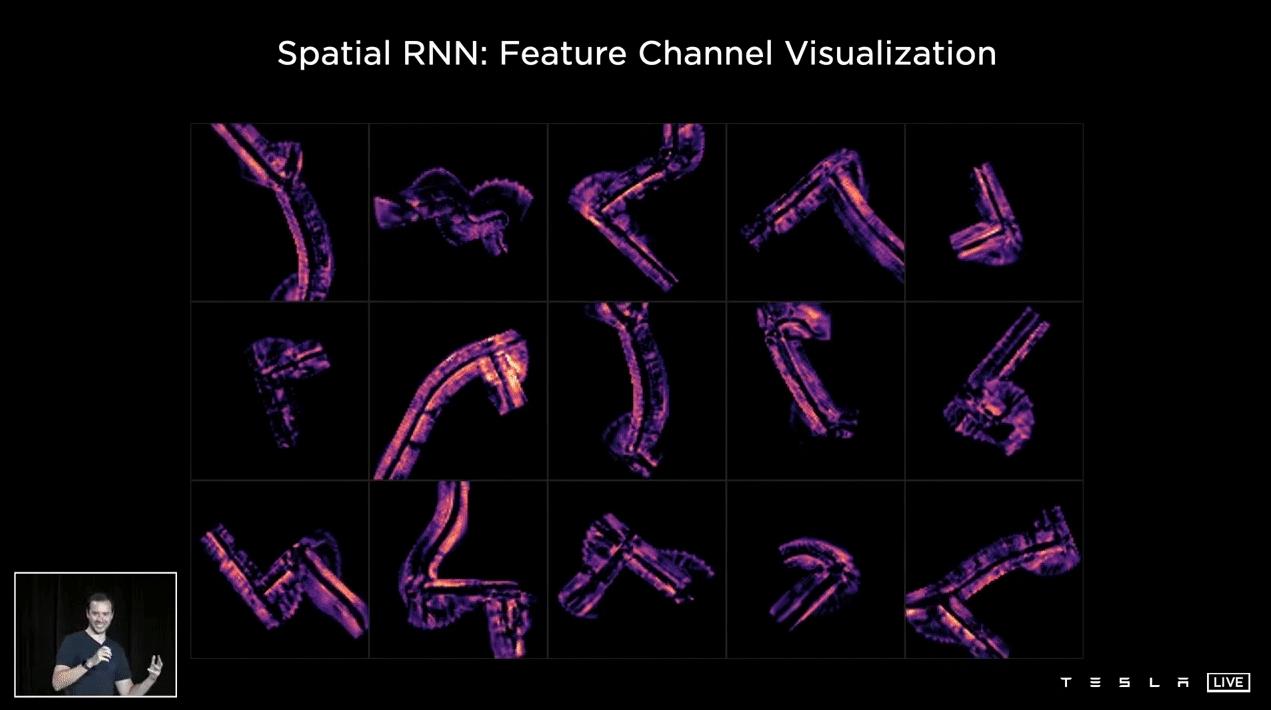
这个例子显示了不同交叉口的不同遍历前10个处于隐藏状态的通道的平均值。因为RNN一直在跟踪任何时间点发生的事情。神经网络有能力选择性地读写这些记忆。例如,如果有一辆车就在我们旁边,并且阻塞了道路的某些部分,网络有能力不写入这些位置。当汽车离开,我们有一个很好的视野,RNN肯定想要写关于空间中有什么信息。这样您可以看到关于驾驶的特征信息是完整的,不会因为临时遮挡而导致信息丢失,从而导致错误的操作。
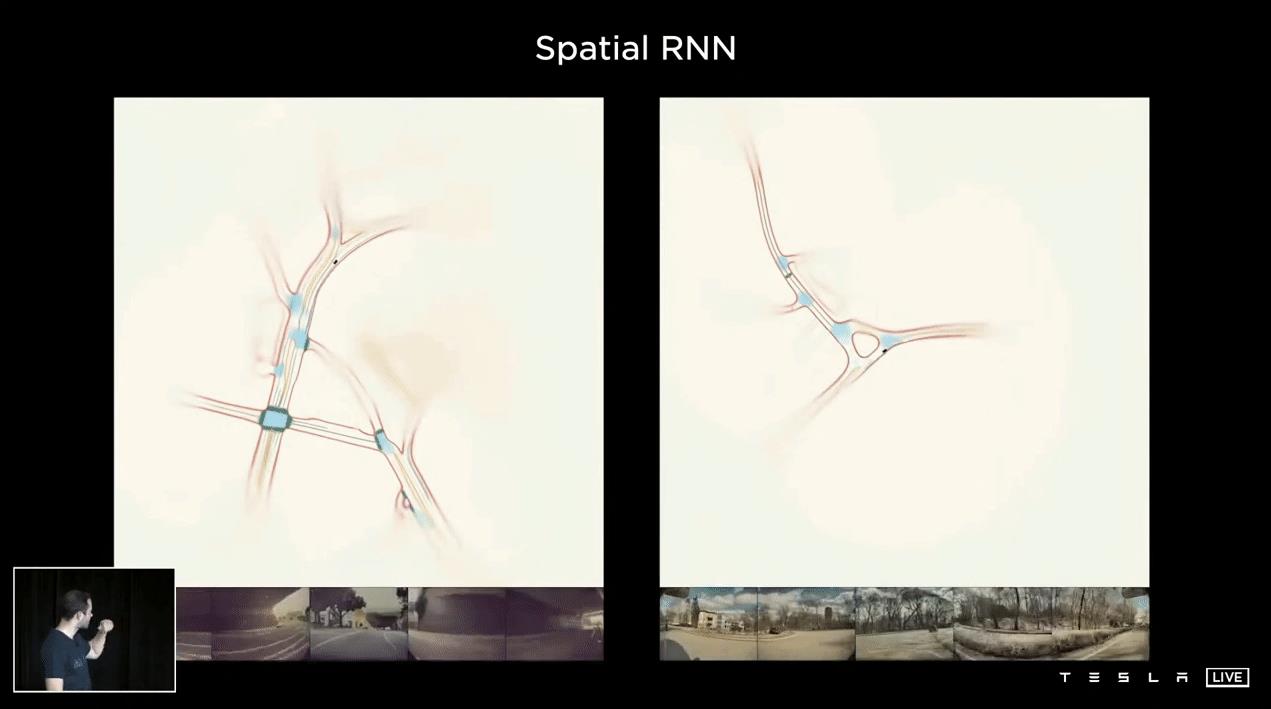
这显示了使用Spatial RNN的单个片段的几个预测,单个遍历。但这里可能会有很多次旅行基本上是很多车,很多片段可以合作来构建这个地图,基本上是一个有效的高清地图。这个映射将在后面的自动标记部分中使用。
空间RNN的好处:
- 改进了对临时遮挡的鲁棒性
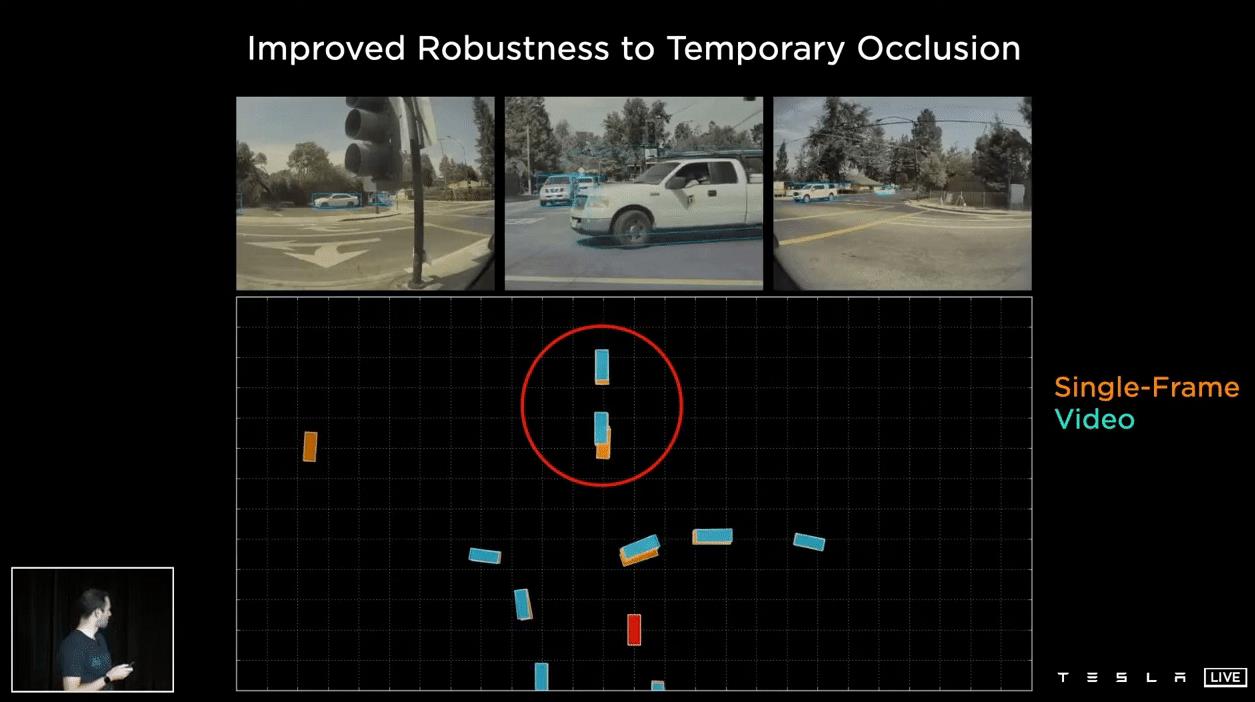
在这个例子中,有两辆车(从屏幕顶部),其中一辆车将从屏幕右侧驶过,并短暂遮挡它们。屏幕中间底部的红色方块是自我车。有单帧预测(橙色)和视频预测(蓝色)。当两者都在观测范围内时,预测结果大致相同。当它们被遮挡时,单帧网络会降低检测,但视频模块会记住它们。当它们只是部分被遮挡时,单帧网络会做出非常可怕的预测(红色圆圈内不稳定的橙色块)。
- 从视频架构改进深度和速度
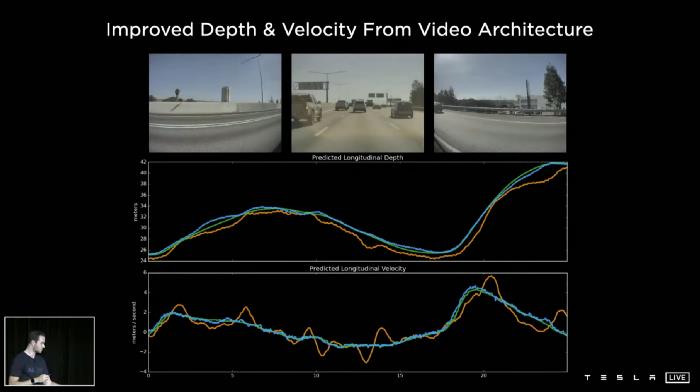
空间RNN在估计深度特别是速度方面有显著的改进。在“移除雷达”项目中,雷达深度和速度显示为绿色,单帧表现为橙色,视频模块表现为蓝色。我们看到深度的质量更高,速度也更高。视频模块实际上就在雷达信号的上方。
我们也看到了这个项目的最终结果。从2021年5月开始,为北美市场生产的Model 3和Model Y将不再配备雷达。
特斯拉视觉网络最终结构
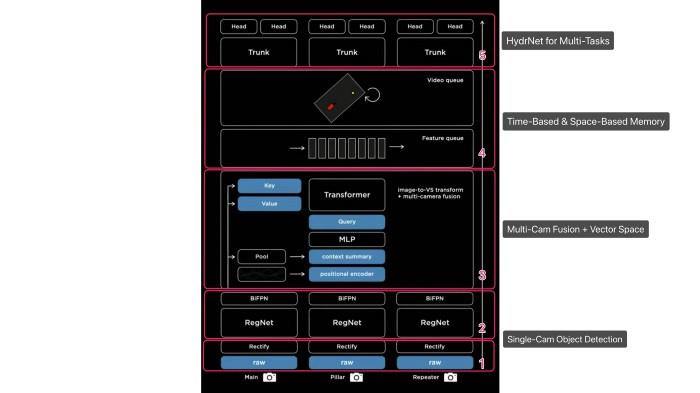
- 原始图像在底部输入,然后经过校正层对相机进行校正,然后把所有的东西放入一个普通的虚拟相机中,
- 通过RegNets残差网络将其处理成多个不同尺度的特征,并将多尺度信息与BiFBN融合
- 通过Transformer模块将其重新表示为向量空间和输出空间。
- 在时间或空间上将馈送到特征队列,由视频模块处理,比如Spatial RNN。
- 接着进入HydraNet的分支结构,其中有树干和头部用于所有不同的任务。
这个特斯拉视觉模块干净而优雅,整个建筑呈现出一种工程美学。
目前,大多数电动汽车制造商的视觉系统还处于特斯拉架构的第一和第二阶段。
特斯拉视觉方案下一阶段计划
- 在目前的神经网络中,时间和空间的融合比较晚。他们计划做一个更早的空间或时间融合,例如在底部使用成本体积或光流网络。如果你感兴趣,你可以阅读这篇文章:PWC-Net: CNNs for Optical Flow Using Pyramid, warp, and Cost Volume。
- 目前的神经网络的输出是密集的光栅,实际上在汽车中进行后处理的成本非常高,而且系统的延迟也不理想。他们正在研究各种预测道路稀疏结构的方法,并试图减少昂贵的后处理。
特斯拉视觉方案技术栈
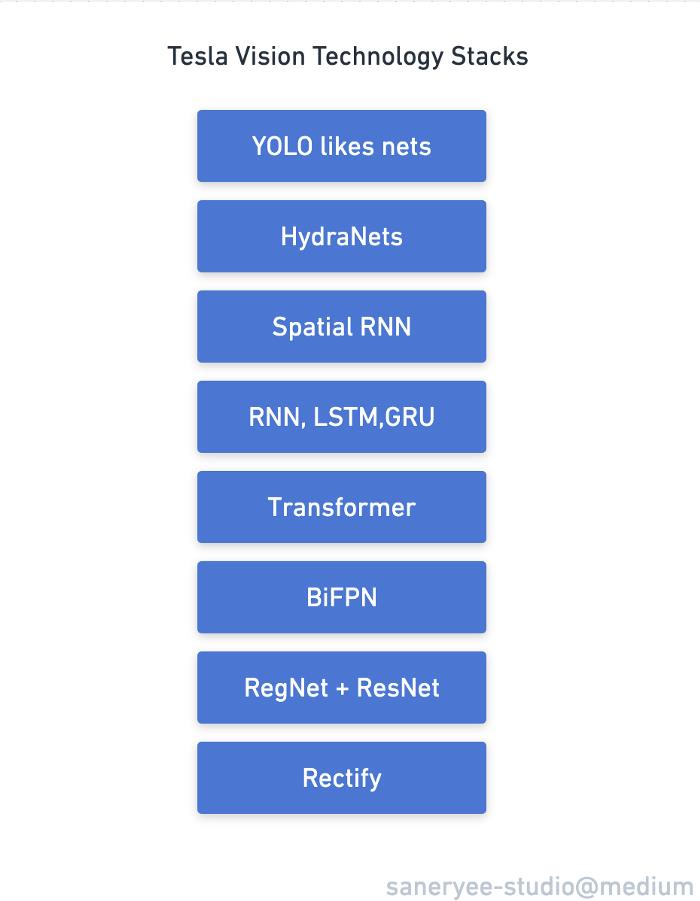
从上图的特斯拉技术栈来看,特斯拉使用的模型是一些处理对象检测领域的常用模型,如RNN、LSTM、Transformer、ResNet、RegNet、BiFPN、YOLO等,但特斯拉AI Team对这些模型有更深入的了解。他们融合多种模型和深入挖掘模型潜力的能力让我这个普通的人工智能工程师感到惊讶。
当我们还在讨论论文中出现的有趣的新模型时,特斯拉的工程师已经在他们的任务中实现和使用了这些模型,并将它们融合到他们的神经网络架构中。
特斯拉AI日的感受
特斯拉成功的要素:
- 第一性原理
- 工程能力
- 执行能力
在接下来的特斯拉人工智能日系列中,我们将讨论:计划与控制、自动标注、模拟、缩放数据生成、人工智能编译与调度、工具与评估等。
以上是关于深度理解特斯拉自动驾驶解决方案 2:向量空间的主要内容,如果未能解决你的问题,请参考以下文章
丧子车主怒告特斯拉:对“自动驾驶”太信赖,结果最受伤害 | 深度对话
自动驾驶感知算法实战15——纯视觉感知和传感器融合方案对比,特斯拉九头蛇的进化
自动驾驶感知算法实战15——纯视觉感知和传感器融合方案对比,特斯拉九头蛇的进化