人工智能--基于LSTM的文本挖掘
Posted Abro.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能--基于LSTM的文本挖掘相关的知识,希望对你有一定的参考价值。
学习目标:
- 理解文本挖掘的基本原理。
- 掌握利用LSTM对文本进行分类的方法。
学习内容:
近年来,随着微信、微博、市长信箱、阳光热线等网络问政平台逐步成为政府了解民意、汇聚民智、凝聚民气的重要渠道,各类社情民意相关的文本数据量不断攀升,给以往主要依靠人工来进行留言划分的相关部门的工作带来了极大挑战。在处理网络问政平台的群众留言时,工作人员首先按照一定的划分体系对留言进行分类,以便后续将群众留言分派至相应的职能部门处理。目前,大部分电子政务系统还是依靠人工根据经验处理,存在工作量大、效率低,且差错率高等问题。请根据附件text_data.xlsx给出的数据,划分训练样本和测试样本,参考以下代码,建立基于LSTM的神经网络,对留言内容的一级标签进行分类。并调整网络参数,提高分类的效果,和原始的贝叶斯分类方法的结果进行比较。
数据表的结构


学习过程:
测试结果如下表:
未把留言主题和留言详情归为留言主题,对留言内容的一级标签进行分类的结果如下表:
| 优化器 | 迭代次数 | LSTM的input_size | 测试集识别率 | 原始贝叶斯分类的测试集识别率 |
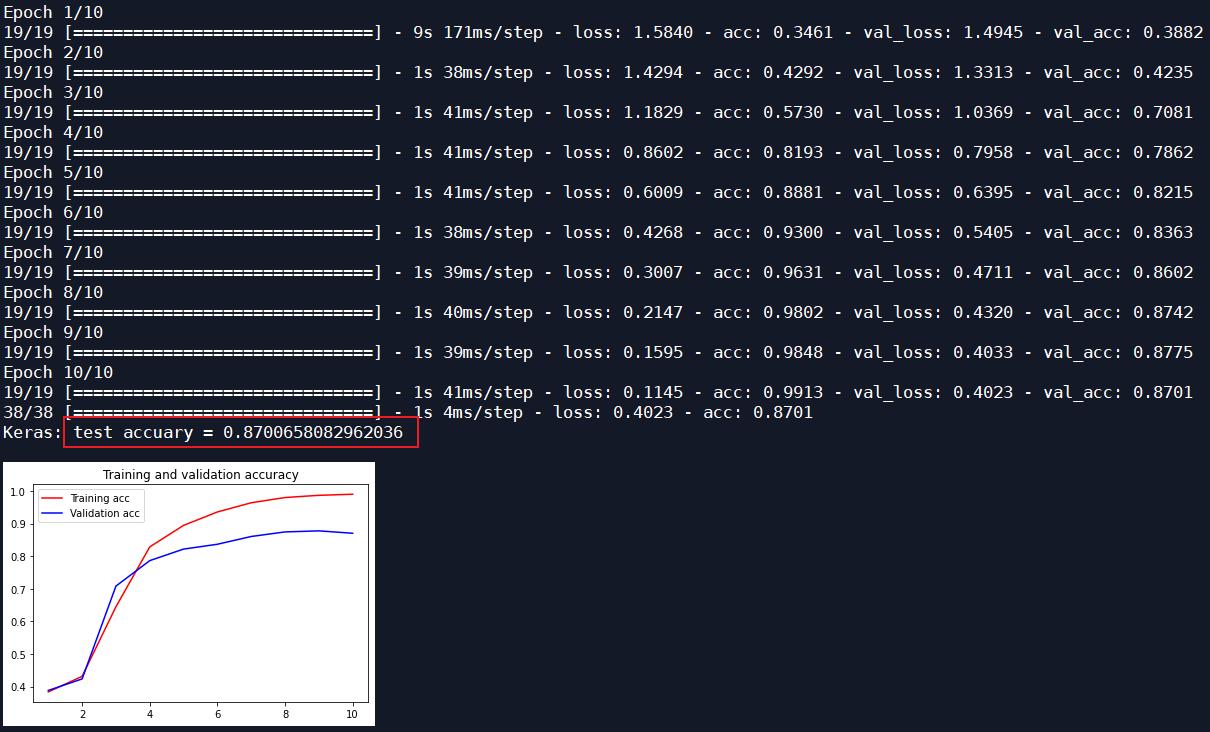
| Adam | 10 | 16 | 0.8701 | 0.7245 |
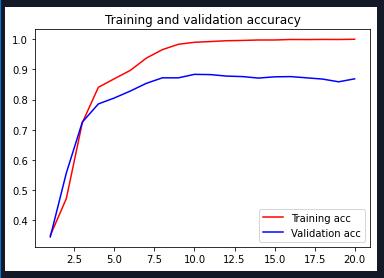
| Adam | 20 | 16 | 0.8684 | 0.7245 |
| RMSProp | 10 | 16 | 0.8692 | 0.7245 |
把留言主题和留言详情都归到留言主题,作为数据集对留言内容的一级标签进行分类的结果如下表:
| 优化器 | 迭代次数 | LSTM的input_size | 测试集的识别率 | 原始贝叶斯分类的测试集识别率 |
| Adam | 10 | 未增加LSTM网络 | 0.7020 | 0.7912 |
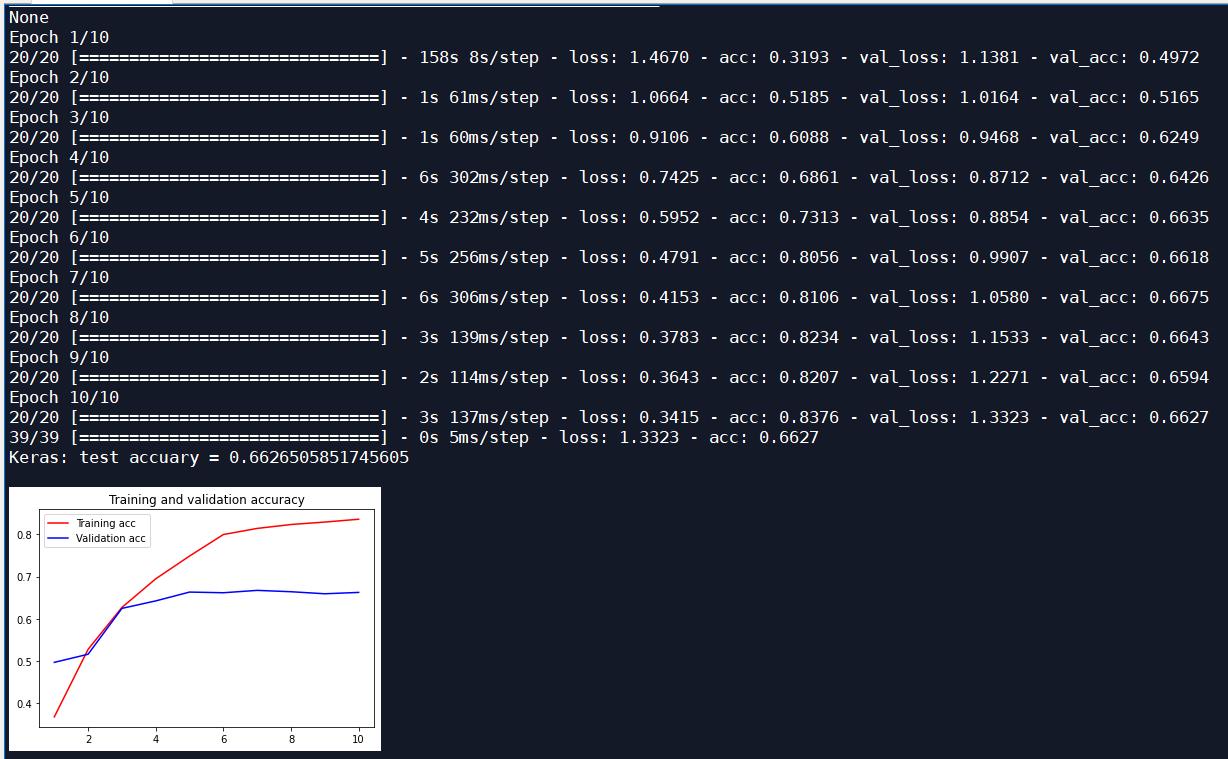
| Adam | 10 | 128 | 0.6627 | 0.7912 |
| Adam | 10 | 32 | 0.6779 | 0.7912 |
| Adam | 10 | 16 | 0.6827 | 0.7912 |
测试过程:
未把留言主题和留言详情归为留言主题,对留言内容的一级标签进行分类,增加一个LSTM层,迭代10次,优化器为Adam,input_size为16:

迭代20次:

增加一个LSTM层,迭代10次,优化器为RMSProp:

把留言主题和留言详情都归到留言主题,作为数据集对留言内容的一级标签进行分类, 未添加LSTM网络:

增加一个LSTM层,迭代10次,优化器为Adam,input_size为128:

增加一个LSTM层,迭代10次,优化器为Adam,input_size为32:


增加一个LSTM层,迭代10次,优化器为Adam,input_size为16:


调整LSTM的input_size,随着input_size的减小,测试集的识别率逐渐上升。
源码:
# In[1]: 读取原始数据
import pandas as pd
file='text_data.xlsx'
data_org = pd.read_excel(file)
data = data_org[['留言主题','留言详情','一级标签']]
data['留言主题'] = data['留言主题']+data['留言详情']
label_counts = data['一级标签'].value_counts()
print(label_counts)
num_class = len(label_counts)
# In[2]: 数据预处理
# 去重
data = data['留言主题'].drop_duplicates()
# 去除x序列
import re
data = data.apply(lambda x: re.sub('x', '', x))
# 结巴分词
import jieba
data = data.apply(lambda x:jieba.lcut(x))
# 去除停用词
stopwords=pd.read_csv('stopwords-1.txt',encoding='utf-8',sep='hhhaha',header=None,engine='python')
stopWords=['?','!','\\xa0','\\n','\\t']+list(stopwords.iloc[:,0])
data = data.apply(lambda x:[i for i in x if i not in stopWords])
# 获取标签
labels = data_org.loc[data.index,'一级标签']
labels = labels.factorize()[0] # 类别数字化
# 划分训练样本和测试样本
from sklearn.model_selection import train_test_split
data_tr,data_te,labels_tr,labels_te=train_test_split(data,labels,test_size=0.2,random_state=123)
# In[3]: 使用sklearn模块里面的词频统计工具数字化
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
# 列表转换成字符串,才能作为CountVectorizer.fit_transform的参数
data_tr_s=data_tr.apply(lambda x:' '.join(x))
data_te_s=data_te.apply(lambda x:' '.join(x))
# 每个词的词频,所有样本都有同样多的列(=所有词的数量),每一列对应一个单词出现的次数
# 有些列的元素可能大于1,绝大部分是0
countVectorizer=CountVectorizer()
data_tr_sn=countVectorizer.fit_transform(data_tr_s)
# 使得每个样本所有的分量加起来为1
X_tr=TfidfTransformer().fit_transform(data_tr_sn.toarray()).toarray()
# 变换测试样本
data_te_sn = CountVectorizer(vocabulary=countVectorizer.vocabulary_).fit_transform(data_te_s)
X_te = TfidfTransformer().fit_transform(data_te_sn.toarray()).toarray()
# In[4]: 使用贝叶斯分类器进行分类
from sklearn.naive_bayes import GaussianNB
model=GaussianNB()
model.fit(X_tr,labels_tr)
score_tr = model.score(X_tr,labels_tr)
score_te = model.score(X_te, labels_te)
print('GaussianNb: train accuary = %s' % score_tr)
print('GaussianNb: test accuary = %s' % score_te)
# In[5]: 利用keras中的Tokenizer将单词进行编号
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.preprocessing.text import Tokenizer
num_words = 5000
tokenizer = Tokenizer(num_words = num_words) #只考虑最常使用的前num_words个单词
tokenizer.fit_on_texts(data_tr)
K_tr = tokenizer.texts_to_sequences(data_tr)
K_te = tokenizer.texts_to_sequences(data_te)
# 每个样本有maxlen个单词,否则前面补0或者截取
maxlen = 10
K_tr = sequence.pad_sequences(K_tr, maxlen=maxlen)
K_te = sequence.pad_sequences(K_te, maxlen=maxlen)
# In[6]: 构建神经网络模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
#from keras.layers import Flatten
from tensorflow.keras.layers import LSTM
from tensorflow.python.keras.layers.embeddings import Embedding
model = Sequential()
# Embedding类将正整数(索引)转换为固定大小的密集向量,通过矩阵乘法进行数据降维。
emebdding_layer = Embedding(num_words, 128, input_length=maxlen)
model.add(emebdding_layer)
#model.add(LSTM(128,return_sequences=True)) #可改为其它参数
model.add(LSTM(16)) #可调整大小
#model.add(Flatten())
model.add(Dense(num_class, activation='sigmoid')) #softsign
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc']) #可改成其他优化器,rmsprop,adam
print(model.summary())
# 训练网络
history = model.fit(K_tr,labels_tr,
validation_data=(K_te, labels_te),
batch_size=256, epochs=20)
loss, score_te = model.evaluate(K_te, labels_te)
print('Keras: test accuary = %s' % score_te)
# In[7]: 绘制训练过程中识别率和损失的变化
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.title('Training and validation accuracy')
plt.plot(epochs, acc, 'red', label='Training acc')
plt.plot(epochs, val_acc, 'blue', label='Validation acc')
plt.legend()
plt.show()
学习产出:
- 增加一个LSTM神经网络后,测试集的识别率有所下降,我通过调整LSTM的input_size使得测试集识别率有所上升;
以上是关于人工智能--基于LSTM的文本挖掘的主要内容,如果未能解决你的问题,请参考以下文章