人工智能--使用神经网络分析电影评论
Posted Abro.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能--使用神经网络分析电影评论相关的知识,希望对你有一定的参考价值。
学习目标:
- 理解文本挖掘的基本原理。
- 掌握利用LSTM对文本进行分类的方法。
学习内容:
对kears自带的keras.datasets.imdb英文影评数据,分析该影评是正面评价还是负面评价。参考以下代码,建立基于LSTM的神经网络,对影评数据进行分类。并调整网络参数,提高分类的效果,和原始的神经网络方法的结果进行比较。
提示:可参考Bidirectional LSTM on IMDB
学习过程:
结果如下表:
| 优化器 | 迭代次数 | 测试集识别率 | |
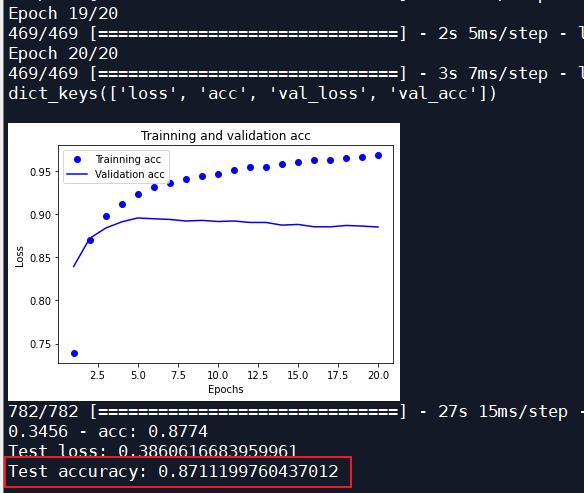
| 原始神经网络 | RMSProp | 20 | 0.8711 |
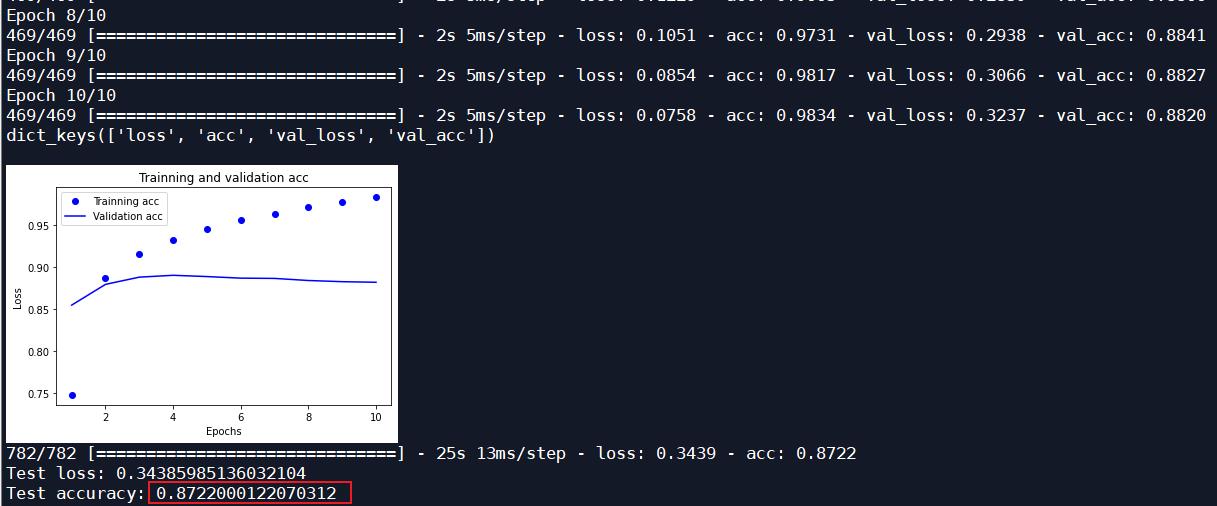
| 原始神经网络 | Adam | 10 | 0.8722 |
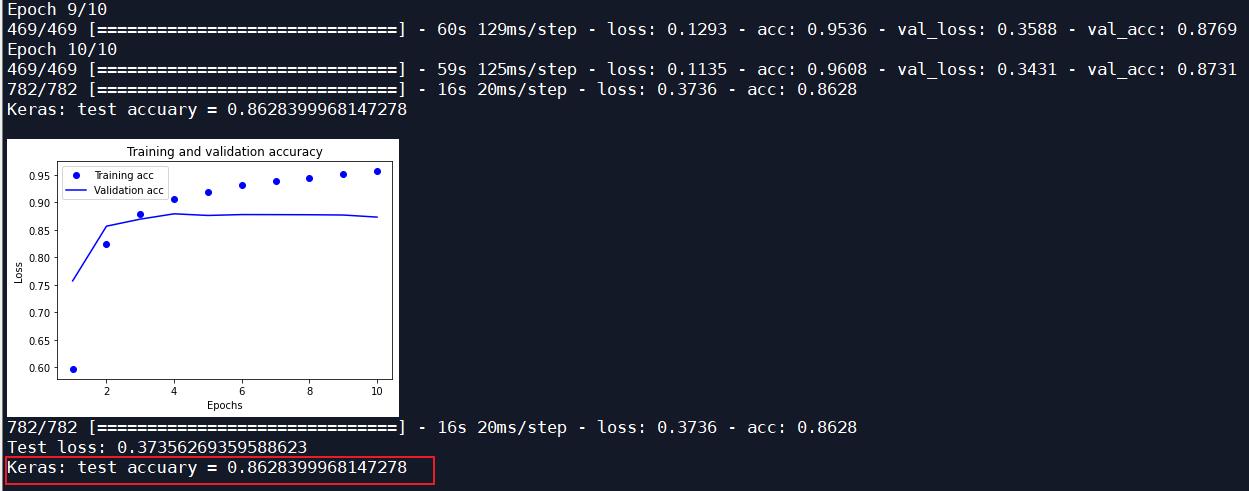
| 一层LSTM | Adam | 10 | 0.8628 |
| 双层LSTM | Adam | 10 | 0.8249 |
| 双向LSTM | Adam | 10 | 0.8619 |
| 双向双层LSTM | Adam | 10 | 0.8538 |
综上,只添加一层LSTM和双向LSTM的神经网络的分类效果较接近原始的神经网络的识别率。
调试过程:
原始神经网络:

一层LSTM:

双层LSTM:



双向LSTM:
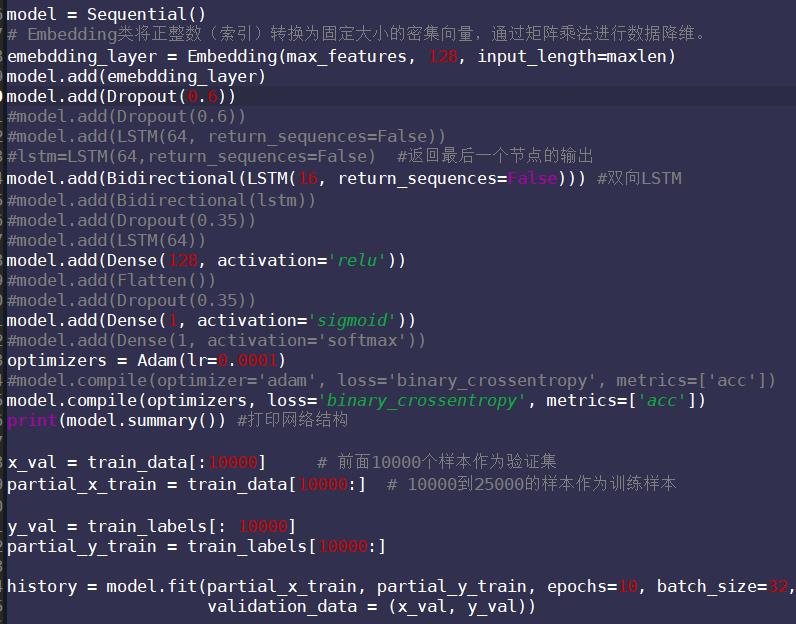
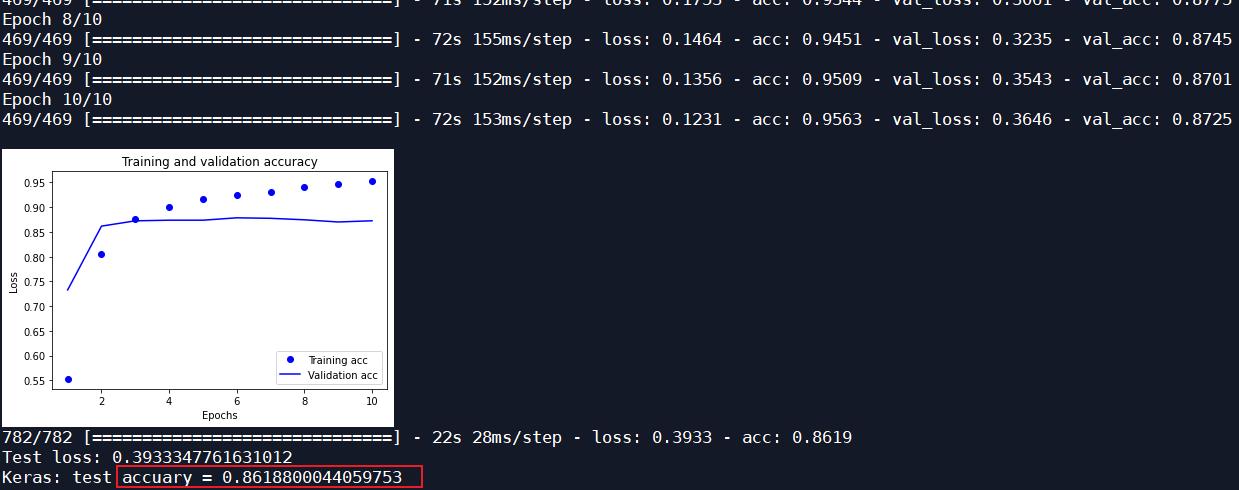
双向LSTM接一层LSTM:


源码:
# In[0]: 读取数据
from keras.datasets import imdb
#num_words表示加载影评时,确保影评里面的单词使用频率保持在前1万位,于是有些很少见的生僻词在数据加载时会舍弃掉
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(train_data[0]) # 单词编号组成一段话的评论
print(train_labels[0])
# In[1]: 单词编号 和 单词 之间的对应关系
#频率与单词的对应关系存储在哈希表word_index中,它的key对应的是单词,value对应的是单词的频率
word_index = imdb.get_word_index()
#我们要把表中的对应关系反转一下,变成key是频率,value是单词
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
'''
在train_data所包含的数值中,数值1,2,3对应的不是单词,而用来表示特殊含义,1表示“填充”,2表示”文本起始“,
3表示”未知“,因此当我们从train_data中读到的数值是1,2,3时,我们要忽略它,从4开始才对应单词,如果数值是4,
那么它表示频率出现最高的单词
'''
text = ""
for wordCount in train_data[0]:
if wordCount > 3:
text += reverse_word_index.get(wordCount - 3)
text += " "
else:
text += "?"
print(text) # 把单词编号转换 为 单词 后,第一个影评原始的单词序列
# In[2]: 利用keras中的Tokenizer将单词进行编号
from keras.preprocessing import sequence
max_features = 10000
maxlen = 200
train_data = sequence.pad_sequences(train_data, maxlen=maxlen)
test_data = sequence.pad_sequences(test_data, maxlen=maxlen)
# In[6]: 构建神经网络模型
from keras.models import Sequential
#from keras.layers import Dense,LSTM,Dropout
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.layers import Bidirectional
#from keras.layers import Flatten
from keras.layers.embeddings import Embedding
from keras.optimizers import Adam
#from keras.optimizers import RMSProp
model = Sequential()
# Embedding类将正整数(索引)转换为固定大小的密集向量,通过矩阵乘法进行数据降维。
emebdding_layer = Embedding(max_features, 128, input_length=maxlen)
model.add(emebdding_layer)
model.add(Dropout(0.35)) #防止过拟合
#model.add(Dropout(0.6))
#model.add(LSTM(64, return_sequences=False))
#lstm=LSTM(64,return_sequences=False) #返回最后一个节点的输出
#双向LSTM
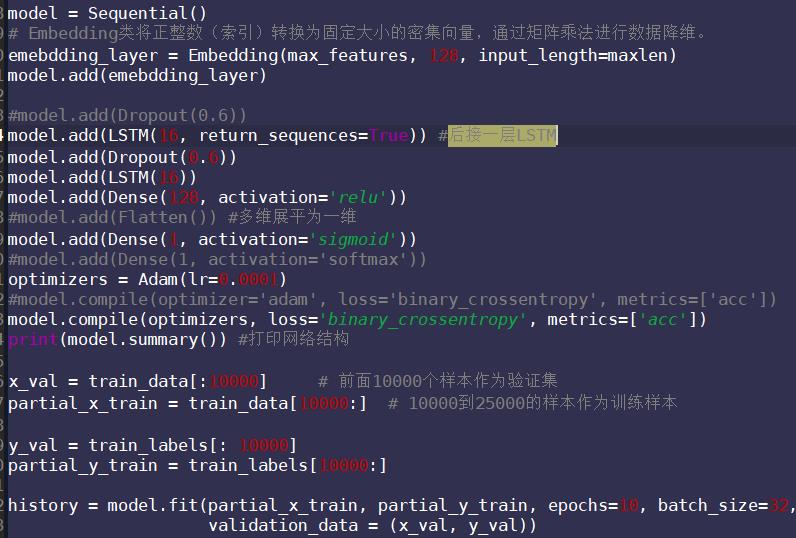
model.add(Bidirectional(LSTM(16, return_sequences=True))) #后接一层LSTM
model.add(LSTM(16))
model.add(Dense(128, activation='relu'))
#model.add(Flatten())
#model.add(Dropout(0.35))
model.add(Dense(1, activation='sigmoid'))
#model.add(Dense(1, activation='softmax')) ###!!!
optimizers = Adam(lr=0.0001)
#model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
model.compile(optimizers, loss='binary_crossentropy', metrics=['acc'])
print(model.summary()) #输出网络结构
x_val = train_data[:10000] # 前面10000个样本作为验证集
partial_x_train = train_data[10000:] # 10000到25000的样本作为训练样本
y_val = train_labels[: 10000]
partial_y_train = train_labels[10000:]
history = model.fit(partial_x_train, partial_y_train, epochs=3, batch_size=32,
validation_data = (x_val, y_val))
# In[3]: 绘制训练过程中识别率和损失的变化
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.title('Training and validation accuracy')
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# In[4]: 测试
loss, score_te = model.evaluate(test_data, test_labels)
print('Test loss:', loss)
print('Keras: test accuary = %s' % score_te)
学习产出:
- 在不改动原有数据集划分的情况下,增加了LSTM层不能很好地提高识别率;
以上是关于人工智能--使用神经网络分析电影评论的主要内容,如果未能解决你的问题,请参考以下文章