人工智能--基于LSTM的文本生成
Posted Abro.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能--基于LSTM的文本生成相关的知识,希望对你有一定的参考价值。
学习目标:
- 理解文本生成的基本原理。
- 掌握利用LSTM生成唐诗宋词的方法。
学习内容:
利用如下代码和100首经典宋词的数据,基于LSTM生成新的词,并调整网络参数,提高生成的效果。

学习过程:
网络结构:
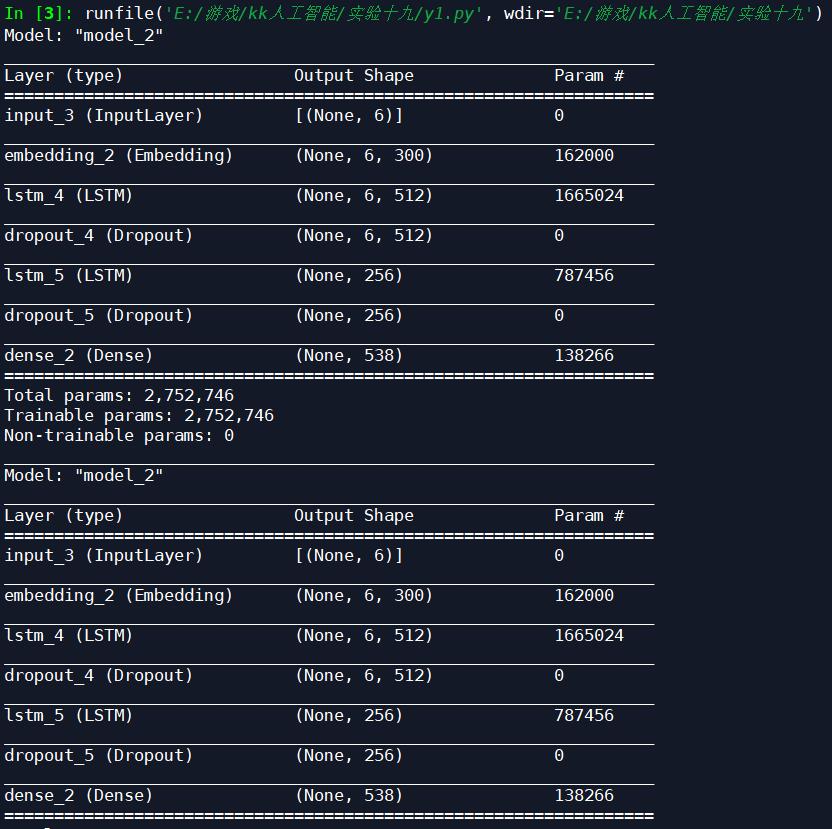

Batch_size改为64,学习率改为0.001后,迭代十次:

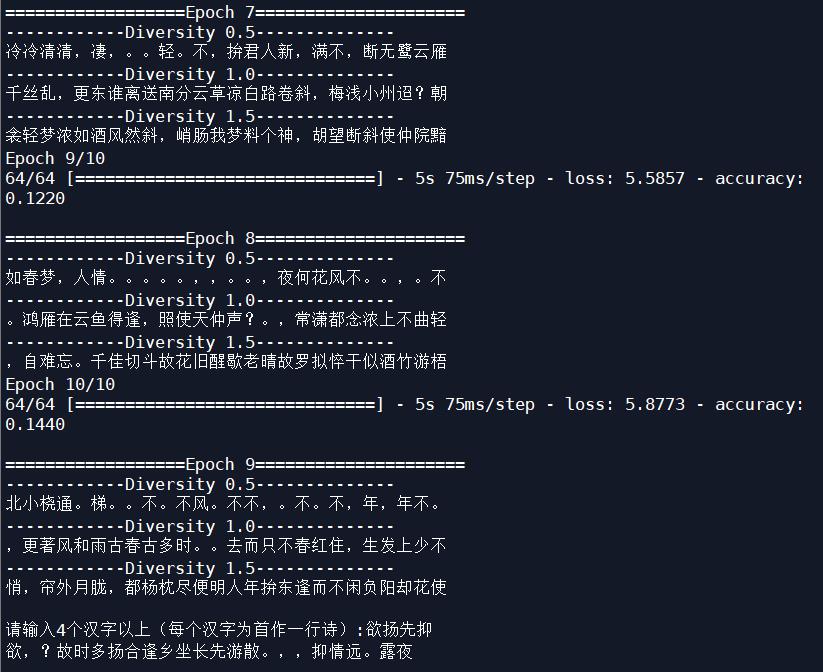
输入四字造词:

Batch_size改为64,学习率改为0.0001后,迭代十次:

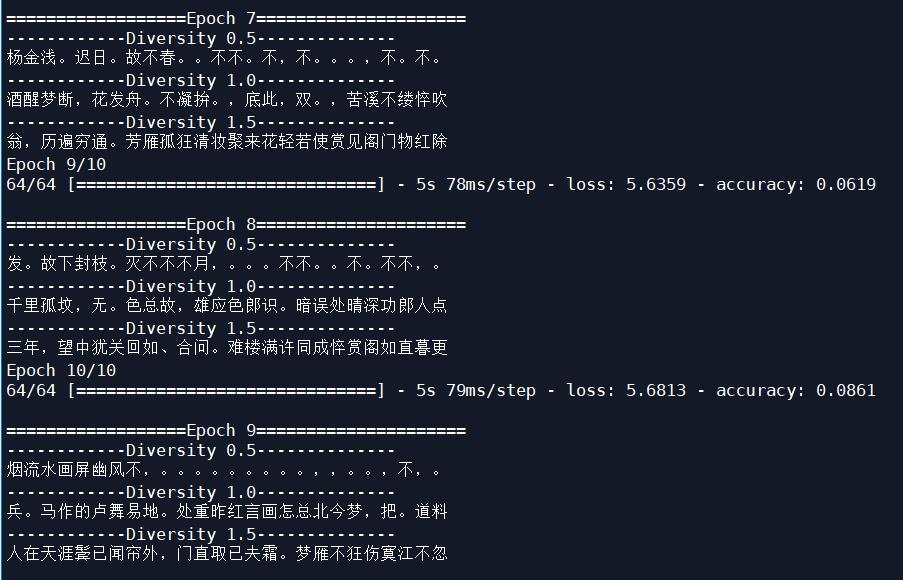
输入四字造词:

显然,把学习率改为0.0001后,LSTM模型生成宋词的效果要好很多。
源码:
# 基于LSTM的唐诗生成
puncs = [']', '[', '(', ')', '', '', ':', '《', '》']
# In[1]: 数据预处理
# 配置信息
class Config(object):
#poetry_file = 'poetry.txt' # 数据量太大,导致GPU内存溢出
poetry_file = 'poetry_song.txt' # 换成宋词的数据做训练
weight_file = 'poetry_song_model.h5'
max_len = 6 # 根据前六个字预测第七个字
batch_size = 64 #改为128
learning_rate = 0.001 #可改为0.0001
# 在构建LSTM网络之前,需要标识诗句的结束点、去掉数据集中低频的字和构建word到id的映射
def preprocess_file(Config):
# 语料文本内容
files_content = ''
with open(Config.poetry_file, 'r', encoding='utf-8') as f:
for line in f:
# 每行的末尾加上"]"符号代表一首诗结束
for char in puncs:
line = line.replace(char, '')
files_content += line.strip() + ']'
# 去掉低频的字
words = sorted(list(files_content))
words.remove(']')
counted_words =
for word in words:
if word in counted_words:
counted_words[word] += 1
else:
counted_words[word] = 1
erase = []
for key in counted_words:
if counted_words[key] <= 2:
erase.append(key)
for key in erase:
del counted_words[key]
del counted_words[']']
wordPairs = sorted(counted_words.items(), key=lambda x: -x[1])
words, _ = zip(*wordPairs)
# word到id的映射。注意单位是每个汉字,而不是每个词语
word2num = dict((c, i + 1) for i, c in enumerate(words))
num2word = dict((i, c) for i, c in enumerate(words))
word2numF = lambda x: word2num.get(x, 0)
return word2numF, num2word, words, files_content
# In[2]: 定义一个类,包含 生成训练数据,构建网络模型,训练网络,根据给出的文字生成诗句
import random
import os
import keras
import numpy as np
from keras.callbacks import LambdaCallback
from keras.models import Input, Model, load_model
from keras.layers import LSTM, Dropout, Dense, Embedding
from keras.optimizers import Adam
class PoetryModel(object):
def __init__(self, config):
self.model = None
self.do_train = True
self.loaded_model = False
self.config = config
# 文件预处理
self.word2numF, self.num2word, \\
self.words, self.files_content = preprocess_file(self.config)
# 如果网络文件存在则直接加载网络,否则开始训练
if os.path.exists(self.config.weight_file):
self.model = load_model(self.config.weight_file)
self.model.summary()
else:
self.train()
self.do_train = False
self.loaded_model = True
# 生成训练数据,x表示输入,y表示输出。
# 输入信息为6个字,输出信息为第1个字。
# 比如“我想要吃香蕉啊”,输入即为“我想要吃香蕉”,输出为“啊”。
# 之后将文字转换成向量的形式
def data_generator(self):
i = 0
# 需要注意的是,此处的生成器是一个while True的无限循环过程。
# 当输入字段长度大于文本语料字段的长度时,下标已经超过语料的长度,
# 因此在训练网络时要限制网络学习的循环次数。
while True:
x = self.files_content[i: i + self.config.max_len]
y = self.files_content[i + self.config.max_len]
# 给定前六个字,生成第七个字。跨度为6的句子中,前后每个字都是有关联的。
# 如果出现了“]”“[”等符号,说明“]”符号之前的和之后的语句是没有关联的内容,分别属于两首不同的诗。
puncs = [']', '[', '(', ')', '', '', ':', '《', '》', ':']
if len([i for i in puncs if i in x]) != 0:
i += 1
continue
if len([i for i in puncs if i in y]) != 0:
i += 1
continue
y_vec = np.zeros(
shape = (1, len(self.words)),
dtype = np.bool
)
y_vec[0, self.word2numF(y)] = 1.0
x_vec = np.zeros(
shape = (1, self.config.max_len),
dtype = np.int32
)
for t, char in enumerate(x):
x_vec[0, t] = self.word2numF(char)
yield x_vec, y_vec
i += 1
# 建立基于LSTM的神经网络模型
def build_model(self):
input_tensor = Input(shape=(self.config.max_len,))
embedd = Embedding(len(self.num2word) + 2, 300,
input_length=self.config.max_len)(input_tensor)
lstm = LSTM(512, return_sequences=True)(embedd)
#flatten = Flatten()(lstm)
dropout = Dropout(0.6)(lstm)
lstm = LSTM(256)(dropout)
flatten = Dropout(0.6)(lstm)
dense = Dense(len(self.words), activation='softmax')(flatten)
self.model = Model(inputs=input_tensor, outputs=dense)
optimizer = Adam(lr=self.config.learning_rate)
self.model.compile(loss='categorical_crossentropy',
optimizer=optimizer, metrics=['accuracy'])
self.model.summary()
# 查看学习情况
# 对每个测试样本(6个汉字序列),self.model.predict的预测结果preds是固定的
# 但是,为了生成随机的结果,在多项式概率分布条件下再随机选择
# preds的某个分量越高,被选择的概率越大,但不是每次都选分量最高对应的汉字。
def sample(self, preds, temperature=1.0):
# 当temperature=1.0时,网络输出正常
# 当temperature=0.5时,网络输出比较open
# 当temperature=1.5时,网络输出比较保守
# 在训练的过程中可以看到temperature不同,结果也不同
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
def generate_sample_result(self, epoch, logs):
# 训练过程中,每个epoch打印出当前的学习情况,随机采样
print('\\n==================Epoch ====================='.format(epoch))
for diversity in [0.5, 1.0, 1.5]:
print('------------Diversity --------------'.format(diversity))
start_index = random.randint(
0, len(self.files_content) - self.config.max_len - 1)
generated = ''
sentence = self.files_content[start_index: start_index + self.config.max_len]
generated += sentence
for i in range(20):
x_pred = np.zeros((1, self.config.max_len))
for t, char in enumerate(sentence[-6:]):
x_pred[0, t] = self.word2numF(char)
preds = self.model.predict(x_pred, verbose=0)[0]
next_index = self.sample(preds, diversity)
next_char = self.num2word[next_index]
generated += next_char
sentence = sentence + next_char
print(sentence)
# 根据给出的文字,生成诗句。每个汉字为首作一行诗
def predict(self, text):
if not self.loaded_model:
return
# 随机选择一行,截取最后5个字,接上用户输入的第一个字,作为生成第一句中的第二个字的随机种子
with open(self.config.poetry_file, 'r', encoding='utf-8') as f:
file_list = f.readlines()
random_line = random.choice(file_list)
# 如果给的text不到四个字,则随机补全
if not text or len(text) != 4:
for _ in range(4 - len(text)):
random_str_index = random.randrange(0, len(self.words))
text += self.num2word.get(random_str_index) \\
if self.num2word.get(random_str_index) \\
not in [',', '。', ','] else self.num2word.get(
random_str_index + 1)
seed = random_line[-(self.config.max_len):-1]
res = ''
seed = 'c' + seed # 第一个字符没有用的,会被去掉,方便统一编程
for c in text:
# 生成下一个字的种子,包含6个字
seed = seed[1:] + c
#print(seed)
# 经过这个循环后,c将变为生成句子的第一个字,生成的一行句子一共有6个字
for j in range(5):
x_pred = np.zeros((1, self.config.max_len))
for t, char in enumerate(seed):
x_pred[0, t] = self.word2numF(char)
preds = self.model.predict(x_pred, verbose=0)[0]
next_index = self.sample(preds, 1.0)
next_char = self.num2word[next_index]
seed = seed[1:] + next_char
res += seed
return res
# 训练网络
def train(self):
# 训练模型
number_of_epoch = 10 #100
if not self.model:
self.build_model()
self.model.summary()
self.model.fit_generator(
generator=self.data_generator(),
verbose=True,
steps_per_epoch=self.config.batch_size,
epochs=number_of_epoch,
callbacks=[
keras.callbacks.ModelCheckpoint(self.config.weight_file,
save_weights_only=False),
LambdaCallback(on_epoch_end=self.generate_sample_result)
]
)
# In[3]: 主函数,程序入口
if __name__ == '__main__':
# 构造网络对象。并且会判断:如果训练好的权重.h5文件存在则直接加载,否则开始训练
model = PoetryModel(Config)
text = input('请输入4个汉字以上(每个汉字为首作一行诗):')
while len(text)>0:
sentence = model.predict(text)
print(sentence)
text = input('请输入4个汉字以上(每个汉字为首作一行诗):')
学习产出:
- 造出来的词有点瑕疵,有时候造出来的宋词,在人看来不像是一首宋词。
以上是关于人工智能--基于LSTM的文本生成的主要内容,如果未能解决你的问题,请参考以下文章