Python本地数据(文件及文件夹)读写的代码架构
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python本地数据(文件及文件夹)读写的代码架构相关的知识,希望对你有一定的参考价值。
前言
-
场景:
做算法项目时候,一些临时数据(如:中间数据、模型)可以存本地,如何放置才不会乱? -
本文目的:
本地临时数据 的 存放、管理、读取
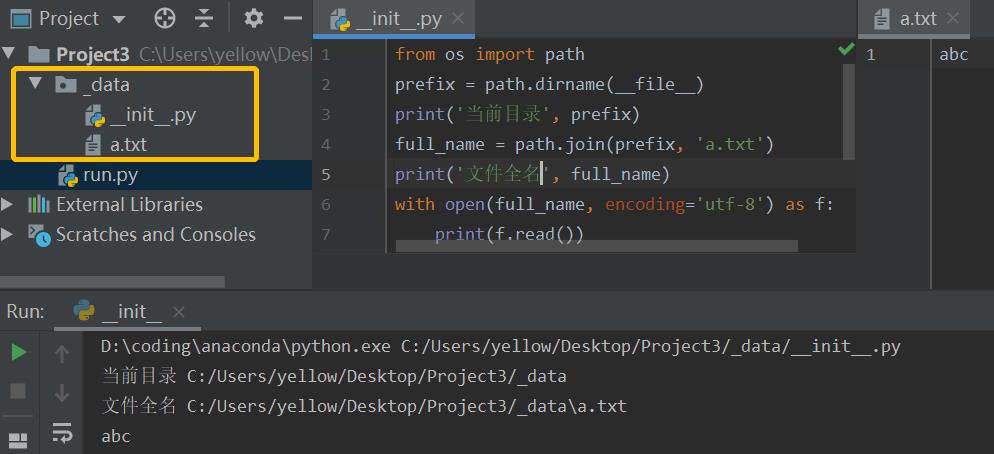
单个数据文件
from os import path
prefix = path.dirname(__file__)
print('当前目录', prefix)
full_name = path.join(prefix, 'a.txt')
print('文件全名', full_name)
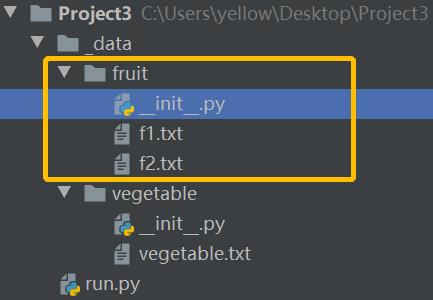
多个数据文件
import os
# 当前目录
prefix = os.path.dirname(__file__)
# 数据容器
data = ''
# 遍历当前目录下的txt文件
for suffix in os.listdir(prefix):
if suffix.endswith('.txt'):
print('文件名', suffix)
full_name = os.path.join(prefix, suffix)
print('文件全名', full_name)
# 数据读取
with open(full_name, encoding='utf-8') as f:
data += f.read()
优化前后比较
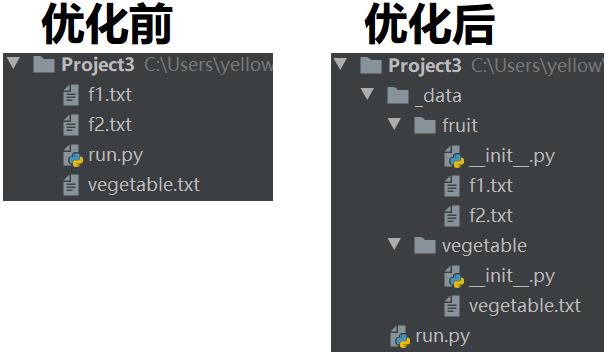
生产代码(run.py)只需import一下就能读到本地数据,而不用在自身写一堆open、read_csv…
以上是关于Python本地数据(文件及文件夹)读写的代码架构的主要内容,如果未能解决你的问题,请参考以下文章