HDFS架构及文件读写流程
Posted firepation
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS架构及文件读写流程相关的知识,希望对你有一定的参考价值。
Hadoop 中有三大组件:HDFS、MapReduce、YARN,HDFS 负责大文件存储的问题,MapReduce 负责大数据计算,而 YARN 负责资源的调度,接下来的文章我会一一介绍这几个组件。今天我们先来聊聊 HDFS 的架构及文件的读写流程。
总体架构
HDFS 设计的目的是为了存储大数据集的文件,因此一台服务器是应付不了的,我们需要一个集群来实现这个目标。当用户需要存储一个文件时,HDFS 会将这个文件切分为一个个小的数据块(在 2.x 的版本中,每个数据块默认大小为 128M),再对每个数据块进行存储,当所有的数据块存储成功之后,才表示这个数据存到 HDFS 中了。HDFS 还会对每个数据块进行备份操作,使系统具有高容错性。
了解了 HDFS 的设计目标之后,我们来看下它的总体架构,下面这张图是从 HADOOP 官网扣下来的,除了刚刚提到的数据块(Blocks),还有两个比较重要的角色:NameNode 和 DataNode。DataNode 即数据节点,顾名思义,它们是存储真实数据的节点(每个节点就是一台服务器)。而 NameNode 呢?它主要维护元数据信息,包括:
- 整个系统的文件和目录以及它们的层级关系
- 文件目录的所有者及其权限
- 每个文件由哪些数据块组成和每个数据块的名称
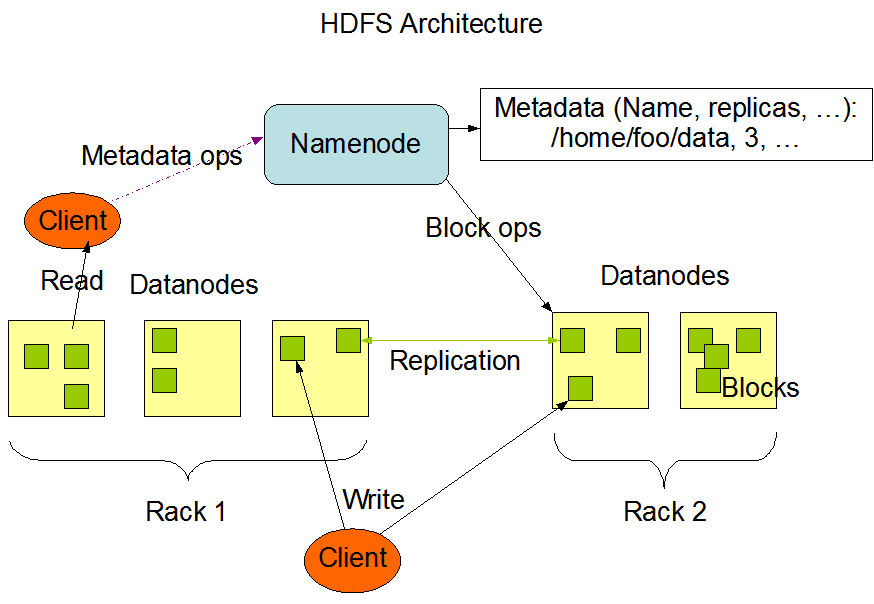
但是这里需要注意的是,NameNode 不会将每个数据块的地址信息持久化到磁盘中,这些信息会在 NameNode 启动之后从各个 DataNode 中获取并存放在内存中,因为从内存中读取数据比从磁盘中读取数据快得多,这无疑大大提高了客户端读取文件的性能。
不过,这张图并没有把 HDFS 中另一个重要的角色标出来 --- Secondary NameNode,这个家伙又是干什么的呢?这就不得不提到 HDFS 文件写入过程中涉及到的两个文件 --- fsimage 和 edits。fsimage 是 NameNode 启动时对整个文件系统的快照,edits 是在 NameNode 启动后,对整个系统的改动序列,在系统重启时,会将 edits 合并到 fsimage 文件上。由于 NameNode 会长时间运行,写入的数据量大时,edits 文件会变得很大,这就会出现下面这些问题:
- edits 文件会变得很大,如何去管理这个文件?
- NameNode 的重启会花费很长的时间,因为有很多改动要合并到 fsimage 文件上
- 如果 NameNode 宕掉了,那我们就丢失了很多改动,因此此时的 fsimage 文件时间戳比较旧(也有观点认为丢失的改动不是特别多,因此丢失的只是那些在内存中,没有写入到 edits 文件中的改动)。
为了解决上述问题,就出现了 Secondary NameNode。它会定时到 NameNode 中获取 edits 文件,并更新到 fsimage 上,一旦有新的 fsimage 文件,它就将其拷贝会 NameNode 上。NameNode 下次启动时直接使用这个 fsimage,省去了合并 fsimage 和 edits 文件的过程。这就是 Secondary NameNode 在 HDFS 中的作用。
读写流程分析
接下来的读写流程我们会结合代码进行分析,使用 JAVA API 对 HDFS 进行操作非常简单,利用 maven 环境,在 pom.xml 中加入 hdaoop client 的依赖就可以使用 HDFS 的 API 了。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>#hadoop.version</version>
</dependency>读数据流程
HDFS 文件读取的的代码如下:
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
/*
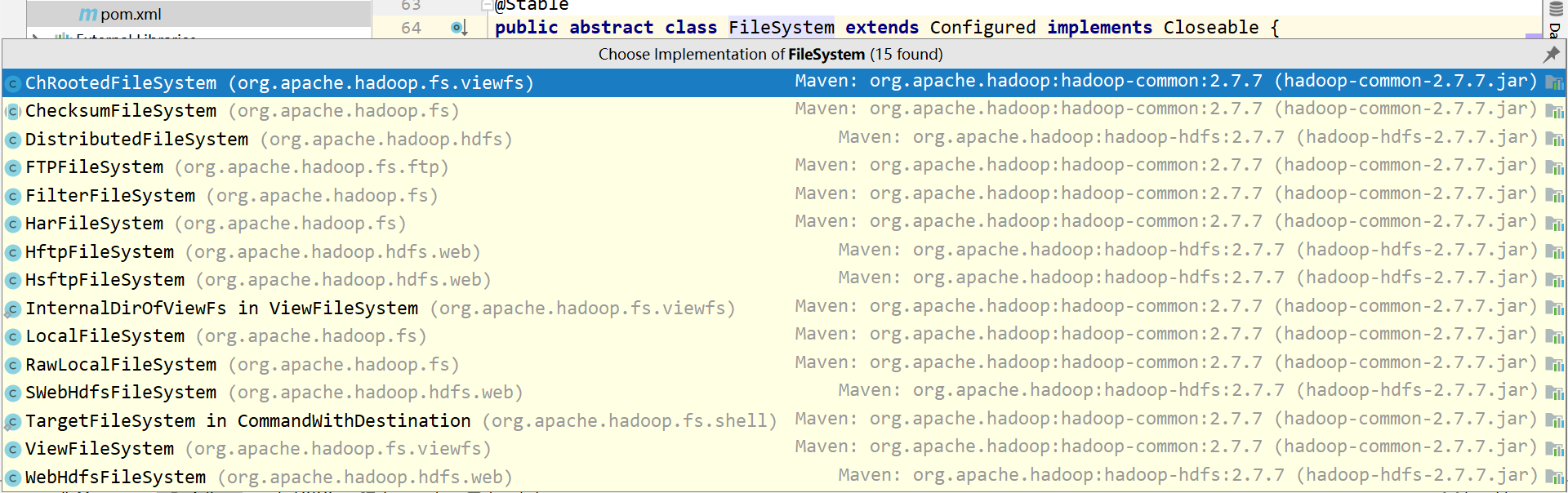
* hadoop 可以跟多种文件系统交互,根据下图,我们也可以看到 FileSystem 有多种实现
* 为了让 hadoop 知道是与什么文件系统进行交互的,我们需要在配置文件中指定。
*/
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
String uri = "hdfs://hadoop-master:9000/e.txt";
// 获取文件系统,这里 FileSystem 具体实现为上面指定的 DistributedFileSystem
FileSystem fs = FileSystem.get(URI.create(uri), conf);
OutputStream out ;
FSDataInputStream in = null;
try
out = new FileOutputStream("e.txt");
in = fs.open(new Path(uri));
// 读取文件到本地
byte[] buf = new byte[4096];
for(int bytesRead = in.read(buf); bytesRead >= 0; bytesRead = in.read(buf))
out.write(buf, 0, bytesRead);
finally
IOUtils.closeStream(in);
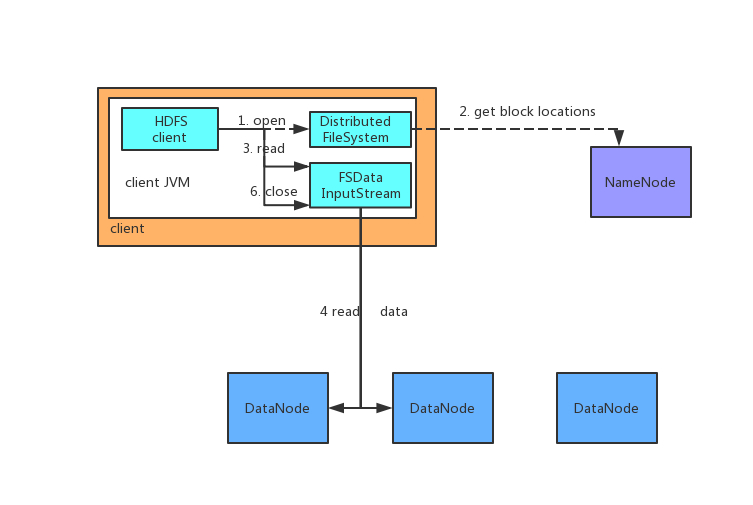
根据上述代码,我们也大致可以猜出 HDFS 读取文件的流程了:
- 获取交互的文件系统(FileSystem),交互的文件系统需要我们在配置文件中指定。FileSystem 的 HDFS 实现类是 DistributedFileSystem(步骤一)。
- DistributedFileSystem 通过远程过程调用(RPC)来调用 namenode,nanenode 将包含文件数据块的 datanode 返回给客户端,并根据 datanode 与客户端的距离来排序(步骤二)。
- DistributedFileSystem 返回 FSDataInputStream 对象,用来读取数据。客户端通过调用 read 方法,从最近的一个 datanode 读取每个数据块的数据,当读取完一个数据块之后,接着查找包含该数据块且离得最近的 datanode 进行读取,直到读取完最后一个数据块,这些对用户来说都是透明的。(步骤三、步骤四)
- 当整个文件读取完毕之后,调用 close 方法,关闭与 nanode 和 datanode 的连接。
写数据流程
public static void main(String[] args) throws IOException
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
String uri = "hdfs://192.168.1.150:9000/friend/test.txt";
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
FSDataOutputStream out = null;
try
in = new FileInputStream("e-friend.txt") ;
out = fs.create(new Path(uri));
byte[] buf = new byte[4096];
for(int bytesRead = in.read(buf); bytesRead >= 0; bytesRead = in.read(buf))
out.write(buf, 0, bytesRead);
finally
if (in != null)
in.close();
if (out != null)
out.close();
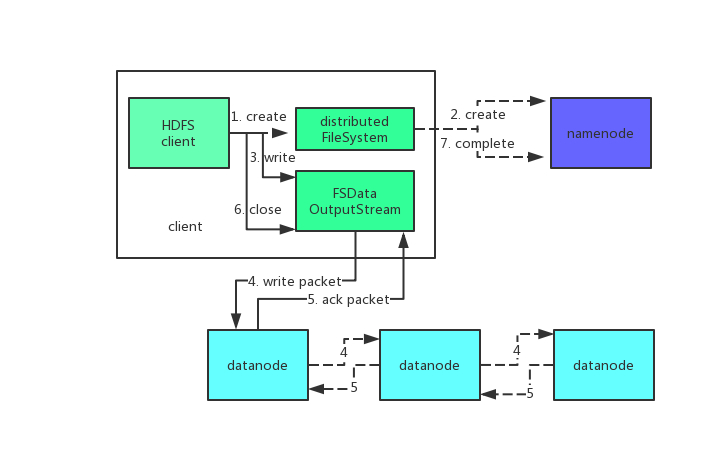
读写数据的代码相似,但是写数据的过程更加复杂,我们一步一步来看。
- 第一步还是一样的,初始化 FileSystem(步骤一),之后 FileSystem 调用 create 方法来创建文件,此时通过远程过程调用 namenode,namenode 会检查以确保这个文件不存在以及客户端有新建该文件的权限,如果检查通过 namenode 会在 edits 记录该操作(步骤二)。
- FileSystem 返回 DFSoutputStream 对象,该对象负责处理 datanode 和 namenode 的通信。当客户端写入数据时(步骤三),DFSOutputStream 将它分为一个个数据包,存到内部的一个队列中(数据队列),DFSOutputStream 处理每个数据块时,先挑选出适合存储该数据块的一组 datanode,这一组 datanode 构成一个管道,假设 HDFS 副本数为 3,那么 DFSOutputStream 将该数据块发送带管道中的第一个 datanode,该 datanode 存储该数据块并把它发送到第二个 datanode 中,以此类推(步骤四)。
- 除了数据队列,DFSOutputStream 还存储了一个确认队列,收到管道中所有 datanode 的确认信息之后,该数据包才会从确认队列中删除(步骤五)。
- 客户端写入后,对数据流(DFSOutputStream)调用 close 方法(步骤六)。
- 告知 namenode 文件写入完成(步骤七)。
以上是关于HDFS架构及文件读写流程的主要内容,如果未能解决你的问题,请参考以下文章