HBase 架构详解及数据读写流程
Posted 禅与计算机程序设计艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase 架构详解及数据读写流程相关的知识,希望对你有一定的参考价值。

什么是 HBase?
Apache HBase 是一种开源 NoSQL 分布式大数据存储。它可以实现对 PB 级数据的随机、严格一致的实时访问。HBase 可非常高效地处理大型稀疏数据集。
HBase 和 Apache Hadoop 及 Hadoop 生态系统无缝集成,使用 Amazon Elastic MapReduce (EMR) 文件系统或 EMRFS 在 Hadoop 分布式文件系统 (HDFS) 或 Amazon S3 顶部运行。HBase 可针对 Hadoop 作为 Apache MapReduce 框架的直接输入和输出,并且与 Apache Phoenix 搭配使用对 HBase 表进行类似于 SQL 的查询。
HBase 如何运作?
HBase 是一种列式非关系数据库。这意味着数据将被存储在单独列中,并且以唯一的行键编列索引。此架构可实现对单独行和列的快速检索,并高效扫描表中的全部单独列。数据和请求分布于 HBase 集群中的全部服务器,让您可以在毫秒内获得 PB 级数据的查询结果。在被用于存储非关系数据,并且通过 HBase API 进行访问时,HBase 可以表现出最高效率。Apache Phoenix 常被用作 HBase 顶部的 SQL 层,您可以使用熟悉的 SQL 语法插入、删除与查询存储在 HBase 中的数据。
内容概括
HBase架构组件:HMaster、HRegion Server、HRegions、ZooKeeper、HDFS
HBase中的HMaster是HBase架构中Master服务器的实现。
当 HBase Region Server 收到来自客户端的写入和读取请求时,它将请求分配到特定的区域,该区域是实际列族所在的区域
HRegions 是 HBase 集群的基本构建元素,由表的分布组成,由 Column families 组成。
HBase Zookeeper 是一个集中式监控服务器,维护配置信息并提供分布式同步。
HDFS 提供高度的容错能力并运行在廉价的商品硬件上。
HBase 数据模型是一组组件,由表、行、列族、单元格、列和版本组成。
面向列和面向行的存储在存储机制上有所不同。
HBase架构及其重要组成部分
HBase 定义
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
HBase的架构图
下面是带有组件的 HBase 的详细架构:
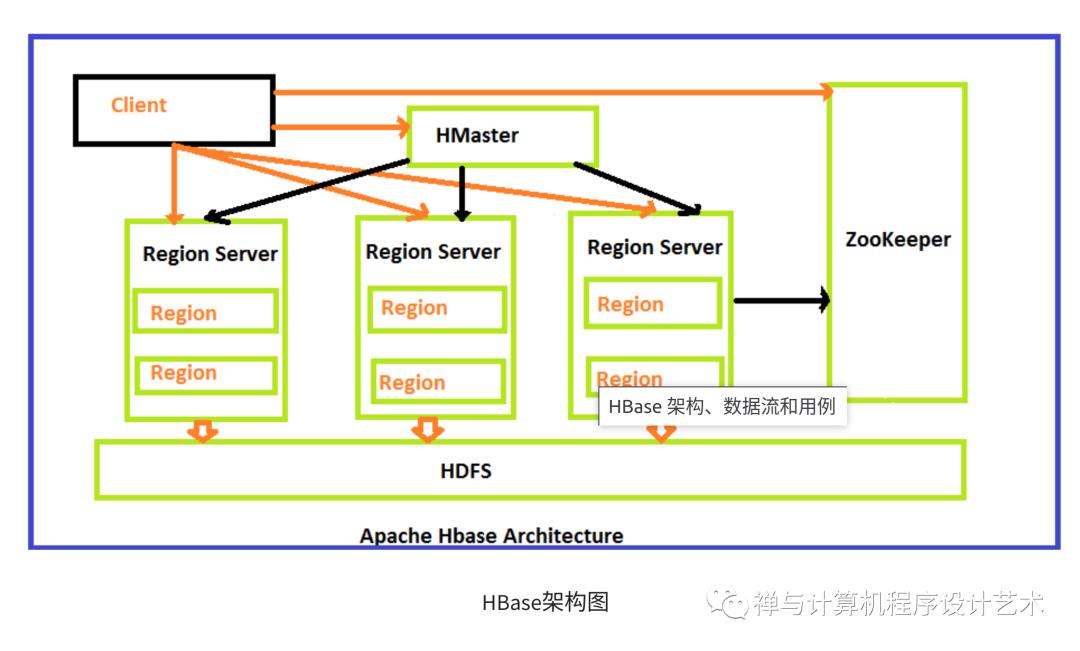
HBase architecture consists mainly of four components:
HMaster
HRegionserver
HRegions
Zookeeper
HDFS
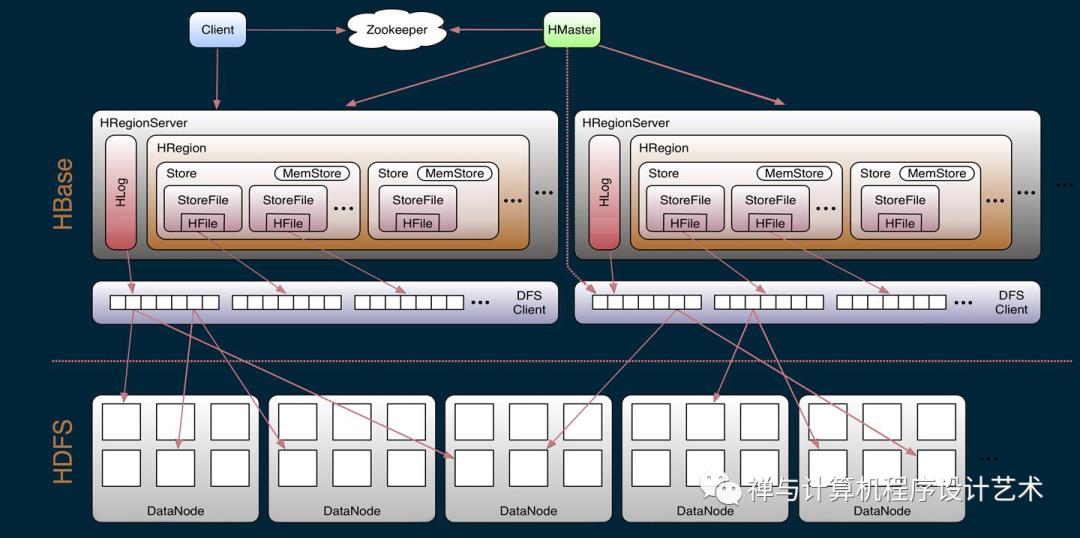
架构角色:
1)Master
Master是所有Region Server的管理者,其实现为 HRegionServer,主要作用有:
对于表的DDL操作:create,delete,alter;
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
2)Zookeeper:
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
3)WAL:
由于数据要经 MemStore 排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写入 Write-Ahead logfile的文件中,然后再写入到Memstore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
HLog(WAL log):HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
4)MemStore:
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
5)StoreFile:
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在StoreFile上是有序的。
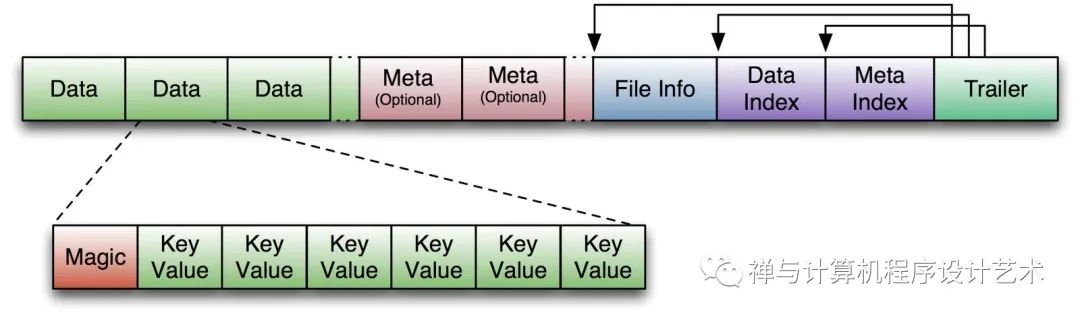
HBase is a type of "NoSQL" database. "NoSQL" is a general term meaning that the database isn’t an RDBMS which supports SQL as its primary access language, but there are many types of NoSQL databases: BerkeleyDB is an example of a local NoSQL database, whereas HBase is very much a distributed database. Technically speaking, HBase is really more a "Data Store" than "Data Base" because it lacks many of the features you find in an RDBMS, such as typed columns, secondary indexes, triggers, and advanced query languages, etc.
However, HBase has many features which supports both linear and modular scaling. HBase clusters expand by adding RegionServers that are hosted on commodity class servers. If a cluster expands from 10 to 20 RegionServers, for example, it doubles both in terms of storage and as well as processing capacity. An RDBMS can scale well, but only up to a point - specifically, the size of a single database server - and for the best performance requires specialized hardware and storage devices. HBase features of note are:
Strongly consistent reads/writes: HBase is not an "eventually consistent" DataStore. This makes it very suitable for tasks such as high-speed counter aggregation.
Automatic sharding: HBase tables are distributed on the cluster via regions, and regions are automatically split and re-distributed as your data grows.
Automatic RegionServer failover
Hadoop/HDFS Integration: HBase supports HDFS out of the box as its distributed file system.
MapReduce: HBase supports massively parallelized processing via MapReduce for using HBase as both source and sink.
Java Client API: HBase supports an easy to use Java API for programmatic access.
Thrift/REST API: HBase also supports Thrift and REST for non-Java front-ends.
Block Cache and Bloom Filters: HBase supports a Block Cache and Bloom Filters for high volume query optimization.
Operational Management: HBase provides build-in web-pages for operational insight as well as JMX metrics.
Data Model:数据模型
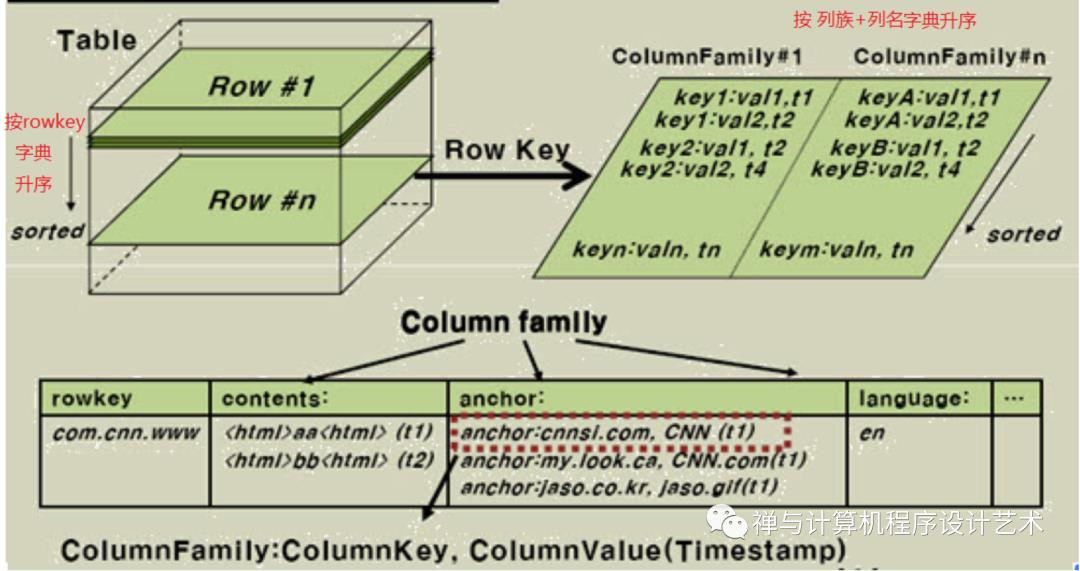
In HBase, data is stored in tables, which have rows and columns. This is a terminology overlap with relational databases (RDBMSs), but this is not a helpful analogy. Instead, it can be helpful to think of an HBase table as a multi-dimensional map.
Scanner体系构建的最终结果是一个由StoreFileScanner和MemstoreScanner组成的heap(最小堆)么,这里就派上用场了。下图是一张表的逻辑视图,该表有两个列族cf1和cf2(我们只关注cf1),cf1只有一个列name,表中有5行数据,其中每个cell基本都有多个版本。cf1的数据假如实际存储在三个区域,memstore中有r2和r4的最新数据,hfile1中是最早的数据。现在需要查询RowKey=r2的数据,按照上文的理论对应的Scanner指向就如图所示:
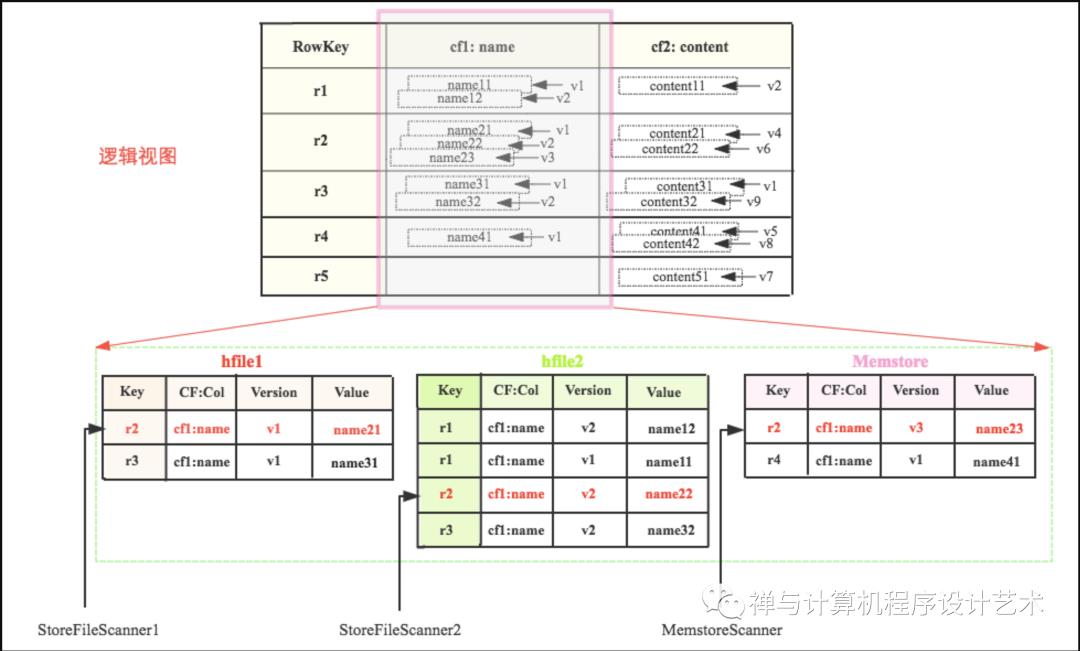
这三个Scanner组成的heap为
<MemstoreScanner,StoreFileScanner2, StoreFileScanner1>
Scanner由小到大排列。查询的时候首先pop出heap的堆顶元素,即MemstoreScanner,得到keyvalue = r2:cf1:name:v3:name23的数据,拿到这个keyvalue之后,需要进行如下判定:
检查该KeyValue的KeyType是否是Deleted/DeletedCol等,如果是就直接忽略该列所有其他版本,跳到下列(列族)
检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略
检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略
检查该KeyValue是否满足用户查询中设定的版本数,比如用户只查询最新版本,则忽略该cell的其他版本;反正如果用户查询所有版本,则还需要查询该cell的其他版本。
Storage Mechanism in HBase
HBase is a column-oriented database and data is stored in tables. The tables are sorted by RowId. As shown below, HBase has RowId, which is the collection of several column families that are present in the table.
The column families that are present in the schema are key-value pairs. If we observe in detail each column family having multiple numbers of columns. The column values stored into disk memory. Each cell of the table has its own Metadata like timestamp and other information.
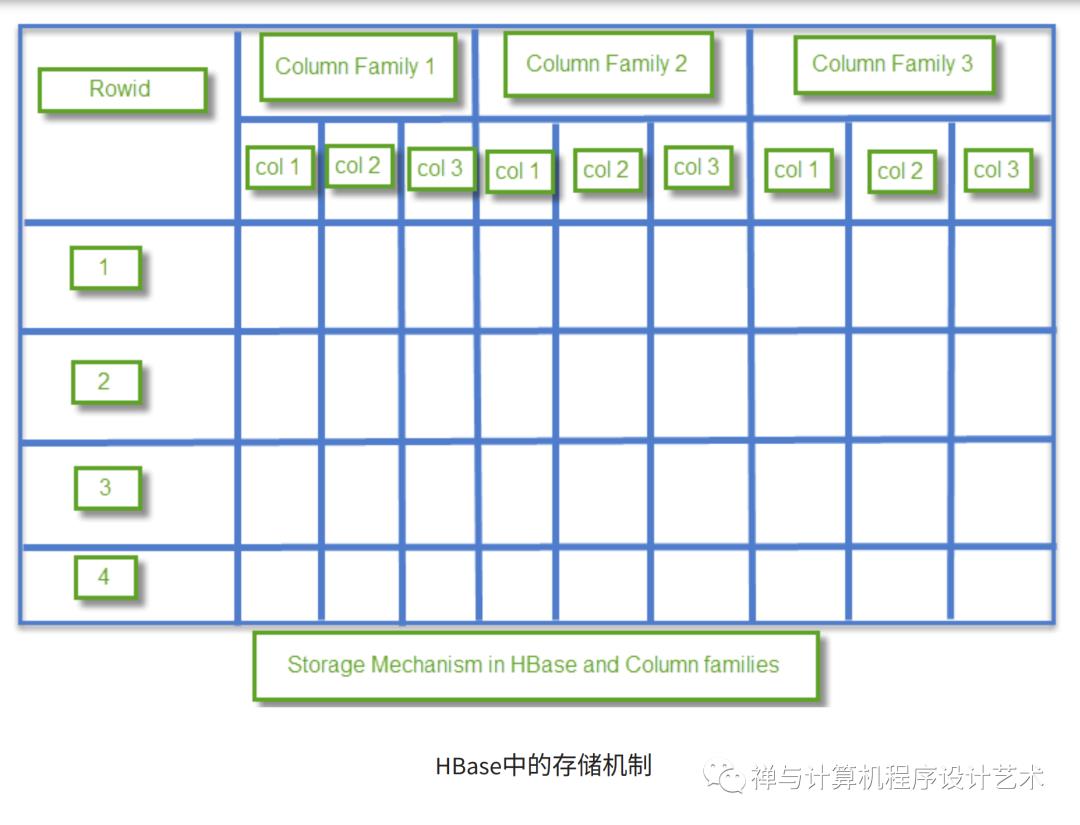
Coming to HBase the following are the key terms representing table schema
Table: Collection of rows present.
Row: Collection of column families.
Column Family: Collection of columns.
Column: Collection of key-value pairs.
Namespace: Logical grouping of tables.
Cell: A row, column, version tuple exactly specifies a cell definition in HBase.
HBase Data Model Terminology
Table
An HBase table consists of multiple rows.
Row
A row in HBase consists of a row key and one or more columns with values associated with them. Rows are sorted alphabetically by the row key as they are stored. For this reason, the design of the row key is very important. The goal is to store data in such a way that related rows are near each other. A common row key pattern is a website domain. If your row keys are domains, you should probably store them in reverse (org.apache.www, org.apache.mail, org.apache.jira). This way, all of the Apache domains are near each other in the table, rather than being spread out based on the first letter of the subdomain.
Column
A column in HBase consists of a column family and a column qualifier, which are delimited by a
:(colon) character.Column Family
Column families physically colocate a set of columns and their values, often for performance reasons. Each column family has a set of storage properties, such as whether its values should be cached in memory, how its data is compressed or its row keys are encoded, and others. Each row in a table has the same column families, though a given row might not store anything in a given column family.
Column Qualifier
A column qualifier is added to a column family to provide the index for a given piece of data. Given a column family
content, a column qualifier might becontent:html, and another might becontent:pdf. Though column families are fixed at table creation, column qualifiers are mutable and may differ greatly between rows.Cell
A cell is a combination of row, column family, and column qualifier, and contains a value and a timestamp, which represents the value’s version.
Timestamp
A timestamp is written alongside each value, and is the identifier for a given version of a value. By default, the timestamp represents the time on the RegionServer when the data was written, but you can specify a different timestamp value when you put data into the cell.
HMaster
HMaster in HBase is the implementation of a Master server in HBase architecture. It acts as a monitoring agent to monitor all Region Server instances present in the cluster and acts as an interface for all the metadata changes. In a distributed cluster environment, Master runs on NameNode. Master runs several background threads.
The following are important roles performed by HMaster in HBase.
Plays a vital role in terms of performance and maintaining nodes in the cluster.
HMaster provides admin performance and distributes services to different region servers.
HMaster assigns regions to region servers.
HMaster has the features like controlling load balancing and failover to handle the load over nodes present in the cluster.
When a client wants to change any schema and to change any Metadata operations, HMaster takes responsibility for these operations.
Some of the methods exposed by HMaster Interface are primarily Metadata oriented methods.
Table (createTable, removeTable, enable, disable)
ColumnFamily (add Column, modify Column)
Region (move, assign)
The client communicates in a bi-directional way with both HMaster and ZooKeeper. For read and write operations, it directly contacts with HRegion servers. HMaster assigns regions to region servers and in turn, check the health status of region servers.
In entire architecture, we have multiple region servers. Hlog present in region servers which are going to store all the log files.
HBase Region Servers
When HBase Region Server receives writes and read requests from the client, it assigns the request to a specific region, where the actual column family resides. However, the client can directly contact with HRegion servers, there is no need of HMaster mandatory permission to the client regarding communication with HRegion servers. The client requires HMaster help when operations related to metadata and schema changes are required.
HRegionServer is the Region Server implementation. It is responsible for serving and managing regions or data that is present in a distributed cluster. The region servers run on Data Nodes present in the Hadoop cluster.
HMaster can get into contact with multiple HRegion servers and performs the following functions.
Hosting and managing regions
Splitting regions automatically
Handling read and writes requests
Communicating with the client directly
HBase Regions
HRegions are the basic building elements of HBase cluster that consists of the distribution of tables and are comprised of Column families. It contains multiple stores, one for each column family. It consists of mainly two components, which are Memstore and Hfile.
ZooKeeper
HBase Zookeeper is a centralized monitoring server which maintains configuration information and provides distributed synchronization. Distributed synchronization is to access the distributed applications running across the cluster with the responsibility of providing coordination services between nodes. If the client wants to communicate with regions, the server’s client has to approach ZooKeeper first.
It is an open source project, and it provides so many important services.
Services provided by ZooKeeper
Maintains Configuration information
Provides distributed synchronization
Client Communication establishment with region servers
Provides ephemeral nodes for which represent different region servers
Master servers usability of ephemeral nodes for discovering available servers in the cluster
To track server failure and network partitions
Master and HBase slave nodes ( region servers) registered themselves with ZooKeeper. The client needs access to ZK(zookeeper) quorum configuration to connect with master and region servers.
During a failure of nodes that present in HBase cluster, ZKquoram will trigger error messages, and it starts to repair the failed nodes.
HDFS
HDFS is a Hadoop distributed File System, as the name implies it provides a distributed environment for the storage and it is a file system designed in a way to run on commodity hardware. It stores each file in multiple blocks and to maintain fault tolerance, the blocks are replicated across a Hadoop cluster.
HDFS provides a high degree of fault –tolerance and runs on cheap commodity hardware. By adding nodes to the cluster and performing processing & storing by using the cheap commodity hardware, it will give the client better results as compared to the existing one.
In here, the data stored in each block replicates into 3 nodes any in a case when any node goes down there will be no loss of data, it will have a proper backup recovery mechanism.
HDFS get in contact with the HBase components and stores a large amount of data in a distributed manner.
HBase Data Model is a set of components that consists of Tables, Rows, Column families, Cells, Columns, and Versions. HBase tables contain column families and rows with elements defined as Primary keys. A column in HBase data model table represents attributes to the objects.
HBase Data Model consists of following elements,
Set of tables
Each table with column families and rows
Each table must have an element defined as Primary Key.
Row key acts as a Primary key in HBase.
Any access to HBase tables uses this Primary Key
Each column present in HBase denotes attribute corresponding to object
HBase Use Cases
Following are examples of HBase use cases with a detailed explanation of the solution it provides to various technical problems
| Problem Statement | Solution |
|---|---|
Telecom Industry faces following Technical challenges
| HBase is used to store billions of rows of detailed call records. If 20TB of data is added per month to the existing RDBMS database, performance will deteriorate. To handle a large amount of data in this use case, HBase is the best solution. HBase performs fast querying and displays records. |
| The Banking industry generates millions of records on a daily basis. In addition to this, the banking industry also needs an analytics solution that can detect Fraud in money transactions | To store, process and update vast volumes of data and performing analytics, an ideal solution is – HBase integrated with several Hadoop ecosystem components. |
That apart, HBase can be used
Whenever there is a need to write heavy applications.
Performing online log analytics and to generate compliance reports.
Column-oriented vs Row-oriented storages
Column and Row-oriented storages differ in their storage mechanism. As we all know traditional relational models store data in terms of row-based format like in terms of rows of data. Column-oriented storages store data tables in terms of columns and column families.
The following Table gives some key differences between these two storages
| Column-oriented Database | Row oriented Database |
|---|---|
|
|
|
|
HBase Read and Write Data Explained
The Read and Write operations from Client into Hfile can be shown in below diagram.
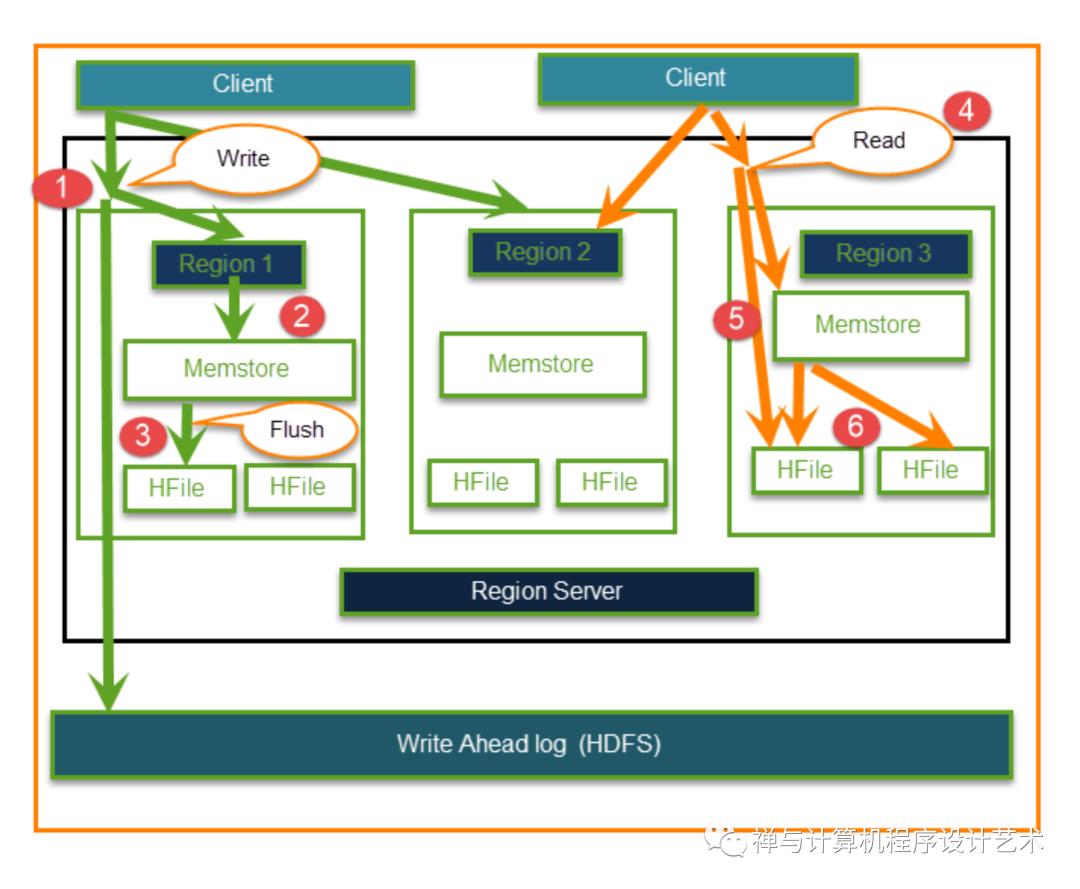
Step 1) Client要写数据,先和Regions server通信,再和regions通信
Step 2) Regions 联系 memstore 存储与列族相关联
Step 3)首先将数据存入Memstore,数据在Memstore中进行排序,然后刷新到HFile。使用 Memstore 的主要原因是将数据存储在基于 Row Key 的分布式文件系统中。Memstore 将放在 Region server 主内存中,而 HFiles 将写入 HDFS。
Step 4) Client要从Regions中读取数据
Step 5)反过来Client可以直接访问Mem store,并且可以请求数据。
步骤 6) Client接近 HFiles 以获取数据。数据由客户端获取和检索。
Step 1) Client wants to write data and in turn first communicates with Regions server and then regions
Step 2) Regions contacting memstore for storing associated with the column family
Step 3) First data stores into Memstore, where the data is sorted and after that, it flushes into HFile. The main reason for using Memstore is to store data in a Distributed file system based on Row Key. Memstore will be placed in Region server main memory while HFiles are written into HDFS.
Step 4) Client wants to read data from Regions
Step 5) In turn Client can have direct access to Mem store, and it can request for data.
Step 6) Client approaches HFiles to get the data. The data are fetched and retrieved by the Client.
Memstore holds in-memory modifications to the store. The hierarchy of objects in HBase Regions is as shown from top to bottom in below table.
| Table | HBase table present in the HBase cluster |
| Region | HRegions for the presented tables |
| Store | It stores per ColumnFamily for each region for the table |
| Memstore |
|
| StoreFile | StoreFiles for each store for each region for the table |
| Block | Blocks present inside StoreFiles |
HBase vs. HDFS
HBase runs on top of HDFS and Hadoop. Some key differences between HDFS and HBase are in terms of data operations and processing.
| HBASE | HDFS |
|---|---|
Low latency operations | High latency operations |
Random reads and writes | Write once Read many times |
Accessed through shell commands, client API in Java, REST, Avro or Thrift | Primarily accessed through MR (Map Reduce) jobs |
Storage and process both can be perform | It’s only for storage areas |
Some typical IT industrial applications use HBase operations along with Hadoop. Applications include stock exchange data, online banking data operations, and processing Hbase is best-suited solution method.
Summary
HBase architecture components: HMaster, HRegion Server, HRegions, ZooKeeper, HDFS
HMaster in HBase is the implementation of a Master server in HBase architecture.
When HBase Region Server receives writes and read requests from the client, it assigns the request to a specific region, where the actual column family resides
HRegions are the basic building elements of HBase cluster that consists of the distribution of tables and are comprised of Column families.
HBase Zookeeper is a centralized monitoring server which maintains configuration information and provides distributed synchronization.
HDFS provides a high degree of fault–tolerance and runs on cheap commodity hardware.
HBase Data Model is a set of components that consists of Tables, Rows, Column families, Cells, Columns, and Versions.
Column and Row-oriented storages differ in their storage mechanism.
HBase 读写流程:
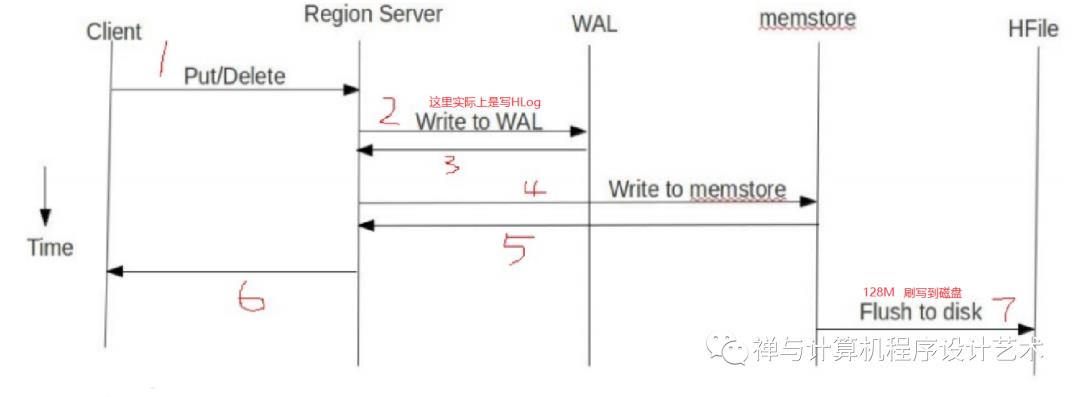
参考资料:
https://hbase.apache.org/book.html#_architecture
Get Started with HBase
Procedure: Download, Configure, and Start HBase in Standalone Mode
Choose a download site from this list of Apache Download Mirrors. Click on the suggested top link. This will take you to a mirror of HBase Releases. Click on the folder named stable and then download the binary file that ends in .tar.gz to your local filesystem. Do not download the file ending in src.tar.gz for now.
Extract the downloaded file, and change to the newly-created directory.
$ tar xzvf hbase-3.0.0-alpha-4-SNAPSHOT-bin.tar.gz $ cd hbase-3.0.0-alpha-4-SNAPSHOT/You must set the
JAVA_HOMEenvironment variable before starting HBase. To make this easier, HBase lets you set it within the conf/hbase-env.sh file. You must locate where Java is installed on your machine, and one way to find this is by using the whereis java command. Once you have the location, edit the conf/hbase-env.sh file and uncomment the line starting with #export JAVA_HOME=, and then set it to your Java installation path.Example extract from hbase-env.sh where JAVA_HOME is set
# Set environment variables here. # The java implementation to use. export JAVA_HOME=/usr/jdk64/jdk1.8.0_112The bin/start-hbase.sh script is provided as a convenient way to start HBase. Issue the command, and if all goes well, a message is logged to standard output showing that HBase started successfully. You can use the
jpscommand to verify that you have one running process calledHMaster. In standalone mode HBase runs all daemons within this single JVM, i.e. the HMaster, a single HRegionServer, and the ZooKeeper daemon. Go to http://localhost:16010 to view the HBase Web UI.
Procedure: Use HBase For the First Time
Connect to HBase.
Connect to your running instance of HBase using the
hbase shellcommand, located in the bin/ directory of your HBase install. In this example, some usage and version information that is printed when you start HBase Shell has been omitted. The HBase Shell prompt ends with a>character.$ ./bin/hbase shell hbase(main):001:0>Display HBase Shell Help Text.
Type
helpand press Enter, to display some basic usage information for HBase Shell, as well as several example commands. Notice that table names, rows, columns all must be enclosed in quote characters.Create a table.
Use the
createcommand to create a new table. You must specify the table name and the ColumnFamily name.hbase(main):001:0> create 'test', 'cf' 0 row(s) in 0.4170 seconds => Hbase::Table - testList Information About your Table
Use the
listcommand to confirm your table existshbase(main):002:0> list 'test' TABLE test 1 row(s) in 0.0180 seconds => ["test"]Now use the
describecommand to see details, including configuration defaultshbase(main):003:0> describe 'test' Table test is ENABLED test COLUMN FAMILIES DESCRIPTION NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'f alse', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536' 1 row(s) Took 0.9998 secondsPut data into your table.
To put data into your table, use the
putcommand.hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1' 0 row(s) in 0.0850 seconds hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2' 0 row(s) in 0.0110 seconds hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3' 0 row(s) in 0.0100 secondsHere, we insert three values, one at a time. The first insert is at
row1, columncf:a, with a value ofvalue1. Columns in HBase are comprised of a column family prefix,cfin this example, followed by a colon and then a column qualifier suffix,ain this case.Scan the table for all data at once.
One of the ways to get data from HBase is to scan. Use the
scancommand to scan the table for data. You can limit your scan, but for now, all data is fetched.hbase(main):006:0> scan 'test' ROW COLUMN+CELL row1 column=cf:a, timestamp=1421762485768, value=value1 row2 column=cf:b, timestamp=1421762491785, value=value2 row3 column=cf:c, timestamp=1421762496210, value=value3 3 row(s) in 0.0230 secondsGet a single row of data.
To get a single row of data at a time, use the
getcommand.hbase(main):007:0> get 'test', 'row1' COLUMN CELL cf:a timestamp=1421762485768, value=value1 1 row(s) in 0.0350 secondsDisable a table.
If you want to delete a table or change its settings, as well as in some other situations, you need to disable the table first, using the
disablecommand. You can re-enable it using theenablecommand.hbase(main):008:0> disable 'test' 0 row(s) in 1.1820 seconds hbase(main):009:0> enable 'test' 0 row(s) in 0.1770 secondsDisable the table again if you tested the
enablecommand above:hbase(main):010:0> disable 'test' 0 row(s) in 1.1820 secondsDrop the table.
To drop (delete) a table, use the
dropcommand.hbase(main):011:0> drop 'test' 0 row(s) in 0.1370 secondsExit the HBase Shell.
To exit the HBase Shell and disconnect from your cluster, use the
quitcommand. HBase is still running in the background.
Procedure: Stop HBase
In the same way that the bin/start-hbase.sh script is provided to conveniently start all HBase daemons, the bin/stop-hbase.sh script stops them.
$ ./bin/stop-hbase.sh stopping hbase.................... $After issuing the command, it can take several minutes for the processes to shut down. Use the
jpsto be sure that the HMaster and HRegionServer processes are shut down.
The above has shown you how to start and stop a standalone instance of HBase. In the next sections we give a quick overview of other modes of hbase deploy.
【更多阅读】
《人月神话》8 胸有成竹(Chaptor 8.Calling the Shot -The Mythical Man-Month)
《人月神话》(The Mythical Man-Month)5画蛇添足(The Second-System Effect)
《人月神话》(The Mythical Man-Month)4概念一致性:专制、民主和系统设计(System Design)
Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!
十年技术进阶路:让我明白了三件要事。关于如何做好技术 Team Leader?如何提升管理业务技术水平?(10000字长文)
以上是关于HBase 架构详解及数据读写流程的主要内容,如果未能解决你的问题,请参考以下文章