论文阅读2021中国法研杯司法考试数据集研究(CAIL2021)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读2021中国法研杯司法考试数据集研究(CAIL2021)相关的知识,希望对你有一定的参考价值。
英文标题:JEC-QA: A Legal-Domain Question Answering Dataset
中文标题:法律领域问答数据集
论文下载:arxiv@1911.12011
项目地址:GitHub@CAIL2021
比赛链接:CAIL2021@司法考试
序言
本论文是关于中国法律智能技术评测 2021 2021 2021比赛中司法考试任务数据集的构成与一些测试模型的评估。在上面的项目地址GitHub@CAIL2021中已有测试模型,但是它完全没有应用到数据集中给到的参考书目文档,笔者在阅读本论文前认为参考书目文档可能可以用于数据增强,或用于构建知识图谱以预训练得到更好的题干及选项的语义表示。诸多尝试后,笔者决定还是先参考原作者已完成的工作,事实上原作者是将司法考试任务视为阅读理解任务来评估的,其中使用到 ElasticSearch \\textElasticSearch ElasticSearch检索以及多级推理等技术,这意味着该任务的解决思路将会十分开阔,但是该任务本身的困难程度是非常高的,因为目前机器做题的成绩远远差于普通人类的水平。
笔者建议对该任务感兴趣的朋友可以先阅读本文以熟悉前人的解决思路,然后再加以改进并测试。项目地址GitHub@CAIL2021中的基线模型的正确率大约为 26 % 26\\% 26%,这已经足以通过该评测任务第一阶段的测试了。
其实这个任务目前也没有多少队伍在做,笔者只是对这个话题非常感兴趣,所以花了一些功夫。个人觉得对参考书目文档的预处理是非常重要的,其中有许多冗余的信息,然后数据集中的subject字段是存在缺失的,而这个字段其实对信息检索是非常有帮助的,所以需要额外训练模型对该字段进行预测,这个笔者之前也想到了,在本论文中原作者也强调了这一点的必要性。
文章目录
- 序言
- 摘要 Abstract \\textAbstract Abstract
- 1 1 1 引入 Introduction \\textIntroduction Introduction
- 2 2 2 相关工作 Related Work \\textRelated Work Related Work
- 3 3 3 数据集构成与分析 Dataset Construction and Analysis \\textDataset Construction and Analysis Dataset Construction and Analysis
- 4 4 4 实验 Experiments \\textExperiments Experiments
- 4.1 4.1 4.1 检索策略 Retrieve Strategy \\textRetrieve Strategy Retrieve Strategy
- 4.2 4.2 4.2 实验配置 Experiment Settings \\textExperiment Settings Experiment Settings
- 4.3 4.3 4.3 基线 Baselines \\textBaselines Baselines
- 4.4 4.4 4.4 实验结果 Experimental Results \\textExperimental Results Experimental Results
- 4.5 4.5 4.5 比较分析 Comparative Analysis \\textComparative Analysis Comparative Analysis
- 4.6 4.6 4.6 案例分析 Case Study \\textCase Study Case Study
- 5 5 5 结论 Conclusion \\textConclusion Conclusion
- 6 6 6 致谢 Acknowledgements \\textAcknowledgements Acknowledgements
- 附录 A \\textA A:参考文献
- 后记
摘要 Abstract \\textAbstract Abstract
-
本文提出目前规模最大的法律领域问答数据集 JEC-QA \\textJEC-QA JEC-QA,数据源为中国国家司法考试(National Judicial Examination of China,下简称为 NJEC \\textNJEC NJEC)真题,每年 NJEC \\textNJEC NJEC的通过率约为 10 % 10\\% 10%。
-
司法考试中通常需要检索相关法条以完成答题,这属于逻辑推理的过程,因此常规的问答模型在 JEC-QA \\textJEC-QA JEC-QA数据集上的表现并不是很好,最先进的问答模型也只能取得 28 % 28\\% 28%的正确率,而专业人员平均能够达到 81 % 81\\% 81%的正确率,即便是非专业人员稍加训练一般也能达到 64 % 64\\% 64%的正确率,因此人类与机器在司法考试任务上的表现差异巨大。
-
JEC-QA \\textJEC-QA JEC-QA数据集可以从官网获得:该数据集需要发送邮件向原作者申请获得,如果急需使用的可以通过笔者分享的链接下载👇
链接: https://pan.baidu.com/s/1vDvklLaFFqNtT7T9-mZ0iw 提取码: s3u5此外, JEC-QA \\textJEC-QA JEC-QA比CAIL2021@司法考试提供的数据集更加完整,两者训练集完全相同,但 JEC-QA \\textJEC-QA JEC-QA中额外提供测试集与法学参考教材的文档数据。
1 1 1 引入 Introduction \\textIntroduction Introduction
-
法律问答(Legal Question Answering,下简称为 LQA \\textLQA LQA)旨在为法律问题提供解释,建议以及解决方案。合格的 LQA \\textLQA LQA系统不仅可以为非专业人员提供专业咨询服务,而且还能帮助专业人员提高工作效率(如更加准确地分析真实案件)。
-
LQA \\textLQA LQA的两大难点:
① 高质量的 LQA \\textLQA LQA训练数据集稀缺;
② 法律领域的案例与问题都是复杂且细致的;
-
大部分 LQA \\textLQA LQA问题可以划分为两种典型的类别,如Table 1所示:

① 知识驱动的(knowledge-driven,下简称为 KD \\textKD KD)问题:理解特定法律概念;
② 案例分析的(case-analysis,下简称为 CA \\textCA CA)问题:分析真实案件;
两类问题都要求模型具有复杂推理能力与文本理解能力,因此 LQA \\textLQA LQA是自然语言处理中非常困难的任务。
-
JEC-QA \\textJEC-QA JEC-QA数据集概述:
① 数据集中共计 26365 26365 26365条多项选择题,每条选择题包含 4 4 4个选项,规模是参考文献 [ 23 ] [23] [23]中数据集的 50 50 50倍;
② 数据集中包含一套全国统一法律职业资格考试辅导书和中国法律规定构成的参考书目文档(详见 JEC-QA \\textJEC-QA JEC-QA数据集中 reference_book \\textreference\\_book reference_book目录下的内容);
③ 数据集中标注了部分问题所属的 KD \\textKD KD和 CA \\textCA CA类别,以及问题所属的法律类型(如属于国际经济法问题,刑法问题等),如何由专家提供的额外标签对 LQA \\textLQA LQA的深度分析是很有帮助的;
-
原作者可能是希望我们从 JEC-QA \\textJEC-QA JEC-QA的参考书目中检索相关文档,再使用阅读理解模型来回答相关问题,其中又涉及单词匹配(word matching),概念理解(concept understanding),数词分析(numerical analyis),多段落阅读(multi-paragraph reading),多级推理(multi-hop reasoning)等技术。
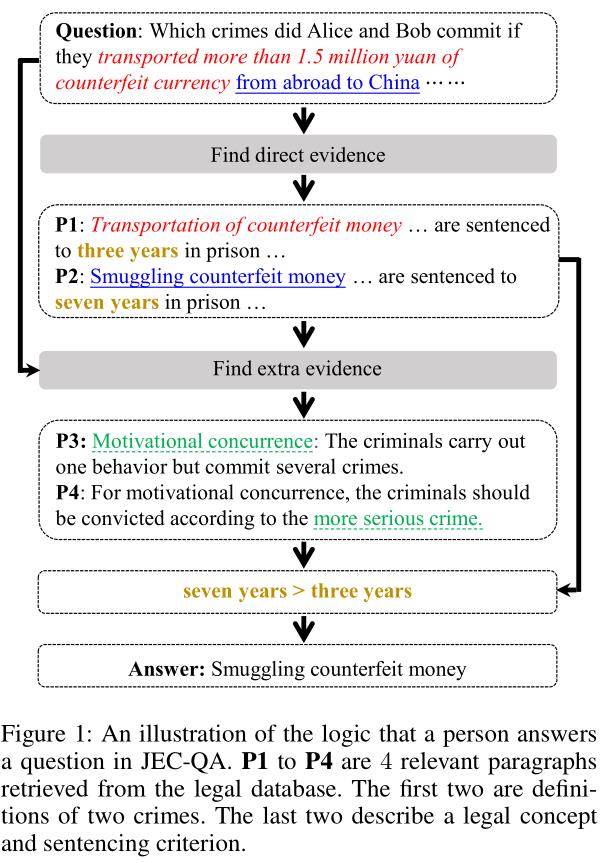
以Figure 1为例,图中描述的是一种犯罪行为导致两种不同的犯罪类型,要求模型必须理解Motivational Concurrence并推理出除单词级别的语义匹配(lexical-level semantic matching)外的其他证据。此外,模型需要通过多段落阅读与多级推理来结合直接证据和其他证据来回答问题,数词分析需要被用来比较哪一种犯罪行为是更加严重的。
-
本文设计了统一的问答架构并实现了 7 7 7种代表性的神经阅读理解模型,通过将这些方法在 JEC-QA \\textJEC-QA JEC-QA数据集上进行测试,发现最好的方法也只能取得大约 25 % 25\\% 25%和 29 % 29\\% 29%的正确率(分别在 KD \\textKD KD和 CA \\textCA CA问题类别上),该水平远远低于人类的表现。实验结果表明现存的问答方法无法在 JEC-QA \\textJEC-QA JEC-QA上进行复杂的多级推理,并且难以理解法律概念。
2 2 2 相关工作 Related Work \\textRelated Work Related Work
2.1 2.1 2.1 阅读理解 Reading Comprehension \\textReading Comprehension Reading Comprehension
-
阅读理解数据集(近十年内提出):
① 相对早期的数据集( 2013 2013 2013至 2016 2016 2016年):基于以下数据集,参考文献 [ 11 , 42 , 43 , 52 ] [11,42,43,52] [11,42,43,52]中都提出了不同的深度阅读理解模型并取得很好的评估结果。
-
CNN/DailyMail \\textCNN/DailyMail CNN/DailyMail:参考文献 [ 17 ] [17] [17]
-
MCTest \\textMCTest MCTest:参考文献 [ 35 ] [35] [35]
-
SQuAD \\textSQuAD SQuAD:参考文献 [ 33 ] [33] [33]
-
WikiQA \\textWikiQA WikiQA:参考文献 [ 50 ] [50] [50]
-
NewsQA \\textNewsQA NewsQA:参考文献 [ 39 ] [39] [39]
② 回答问题涉及概括多篇不同文本的数据集( 2016 2016 2016至 2017 2017 2017年):基于以下数据集,参考文献 [ 07 , 44 , 45 , 47 ] [07,44,45,47] [07,44,45,47]提出汇总多文本信息的技术。
-
TrivialQA \\textTrivialQA TrivialQA:参考文献 [ 21 ] [21] [21]
-
MS-MARCO \\textMS-MARCO MS-MARCO:参考文献 [ 31 ] [31] [31]
-
DuReader \\textDuReader DuReader:参考文献 [ 16 ] [16] [16]
③ 回答问题涉及逻辑推理的数据集( 2017 2017 2017至 2018 2018 2018年):目前依然缺乏具有逻辑推理能力的阅读理解模型。
-
RACE \\textRACE RACE:参考文献 [ 28 ] [28] [28]
-
HotpotQA \\textHotpotQA HotpotQA:参考文献 [ 49 ] [49] [49]
-
ARC \\textARC ARC:参考文献 [ 07 ] [07] [07]
-
2.2 \\text2.2 2.2 开放领域问答 Open-domain Question Answering \\textOpen-domain Question Answering Open-domain Question Answering
-
开放领域问答(下简称为 OpenQA \\textOpenQA OpenQA)的概念在参考文献 [ 14 ] [14] [14]种首次提出,其旨在借助外部知识库来回答问题,早期的研究一般借助人工收集的知识文档(参考文献 [ 03 , 27 , 41 ] [03,27,41]
阅读论文《基于神经网络的数据挖掘分类算法比较和分析研究》 安徽大学 工程硕士:常凯 数据集的介绍
MSRA研究获ICCV 2021最佳论文,接收论文近半来自中国学者,脸部相关研究被拒率最高...