阅读论文《基于神经网络的数据挖掘分类算法比较和分析研究》 安徽大学 工程硕士:常凯 数据集的介绍
Posted Adaisme
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读论文《基于神经网络的数据挖掘分类算法比较和分析研究》 安徽大学 工程硕士:常凯 数据集的介绍相关的知识,希望对你有一定的参考价值。
数据集的介绍
1.“鲍鱼年龄”数据集(Abalone Data Set)。是通过预测鲍鱼环,也就是鲍鱼的年轮,来推断鲍鱼寿命。该数据集来自于UCI(University of California,Irvine,UCI)提出的用于机器学习的数据库。

共有八个属性分别是:性别、长度、直径等
具体的属性的介绍

方法一:利用BP
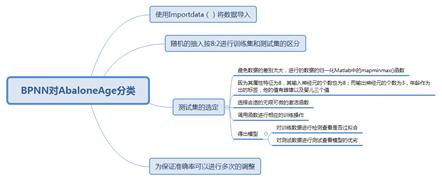
方法使用ELM

方法三:使用SVM
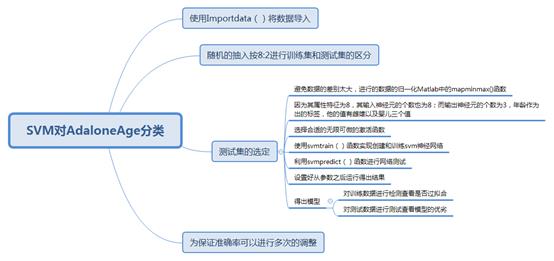
我:通过Xmind函数发现其实对一种新的方法而言函数都是集成可以直接用的,我们要做的就是知道每个函数的具体的意义,以及知道大致的流程。理解是一切的基础,也是我们可以自由的使用函数的基础
2.“是否有心脏病”集的介绍
(Statlog (Heart)Data Set)是通过研究年龄,性别,血压等属性的值来判断被访者是否有心脏病。

具体的属性的特征:

chest pain 胸痛
resting blood pressure 静息血压
serum cholestoral 血清胆汁酸
fasting blood sugar 空腹血糖
resting electrocardiographic results 休息心电图结果
maxinum heart rate achieved 最大心跳速率
exercise induced angina 锻炼诱发心绞痛
oldpeak
the slope of the peak exercise ST segment 锻炼高峰期ST段的斜率
number of major vessels 血管容量
thal 塔尔
输入:13个属性 输出:是1,否0
分别是三中方法处理:
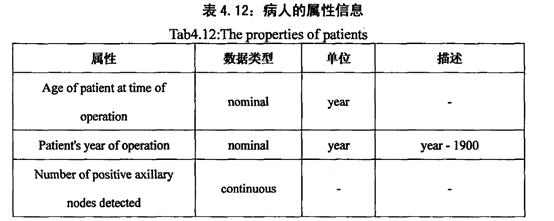
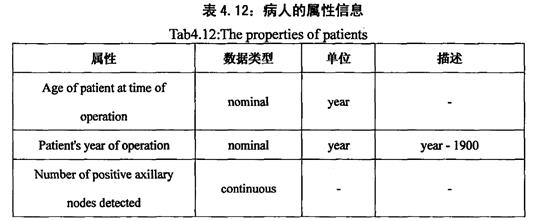
3.“癌症患者生存期”集的介绍
(Haberman‘s Survival Data Set’),是通过岁病人手术时的年龄,手术年份,检测到阳性腋窝淋巴结数三个方面,来判断病人的生存状况

三个属性分别为:病人手术时的年龄,病人手术的年份,腋窝淋巴结阳性检测出的数量
病人的生存状况:1代表病人存活了五年甚至更久,2代表并没没活过5年
输入:三个属性
输出:两个标签
4.“小麦种子集”(Seed Data Set)
通过不同的三种小麦种子(Kama、Rosa、Canadian)的物理的特性进而去判断种子的类型
具体的属性:
Perimeter 周长
Compactness 紧凑
length of kernel 内核长度
width of kernel 内核宽度
asymmetry coefficient 不对称系数
length of kernel groove 谷纹长度
输入:以上的这些属性
输出:就是判别属于那种类型
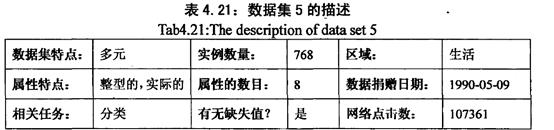
5.“印第安人是否有糖尿病”
(pima Indians Diabetes Data Set)是通过研究八个数值类型的属性然后的出相应的结论的判别。
数据集的最后一个部分为分类的属性:0表示没有糖尿病;1表示有
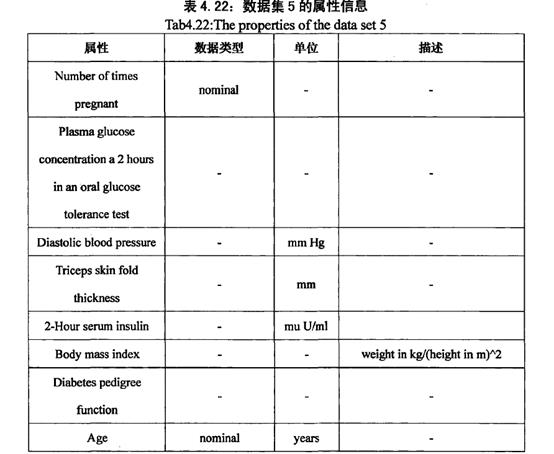
Plasma glucose concentration a 2 hours in an oral glucose tolerance test
在口服葡萄糖耐量试验中血浆葡萄糖浓度为2小时
Diastolic blood pressure 舒张压
Triceps skin fold thickness 三头肌皮褶厚度
2-hours serum insulin 2小时血清胰岛素
Body mass index 体重指数
Diabetes pedigree function 糖尿病谱系功能
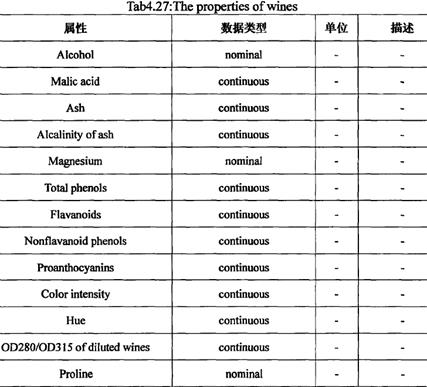
6.“普葡萄酒种类”
(Wine Data Set)记录的是在意大利同一个区域里三种不同品种的葡萄酒的化学成分分析的结果。
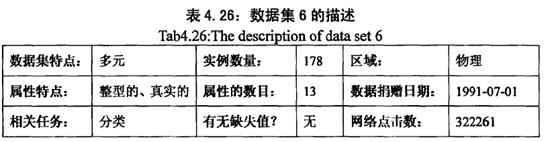
具体的属性为:
以上是关于阅读论文《基于神经网络的数据挖掘分类算法比较和分析研究》 安徽大学 工程硕士:常凯 数据集的介绍的主要内容,如果未能解决你的问题,请参考以下文章