集合
Posted Spring-_-Bear
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集合相关的知识,希望对你有一定的参考价值。
第14章 集合
499. 集合介绍
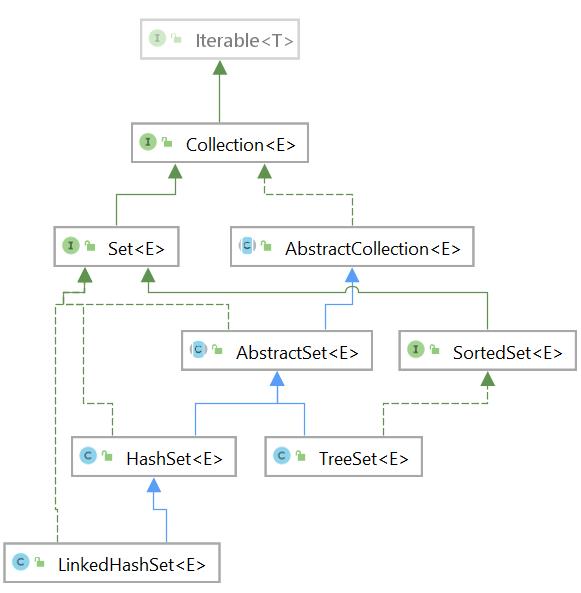
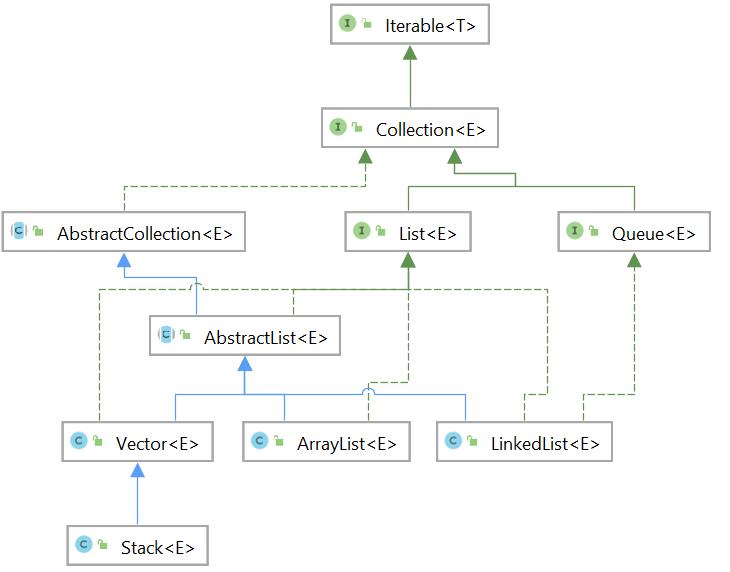
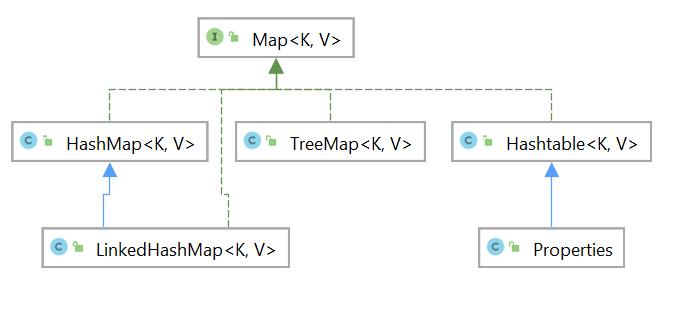
500. 集合体系图
- Set 集合体系图
- List 集合体系图
- Map 集合体系图
501. Collection方法
- Collection 接口没有直接的实现子类,是通过它的子接口 Set 和 List 来实现的
// 只要是 Collection 接口的是实现类都可以做实参
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean containsAll(Collection<?> c);
502. 迭代器遍历
-
Iterator 对象称为迭代器,主要用于遍历 Collection 集合中的元素
-
所有实现了 Collection 接口的集合类都有一个 iterator() 方法,用以返回一个实现了 Iterator 接口的对象即可以返回一个迭代器
-
Iterator 对象仅用于遍历集合,本身并不存放数据对象
// 得到某个集合的迭代器
Iterator iterator = collection.iterator();
// 判断是否还有下一个元素
while(iterator.hasNext())
System.out.println(iterator.next());
503. 集合增强for
- 使用增强 for 循环遍历集合时,底层仍然使用的 Iterator 进行遍历
504. 测试题
505. List接口方法
- 实现 List 的集合类中的元素有序(加入顺序与取出顺序一致),允许存在重复
- 支持使用对应的索引值直接获取元素的值
// 在索引为 index 的位置插入 element,后续元素后移
void add(int index, E element);
// 指定起始索引的子集合 [fromIndex,toIndex)
List<E> subList(int fromIndex, int toIndex);
506. List接口练习
507. List三种遍历方式
508. List排序练习
509. ArrayList注意事项
- ArrayList 可以添加多个空元素,底层由 Object[] 数组实现来存储数据
- ArrayList 基本等同于 Vector,除了 ArrayList 是线程不安全的,执行效率比 Vector 高,多线程条件下最好不使用 ArrayList
510. ArrayList扩容机制
- ArrayList 中维护了一个 Object 类型的数组 elementData 即 transient Object[] elementData
- 若创建 ArrayList 对象时使用的是无参构造器,则 elementData 初始容量为 0,第 1 次添加后设置容量为 10,此后按照 elementData 容量的 1.5 倍进行扩容
- 若使用的是指定容量大小的构造器,则 elementData 的初始容量为指定大小,需要扩容时按照 1.5 进行扩容
511. ArrayList底层源码1
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity)
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
512. ArrayList底层源码2
513. Vector注意事项
- Vector 底层存储数据时是一个对象数组即 protected Object[] elementData
- Vector 是线程安全的,在开发中,需要考虑线程同步安全时,考虑使用 Vector 而不是 ArrayList
514. Vector源码解读
- 创建 Vector 的对象时若使用无参构造器,则默认初始化容量为 0,当第 1 次添加元素时设置容量大小为 10,此后按 2 倍扩容;若使用了有参构造器,则初始容量为指定大小,此后按照 2 倍扩容
private void grow(int minCapacity)
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
515. 双向链表模拟
-
LinkedList 具有双向链表和双端队列特点;可以添加多个 null 元素,允许重复;线程不安全
-
LinkedList 底层维护了一个双向链表,类中有两个属性 transient Node first 和 transient Node last 分别指向头节点和尾节点
// LinkedList 的内部类 Node private static class Node<E> E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) this.item = element; this.next = next; this.prev = prev; -
每个节点中又维护了 prev、next、item 三个属性,所以 LinkedList 元素的增加与删除效率较高
516. LinkedList源码图解
// 添加新节点到表尾
void linkLast(E e)
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
// 移除头节点
private E unlinkFirst(Node<E> f)
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
517. List集合选择
518. Set接口方法
- Set 中的元素无序,没有索引,因而只有两种遍历方式
- Set 不允许重复元素,故最多只包含一个 null
519. HashSet全面说明
- HashSet 的底层使用的是 HashMap,HashMap 底层是(数组 + 链表 + 红黑树)
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet()
map = new HashMap<>();
520. 数组链表模拟
// 确定元素 hash 值的算法
static final int hash(Object key)
int h;
// key 的 hashCode 与 key 无符号右移 16 位的值进行按位异或 ^ 运算得到元素得 hash 值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- 元素存放过程:先通过 hash(Object) 方法获得本次元素的 hash 值,将 hash 值与本次哈希表大小 -1 的值进行按位与运算获得此元素在哈希表中的位置号,如果该位置上没有其它元素则直接存放;如果存在,则遍历链表判断是否已经存在相同元素,如果存在则不添加并且返回元素值,否则创建新的节点连接到链表尾(判断两个元素是否相同的条件:当前元素的 hash 值与哈希表位置号上元素的 hash 值相同且值相同(引用相同)或者 要添加的元素不为空且 equals 比较相同)
521. HashSet扩容机制
- 在 Java 8 中,如果哈希表的大小 >= 64 且某条链表的长度 >= 8 则会将该条链表树化为红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
static final int TREEIFY_THRESHOLD = 8;
522. HashSet源码解读1
- HashMap 为键值对,所以在 HashSet 采用 HaspMap 实现存储时,value 为系统给定的 PRESENT
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
523. HashSet源码解读2
- HashMap 实现添加元素的方法
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table 为 HashMap 属性,Node 类型的数组,进行第一次扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 用本次哈希表长度减 1 与本次元素的 hash 值进行按位与运算获得元素在哈希表中的位置号
if ((p = tab[i = (n - 1) & hash]) == null)
// 位置号上未存储元素则直接存放
tab[i] = newNode(hash, key, value, null);
else
// 判断是否存在相同的元素,不存在则存放到此条链表的末尾
Node<K,V> e; K k;
// 如果当前元素的 hash 值与哈希表位置号上元素的 hash 值相同且值相同(引用相同)或者 要添加的元素不为空且 equals 比较相同,则不添加
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断当前位置号是否是红黑树数据结构,是则按照红黑树方式添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else
// 遍历此位置号上的链表元素,判断是否与当前需要加入的元素相同
for (int binCount = 0; ; ++binCount)
// 不相同,添加到链表尾
if ((e = p.next) == null)
p.next = newNode(hash, key, value, null);
// 判断该条链表上的元素个数是否 >= 8个,是则进行是否树化判断
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
// 如果存在相同的元素则不添加
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
// 存在相同元素,则不添加,返回旧值
if (e != null) // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
++modCount;
// size 加入到哈希表中的元素个数
// 判断加入的元素个数是否不小于临界值,是则对哈希表进行扩容
if (++size > threshold)
resize();
// HashMap 的空方法,留给子类实现以扩展功能
afterNodeInsertion(evict);
// 返回 null 代表元素添加成功
return null;
524. HashSet源码解读3
- HashMap 实现扩容的方法:第一次添加时 table 扩容到 DEFAULT_INITIAL_CAPACITY 16,加载因子为 loadFactor 0.75,临界值为 threshold 12,如果 table 已添加 threshold 个元素,则 table 按照 2 倍方式扩容到 32,临界值为 24,依次类推
- 如果 table 大小不小于 MIN_TREEIFY_CAPACITY 64 且某条链表的长度不小于 TREEIFY_THRESHOLD 8,则将该条链表树化为红黑树
525. HashSet源码解读4
// 判断加入的元素个数是否不小于临界值,是则对哈希表进行扩容
if (++size > threshold)
resize();
526. HashSet最佳实践
527. HashSet思考题
528. LinkedHashSet介绍
- LinkedHashSet 底层使用 LinkedHashMap,底层维护了一个 数组 + 双向链表
- LinkedHashSet 根据元素的 hashCode 值来决定元素都得存储位置,同时使用链表维护元素的次序,使得元素看起来是以插入顺序保存的;不允许添加重复元素
- LinkedHashSet 有 head 和 tail 指针,使用使用头尾指针遍历 linkedHashSet 时取出元素的顺序与插入元素的顺序一致
- LinkedHashSet 在添加一个元素时,先求 hash 值,再求在哈希表中的索引号,然后判断元素是否添加
529. LinkedHashSet源码解读
- LinkedHashSet 底层数组的类型是 HashMap$Node[],其中存放的元素是 LinkedHashMap$Entry 类型
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V>
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V>
530. LinkedHashSet课堂练习
531. Map接口特点1
- Map 与 Collection 并列存在,用于保存具有映射关系的键值对:key - value
- Map 中的 key 和 value 可以是任何引用类型,k - v 会封装到 HashMap$Node 对象中,因为 Node 实现了 Entry 接口
- Map 中的 key 不允许重复,value 可以重复;key 最多有一个 null,value 可以有多个 null;当 key 相同而 value 不同时,用新的 value 替换旧的 value
532. Map接口特点2
- key - value 的值存放到 HashMap$Node 中,为单独方便遍历 key 或 value,使用 KeySet(Set 类型) 引用到 Node 中所有的 key,使用 Values (Collection 类型)引用到所有的 value;将对应的 key - value 封装到 Entry 中,再将 Entry 存放到 EntrySet 中
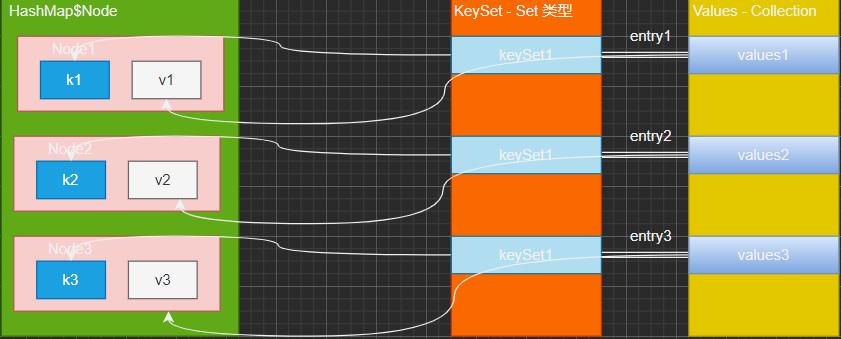
// EntrySet
final class EntrySet extends AbstractSet<Map.Entry<K,V>>
// KeySet
final class KeySet extends AbstractSet<K>
// Values
final class Values extends AbstractCollection<V>
- EntrySet 使用示例
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("李春雄", 21);
// 通过 Entry 遍历
Set<Map.Entry<Object, Object>> entries = hashMap.entrySet();
for (Map.Entry<Object, Object> entry : entries)
System.out.println(entry);
System.out.println("key = " + entry.getKey());
System.out.println("value = " + entry.getValue());
// 通过 KeySet 遍历所有的 key
Set<Object> keySet = hashMap.keySet();
for (Object object : keySet)
System.out.println("key = " + object);
// 通过 Values 遍历所有的 value
Collection<Object> values = hashMap.values();
for (Object value : values)
System.out.println(value);
533. Map接口方法
534. Map六大遍历方式
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("李春雄", 21);
// 使用增强 for 的地方也可以使用迭代器
// 1. 通过 EntrySet 遍历
Set<Map.Entry<Object, Object>> entrySet = hashMap.entrySet();
for (Map.Entry<Object, Object> entry : entrySet)
System.out.println(entry);
// 2. 通过 KeySet 遍历
Set<Object> keySet = hashMap.keySet();
for (Object key : keySet)
System.out.println(key + " - " + hashMap.get(key));
// 3. 使用 Map.Entry 的 getKey() 和 getValue() 方法
for (Map.Entry<Object, Object> entry : entrySet)
System.out.println(entry.getKey() + " - " + entry.getValue());
535. Map课堂练习
536. HashMap阶段小结
- key - value 封装在 HashMap$Node;HashMap 线程不安全
// key 相同而 value 不同时的替换 value 的机制
if (e != null) // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
537. HashMap底层机制
- JDK 7.0 的 HashMap 底层实现是(哈希表 + 链表),JDK 8.0 是(哈希表 + 链表 + 红黑树)
- 若某颗红黑树元素个数较少,则会触发剪枝行为即将红黑树转换为链表
538. HashMap源码解读
539. HashMap扩容树化触发
540. Hashtable使用
- Hashtable 的键和值都不能为 null,为 null 则抛出 NullPointerException,使用方法与 HashMap 基本一致;Hashtable 线程安全,HashMap 线程不安全
541. Hashtable扩容
- Hashtable 初始化容量大小为 11,数组类型为 Hashtable$Entry;加载因子 loadFactor 0.75;按原有容量的 2 倍加 1 的机制进行扩容
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
542. Properties
543. 集合选型规则

544. TreeSet源码解读
// 排序使用示例
TreeSet<String> treeSet = new TreeSet<>(new Comparator<Object>()
@Override
public int compare(Object o1, Object o2)
return ((String) o2).length() - ((以上是关于集合的主要内容,如果未能解决你的问题,请参考以下文章
数学分析集合 ① ( 集合概念 | 集合表示 | 常用的数集合 | 集合的表示 )
数学分析集合 ① ( 集合概念 | 集合表示 | 常用的数集合 | 集合的表示 )
Groovymap 集合 ( map 集合遍历 | 使用 map 集合的 each 方法遍历 map 集合 | 代码示例 )
Groovy集合声明与访问 ( 使用 [] 创建 ArrayList 和 LinkedList 集合 | 集合赋初值 | 使用下标访问集合 | 使用 IntRange 作为下标访问集合 )