7分钟分析人类全基因组,他们刷新全球纪录,此前最快也要24小时
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7分钟分析人类全基因组,他们刷新全球纪录,此前最快也要24小时相关的知识,希望对你有一定的参考价值。
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
7分钟,这是来自中国的一支团队“合力出成绩”、一举打破的世界纪录:
全球首次将人类全基因组分析,推进分钟级时代。

这支团队,由三家来自中国的机构共同组建。
他们这次所做的具体任务,叫做30X人类全基因组测序(WGS)胚系变异分析。
(其中,“30X”是指全基因组测序的深度)
而在这个团队之前,同等条件下完成这项任务所需的时间,却长达近24小时之久。
所以咱就是说,现在的“battle”结果就是——24小时 vs 7分钟,性能整个提升了200多倍!

与此同时,在相同条件下的计算成本还降低了80%,存储成本也下降30%。
但更重要的一点是,这事可能和你我都息息相关。
因为基因预测的一个用途,就是检测罹患多种疾病的可能性,锁定个人病变基因,以此来提前预防和治疗。
(P.s.世界著名演员安吉丽娜朱莉就这么做过。)
听起来确实是个好事,但如果放到过去,由于既耗时又费钱,能做得起基因预测的人屈指可数。
但今时不如往日,随着算力、AI、大数据技术的不断发展和融合,让基因测序这样数据密集型应用变得越发亲民。
而这一次的“7分钟”,可以说是把基因测序这件事往“平民时代”更推近了一步。
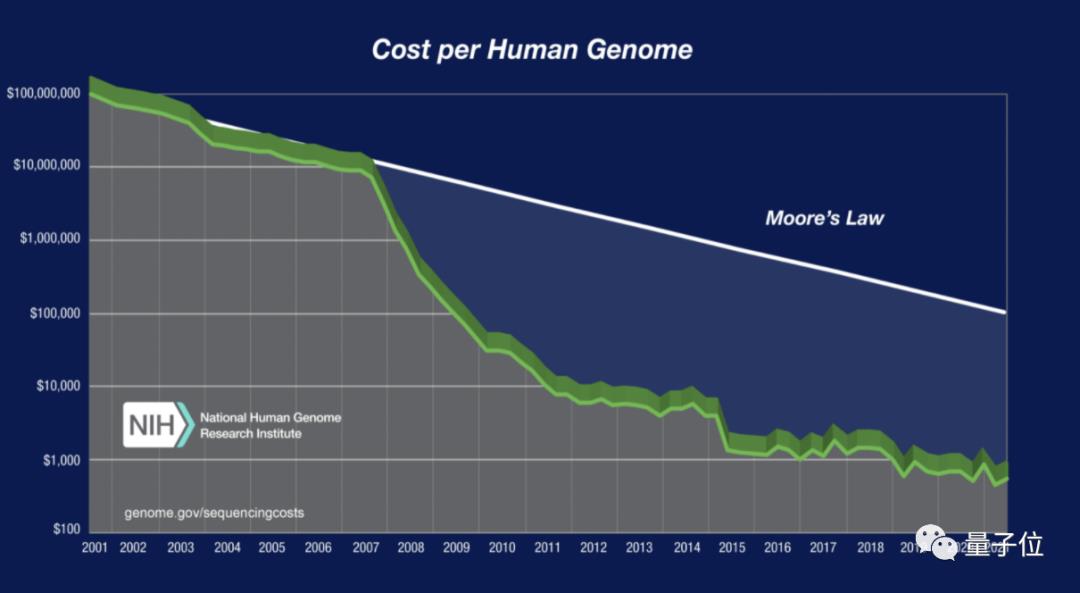
△ 图源:美国国家卫生研究院(NIH)
那么接下来的问题便是,为什么这支队伍的方法,就能做到“快好省”呢?
从24小时到7分钟,他们是怎么办到的?
人类全基因组测序要做的事,就是对未知基因组序列的物种进行个体的基因组测序。
但非常明显的一个难题,就是其数量过于庞大。
毕竟对象可是组成人体2.5万基因的约30亿碱基对,换算成容量大小则约为3GB。

但这还不算完,为了保障基因数据的完整性,在此基础上还需要做30次的平行测试。
如此一来,在最终测序完成之后,全基因组的数据量便将达到约100G。
而且随着技术的不断迭代演进,数据的存储已经从最初的人类基因组开始细分扩展,逐步涉及到肿瘤、遗传病的检测等等。
也正是因为数据量和数据种类的日益庞大,使得这方面的工作数据存储,动辄便以PB为单位来保存。
这就直接影响到了诸如基因采样、样本制作、数据下机、生信分析以及后基因测序等环节。
但更为重要的是,诸如基因这样的数据,隐私安全是非常值得注重的一环,而也正因为数据量的爆发式增长,使得数据安全管理、存储和分析变得异常困难。
团队在面对这些挑战所选择的突破口,并不是大多数人以为的强行堆算力,而是用底层数据存储的飞跃来做到提速。
简单来说,就是通过把以往不能合并处理的海量数据,打破它们之间的壁障,让整体的处理效率“更上一层楼”。
具体而言,他们所提出的解决方案便是大规模多组学数据并行加速分析平台。
据介绍,华西医院在这项工作中主要负责顶层设计,包括多模态组学数据分析和基因应用等。
华为在存储方面,提供高性能数据存储和基因数据管理系统的技术支持。
……
而纵观整个流程,数据存储的环节最为重要,可以说是贯穿始末:
基因测序阶段:存储系统需要足够的稳定性,来保障过程不被中断;
基因数据分析阶段:要有足够处理小文件等任务的能力;
数据归档阶段:能够将基因数据长期、安全、完整地保存起来。
由此可见,存储系统就像是一根“定海神针”,牢牢地把握着海量数据任务的“命脉”。
那么接下来的一个问题便是——团队此次能够打破世界纪录,它的专属“定海神针”又是什么?
世界顶级选手在背后发力
不卖关子,团队在这项任务中的存储系统,便是来自华为面向高性能数据分析(HPDA)的分布式存储OceanStor Pacific系列。

它是一种可大规模横向扩展的智能分布式存储,可以hold住高性能计算、AI应用、数据库、大数据分析和海量数据备份归档等业务需求。
而OceanStor Pacific之所以能协助团队在此次任务中打破世界纪录,是因为它自身就是头顶“世界顶级选手”光环的那种存储系统。
在国内范围来看,更是独秀一枝,不论是整体、文件存储、对象存储还是块存储方面,都是稳居市场第一。
而且不仅是市场方面的表现,从性能榜单上来看亦是如此。
这不,就在前不久IO500 (高性能计算领域针对存储性能最权威世界排行榜之一)发布的最新榜单中,华为存储HPDA Lab(由华为OceanStor Pacific存储支撑)位列第二。
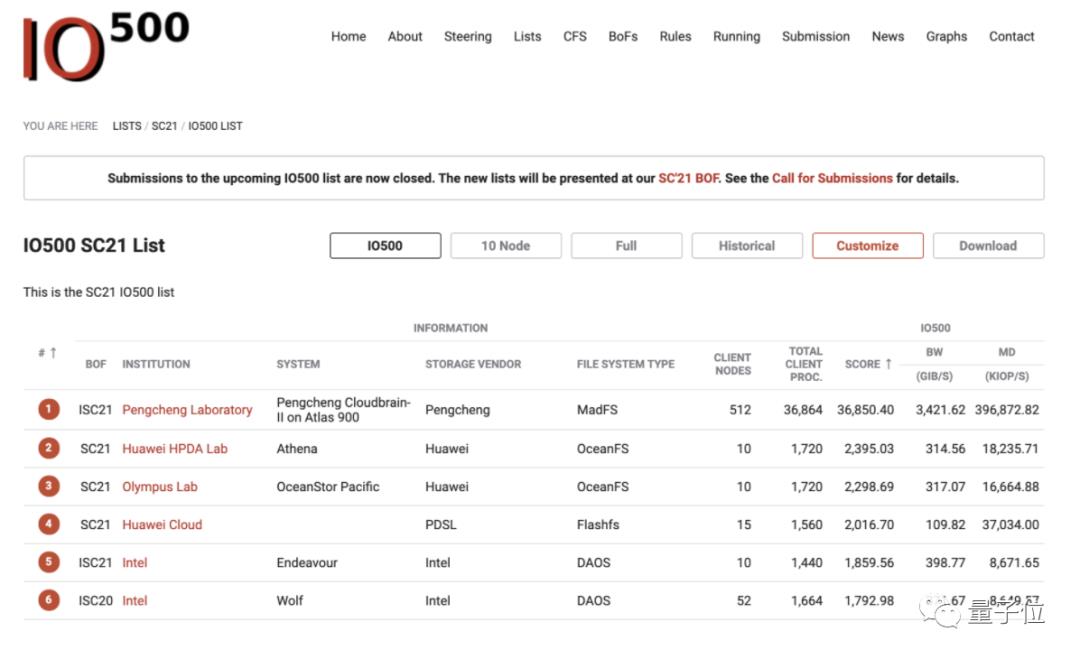
那么问题来了,OceanStor Pacific系列存储凭什么?
从官方对它的介绍中,我们挖到了一条线索,那便是“新一代”:

这个“新”,可以总结为三个方面。
首先是超高密设计。
以OceanStor Pacific 9950为例,它具备单框8节点,5U、80盘位的特性。

而之所以能如此“能装”,是因为它将各种SSD(固态硬盘)都设计的非常小巧:

另外一款5U、120盘位的OceanStor Pacific 9550,更是能够达到单框最大可提供2.4PB的裸容量。
如此超高密度的设计,便可以支撑海量数据的存储。
基于这样的硬件设计之下,便是华为存储的第二个特性——“多到一,一到多”,具体来讲就是:
多套存储变一套,一套存储支持多样化算力。
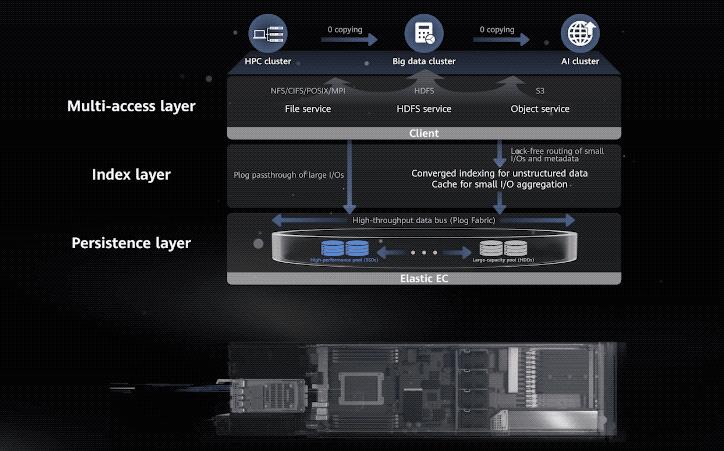
导致这样做的原因,根本上是高性能存储面临的负载类型越发复杂多样。
传统的做法就是来一个负载类型,就部署一个对应类型的存储;但这样做的结果,就是容易产生“孤岛现象”,而且不利于提高整体的效率。
而理想的状态就是存储系统可以满足一个“既要又要”——高带宽、高IOPS。
(带宽型方面的衡量标准是单位时间内的数据总吞吐量;而IOPS则是单位时间内能处理的总的IO请求量、以及每个IO的处理时延。)
对此,华为存储所采用的策略就有点“随机应变”的味道了。
例如存储系统在面对大文件时,就对应“大I/O”,采用直通方式将数据写到磁盘。

这样做的结果,就让大文件的宽带处于业界2倍的水平。
而当与之相对的小文件到来时,就对应“小I/O”,主要是将数据聚合后写到磁盘:

如此一来,就可以在理想的时延下提升磁盘空间的利用率,而且小文件的随机性能也达到了业界的5倍。
OceanStor Pacific系列存储的第三个独特性,便是打通协议的“任督二脉”。
华为存储提出这个特性的大背景,是因为现在在处理诸如基因测序这样的任务时,数据往往会呈现多种格式,例如文件、对象、大数据等等。
也正因如此,以往在整个数据处理过程中,单是数据转化、拷贝、加载这样的工作就占到了35%的时间。
于是,为了这方面的提高效率,就需要新的“协议互通”技术。
而这种新技术并不是指“共池”,在本质上是有着很大的区别。
“共池”主要共享硬件资源池,是在一套硬件上划分出多个独立的逻辑资源池,并根据不同的数据类型做部署。
但问题在于每个逻辑资源池只支持一种协议访问,也就是说跨协议的时候,还是需要经过“数据拷贝”的过程:

华为存储提出的“协议互通”技术则不然,实现的是多个协议共用一个硬件资源池。
而且还是同时支持文件、对象、大数据等多种协议访问的那种:
换言之,现在当一份数据“走进”存储系统后,不再需要做任何的转换了,可以直接被其它协议直接访问。
这便是打通协议“任督二脉”的奥义所在了。
而也正是因为刚才讲到的这些独有“功夫”,华为存储,这个世界级选手所涉足的领域早已不仅限于基因测序。
还有众多诸如此类的海量数据场景,例如能源勘探、气象海洋、智能制造、超算中心等等。
……
不难看出,华为在数据存储这一块,可谓是内修功法、外用其力。
那么最后一个问题便是:
数据存储,为什么这么重要?
因为一个非常明显的趋势是:
在智能时代之下,数据存储已经成为数据密集型应用的瓶颈。
或许你会说,数据量大,哪怕是PB级别,把算力堆上去不就可以了吗?
确实,在过去一段时间里,在处理像基因测序、生物制药等数据密集型应用时,大家似乎都会关注其背后的高性能计算(HPC)的效果如何。
每年的HPC Top 500 高性能计算机排行榜,也成为公众备受关注的“保留节目”。
但随着数据爆发式的增长,以及AI技术的不断推陈出新,数据密集型应用的发展不再仅仅聚焦在算力方向。
正如IDC所统计的那般:
全球67%的高性能计算中心已经在使用AI、大数据相关技术。
换言之,HPC、AI和大数据,它们三个融合的速度正在加快。
也正因如此,数据密集型应用正在步入一个新的时代—— 高性能数据分析 (HPDA)。
在这个时代之下,类似自动驾驶、基因测序等任务,对于数据分析的实时性要求越来越高。
而要实现这一点,也正如刚才我们所阐述的,离不开“数据存储系统”这一夯实的底座。
唯有这根“定海神针”足够稳固、扎实,且需得具备技术上的创新,才能保证其上层的工作以及上层与之的交互畅通无阻。
但比起应用方面的丝滑,通过推进新一代存储系统(即HPDA)来进一步发展数据密集型应用,这件事还具有更深远的意义。
例如油气地震勘探也在进入海量数据时代,需要采用大量的高性能计算和大数据分析技术。
但痛点也正如刚才我们提到的,其间的任务绝不是单一的,所产生的数据类型、结构也是纷繁复杂。
而通过新一代存储系统的优势,就可以做到规模化统一部署,以此来提高整体流程的效率。

再如超算中心、智能医疗、自动驾驶,甚至是宇宙探测等,均是需要HPDA的能力来完成对海量数据的高效分析。
这些亟需注入“新力量”的领域,恰恰正是科技、经济强国所发力的地方。
从另一种角度来看,新一代数据存储正在成为国家的关键基础设施,堪称“国之重器”。
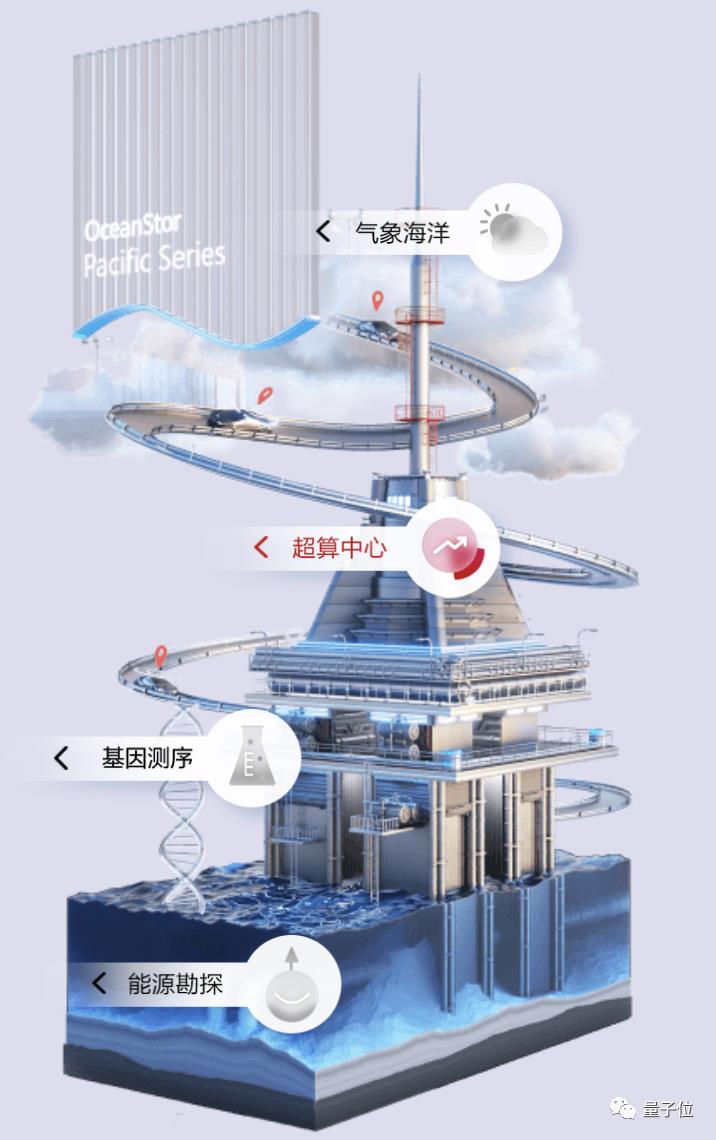
而华为OceanStor Pacific系列存储,无论是从市场份额、技术实力排名等等,均已成为国产新一代数据存储系统中的不二之选。
但比起亮眼的成绩,在最重要的实际行动方面,华为OceanStor Pacific系列存储也已经是处于“进行时”了。
至于接下来在HPDA时代中,新一代数据存储的技术进步还将结出怎样的硕果,是值得拭目以待了。
参考链接:
[1]https://en.wikipedia.org/wiki/Human_Genome_Project
[2]https://www.genome.gov/about-genomics/fact-sheets/Sequencing-Human-Genome-cost
[3]https://io500.org/
以上是关于7分钟分析人类全基因组,他们刷新全球纪录,此前最快也要24小时的主要内容,如果未能解决你的问题,请参考以下文章
二本毕业后3年发两篇Nature引热议,他此前研究刷新世界纪录