突破!阿里达摩院刷新VQA纪录,AI再次超越人类
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了突破!阿里达摩院刷新VQA纪录,AI再次超越人类相关的知识,希望对你有一定的参考价值。

近年来,在深度学习和大数据的支撑下,自然语言处理技术迅猛发展。而预训练语言模型把自然语言处理带入了一个新的阶段,得到了工业界的广泛关注。随着技术的发展,阿里巴巴达摩院在通用语言的基础上,已拓展到多语言、生成式、多模态、结构化、知识驱动等领域,不仅节省了大量的时间成本,还提高了效率。
8月12日,国际权威机器视觉问答榜单 VQA Leaderboard 出现了关键突破:阿里巴巴达摩院以81.26%的准确率创造了新纪录,让 AI 在“诗图会意”上首次超越人类基准。这是继2015年、2018年 AI 分别在视觉识别及文本理解领域超越人类后,人工智能在多模态技术领域也迎来一大进展。
 (达摩院AliceMind在VQA Leaderboard上创造首次超越人类的纪录)
(达摩院AliceMind在VQA Leaderboard上创造首次超越人类的纪录)

VQA是什么?
近10年来,AI技术保持高速发展,AI在下棋、视觉、文本理解等单模态技能上突飞猛进,比如在视觉理解领域,以CNN为代表的卷积累模型2015年在ImageNet视觉分类任务上超越了人类成绩;在文本理解领域,2018年微软与阿里几乎同时在斯坦福SQuAD挑战赛上让AI阅读理解超越了人类基准。
然而,在视觉问答VQA(Visual Question Answering)这一涉及视觉-文本跨模态理解的高阶认知任务上,AI过去始终未能达到人类水平的突破。
随着深度学习、视觉理解、文本理解等领域高速发展,自然语言处理技术与计算机视觉交融逐渐成为多模态领域重要的前沿研究方向。其中,VQA是多模态领域挑战极高的核心任务,解决VQA挑战,对研发通用人工智能具有重要意义。
为鼓励攻克这一难题,全球计算机视觉顶会CVPR从2015年起连续6年举办VQA挑战赛,吸引了包括微软、Facebook、斯坦福大学、阿里巴巴、百度等众多顶尖机构踊跃参与,形成了国际上规模最大、认可度最高的VQA数据集,其中包含超20万张真实照片、110万道考题。
VQA是 AI 领域难度最高的挑战之一。在测试中,AI需根据给定图片及自然语言问题生成正确的自然语言回答。这意味着单个AI模型需融合复杂的计算机视觉及自然语言技术:首先对所有图像信息进行扫描,再结合对文本问题的理解,利用多模态技术学习图文的关联性、精准定位相关图像信息,最后根据常识及推理回答系列问题。
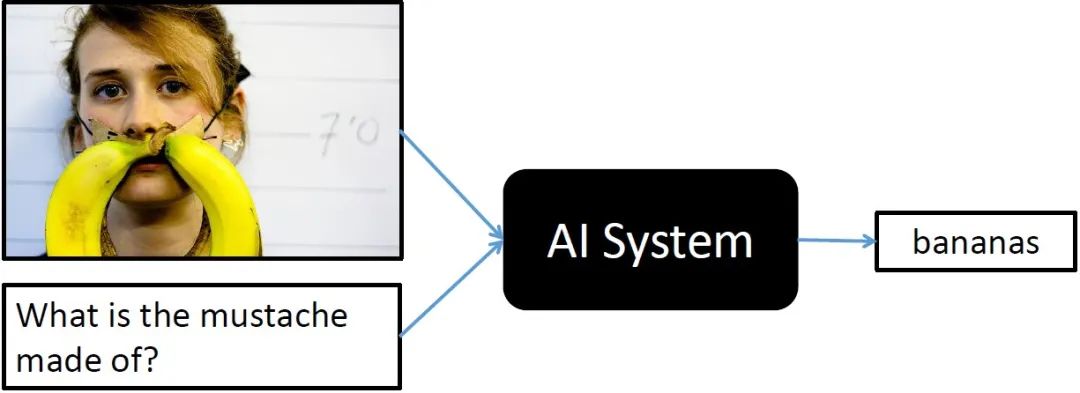
今年6月,阿里达摩院在VQA 2021 Challenge的55支提交队伍中夺冠,成绩领先第二名约1个百分点、去年冠军3.4个百分点。两个月后,达摩院再次以81.26%的准确率创造VQA Leaderboard全球纪录,首次超越人类基准线80.83%。
这一结果意味着,AI在封闭数据集内的VQA表现已媲美人类。
面对更开放的现实世界,AI一定会遇到新的挑战,需要喂更多的数据、进一步提升模型。但和CV等领域的发展一样,这一结果依然具有标志性意义,相信VQA技术在现实中的表现提升只是时间问题。
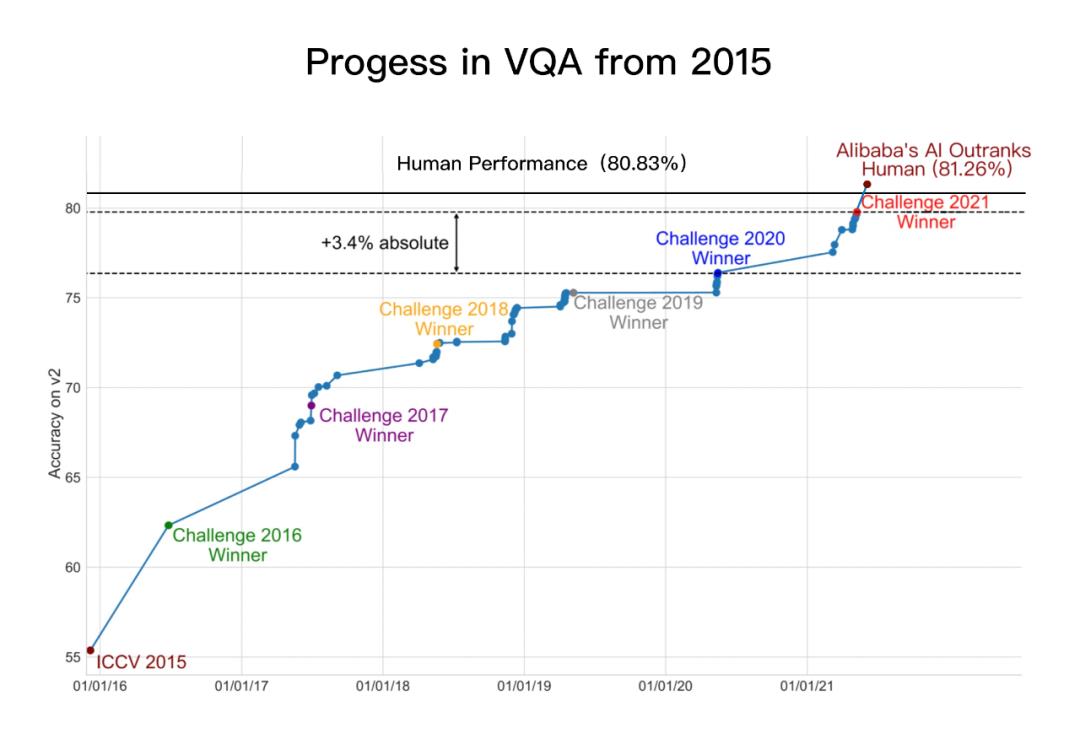
(VQA技术自2015年的进展)

VQA“学霸”如何炼成?
VQA挑战的核心难点在于,需在单模态精准理解的基础上,整合多模态的信息进行联合推理认知,最终实现跨模态理解,即在统一模型里做不同模态的语义映射和对齐。
据了解,为了解决VQA挑战,基于阿里云PAI 平台及EFLOPS框架的工程底座,达摩院语言技术实验室及视觉实验室对AI视觉-文本推理体系进行了系统性的设计,融合了大量算法创新,包括:
(1)多样性的视觉特征表示,从各方面刻画图片的局部和全局语义信息,同时使用Region,Grid,Patch等视觉特征表示,以更精准地进行单模态理解;
(2)基于海量图文数据和多粒度视觉特征的多模态预训练,用于更好地进行多模态信息融合和语义映射,创新性地提出了SemVLP,Grid-VLP,E2E-VLP和Fusion-VLP等预训练模型;
(3)研发自适应的跨模态语义融合和对齐技术,创新性地在多模态预训练模型中加入Learning to Attend机制来进行跨模态信息地高效深度融合;
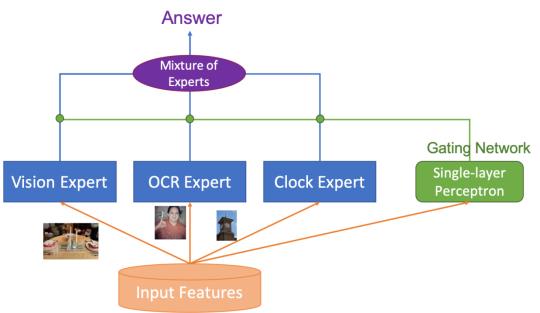
(4)采用Mixture ofExperts (MOE)技术进行知识驱动的多技能AI集成。
其中自研的多模态预训练模型E2E-VLP,StructuralLM已被国际顶级会议ACL2021接受。
模型大图如下:

这不是达摩院第一次在AI关键领域超越人类。
早在2018年,作为业界最早投入预训练语言模型研究的机构之一,达摩院前身IDST曾在斯坦福SQuAD挑战赛中历史性地让机器阅读理解首次超越人类,轰动全球。

今年以来,达摩院在AI底层技术领域动作频频。
从3月起,达摩院先后发布了中国科技公司中首个超大规模多模态预训练模型M6及首个超大规模中文语言模型PLUG,并开源了历经3年打造的深度语言模型体系 AliceMind(https://github.com/alibaba/AliceMind),其曾登顶 GLUE等六大国际权威NLP榜单。

VQA考高分有什么用?
达摩院语言技术实验室负责人司罗认为,“人工智能分为计算智能、感知智能、认知智能、创造智能四个层次。”
本次,AI在视觉—文本跨模态理解及推理上媲美人类的水平,意味着AI向认知智能迈进了关键一步。
据了解,VQA技术拥有广阔的应用场景,可用于图文阅读、跨模态搜索、盲人视觉问答、医疗问诊、智能驾驶、虚拟主播等领域,或将变革人机交互方式。目前,VQA技术已在阿里内部广泛应用于商品图文理解、智能客服等场景。
在阿里平台上,达摩院VQA能力已实现大范围工业应用落地,典型VQA应用包括:
(1)商品图文信息理解:数万家淘宝天猫商家开通使用店小蜜客服VQA视觉问答功能,AI帮助提升了提问解决率,优化了买家体验,降低了商家配置工作量。盒马、考拉的客服场景,闲鱼的图文同款匹配场景也接入了VQA能力。
淘宝店小蜜VQA能力详解:
a)商家精心制作的商品详情海报内,蕴含着大量有价值的商品信息。
b)消费者对商品进行提问时,AI客服可通过理解、检索商品海报进行回答,如裁切一张小图作为答案,一方面为消费者带来了更好的交互体验,另一方面为卖家节省了大量配置成本。

VQA不仅可以回答事实类问题,还可以回答非事实类、主观类问题。


(2)直播视频交互:VQA技术被应用于智能直播间等多模态人机交互场景中,帮助解决直播中多模态剧本构建、多模态语义问答等问题。
(3)多模态搜索:基于创新性的多模态预训练方法,达摩院为AliExpress训练了电商多模态通用模型,应用于搜索query相关性排序等需要图文理解的场景,有效提升了搜索相关性。
据悉,VQA技术在电商领域成熟运用后,阿里计划将其推广至医疗问诊等更广泛的社会应用领域。

VQA考卷有多难?
对单一AI模型来说,VQA考卷难度堪称“变态”。
要拿到漂亮的分数,AI不仅要修炼好图像识别、文本识别、文本理解等基本功,还要解锁计数、读钟表、推理认知等附加技能,此外还必须拥有百科全书的丰富常识。
比如,在下面这道VQA考题中,根据有礼服装饰的小熊玩具照片+图片“这些玩具用来做什么的?”AI需要成功推理出一个可能的答案“婚礼”。

6年前,这些问题对AI来说难度极高。经过多年的技术积累,达摩院AliceMind在VQA测试中拿到了超81分的成绩,基本达到普通人看图问答的水准。
相信AI未来将给人类带来更多惊喜。
论文链接:
1. E2E-VLP: End-to-EndVision-Language Pre-training Enhanced by Visual Learning, ACL2021
2. A Structural Pre-trained Modelfor Table and Form Understanding, ACL 2021
3. SemVLP: Vision-LanguagePre-training by Aligning Semantics at Multiple Levels


往
期
回
顾
技术
新闻
技术
大赛

分享

点收藏

点点赞

点在看
以上是关于突破!阿里达摩院刷新VQA纪录,AI再次超越人类的主要内容,如果未能解决你的问题,请参考以下文章
首次超越人类!“读图会意”这件事,AI比你眼睛更毒辣 | 达摩院
阿里AI破纪录超人类;世界杯的火眼睛睛,伤了多少人的心;天才黑客决定给马斯克打工12周...