大数据开发技术期末复习(不挂科)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发技术期末复习(不挂科)相关的知识,希望对你有一定的参考价值。
考前秘籍文档
1 配置Hadoop时,JAVA_HOME包含在哪一个配置文件中。
hadoop-env.sh
2 HDFS是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是哪些?
一次写入,多次读
3 下列哪个程序通常与NameNode 在同一个节点启动?
Jobtracker
4 更改NameNode访问地址的配置文件是哪个?
core-site.xml
5 格式化HDFS的命令是哪个?
hdfs namenode–format
hadoop namenode –format
6 一个block是多少字节?对于指定大小的文件,按照这个大小,能够创建多少块。
128MB
7 NameNode的端口号是多少?
50070
8 下列哪个程序通常与NameNode在一个节点启动?
Jobtracker
9 哪个部件通常是集群的最主要瓶颈。
磁盘IO
10 HBase采用哪种结构作为底层数据存储?
HDFS
11 在Hadoop项目结构中,MapReduce指的是什么?
分布式编程模型和计算框架,解决分布式门槛高的问题,基于其框架对分布式计算的抽象map和reduce,可以实现分布式计算程序
分布式并行编程模型
12 Hadoop的核心是由什么哪些组件组成?
核心(基础)组件: ["HDFS","MapReduce","yarn"]
- hdfs :分布式海量数据存储功能
- Yarn:提供任务调度和资源管理功能(资源管理:协调平衡集群中的计算节点,合理分配 ;任务调度:一个作业对应多个任务,负责任务调度,状态监控,容错管理等)
- MapReduce:(分布式编程模型和计算框架,解决分布式门槛高的问题,基于其框架对分布式计算的抽象map和reduce,可以实现分布式计算程序。)
常用组件: hive、hbase、streaming、zookeeper
- hive提供数据摘要和数据仓库,解决数据仓库构建问题,基于Hadoop平台的存储和计算,与传统SQL相结合,让熟悉SQL的编程人员轻松向Hadoop平台迁移。
- streaming解决非java开发人员使用Hadoop平台的语言问题,使各种语言如C++,python,shell等均可以无障碍使用Hadoop平台。
- hbase基于列式存储模型的分布式数据库,解决某些场景下,需要Hadoop平台数据及时响应的问题。
- zookeeper分布式协同服务,主要解决分布式下数据管理问题,统一平台,状态同步,集群管理,配置同步。)
13 数据分片是由哪个函数完成的?
getSplit
14 HBase 的客户端并不依赖Master,而是通过ZooKeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小。
Zookeeper
15 HBase中客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的region的位置信息,用来加快后续数据访问过程。
region
16 一个基本的Hadoop集群中的节点主要包括哪些进程?
Datanode;
Namenode;
SecondaryNameNode
1.NameNode
2.SecondaryNameNodet
3.DataNode
4.ResourceManager
5.NodeManager
6.DFSZKFailoverController
7.JournalNode )
17 运行HDFS程序之前,需要先初始化NameNode对象,该对象的主要作用是读取HDFS的元数据信息,也就是安装Hadoop时候的hdfs-site.xml文件。
运行HDFS程序之前,需要先初始化configuration对象,
该对象的主要作用是读取HDFS的系统配置信息,也就是安装Hadoop时候的配置文件。
18 一个MapReduce任务主要包括哪两部分?
主要包括两部分:Map任务和Reduce任务.
(1) Map任务服务对数据的获取、分割与处理,其核心执行方法为map()方法。
(2) Reduce任务负责对Map任务的结果进行汇总,其核心执行方法为reduce()方法
19 MapReduce编程模型,键值对<key,value>的key必须实现什么接口?
可写接口(WritableComparable)
20 HBASE是一个疏松的、分布式的、已排序的多维度持久化的分布式数据库
面向列的分布式数据库
21 Hadoop处理平台能够完成在线处理吗?
不能
22 伪分布式Hadoop是指在一台主机上通过虚拟机配置的集群模式?
对
23 Hadoop 支持数据的随机读写吗?
不支持
24 MapReduce计算过程中,相同的key默认会被发送到同一个reduce task处理吗?
对
25 HBase对于空(NULL)的列,需要占用存储空间吗?
不占用
26 如何实现服务器之间的免密登录?
(1)免密登录原理
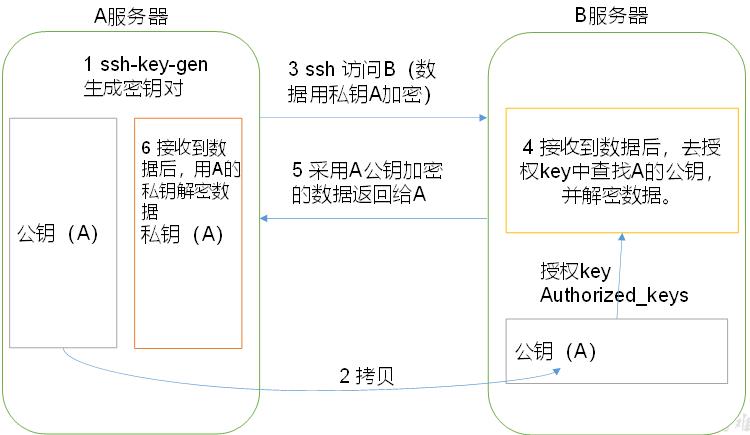
(2)生成公钥和私钥:
[zs@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[zs@hadoop102 .ssh]$ ssh-copy-id hadoop102
[zs@hadoop102 .ssh]$ ssh-copy-id hadoop103
[zs@hadoop102 .ssh]$ ssh-copy-id hadoop104
注意:
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
还需要在hadoop103上采用zs账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
ssh-keygen -t rsa
ssh-copy-id 目标服务器ip
总结:
- 在当前服务器上生成公钥和私钥:
ssh-keygen -t rsa - 将公钥拷贝到要免密登录的目标机器上:
ssh-copy-id 目标服务器ip - 还需要在当前服务器上采用root账号,配置一下无密登录到目标服务器;
- 在目标服务器上同样配置一下无密登录到当前服务器;
- 即可实现服务器之间互相免密登录。
27 HDFS读数据流程?
- 跟namenode通信查询元数据,找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,先在本地缓存,然后写入目标文件
28 Mapreduce中,Partitioner操作的作用?
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
29 Hadoop怎么样实现二级排序?
使用Mapreduce实现(三个阶段:map起始阶段,map最后阶段,reduce阶段)
30 Hadoop集群中Hadoop需要启动哪些进程,它们的作用分别是什么?
- NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
- SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
- DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
- ResourceManager(JobTracker)JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
- NodeManager(TaskTracker)执行任务
- DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
- JournalNode 高可用情况下存放namenode的editlog文件.
31 互联模式属于Hadoop 可以运行的模式吗?
不属于
32 与HDFS类似的框架是哪些?
GFS
33 MapReduce程序只能用Java语言编写吗?
不是
34 HDFS 中的 block 默认保存几份?
3份
35 Hadoop平台中执行一个job,如果这个job的输出路径已经存在,那么程序会怎样?
抛出一个异常,然后退出
36 哪个HDFS命令可用于检测数据块的完整性?
在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态、获取文件的block信息和位置信息等
hdfs fsck /
37 Hadoop可以处理哪种类型的数据?
结构化 半结构化 非结构化
概括点来说,就是传统的结构化数据,文字图片等,以及非结构化的数据,视频、音频等,都能基于Hadoop框架技术得到合理的处理。
38 哪个组件可以指定对key进行Reduce分发的策略?
Partitioner
39 哪个进程负责 MapReduce 任务调度?
Jobtracker
40 在Hadoop中定义的主要公用InputFormat中,默认是哪一个?
TextInputFormat
41 在HDFS中,NameNode的主要功能是什么?
存储元数据(选择题)
- 我们把目录结构及文件分块位置信息叫做元数据。Namenode 负责维护整个hdfs文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block的id,及所在的datanode 服务器)。
- Namenode节点负责确定指定的文件块到具体的Datanode结点的映射关系。在客户端与数据节点之间共享数据。
- 管理Datanode结点的状态报告,包括Datanode结点的健康状态报告和其所在结点上数据块状态报告,以便能够及时处理失效的数据结点。
42 在Hadoop中定义的主要公用InputFormat中,默认是哪一个?
TextInputFormat
A、 TextInputFormat
B、 KeyValueInputFormat
C、 SequenceFileInputFormat
选择(A)
43 Hadoop运行的模式有哪些?
- a)单机版
- b)伪分布式
- c)分布式
44 Hadoop集群搭建中常用的4个配置文件为哪些?
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
(填空题)
45 HBase架构采用主从(master/slave)方式,由ZooKeeper集群和哪两种类型的节点组成?这种模式类似于HDFS的NameNode与 DataNode。
HMaster节点、HRegionServer节点
46 在HBase中,Root表是存储根数据的表,存储了.META.表在什么上的信息?
-ROOT-表和.META.表是hbase的元数据表,
在-ROOT-表中保存有.META.表的相关信息,
在.META.表中保存有业务表的region相关信息
47 Mapreduce操作数据的最小单位是什么?
一个键值对
48 HDFS以流的形式访问文件系统中的数据吗?
是Hadoop分布式计算中的数据存储系统,是基于流数据模式访问和处理超大文件的需求而开发的
对
49 HDFS既适合超大数据集存储,也适合小数据集的存储吗?
错,只适合大数据存储
50 HDFS系统采用NameNode定期向DataNode发送心跳消息,用于检测系统是否正常运行吗?
不是 是datanode定期向namenode发送心跳消息
51 TaskTracker进程负责 MapReduce 任务调度吗?
错(Jobtracker)
Jobtracker是主线程,它负责接收客户作业提交,调度任务到工作节点上运行tasktracker—由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态.
52 Namenode启动时会自动进入安全模式,在此阶段,文件系统允许有修改吗?
错
NameNode 在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改
53 HDFS中的写数据流程。
- 和namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求第一个 block该传输到哪些datanode服务器上
- namenode返回3个datanode服务器ABC
- client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
54 使用start-all.sh命令启动Hadoop时,请给出启动进程名称和各进程启动顺序。
启动顺序:namenode –> datanode -> secondarynamenode -> resourcemanager -> nodemanager
55 HDFS里的edit log和fs image作用?
- fsimage文件其实是Hadoop文件系统元数据的一个永久性的检查点,其中包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;
- edits文件存放的是Hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
在HDFS中,每一个文件块都会有一条元数据用来唯一标识这个文件块的存在。
而Fimage和edit.log这两个文件就是用来保存,处理这些元数据信息的文件。
56 NameNode与SecondaryNameNode 的区别与联系?
1)区别
- NameNode 负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
- SecondaryNameNode 主要用于定期合并命名空间镜像和命名空间镜像的编辑日志。
2)联系
- SecondaryNameNode 中保存了一份和 namenode 一致的镜像文件(fsimage)和编辑日志(edits)。
- 在主 namenode 发生故障时(假设没有及时备份数据),可以从 SecondaryNameNode
57 在CentOS环境下,按照伪分布方式安装和配置Hadoop平台的主要过程。
1、hadoop安装包下载
2、hadoop安装包解压
3、hadoop伪分布式环境搭建
环境搭建步骤如下:
1、将hadoop安装目录添加到系统环境变量(~/.bash_profile)
2、配置hadoop环境的配置文件hadoop-env.sh
3、配置hadoop核心文件core-site.xml
4、配置HDFS文件hafs-site.xml
5、配置MapReduce文件mapred-site.xml
6、配置YARN文件yaen-site.xml
7、从节点配置文件slaves
58 Hadoop的作者是哪一位?
Doug cutting
编程题
WordCountDriver
package com.zs.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
// 1. 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2. 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3. 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4. 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5. 设置最终输出kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6.设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\\\software\\\\hadoop\\\\input\\\\inputword"));
FileOutputFormat.setOutputPath(job, new Path("D:\\\\software\\\\hadoop\\\\output\\\\output3"));
// 7. 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
WordCountMapper
package com.zs.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; // 2.x 3.x,mapred:1.x
import java.io.IOException;
/**
* KEYIN,map阶段输入的key的类型:LongWritable
* VALUEIN,map阶段输入value类型:Text
* KEYOUT,map阶段输出的Key类型:Text
* VALUEOUT,map阶段输出的value类型:IntWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
// 定义全局变量,节省资源
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
// super.map(key, value, context);
// 1. 获取一行
String line = value.toString();
// 2. 切割
String[] words = line.split(" ");
// 3. 循环写出
for (String word : words)
// 封装outK
outK.set(word);
// 写出
context.write(outK, outV);
WordCountReducer
package com.zs.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN,reduce:LongWritable
* VALUEIN,reduce阶段输入value类型:Text
* KEYOUT,reduce阶段输出的Key类型:Text
* VALUEOUT,reduce阶段输出的value类型:IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
int sum = 0;
// 累加
for (IntWritable value : values)
sum += value.get();
outV.set(sum);
// 写出
context.write(key, outV);
暂且为止!
总结
- 单从大数据学习角度来说:想要学好BD还是需要下更多功夫去钻研的。
- 单从考试角度来说:想考个及格还是不难的,毕竟考试比较水,大家都懂。
- 考试既然水,分数就无所谓高低,重要的是我们学了多少东西。
- 如果看到这里,首先恭喜你与我同在,提前祝你考一个好的成绩。
- 如果有用的话,小伙伴帮忙点赞/打赏,算是对俺无私分享的支持与鼓励。
- 再次感谢大家的支持与陪伴,感谢其他学霸/大佬对此文的贡献,我仅仅是一个文字搬运工,分享快乐。
加油!
感谢!
努力!
以上是关于大数据开发技术期末复习(不挂科)的主要内容,如果未能解决你的问题,请参考以下文章