Python数据分析与可视化期末复习笔记整理(不挂科)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析与可视化期末复习笔记整理(不挂科)相关的知识,希望对你有一定的参考价值。
【Python数据分析与可视化】期末复习笔记
1. 数据分析与可视化概述
对比
- 数据分析是一个探索性的过程,通常从特定的问题开始。它需要好奇心、寻找答案的欲望和很好的韧性,因为这些答案并不总是容易得到的。
- 数据可视化,即数据的可视化展示。有效的可视化可显著减少受众处理信息和获取有价值见解所需的时间。
- 数据分析和数据可视化这两个术语密不可分。在实际处理数据时,数据分析先于可视化输出,而可视化分析又是呈现有效分析结果的一种好方法。
概念
数据可视化:是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为“一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量”。
数据可视化主要是借助于图形化手段,清晰有效地传达与沟通信息。
常用工具
- Microsoft Excel
- R语言
- Python语言
- SAS软件
- SPSS
- 专用的可视化分析工具
Power BI、Tableau、Gehpi和Echarts
Python常用类库
- Numpy
- SciPy
- Pandas
- Matplotlib
- Seaborn
- Scikit-learn
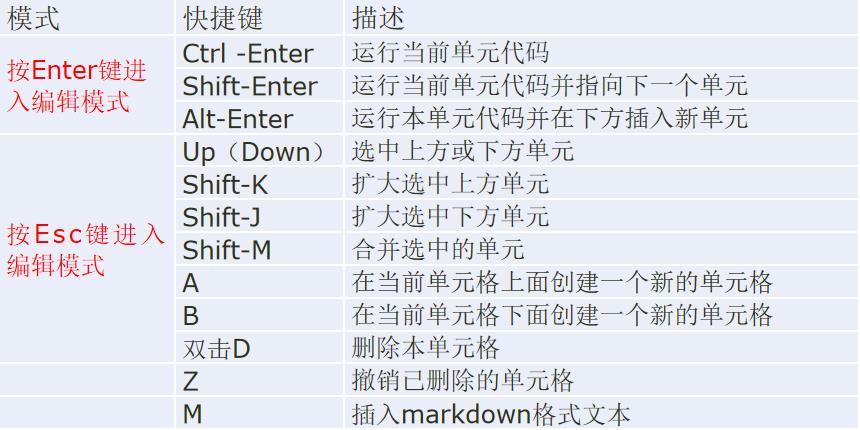
Jupyter notebook中的常用快捷方式
2. Python编程基础
Python是一个结合了解释性、编译性、互动性和面向对象的高级程序设计语言,结构简单,语法定义清晰。Python最具特色的就是使用缩进来表示代码块,不需要使用大括号。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
- Python3 中有六个标准的数据类型:Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)。其中,不可变数据类型有:Number、String、Tuple;可变数据类型有:List、Dictionary、Set。
- Python3支持的数字类型有int(整数)、float(浮点数)、bool(布尔型)、complex(复数)四种类型。
- Python 中的变量是不需要声明数据类型的,变量的“类型”是所指的内存中被赋值对象的类型。
- 同一变量可以反复赋值,而且可以是不同类型的变量,这也是Python语言称之为动态语言的原因。
- 反斜杠为转义符
- 字典中的键必须是唯一的,只能使用不可变的对象(比如字符串)来作为字典的键,字典中的键/值对是没有顺序的。
- 集合是一个由唯一元素组成的非排序集合体。也就是说,集合中的元素没有特定顺序,集合中没有重复项。可以使用大括号 或者set()函数创建集合,但是,创建一个空集合必须用 set(),因为 是用来创建一个空字典。
conda
Python第三方包的安装方式较多,本书建议采用以下方式进行安装和管理:
(1)在CMD命令窗口中,使用conda命令进行自动下载安装,用法如下:
conda install <包名称列表> #安装包
conda remove <包名称列表> #卸载包
conda search<搜索项> #搜索包
conda list #查看所有包
conda update<包名称> #升级包
(2)在CMD命令窗口中使用pip命令,用法如下:
pip install <包名> #安装包
pip install--upgrade <包名> #更新包
pip uninstall <包名> #删除包
也可以在Jupyter notebook的cell中运行pip命令执行相应的命令,只需在命令前加“!”,如执行 !pip install 包名 进行包的安装。
按esc键切换为命令模式,按enter键进入编辑模式
3. NumPy数值计算基础
NumPy简介
NumPy是在1995年诞生的Python库Numeric的基础上建立起来的,但真正促使NumPy的发行的是Python的SciPy库。但SciPy中并没有合适的类似于Numeric中的对于基础数据对象处理的功能。于是,SciPy的开发者将SciPy中的一部分和Numeric的设计思想结合,在2005年发行了NumPy。
NumPy是Python的一种开源的数值计算扩展库。它包含很多功能,如创建n维数组(矩阵)、对数组进行函数运算、数值积分等。 NumPy的诞生弥补了这些缺陷,它提供了两种基本的对象:
- ndarray:是储存单一数据类型的多维数组。
- ufunc:是一种能够对数组进行处理的函数。
NumPy常用函数
通常来说,ndarray是一个通用的同构数据容器,即其中的所有元素都需要相同的类型。利用array函数可创建ndarray数组。
- np.array(object, dtype,ndmin):利用array函数创建数组对象
- ndmin:接收int,制定生成数组应该具有的最小维数,默认为None
- np.arange(start, stop, step, dtype):创建等差一维数组
- step:步长,可省略,默认步长为1;
- dtype:设置元素的数据类型,默认使用输入数据的类型。
- linspace(start, end, count):创建等差数列
- stop: 结束值;生成的元素不包括结束值
- num:要生成的等间隔样例数量
- logspace(start, end, count):创建等比数列
- start, stop代表的是10的幂,默认基数base为10,第三个参数元素个数。
- diag:创建对角矩阵,即对角线元素为0或指定值,其他元素为0
- 格式:
np.diag(v, k=0):np.diag([1,2,3,4])
- 格式:
- eye:创建一个对角线位置为1,其他位置全为0的矩阵
- sort:
axis=1,沿横轴排序,axis=0,沿着纵轴排序. - argsort,lexsort:索引数组,索引值表示数据在新的序列中的位置.
- tile(A, reps):实现数据重复
- repeat(a, reps, axis=None)
ndarray 对象属性和数据转换
ndarray对象属性及其说明:
- ndim:返回数组的轴的个数(秩)
- shape:返回数组的维度
- size:返回数组元素个数
- dtype:返回数据类型
- itemsize:返回数组中每个元素的字节大小
生成随机数
在NumPy.random模块中,提供了多种随机数的生成函数。如randint函数生成指定范围的随机整数来构成指定形状的数组。
np.random.randint(low, high = None, size = None)
random模块的常用随机数生成函数:

数组变换
数组重塑
np.reshape(a, newshape, order='C')
- a:需要处理的数据
- newshape:新维度—整数或整数元组
- reshape的参数中的其中一个可以设置为-1,表示数组的维度可以通过数据本身来推断
数据散开(ravel)
数据扁平化(flatten)
数据重塑不会改变原来的数组.
数组合并
- hstack:左右并在一起
- vstack:上下并在一起
- concatenate:
axis=1:按行横向合并,axis=0:按列纵向合并. - hsplit:横向分割(纵着切),横相对于数组本身而言
- vsplit:纵向分割(横着切)
- split:
axis=1:按行横向分割,axis=0:按列纵向分割.
数组转置和轴对换
- 数组转置是数组重塑的一种特殊形式,可以通过transpose方法进行转置。
数组的切片返回的是原始数组的视图,不会产生新的数据,如果需要的并非视图而是要复制数据,则可以通过copy方法实现。
ufunc函数的广播机制
- ufunc函数:通用函数,是一种能够对数组中所有的元素进行操作的函数,比math库更快
- np.any函数表示逻辑“or”
- np.all函数表示逻辑“and”, 运算结果返回布尔值
广播(broadcasting)是指不同形状的数组之间执行算术运算的方式。
需要遵循4个原则:
- 让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在左边加1补齐。
- 如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为1的维度进行扩展,以匹配另一个数组的形状。
- 输出数组的shape是输入数组shape的各个轴上的最大值。
- 如果两个数组的形状在任何一个维度上都不匹配,并且没有任何一个维度等于1,则引发异常。
条件逻辑运算
- where的用法:
np.where(condition, x, y)- 满足条件(condition),输出x,不满足则输出y。
w = np.array([2,5,6,3,10])
np.where(w>4)
(array([1, 2, 4], dtype=int64),)
where中若只有条件 (condition),没有x和y,则输出满足条件元素的坐标。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
读写二进制文件
-
NumPy提供了多种文件操作函数存取数组内容。
-
文件存取的格式分为两类:二进制和文本。而二进制格式的文件又分为NumPy专用的格式化二进制类型和无格式类型。
-
NumPy中读写二进制文件的方法有:
- np.load(“文件名.npy")是从二进制文件中读取数据;
- np.save(“文件名[.npy]", arr) 是以二进制格式保存数据。
-
读写文本文件
- np.loadtxt("…/tmp/arr.txt",delimiter = “,”)把文件加载到一个二维数组中;
- np.savetxt("…/tmp/arr.txt", arr, fmt = “%d”, delimiter = “,”)是将数组写到某种分隔符隔开的文本文件中;
- np.genfromtxt("…/tmp/arr.txt", delimiter = “,”)是结构化数组和缺失数据。
-
读取CSV文件
- np.loadtxt(fname, dtype=, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding=‘bytes’)
排序
Sort函数对数据直接进行排序,调用改变原始数组,无返回值。
-
格式:
numpy.sort(a, axis, kind, order)- order:排序的字段名,可指定字段排序,默认为None
- axis:axis=1为沿横轴排序;axis=0为沿纵轴排序;axis=None,将数组平坦化之后进行排序
-
np.argsort函数和np.lexsort函数根据一个或多个键值对数据集进行排序。
- np.argsort(): 返回的是数组值从小到大的索引值;
- np.lexsort(): 返回值是按照最后一个传入数据排序的结果。
arr = np.array([7,9,5,2,9,4,3,1,4,3])
print('原数组:',arr)
print('排序后:',arr.argsort())
#返回值为数组排序后的下标排列
print('显示较大的5个数:',arr[arr.argsort()][-5:])
原数组: [7 9 5 2 9 4 3 1 4 3]
排序后: [7 3 6 9 5 8 2 0 1 4]
显示较大的5个数: [4 5 7 9 9]
a = [1,5,1,4,3,4,4]
b = [9,4,0,4,0,2,1]
# 先按照a排序,如果a有相同的数按照b排序
ind=np.lexsort((b,a)) #sort by a,then by b
print('ind:',ind)
tmp=[(a[i],b[i])for i in ind]
print('tmp:',tmp)
ind: [2 0 4 6 5 3 1]
tmp: [(1, 0), (1, 9), (3, 0), (4, 1), (4, 2), (4, 4), (5, 4)]
重复数据与去重
- 在NumPy中,对于一维数组或者列表,unique函数去除其中重复的元素,并按元素由大到小返回一个新的元组或者列表。
- 统计分析中有时也需要把一个数据重复若干次,使用tile和repeat函数即可实现此功能。
- tile函数的格式:np.tile(A, reps)
其中,参数A表示要重复的数组,reps表示重复次数。 - repeat函数的格式:np.repeat(A, reps, axis = None)
“a”: 是需要重复的数组元素,
“repeats”: 是重复次数,
“axis”: 指定沿着哪个轴进行重复,axis = 0表示按行进行元素重复;axis = 1表示按列进行元素重复。
- tile函数的格式:np.tile(A, reps)
常用统计函数
NumPy中提供了很多用于统计分析的函数,常见的有sum、mean、std、var、min和max等。
- 几乎所有的统计函数在针对二维数组的时候需要注意轴的概念。
- axis=0时表示沿着纵轴进行计算,axis=1时沿横轴进行计算。
Numpy中数组的方法sort、argsort和lexsort分别是指 ___、 将___和___
直接排序x中的元素从小到大排列,提取其对应的index(索引)对数组或列表按照某一行或列进行排序
4. Pandas统计分析
Pandas(Python Data Analysis Library)是基于NumPy的数据分析模块,它提供了大量标准数据模型和高效操作大型数据集所需的工具,可以说Pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一。
Pandas有三种数据结构:Series、DataFrame和Panel。
- Series类似于一维数组;
- DataFrame是类似表格的二维数组;
- Panel可以视为Excel的多表单Sheet
- DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
- DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
- Series索引的修改:
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan'] - 索引对象负责管理轴标签和其他元数据,不能进行修改,保证数据结构之间的安全共享。
- 重建索引是指对索引重新排序而不是重新命名,如果某个索引值不存在的话,会引入缺失值。
- reindex:默认对行进行重建索引.
- index:用于索引的新序列
- method:插值(填充)方式
- fill_value:缺失值替换值
- limit:最大填充量
- level copy:在Multiindex的指定级别上匹配简单索引,否则选取其子集,默认为True,无论如何都复制;如果为False,则新旧相等时就不复制
- rename:修改列名
- 如果不希望使用默认的行索引,则可以在创建的时候通过Index参数来设置。
- 在DataFrame数据中,如果希望将列数据作为索引,则可以通过
set_index方法来实现。
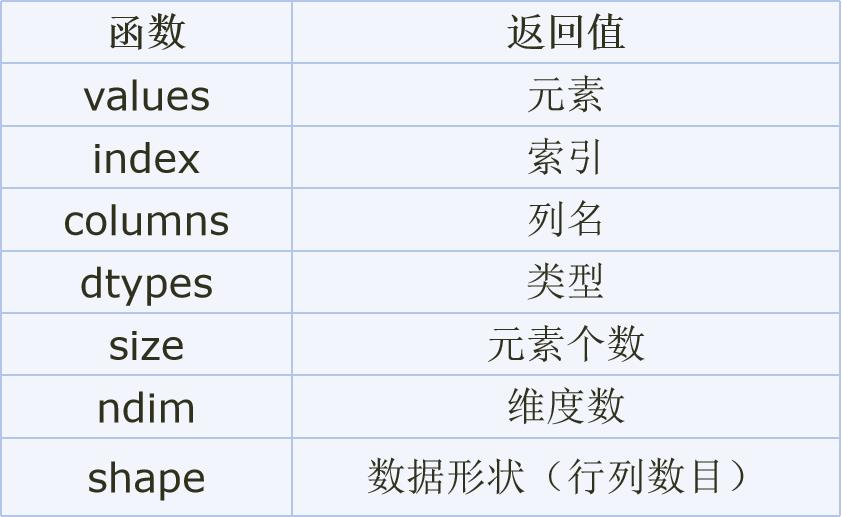
DataFrame的属性
data.rename(columns=('total_bill':'消费总额','tip':'小费','sex':'性别','smoker':'是否抽烟',
'day':'星期','time':'聚餐时间段','size':'人数'),inplace=True)
fdata['是否抽烟'] === fdata.是否抽烟
- 查询抽烟男性中人均消费大于15的数据:
data.query( '是否抽烟=="Yes" & 性别=="Male" & 人均消费>15')
- 删除性别或者聚餐时间为空的行:
data.dropna(subset=['性别','聚餐时间段'],inplace=True)
data.isnull().sum()
-
增加一行直接通过append方法传入字典结构数据即可。
df.append(data, ignore_index=True) -
增加列时,只需为要增加的列赋值即可创建一个新的列。若要指定新增列的位置,可以用insert函数。
-
unique():是以数组形式(numpy.ndarray)返回列的所有唯一值(特征的所有唯一值)
-
nunique():返回dataframe中列的唯一值的个数,也可用于series
-
DataFrame.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method='pad')
函数应用和映射
- map函数:将函数套用到Series的每个元素中;
- apply函数,将函数套用到DataFrame的行或列上,行与列通过axis参数设置;
df.apply(np.mean)默认按列axis=0进行,axis=1按照行. - applymap函数,将函数套用到DataFrame的每个元素上。
data.dpplymap(lambda x:'%.3f'%x)
排序
对于DataFrame数据排序,通过指定轴方向,使用sort_index函数对行或列索引进行排序。如果要进行列排序,则通过sort_values函数把列名传给by参数即可。
df.sum() # 按列进行求和
df.sum(axis=1) # 按行进行求和
汇总与统计
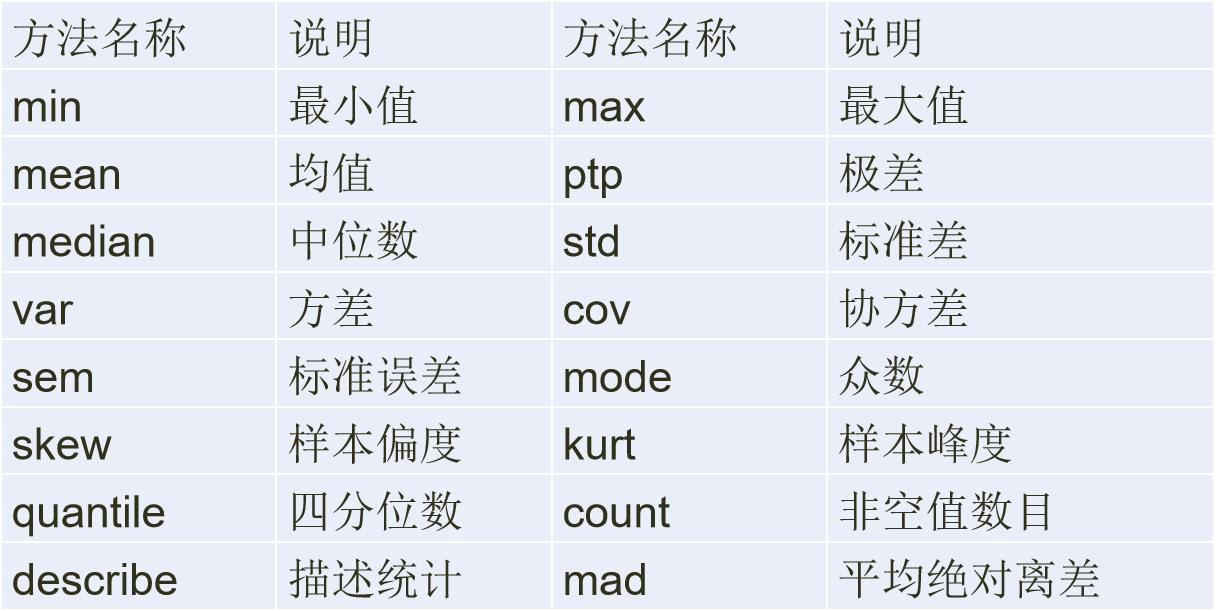
利用describe方法会对每个数值型的列数据进行统计
Pandas中常用的描述性统计量:
对于类别型特征的描述性统计,可以使用频数统计表。Pandas库中通过unique方法获取不重复的数组,利用value_counts方法实现频数统计。
数据分组
groupby方法的参数及其说明:

-
按Series对象(具体数据)分组
-
按列名分组
DataFrame数据的列索引名可以作为分组键,但需要注意的是用于分组的对象必须是DataFrame数据本身,否则搜索不到索引名称会报错。 -
按列表或元组分组
分组键还可以是长度和DataFrame行数相同的列表或元组,相当于将列表或元组看做DataFrame的一列,然后将其分组。 -
按字典分组
如果原始的DataFrame中的分组信息很难确定或不存在,可以通过字典结构,定义分组信息。 -
按函数分组
函数作为分组键的原理类似于字典,通过映射关系进行分组,但是函数更加灵活。
data.groupby(data.map(judge)),sum()
数据聚合
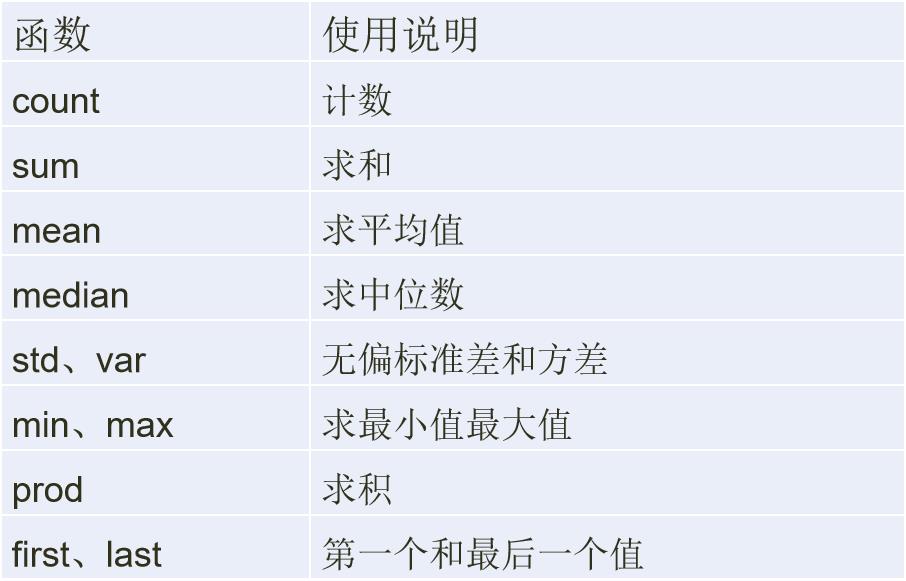
使用agg方法聚合数据
- agg、aggregate方法都支持对每个分组应用某个函数,包括Python内置函数或自定义函数。同时,这两个方法也能够直接对DataFrame进行函数应用操作。
- 在正常使用过程中,agg和aggregate函数对DataFrame对象操作的功能基本相同,因此只需掌握一个即可。
分组运算
-
transform方法
通过transform方法可以将运算分布到每一行。 -
使用apply方法聚合数据
apply方法类似于agg方法,能够将函数应用于每一列。
透视表
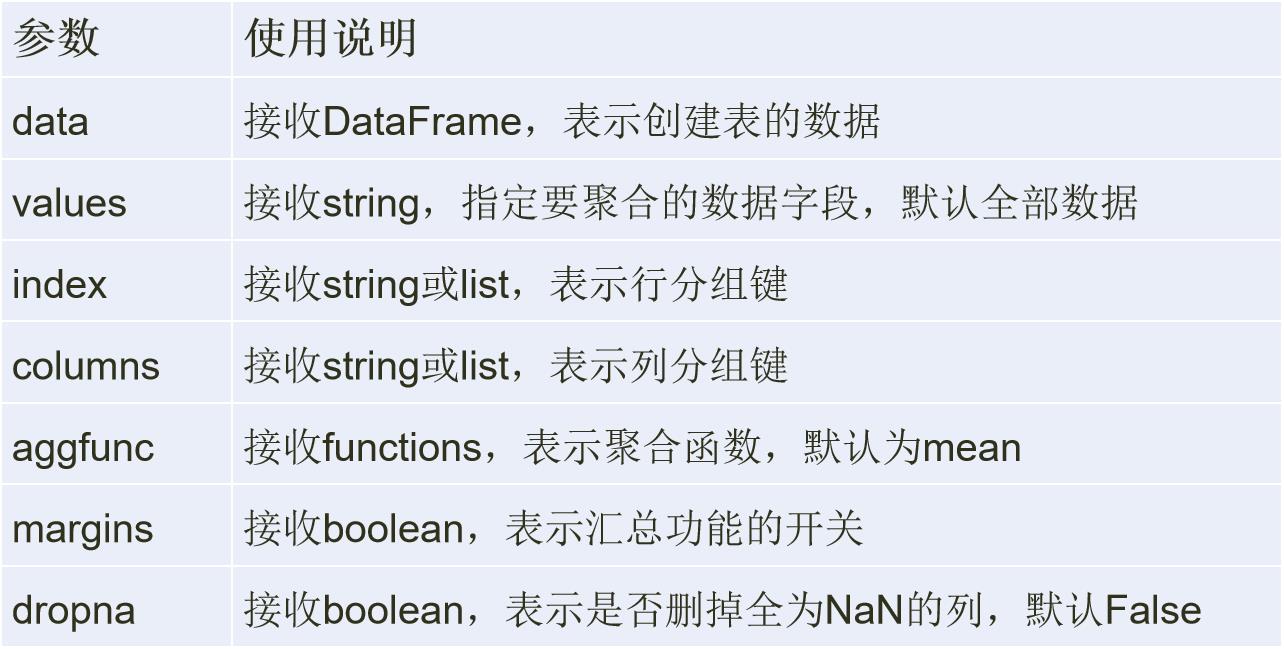
数据透视表(Pivot Table)是数据分析中常见的工具之一,根据一个或多个键值对数据进行聚合,根据列或行的分组键将数据划分到各个区域。
pivot_table函数格式:
pivot_table(data, values=None, index=None, columns=None,
aggfunc='mean', fill_value=None, margins=False,
dropna=True, margins_name='All')
交叉表是一种特殊的透视表,主要用于计算分组频率。
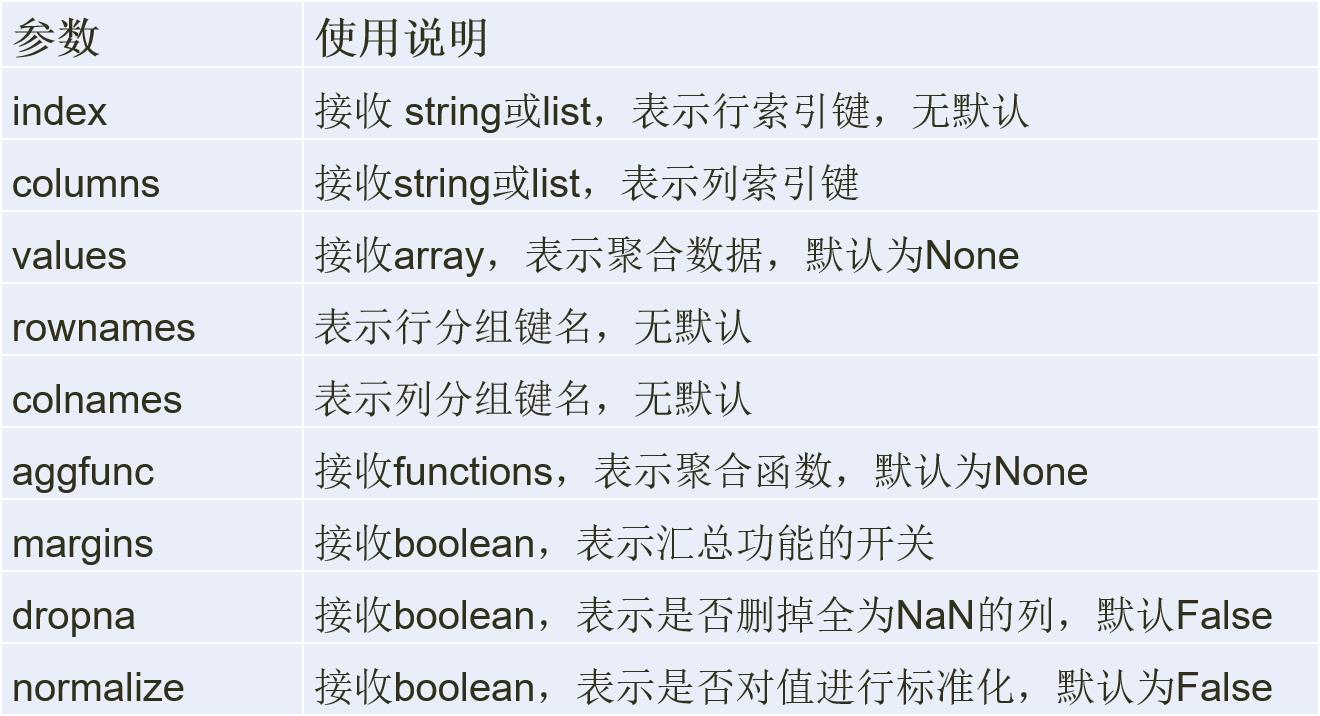
crosstab的格式:
crosstab(index, columns, values=None,
rownames=None, colnames=None,
aggfunc=None,
margins=False, dropna=True, normalize=False)
直方图和密度图
- 直方图用于频率分布,y轴为数值或比率。绘制直方图,可以观察数据值的大致分布规律。pandas中的直方图可以通过hist方法绘制。
- 核密度估计是对真实密度的估计,其过程是将数据的分布近似为一组核(如正态分布)。通过plot函数的kind = ‘kde’可以进行绘制。
散点图主要用来表现数据之间的规律。
- 通过plot函数的kind = 'scatter’可以进行绘制。
Pandas的数据对象在进行算术运算时如果存在不同索引会进行数据对齐,但会引入NAN值
5. Pandas数据载入与预处理
对于数据分析而言,数据大部分来源于外部数据,如常用的CSV文件、Excel文件和数据库文件等。Pandas库将外部数据转换为DataFrame数据格式,处理完成后再存储到相应的外部文件中。
1.文本文件读取
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。
-
txt文件:是Windows操作系统上附带的一种文本格式,文件以.txt为后缀。
-
CSV文件:是Comma-Separated Values的缩写,用半角逗号(’,’)作为字段值的分隔符。
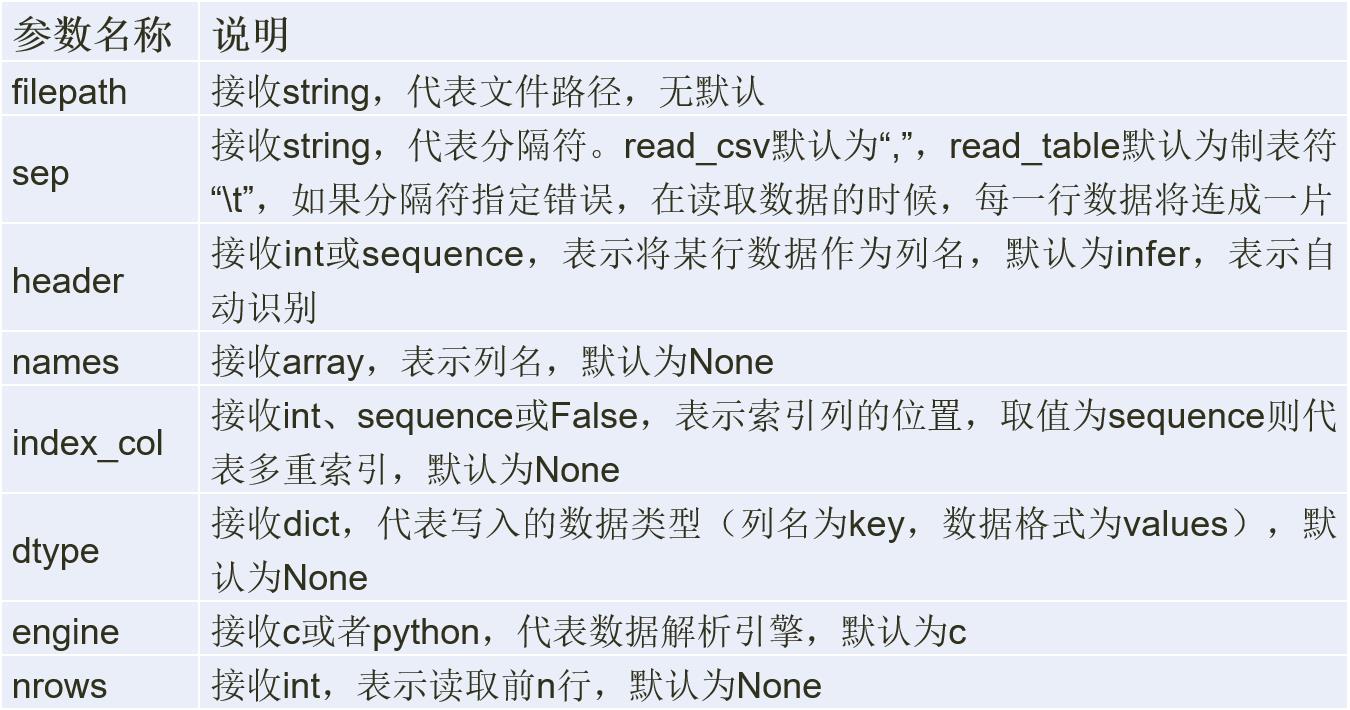
Pandas中使用read_table来读取文本文件:
pandas.read_table(filepath_or_buffer, sep=’\\t’,
header=’infer’, names=None, index_col=None,
dtype=None, engine=None, nrows=None)
Pandas中使用read_csv函数来读取CSV文件:
pandas.read_csv(filepath_or_buffer, sep=’,’,
header=’infer’, names=None, index_col=None,
dtype=None, engine=None, nrows=None)
2. 文本文件的存储
DataFrame.to_csv(path_or_buf = None, sep = ’,’, na_rep,
columns=None, header=True, index=True, index_label=None,
mode=’w’, encoding=None)
1. Excel文件的读取
pandas.read_excel(io, sheetname, header=0,
index_col=None, names=None, dtype)

JSON数据的读取与存储
JSON (javascript Object Notation) 数据是一种轻量级的数据交换格式,因其简洁和清晰的层次结构使其成为了理想的数据交换语言。JSON数据使用大括号来区分表示并存储。
1. Pandas读取JSON数据
Pandas通过read_json函数读取JSON数据。读取代码如下:
import pandas as pd
df=pd.read_json(‘FileName’)
df=df.sort_index
2. JSON数据的存储
Pandas使用pd.to_json实现将DataFrame数据存储为JSON文件。
读取数据库文件
- Pandas读取mysql数据要读取Mysql中的数据,首先要安装Mysqldb包。
import pandas as pd
import MySQLdb
conn = MySQLdb.connect(host = host,port = port,user = username,passwd = password,db = db_name)
df = pd.read_sql('select * from table_name',con=conn) conn.close()
- Pandas读取SQL sever中的数据,首先要安装pymssql包。
import pandas as pd
import pymssql
conn = pymssql.connect(host=host, port=port ,user=username, password=password, database=database)
df = pd.read_sql("select * from table_name",con=conn) conn.close()
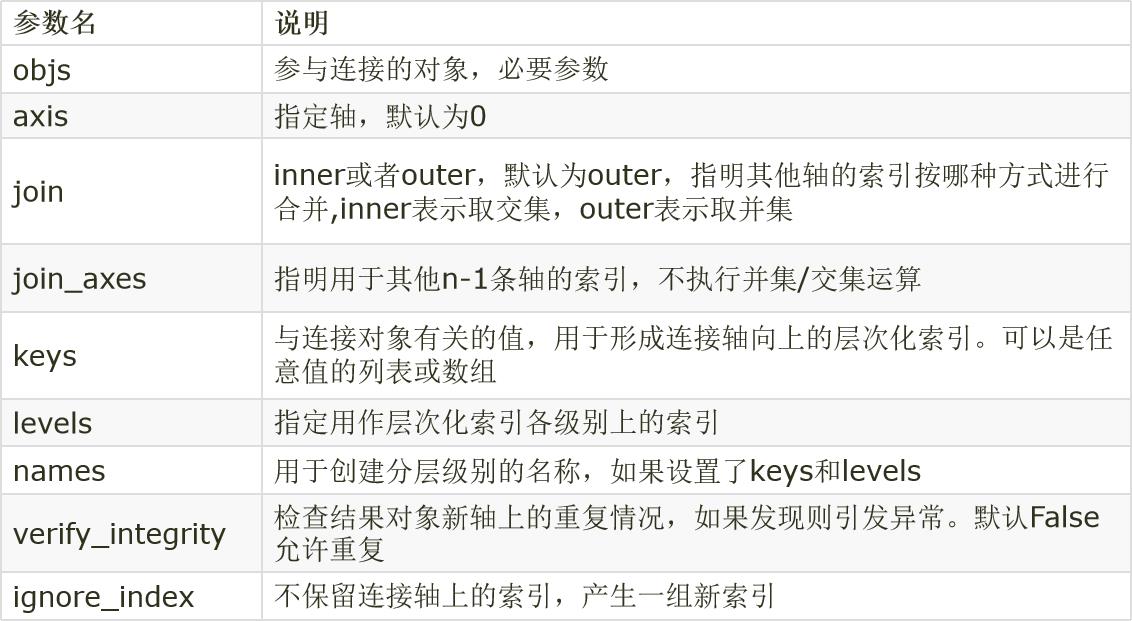
数据合并
merge函数是通过一个或多个键将两个DataFrame按行合并起来,与SQL中的 join 用法类似,Pandas中的数据合并merge( )函数格式如下:
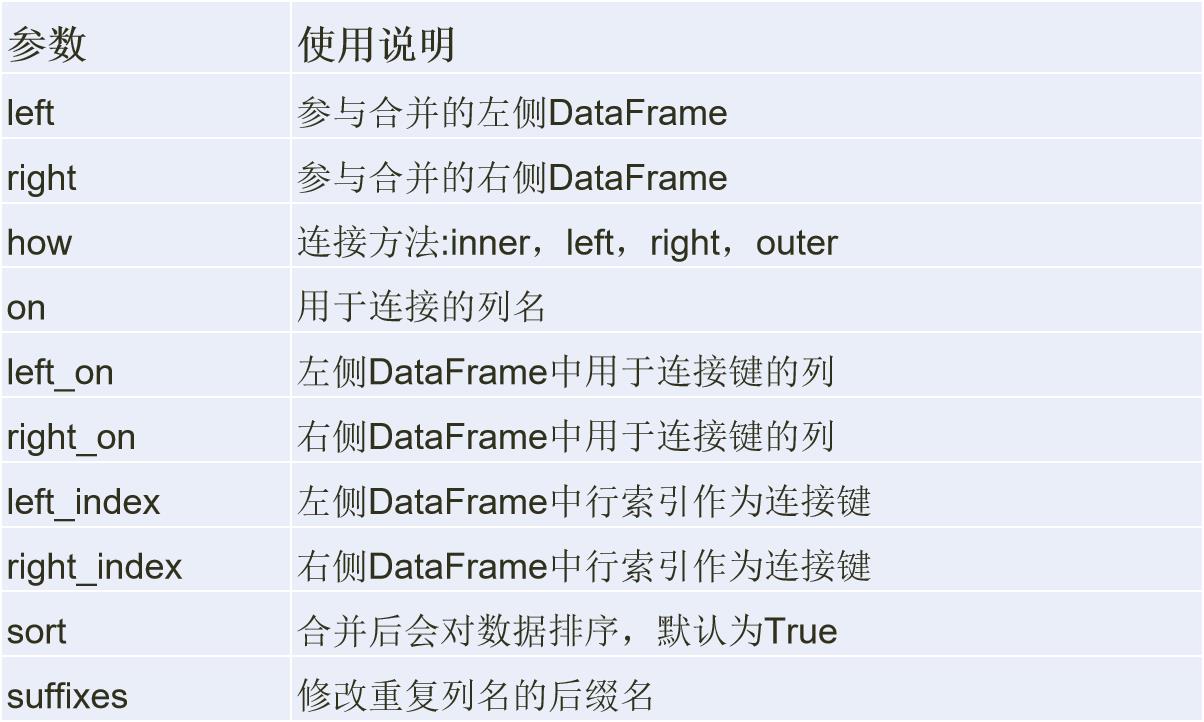
merge合并时默认是内连接(inner),即返回交集。通过how参数可以选择连接方法:左连接(left),右连接(right)和外连接(outer)。
在合并时会出现重复列名,虽然可以人为进行重复列名的修改,但merge函数提供了suffixes用于处理该问题:
concat数据连接:
如果要合并的DataFrame之间没有连接键,就无法使用merge方法。pandas中的concat方法可以实现,默认情况下会按行的方向堆叠数据。如果在列向上连接设置axies = 1即可。
combine_first合并数据
如果需要合并的两个DataFrame存在重复索引,则使用merge和concat都无法正确合并,此时需要使用combine_first方法。
检测与处理缺失值
-
缺失值统计
data.info() -
删除缺失值
df.dropna()

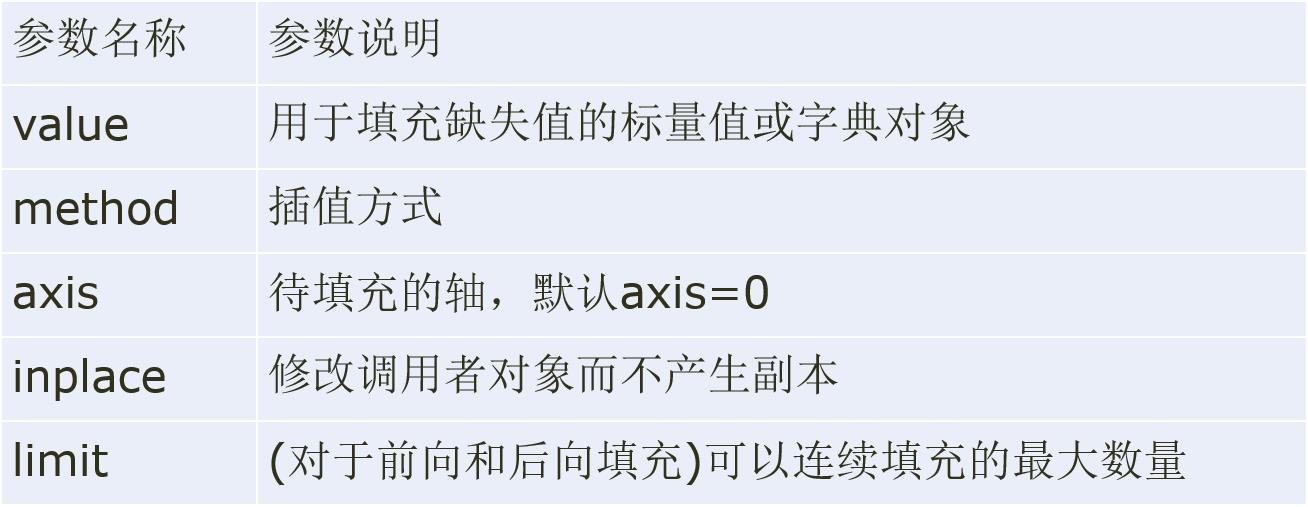
填充缺失值
缺失值所在的特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来填充;缺失值所在特征为类别型数据时,则选择众数来填充。
在DataFrame中利用duplicates方法判断各行是否有重复数据。duplicates方法返回一个布尔值的series,反映每一行是否与之前的行重复。
Pandas通过drop_duplicates删除重复的行,格式为:
drop_duplicates(self, subset=None, keep=’first’, inplace=False)

检测异常值
简单的数据统计方法中常用散点图、箱线图和3σ法则检测异常值。
- 散点图方法: 通过数据分布的散点图发现异常数据。
- 箱线图分析: 利用数据中的五个统计量(最小值、下四分位数、中位数、上四分位数和最大值)来描述数据。
- 3σ法则: 在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值。
散点图方法: 通过数据分布的散点图发现异常数据。
箱线图利用数据中的五个统计量(最小值、下四分位数、中位数、上四分位数和最大值)来描述数据,它也可以粗略地看出数据是否具有对称性、分布的分散程度等信息。
若数据服从正态分布,在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值,因为在正态分布的假设下,距离平均值3σ之外的值出现的概率小于0.003。因此根据小概率事件,可以认为超出3σ之外的值为异常数据。
离差标准化数据
离差标准化是对原始数据所做的一种线性变换,将原始数据的数值映射到[0,1]区间。转换公式如下所示。
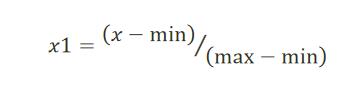
标准差标准化数据
标准差标准化又称零均值标准化或z分数标准化,是当前使用最广泛的数据标准化方法。
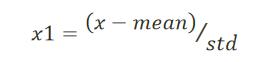
哑变量( Dummy Variables)是用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。
- 利用pandas库中的get_dummies函数对类别型特征进行哑变量处理。

连续型变量的离散化
- 等宽法
Pandas提供了cut函数,可以进行连续型数据的等宽离散化。
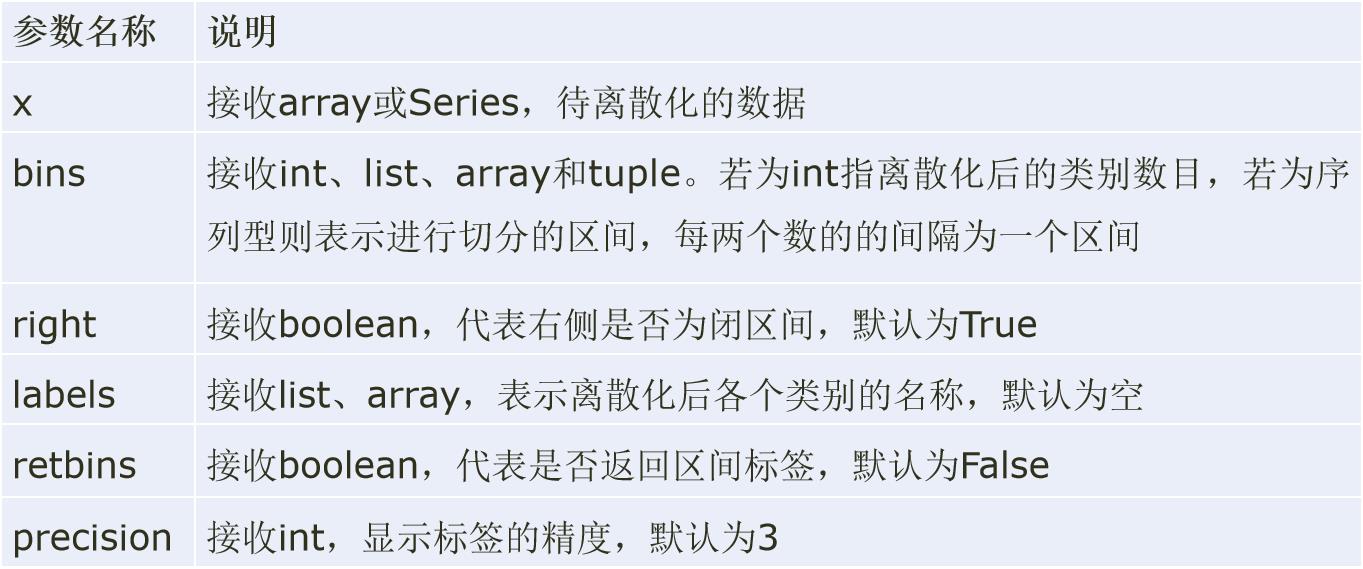
-
等频法
cut函数虽然不能够直接实现等频离散化,但可以通过定义将相同数量的记录放进每个区间。 -
聚类分析法
一维聚类的方法包括两步,首先将连续型数据用聚类算法进行聚类,然后处理聚类得到的簇,为合并到一个簇的连续型数据做同一标记。
简述Python中利用数据统计方法检测异常值的常用方法及其原理。
散点图 箱线图分析 3σ法则,
6. Matplotlib可视化
- Matplotlib 是一个在 python 下实现的类 matlab 的纯 python 的第三方库,旨在用 python实现 matlab 的功能,是python下最出色的绘图库。其风格跟 matlab 相似,同时也继承了 python 的简单明了。
- 要使用matplotlib得先安装 numpy 库 (一个python下数组处理的第三方库,可以很方便的处理矩阵,数组) 。
- matplotlib 对于图像美化方面比较完善,可以自定义线条的颜色和样式,可以在一张绘图纸上绘制多张小图,也可以在一张图上绘制多条线, 可以很方便地将数据可视化并对比分析。
在Jupyter notebook中进行交互式绘图,需要执行一下语句% matplotlib notebook
相关函数简介
figure():创建一个新的绘图窗口。
figtext():为figure添加文字
axes():为当前figure添加一个坐标轴
plot():绘图函数
polar():绘制极坐标图
axis():获取或设置轴属性的边界方法(坐标的取值范围)
clf : 清除当前figure窗口 cla : 清除当前axes窗口
close : 关闭当前figure窗口
subplot : 一个图中包含多个axes
text(): 在轴上添加文字
title(): 设置当前axes标题
xlabel/ylabel:设置当前X轴或Y轴的标签
hist():绘制直方图
hist2d():绘制二维在直方图
hold :设置当前图窗状态;off或者on
imread():读取一个图像,从图形文件中提取数组
legend():为当前axes放置标签
pie():绘制饼状图
scatter():做一个X和Y的散点图,其中X和Y是相同长度的序列对象
stackplot():绘制一个堆叠面积图
acorr():绘制X的自相关函数
annotate():用箭头在指定的数据点创建一个注释或一段文本
bar():绘制垂直条形图 barh():绘制横向条形图
barbs():绘制一个倒钩的二维场
创建子图
创建子图
import matplotlib.pyplot as plt
fig = plt.figure()
#不能使用空白的figure绘图,需要创建子图
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
可以用语句Fig , axes = plt.subplots(2,3) 创建一个新的图片,然后返回包含了已生成子图对象的NumPy数组。数组axes可以像二维数组那样方便地进行索引,如axes[0,1]。也可以通过sharex和sharey表明子图分别拥有相同的x轴和y轴。
fig, axes = plt.subplots(2,3)
调整子图周围的间距:plt.subplots_adjust(wspace=0,hspace=0)
plt.savafig:保存绘制的图片,可以指定图片的分辨率、边缘的颜色等参数。
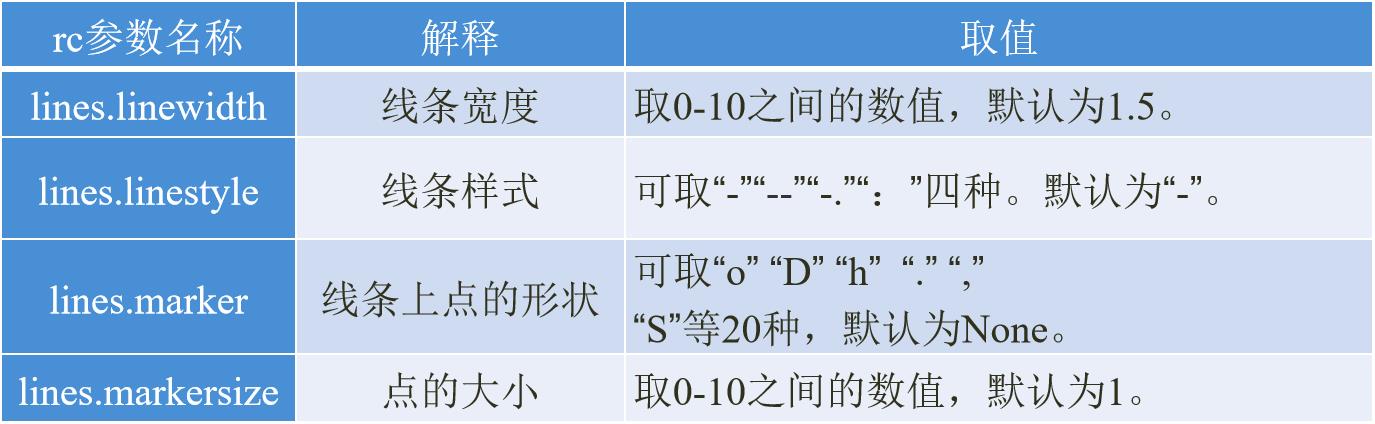
设置pyplot的动态rc参数
- pyplot使用rc配置文件来自定义图形的各种默认属性,被称为rc配置或rc参数。
- 在pyplot中几乎所有的默认属性都是可以控制的,例如视图窗口大小以及每英寸点数、线条宽度、颜色和样式、坐标轴、坐标和网格属性、文本、字体等。
查看matplotlib的rc参数:
import matplotlib as plt
print(plt.rc_params())
常用参数:
Axes:设置坐标轴边界、颜色、坐标
刻度值大小和网格的显示;
Figure:设置边界颜色、图形大小和子区;
Font:设置字号、字体和样式;
Grid:设置网格颜色和线型;
Legend:设置图例和其中的文本显示;
Lines:设置线条颜色、宽度、线型等;
Savefig:对保存图像进行单独设置;
Xtick和ytick:X、Y轴的主刻度和次刻度设置颜色、大小、方向和标签大小。
离散数学期末不挂科复习笔记