最新3D GAN可生成三维几何数据了!模型速度提升7倍,英伟达&斯坦福出品
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新3D GAN可生成三维几何数据了!模型速度提升7倍,英伟达&斯坦福出品相关的知识,希望对你有一定的参考价值。
明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
2D图片变3D,还能给出3D几何数据?
英伟达和斯坦福大学联合推出的这个GAN,真是刷新了3D GAN的新高度。
而且生成画质也更高,视角随便摇,面部都没有变形。

与过去传统的方法相比,它在速度上能快出7倍,而占用的内存却不到其十六分之一。
最厉害的莫过于还可给出3D几何数据,像这些石像效果,就是根据提取的位置信息再渲染而得到的。

甚至还能实时交互编辑。
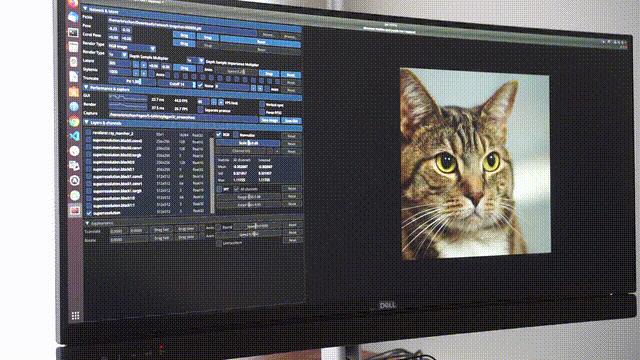
该框架一经发布,就在推特上吸引了大量网友围观,点赞量高达600+。

怎么样?是不是再次刷新你对2D升3D的想象了?
显隐混合+双重鉴别
事实上,只用一张单视角2D照片生成3D效果,此前已经有许多模型框架可以实现。
但是它们要么需要计算量非常大,要么给出的近似值与真正的3D效果不一致。
这就导致生成的效果会出现画质低、变形等问题。
为了解决以上的问题,研究人员提出了一种显隐混合神经网络架构 (hybrid explicit-implicit network architecture)。
这种方法可以绕过计算上的限制,还能不过分依赖对图像的上采样。
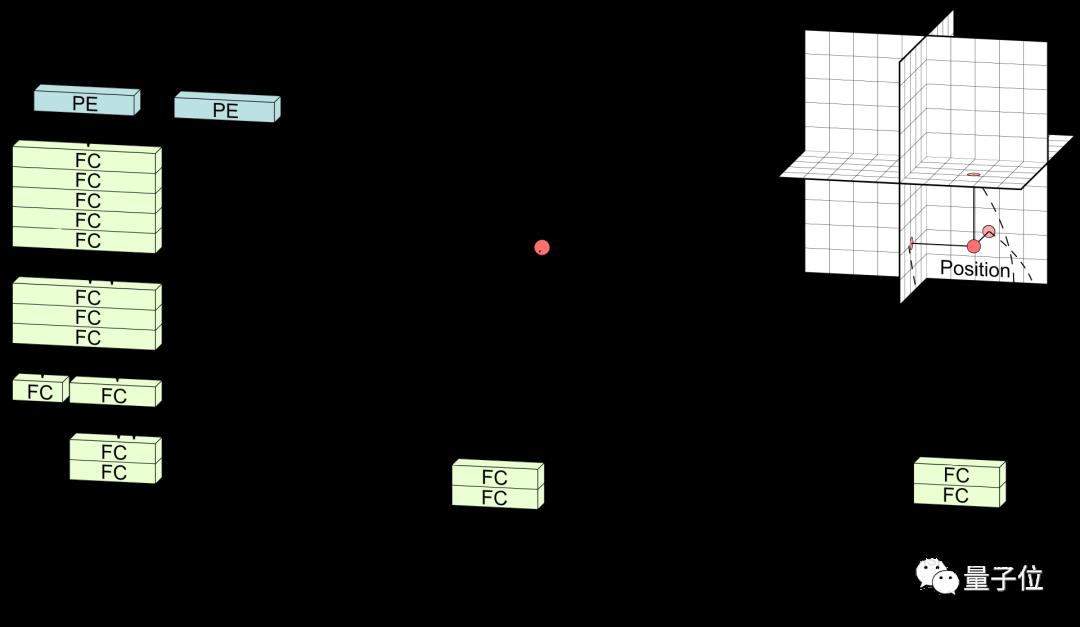
从对比中可以看出,纯隐式神经网络(如NeRF)使用带有位置编码(PE)的完全连接层(FC)来表示场景,会导致确定位置的速度很慢。
纯显式神经网络或混合了小型隐式解码器的框架,虽然速度更快,但是却不能保证高分辨率的输出效果。
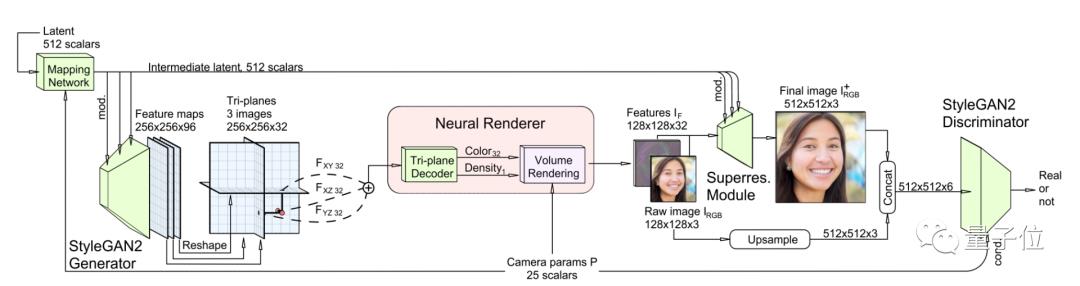
而英伟达和斯坦福大学提出的这个新方法EG3D,就将显式和隐式的表示优点结合在了一起。
它主要包括一个以StyleGAN2为基础的特征生成器和映射网络,一个轻量级的特征解码器,一个神经渲染模块、一个超分辨率模块和一个可以双重识别位置的StyleGAN2鉴别器。
其中,神经网络的主干为显式表示,它能够输出3D坐标;解码器部分则为隐式表示。
与典型的多层感知机制相比,该方法在速度上可快出7倍,而占用的内存却不到其十六分之一。
与此同时,该方法还继承了StyleGAN2的特性,比如效果良好的隐空间(latent space)。
比如,在数据集FFHQ中插值后,EG3D的表现非常nice:

该方法使用中等分辨率(128 x 128)进行渲染,再用2D图像空间卷积来提高最终输出的分辨率和图像质量。
这种双重鉴别,可以确保最终输出图像和渲染输出的一致性,从而避免在不同视图下由于卷积层不一致而产生的问题。

△两图中左半边为最终输出效果,右半边为渲染输出
而没有使用双重鉴别的方法,在嘴角这种细节上就会出现一些扭曲。

△左图未使用双重鉴别;右图为EG3D方法效果
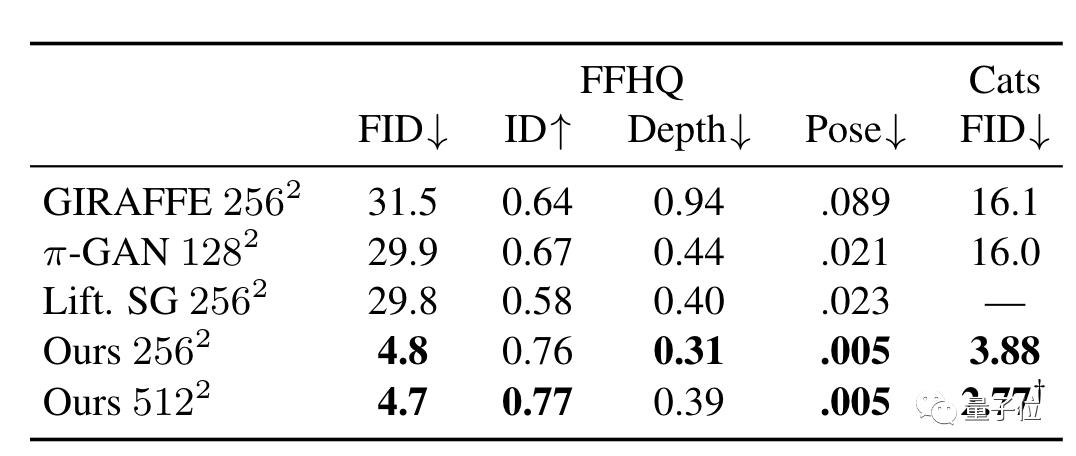
数据上,与此前方法对比,EG3D方法在256分辨率、512分辨率下的距离得分(FID)、识别一致性(ID)、深度准确性和姿态准确性上,表现都更好。
团队介绍
此项研究由英伟达和斯坦福大学共同完成。
共同一作共有4位,分别是:Eric R. Chan、Connor Z. Lin、Matthew A. Chan、Koki Nagano。
其中,Eric R. Chan是斯坦福大学的一位博士研究生,此前曾参与过一些2D图像变3D的方法,比如pi-GAN。

Connor Z. Lin是斯坦福大学的一位正在读博二的研究生,本科和硕士均就读于卡内基梅隆大学,研究方向为计算机图形学、深度学习等。

Matthew A. Chan则是一位研究助理,以上三人均来自斯坦福大学计算机成像实验室(Computational Imaging Lab)。
Koki Nagano目前就职于英伟达,担任高级研究员,研究方向为计算机图形学,本科毕业于东京大学。

论文地址:
https://arxiv.org/abs/2112.07945
参考链接:
https://matthew-a-chan.github.io/EG3D/
以上是关于最新3D GAN可生成三维几何数据了!模型速度提升7倍,英伟达&斯坦福出品的主要内容,如果未能解决你的问题,请参考以下文章