改进的YOLOv5:AF-FPN替换金字塔模块提升目标检测精度
Posted 计算机视觉研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了改进的YOLOv5:AF-FPN替换金字塔模块提升目标检测精度相关的知识,希望对你有一定的参考价值。
关注并星标
从此不迷路
计算机视觉研究院



公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
源代码:https://arxiv.org/pdf/2112.08782.pdf
计算机视觉研究院专栏
作者:Edison_G
随着世界迈向第四次工业革命,电动车越来越普遍,但是路上的交通标志也五花八门,如果利用计算机视觉技术可以全部检测识别,那也是一大进步!
一、前言

交通标志检测对于无人驾驶系统来说是一项具有挑战性的任务,特别是对于多尺度目标的检测和检测的实时性问题。在交通标志检测过程中,目标的尺度变化很大,会对检测精度产生一定的影响。
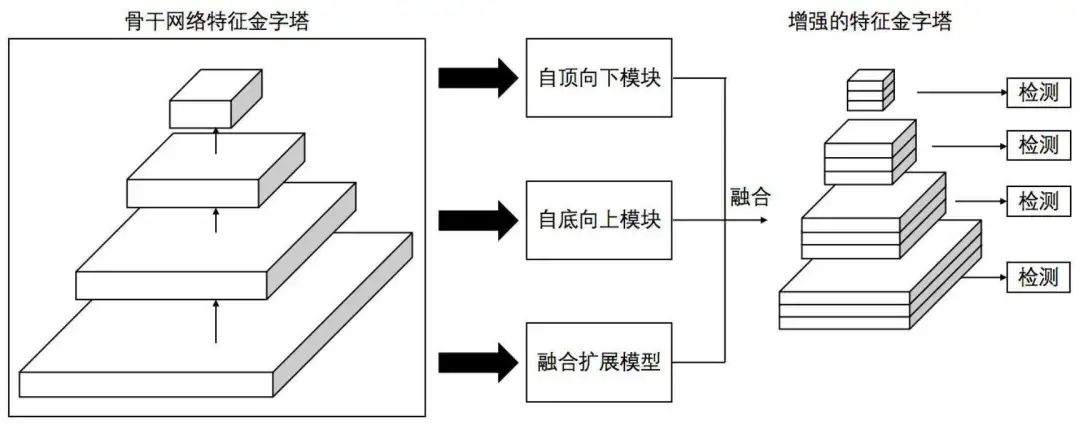
特征金字塔被广泛用于解决这个问题,但它可能会破坏不同尺度交通标志的特征一致性。而且,在实际应用中,常用的方法很难在保证检测实时性的同时提高多尺度交通标志的检测精度。
在今天分享中,研究者提出了一种改进的特征金字塔模型,命名为AF-FPN,它利用自适应注意力模块(AAM)和特征增强模块(FEM)来减少特征图生成过程中的信息丢失并增强表示能力的特征金字塔。将YOLOv5中原有的特征金字塔网络替换为AF-FPN,在保证实时检测的前提下提高了YOLOv5网络对多尺度目标的检测性能。此外,提出了一种新的自动学习数据增强方法来丰富数据集并提高模型的鲁棒性,使其更适合实际场景。在Tsinghua-Tencent 100K (TT100K) 数据集上的大量实验结果证明了与几种最先进的方法相比所提出的方法的有效性和优越性。
二、背景

交通标志识别系统化是自动驾驶中最重要的一部分,怎样去提升交通标志检测和识别技术的精度和实时性能,这个也是现在当技术实际落地时需要解决的重要问题。传统的CNN通常需要大量的参数和浮点运算 (FLOP) 以达到准确性令人满意的效果,例如ResNet-50有大约2560万个参数和需要4.1B FLOPs来处理大小为224×224的图像。然而,移动设备(例如智能手机和自动驾驶汽车)有限的内存和计算资源不能用于大型网络的部署和推理。作为一个one-stage检测器,使用YOLOv5是由于具有计算量小、速度快的优点。
三、新框架详细分析
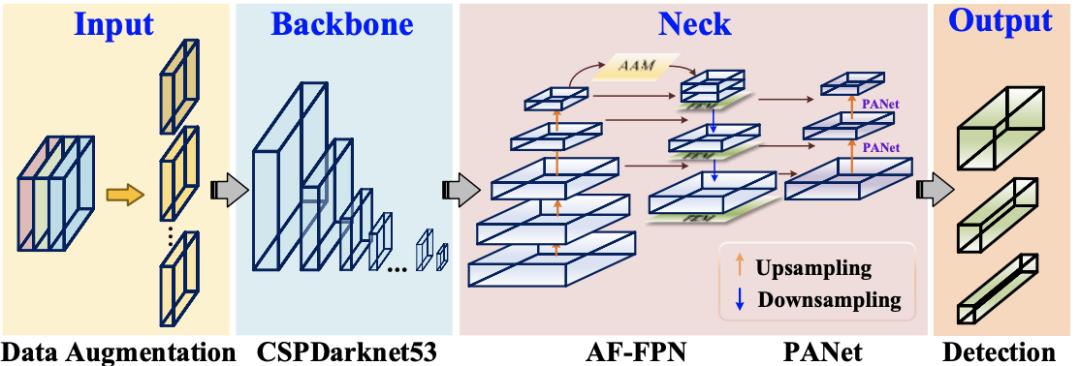
The improved YOLOv5s network framework
作为当前YOLO系列中的最新框架,卓越的YOLOv5其灵活性使其便于快速在车辆硬件方面进行部署。YOLOv5包含四个模型,分别是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。YOLOv5s是YOLO系列最小的模型,更适合部署在车载移动硬件平台,由于其内存大小为14.10M,但识别精度达不到准确、高效识别的要求,尤其是用于识别小规模目标。YOLOv5的基本框架可以分为四个部分:input、backbone、neck和prediction。Input部分通过数据增强来丰富数据集,它具有对硬件设备要求低,计算量成本低。但是它会导致数据集中原来的小目标变小,从而导致数据集的恶化,降低模型的泛化性能。Backbone部分主要由CSP模块组成,它们通过CSPDarknet53执行特征提取。FPN和PANet用于聚合Neck现阶段的图像特征。最后,网络通过Prediction进行目标预测和输出。
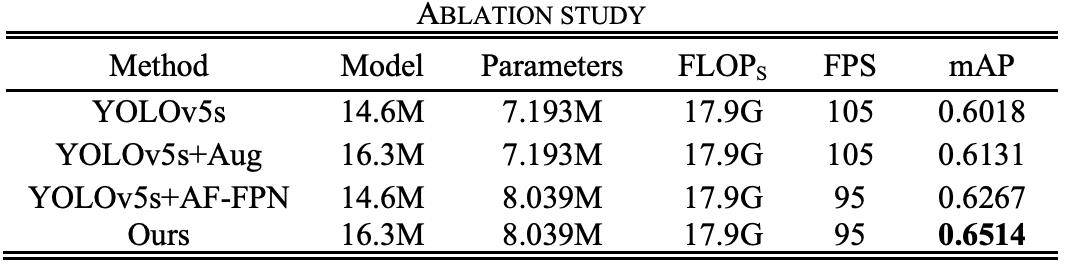
研究者引入AF-FPN和自动学习数据增强来解决模型大小和识别精度不兼容的问题,进一步提高模型的识别性能。将原有的FPN结构替换为AF-FPN,以提高识别多尺度目标的能力,并在识别速度和准确率之间做出有效的权衡。
此外,研究者去除原始网络中的mosaic augmentation,并根据自动学习数据增强策略使用最佳数据增强方法来丰富数据集并提高训练效果。改进后的YOLOv5s网络结构如下图所示。
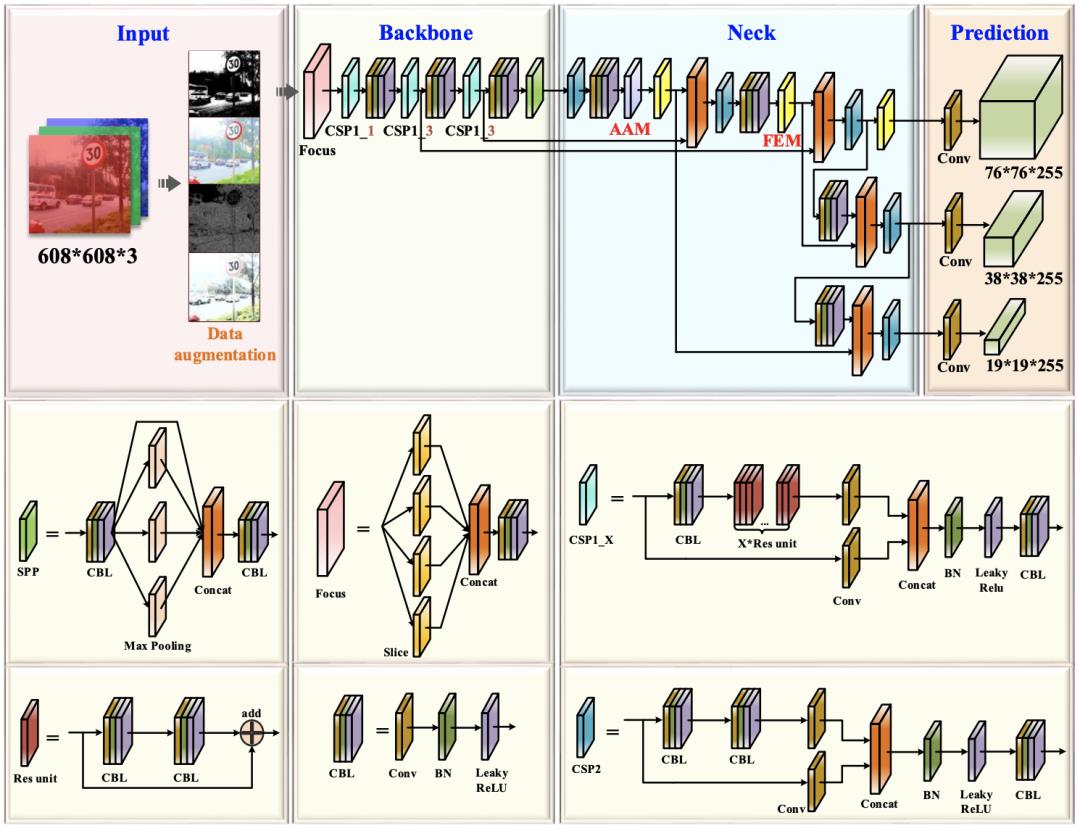
AF-FPN structure
AF-FPN在传统特征金字塔网络的基础上,增加了自适应注意力模块(AAM)和特征增强模块(FEM)。前一部分由于减少了特征通道,减少了在高层特征图中上下文信息的丢失;后一部分增强了特征金字塔的表示并加快了推理速度,同时实现了最先进的性能。AF-FPN的结构如下图所示。
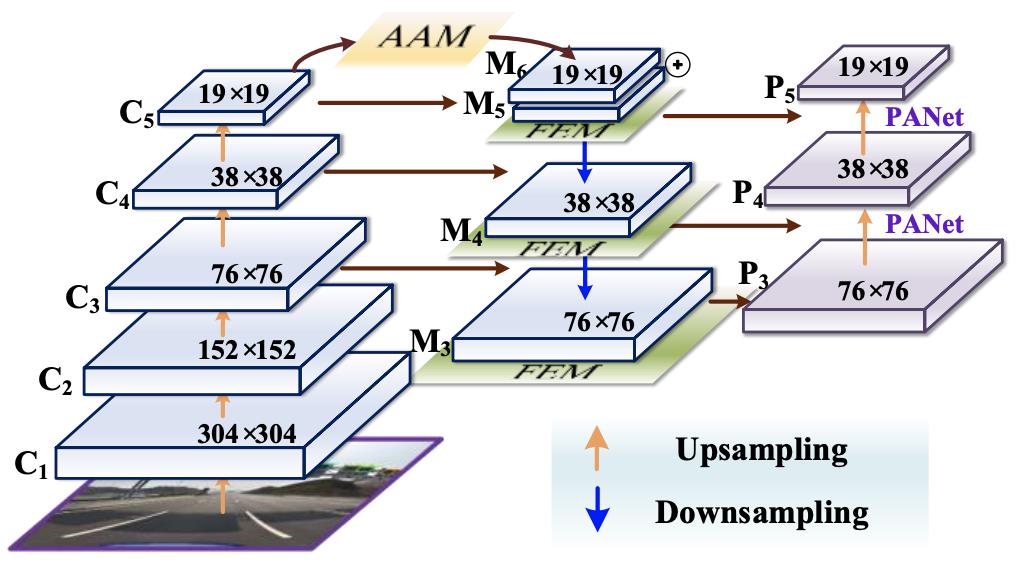
AAM的具体结构如下图所示,作为自适应注意力模块的输入,C5的大小为S=h×w。它首先通过自适应池化层获得不同尺度(β1×S,β2×S,β3×S)的上下文特征。然后每个上下文特征经过1×1卷积,得到相同的通道维度256。使用双线性插值将它们上采样到S的尺度,用于后续融合。
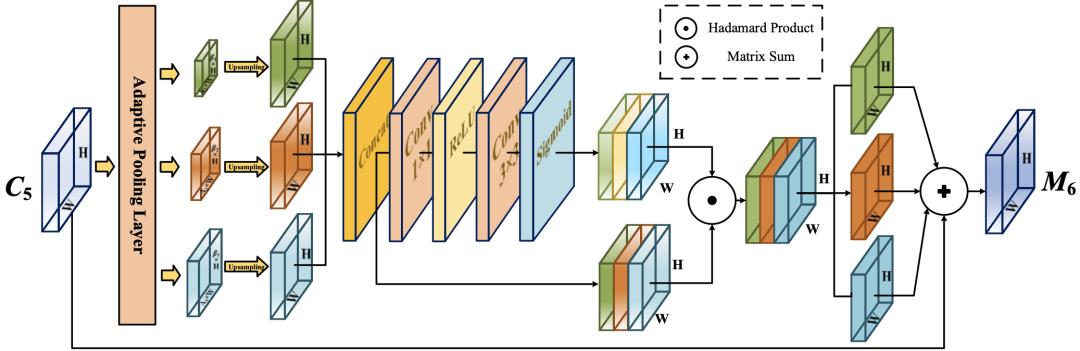
空间注意力机制通过一个Concat层将三个上下文特征的通道合并,然后特征图依次通过1×1卷积层、ReLU激活层、3×3卷积层和sigmoid激活层生成对应的空间权重。生成的权重图和合并通道后的特征图进行Hadamard乘积运算,分离后加入到输入特征图M5中,将上下文特征聚合到M6中。最终的特征图具有丰富的多尺度上下文信息,在一定程度上缓解了由于通道数减少而造成的信息丢失。
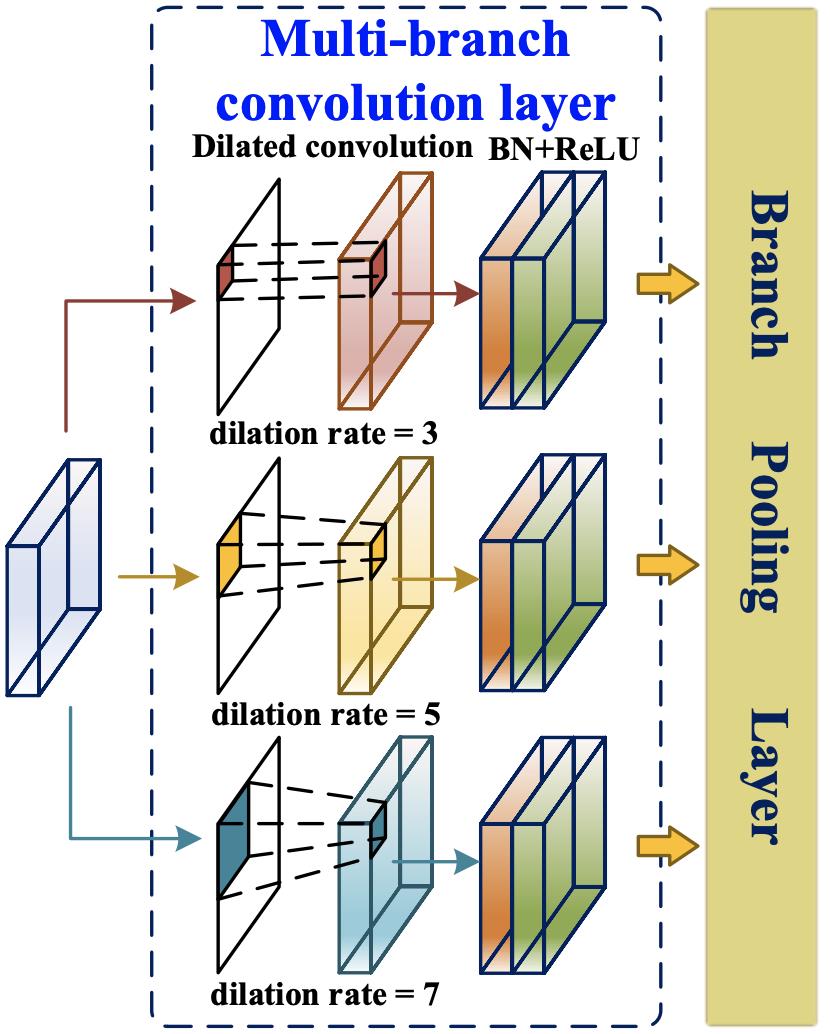
FEM主要利用空洞卷积根据检测到的交通标志的不同尺度自适应学习每个特征图中不同的感受野,从而提高多尺度目标检测和识别的准确性。如上图所示,它可以分为两个部分:多分支卷积层和多分支池化层。多分支卷积层用于通过空洞卷积为输入特征图提供不同大小的感受野。并且平均池化层用于融合来自三个分支感受野的交通信息,以提高多尺度预测的准确性。
Data Augmentation
数据增强我就简单描述下,具体如下示例:

四、实验结果及可视化
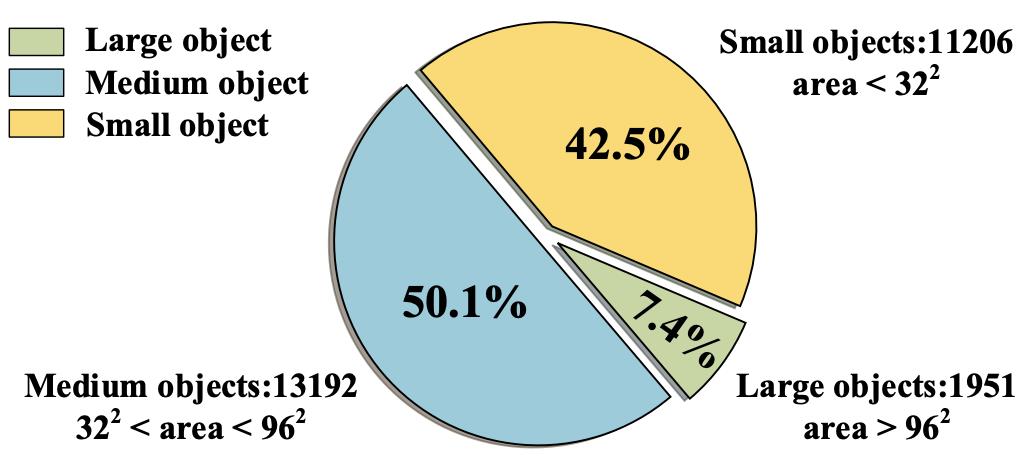
Size distribution of sign instances from the TT100K
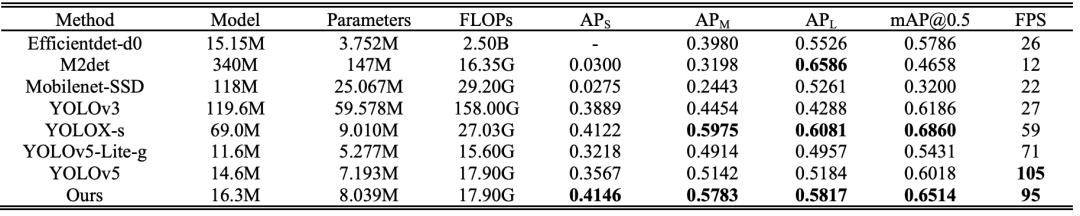
在TT100K数据集上与其他模型的性能比较
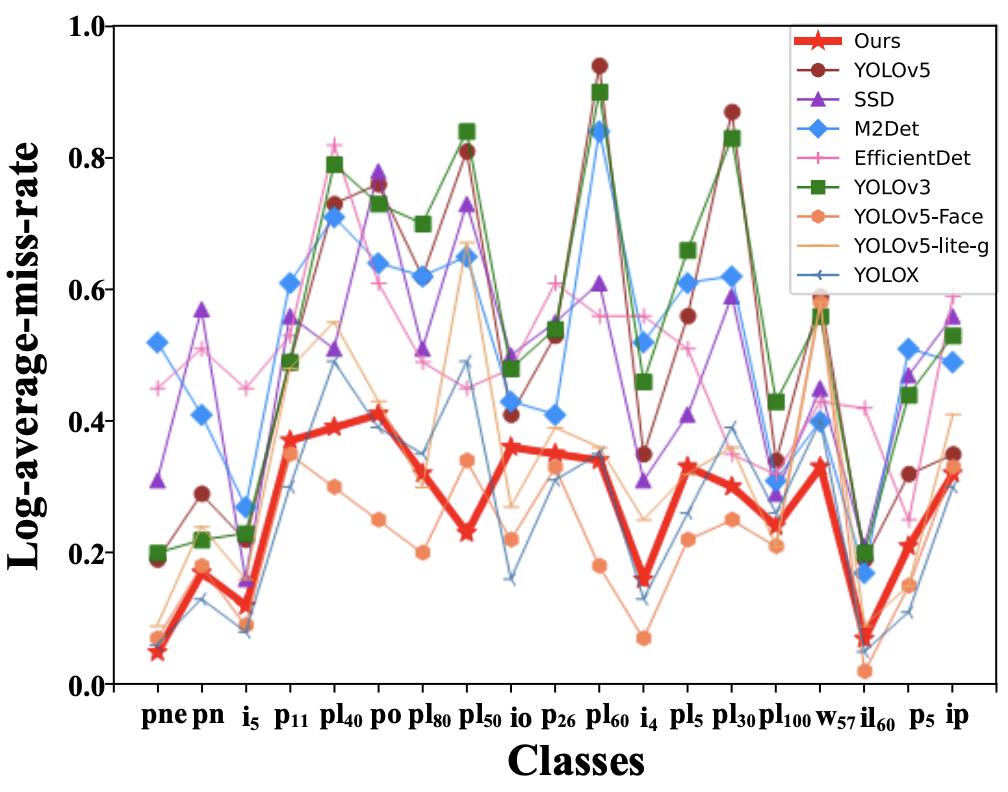
每种方法对19种交通标志的漏检率比较

移动设备部署及通过摄像头拍摄的检测实例

© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
以上是关于改进的YOLOv5:AF-FPN替换金字塔模块提升目标检测精度的主要内容,如果未能解决你的问题,请参考以下文章
YOLOv5/v7/v8改进最新主干系列BiFormer:顶会CVPR2023即插即用,小目标检测涨点必备,首发原创改进,基于动态查询感知的稀疏注意力机制构建高效金字塔网络架构,打造高精度检测器
改进YOLOv5系列:首发结合最新Extended efficient Layer Aggregation Networks结构,高效的聚合网络设计,提升性能
睿智的目标检测56——Pytorch搭建YoloV5目标检测平台