睿智的目标检测56——Pytorch搭建YoloV5目标检测平台
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了睿智的目标检测56——Pytorch搭建YoloV5目标检测平台相关的知识,希望对你有一定的参考价值。
睿智的目标检测56——Pytorch搭建YoloV5目标检测平台
学习前言
这个很久都没有学,最终还是决定看看,复现的是YoloV5的第5版,V5有好多版本在,作者也一直在更新,我选了这个时间的倒数第二个版本。

源码下载
https://github.com/bubbliiiing/yolov5-pytorch
喜欢的可以点个star噢。
YoloV5改进的部分(不完全)
1、主干部分:使用了Focus网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。该结构在YoloV5第5版之前有所应用,最新版本中未使用。
2、数据增强:Mosaic数据增强、Mosaic利用了四张图片进行拼接实现数据中增强,根据论文所说其拥有一个巨大的优点是丰富检测物体的背景!且在BN计算的时候一下子会计算四张图片的数据!
3、多正样本匹配:在之前的Yolo系列里面,在训练时每一个真实框对应一个正样本,即在训练时,每一个真实框仅由一个先验框负责预测。YoloV5中为了加快模型的训练效率,增加了正样本的数量,在训练时,每一个真实框可以由多个先验框负责预测。
以上并非全部的改进部分,还存在一些其它的改进,这里只列出来了一些我比较感兴趣,而且非常有效的改进。
YoloV5实现思路
一、整体结构解析
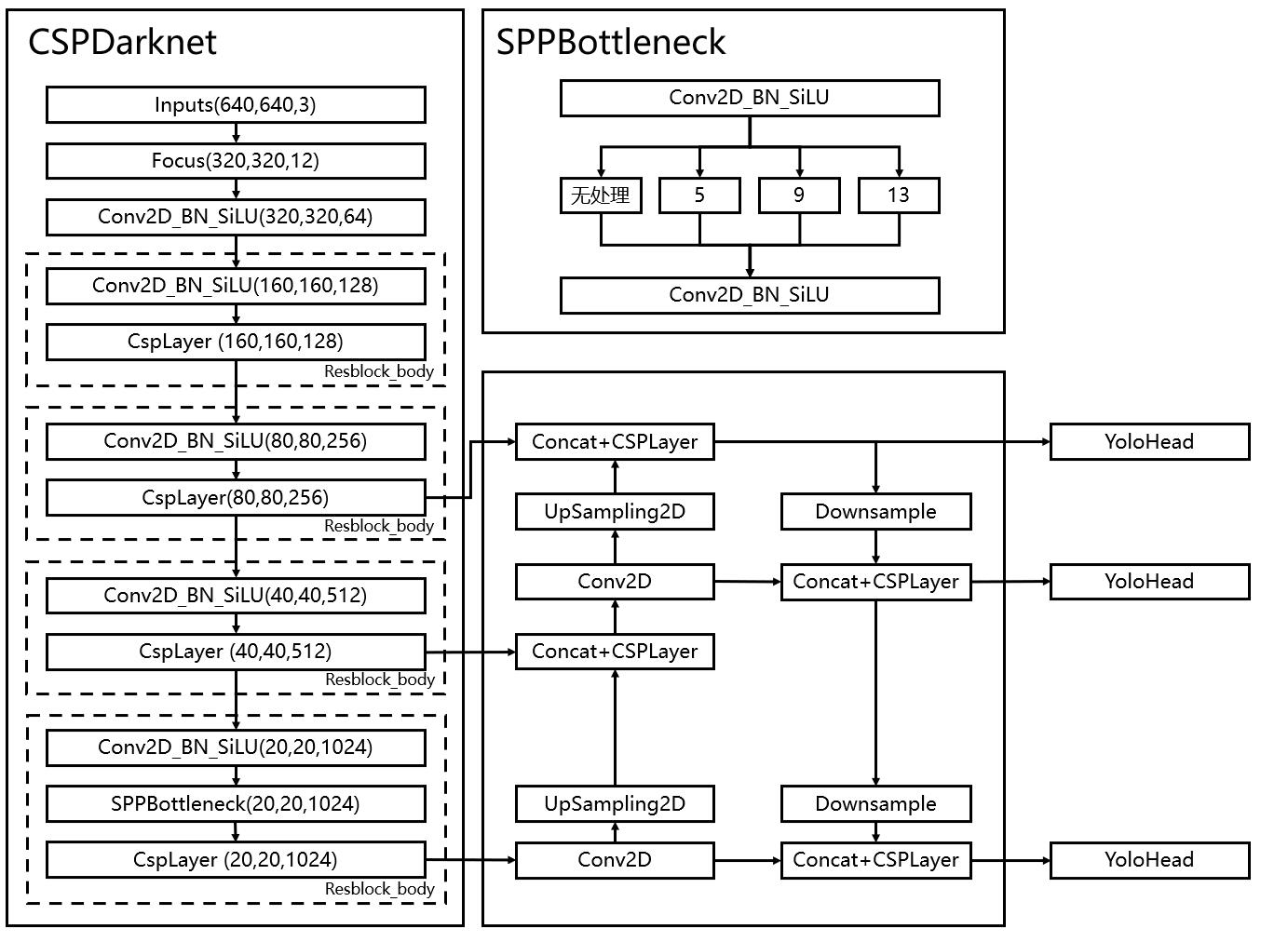
在学习YoloV5之前,我们需要对YoloV5所作的工作有一定的了解,这有助于我们后面去了解网络的细节。
和之前版本的Yolo类似,整个YoloV5可以依然可以分为三个部分,分别是Backbone,FPN以及Yolo Head。
Backbone可以被称作YoloV5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet,输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN可以被称作YoloV5的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV5里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
Yolo Head是YoloV5的分类器与回归器,通过CSPDarknet和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。与以前版本的Yolo一样,YoloV5所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YoloV5网络所作的工作就是 特征提取-特征加强-预测特征点对应的物体情况。
二、网络结构解析
1、主干网络Backbone介绍
YoloV5所使用的主干特征提取网络为CSPDarknet,它具有五个重要特点:
1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV3的主干部分都由残差卷积构成:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))

残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2、使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。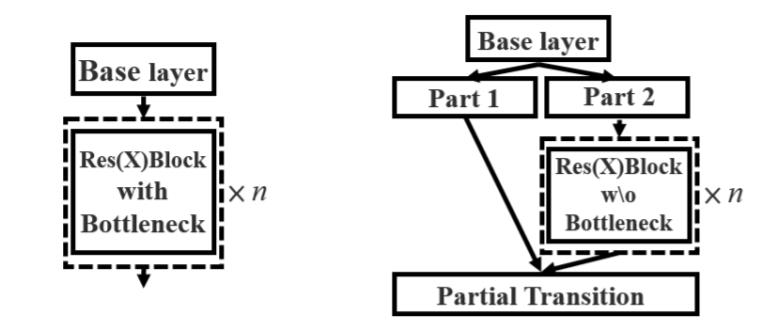
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
3、使用了Focus网络结构,这个网络结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道,下图很好的展示了Focus结构,一看就能明白。
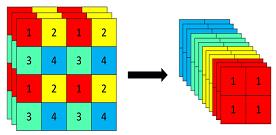
class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
4、使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。
f
(
x
)
=
x
⋅
sigmoid
(
x
)
f(x) = x · \\textsigmoid(x)
f(x)=x⋅sigmoid(x)
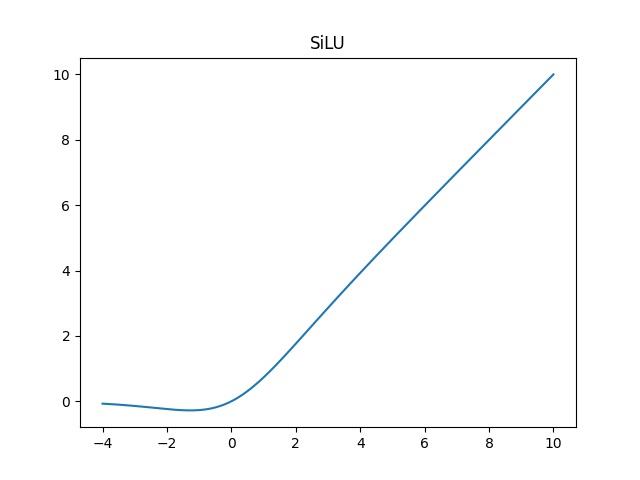
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
5、使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
整个主干实现代码为:
import torch
import torch.nn as nn
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act = SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class CSPDarknet(nn.Module):
def __init__(self, base_channels, base_depth):
super().__init__()
#-----------------------------------------------#
# 输入图片是640, 640, 3
# 初始的基本通道是64
#-----------------------------------------------#
#-----------------------------------------------#
# 利用focus网络结构进行特征提取
# 640, 640, 3 -> 320, 320, 12 -> 320, 320, 64
#-----------------------------------------------#
self.stem = Focus(3, base_channels, k=3)
#-----------------------------------------------#
# 完成卷积之后,320, 320, 64 -> 160, 160, 128
# 完成CSPlayer之后,160, 160, 128 -> 160, 160, 128
#-----------------------------------------------#
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2),
C3(base_channels * 2, base_channels * 2, base_depth),
)
#-----------------------------------------------#
# 完成卷积之后,160, 160, 128 -> 80, 80, 256
# 完成CSPlayer之后,80, 80, 256 -> 80, 80, 256
#-----------------------------------------------#
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2),
C3(base_channels * 4, base_channels * 4, base_depth * 3),
)
#-----------------------------------------------#
# 完成卷积之后,80, 80, 256 -> 40, 40, 512
# 完成CSPlayer之后,40, 40, 512 -> 40, 40, 512
#-----------------------------------------------#
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2),
C3(base_channels * 8, base_channels * 8, base_depth * 3),
)
#-----------------------------------------------#
# 完成卷积之后,40, 40, 512 -> 20, 20, 1024
# 完成SPP之后,20, 20, 1024 -> 20, 20, 1024
# 完成CSPlayer之后,20, 20, 1024 -> 20, 20, 1024
#-----------------------------------------------#
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2),
SPP(base_channels * 16, base_channels * 16),
C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False),
)
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
#-----------------------------以上是关于睿智的目标检测56——Pytorch搭建YoloV5目标检测平台的主要内容,如果未能解决你的问题,请参考以下文章