JavaScript 动态渲染页面爬取 —— 基于 Splash
Posted Amo Xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript 动态渲染页面爬取 —— 基于 Splash相关的知识,希望对你有一定的参考价值。
一、安装 Splash
Splash 是一个 javascript 渲染服务,是一个含有 HTTP API 的轻量级浏览器,它还对接了 Python 中的 Twisted 库和 QT 库。利用它,同样可以爬取动态渲染的页面。利用 Splash,可以实现如下功能:
- 异步处理多个网页的渲染过程;
- 获取渲染后页面的源代码或截图。
- 通过关闭图片渲染或者使用 Adblock 规则的方式加快页面渲染的速度;
- 执行特定的 JavaScript 脚本;
- 通过 Lua 脚本控制页面的渲染过程;
- 获取页面渲染的详细过程并以 HAR(HTTP Archive) 的格式呈现出来。
Splash 建议的安装方式是通过 docker,安装是通过 docker 安装,在这之前请确保已经正确安装好了 docker,官方文档如下:
https://docs.docker.com/desktop/windows/install/
有了 docker,只需要一键启动 Splash 即可,命令如下:
docker run -p 8050:8050 scrapinghub/splash
安装完成之后如下图所示:
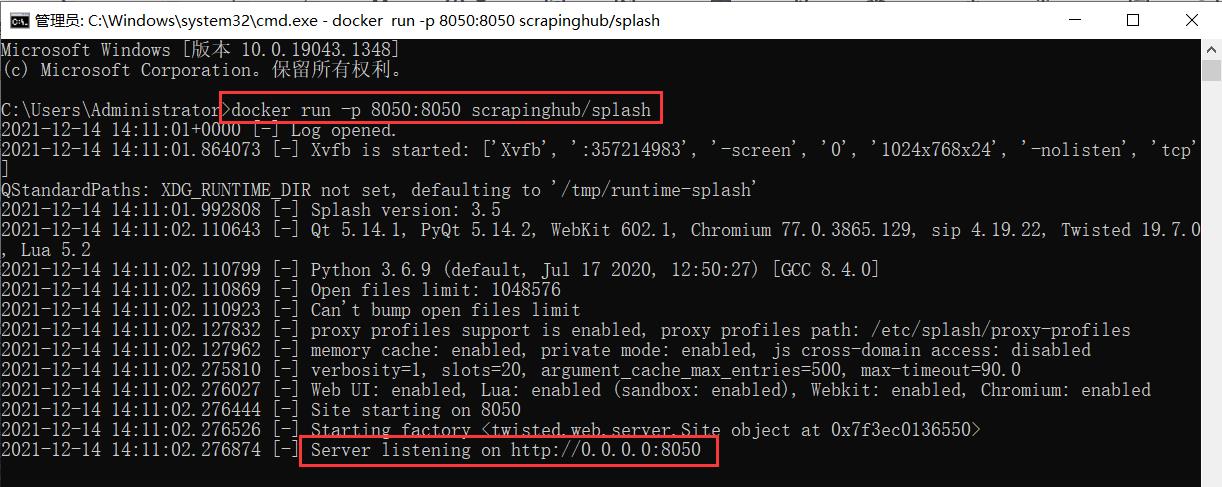
这样就证明 Splash 已经在 8050 端口上运行了。这时我们使用 Google 浏览器打开地址:http://localhost:8050 即可看到 Splash 的主页,如下图所示:

Splash 也可以直接安装在远程服务器上,在服务器上以守护态运行 Splash 即可,命令如下:
docker run -d -p 8050:8050 scrapinghub/splash
在这里多了一个 -d 参数,它代表将 docker 容器以守护态运行,这样在中断远程服务器连接后不会终止 Splash 服务的运行。docker 基础学习笔记可以参考此文章:https://blog.csdn.net/xw1680/article/details/113360133
二、Splash 的使用
1、基本用法:
在本机 8050 端口上运行 Splash 服务,然后打开 http://localhost:8050/,即可看到 Splash 的 Web 页面,如下图所示:
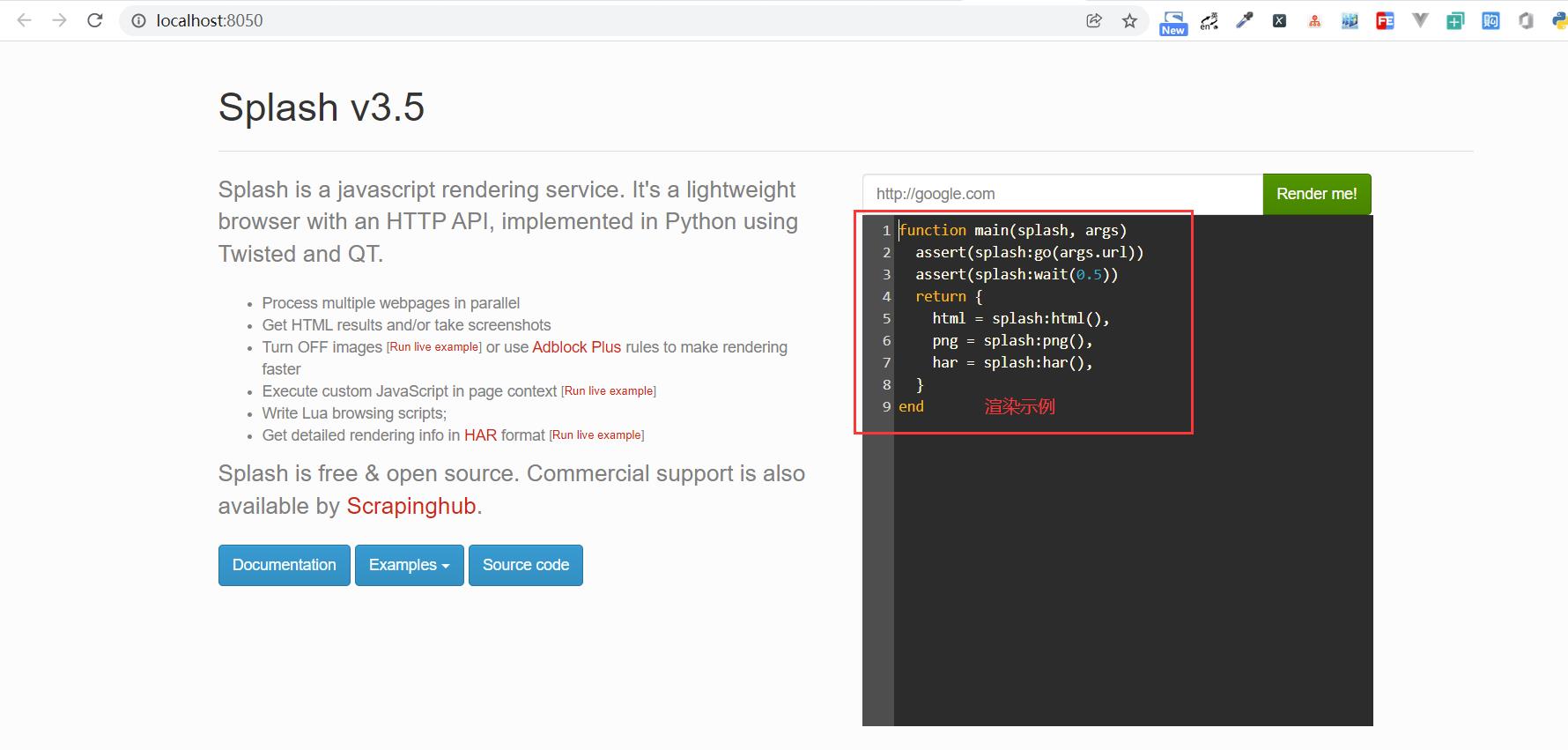
我们可以更改上方输入框中的 URL 为 https://blog.csdn.net/xw1680?,换完内容后单击 Render me!按钮,开始渲染,结果如下图所示:
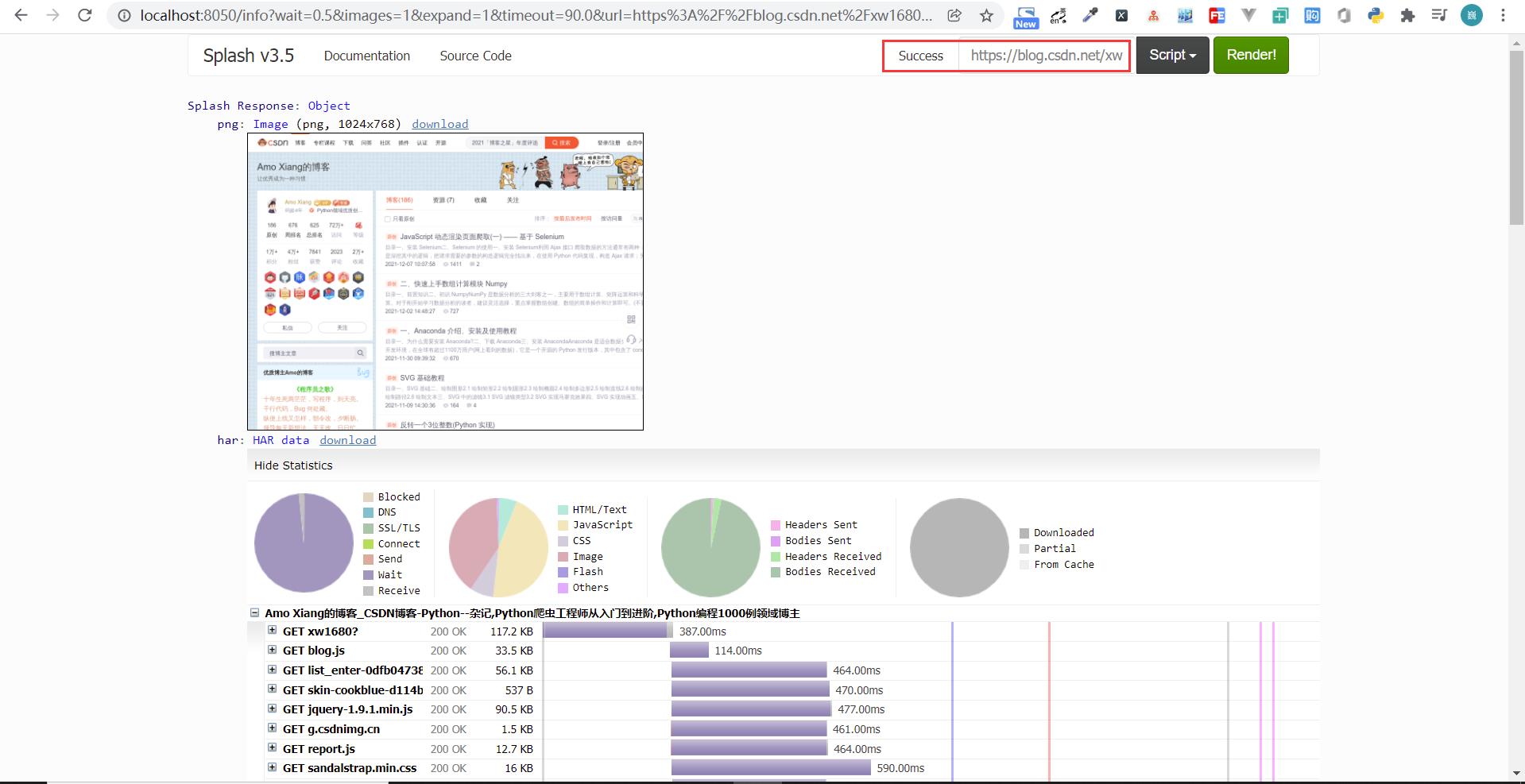
渲染结果中包含渲染截图、HAR 加载统计数据和网页的源代码。Splash 渲染了整个网页,包括 CSS、JavaScript 的加载等,最终呈现的页面和在浏览器中看到的是完全一致的。这段过程是由一段脚本控制的:
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(0.5))
return
html = splash:html(),
png = splash:png(),
har = splash:har(),
end
脚本是 Lua 语言写的,首先调用 go 方法加载页面,然后调用 wait 方法等待了一定时间,最后返回了页面的源代码、截图和 HAR 信息。通过上面简单例子,我们大体了解了 Splash 是通过 Lua 脚本控制页面的加载过程,加载过程完全模拟浏览器,最后可返回各种格式的结果,如网页源码和截图等。下面,具体来了解一下 Lua 脚本的写法以及相关 API 的用法。
2、入口及返回值:
基本实例:
function main(splash, args)
splash:go("https://blog.csdn.net/xw1680?")
splash:wait(0.5)
local title = splash:evaljs("document.title")
return title=title
end
将这段代码粘贴到下图所示的代码编辑区域,然后单击 Render me! 按钮
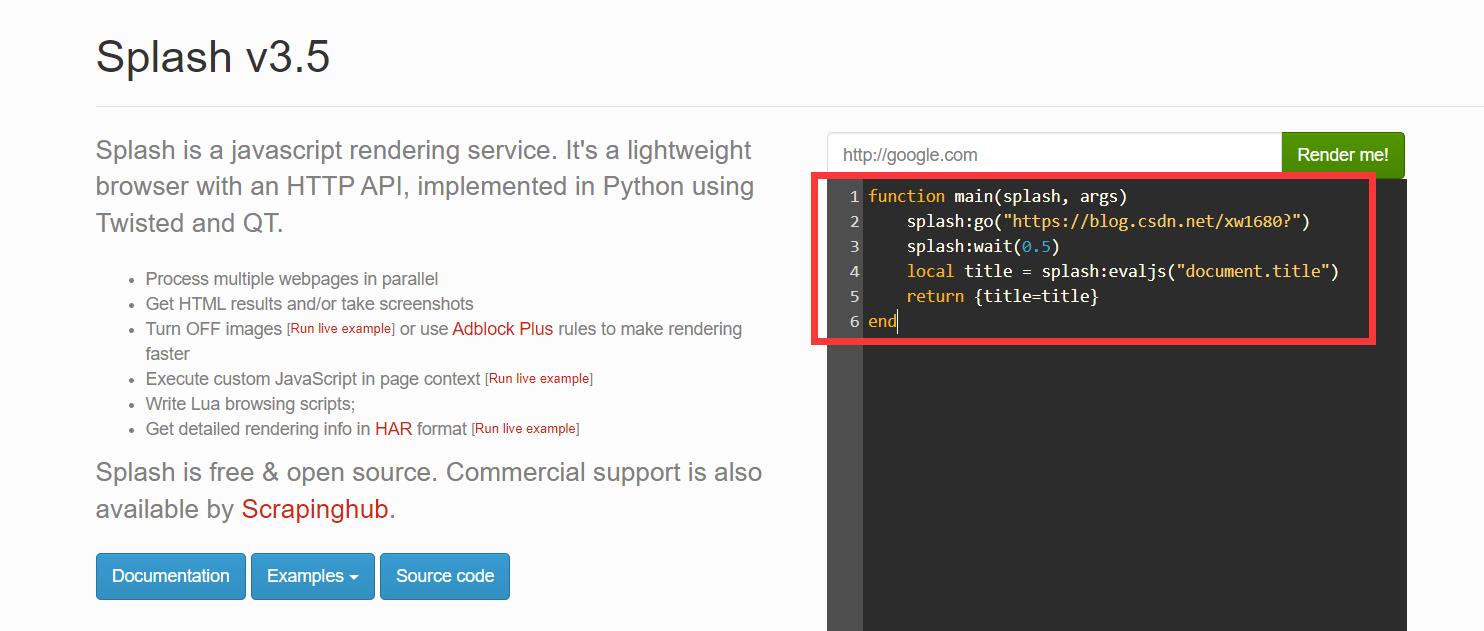
返回结果如下图所示:

渲染结果包含网页的标题。通过 evaljs 方法传入了 JavaScript 脚本,而 document.title 返回的就是网页的标题,evaljs 方法执行完毕后将标题赋值给 title 变量,随后将其返回。注意:main 方法是固定的,Splash 默认会调用该方法。main 方法的返回值既可以是字典形式,也可以是字符串形式,最后都会转换为 Splash 的 HTTP 响应,例如:
function main(splash)
-- 字典形式
return hello="amoxiang!"
end
-- 字符串形式
function main(splash)
return 'amoxiang'
end
Splash 支持异步处理,但是并没有显示地指明回调方法,其回调的跳转是在内部完成的。示例如下:
function main(splash, args)
local example_urls = "www.baidu.com","www.jd.com","www.taobao.com"
local urls = args.urls or example_urls
local results =
for index, url in ipairs(urls) do
-- .. 这里就算不懂lua语法,也大概能猜到是拼接的意思
local ok, reason = splash:go("http://" .. url)
-- ok表示状态
if ok then
--wait()方法类似于Python中的sleep方法, 2为等待的秒数
--splash执行到这里时,会转而处理其他任务,在等待参数指定的时间后再回来继续处理。
splash:wait(2)
results[url] = splash:png()
end
end
return results
end
运行代码后返回 3 个网站的页面截图,如下图所示:
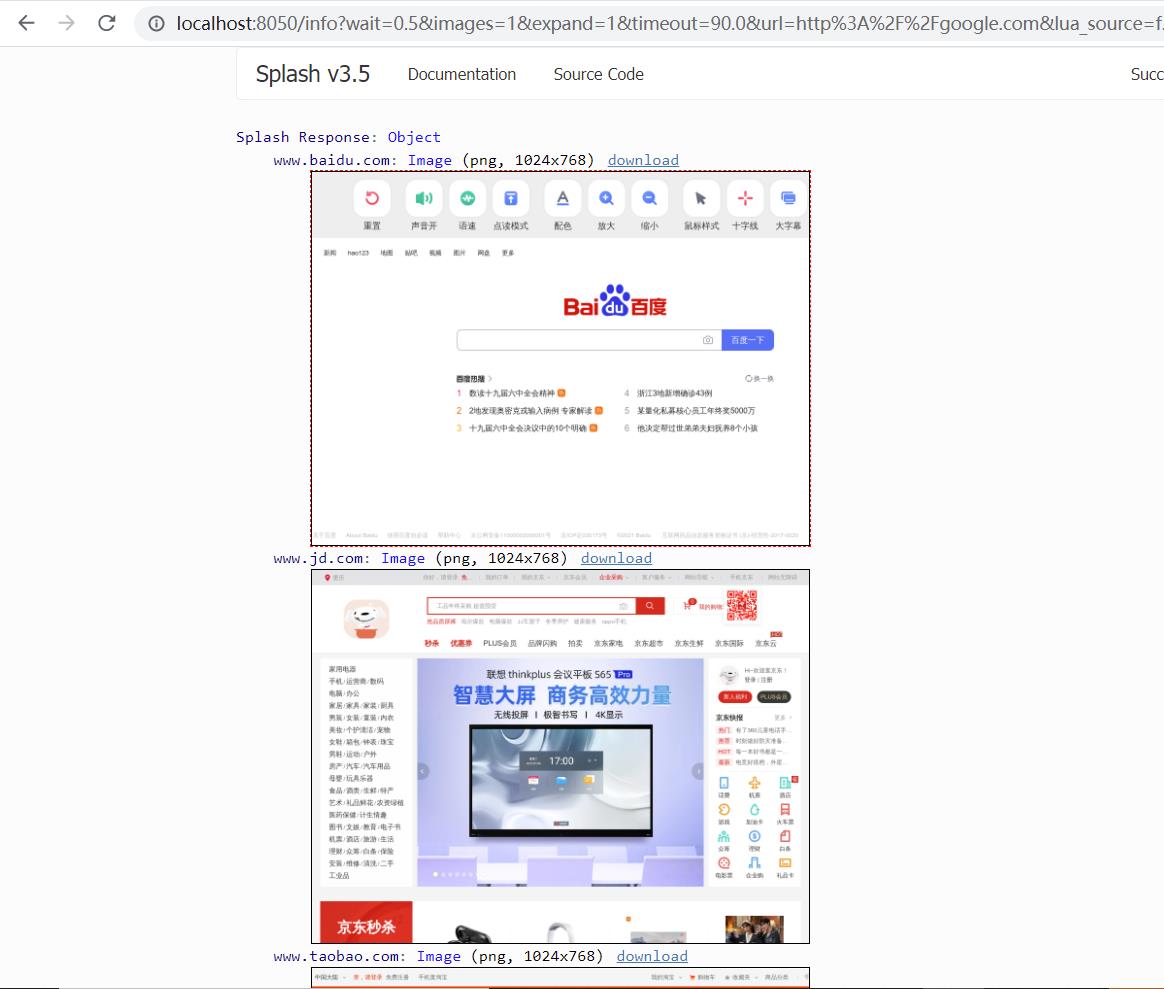
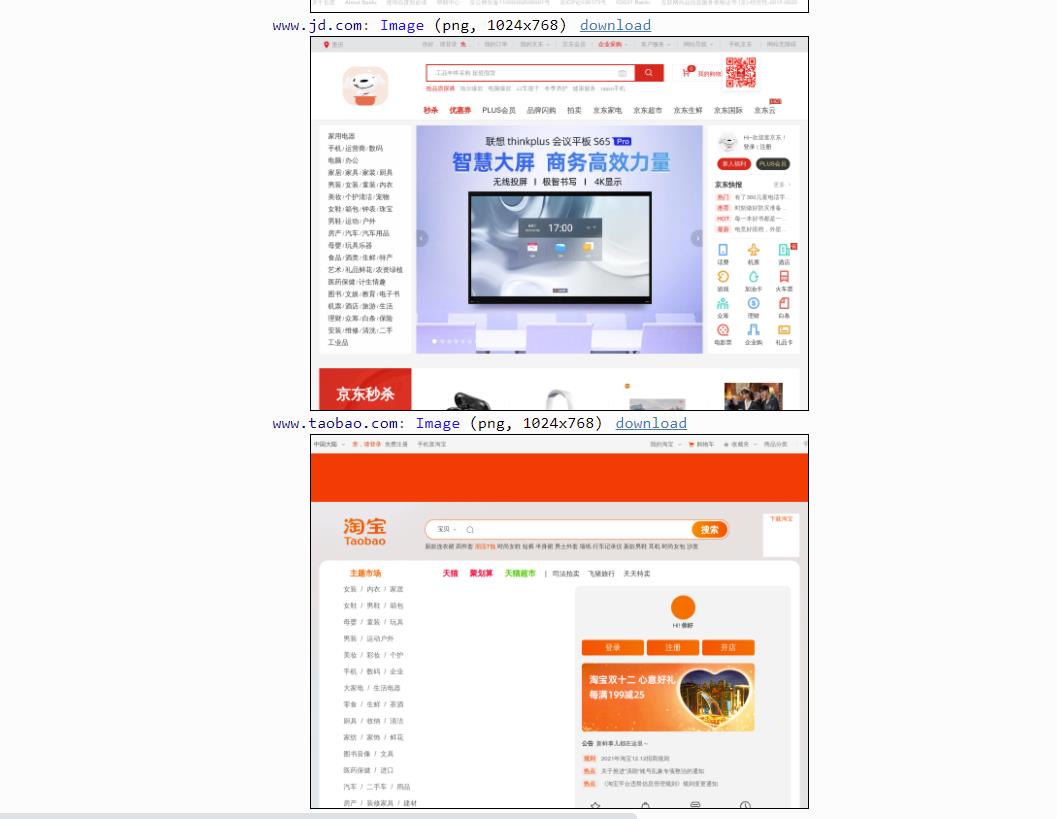
3、splash 对象的属性:
main() 方法中的第一个参数是 splash,类似于 Selenium 中的 WebDriver 对象,我们可以调用它的一些属性和方法来控制加载过程。
args 属性: 获取页面加载时配置的参数,例如请求的地址(URL)。对于 GET 请求,args 属性还可以用于获取 GET 请求的参数;对于 POST 请求,args 属性还可以用于获取表单提交的数据。此外,Splash 支持将 main() 方法的第二个参数直接设置为 args,例如:
function main(splash, args)
-- local url = splash.args.url
local url = args.url
end
js_enabled 属性: Splash 执行 JavaScript 代码的开关,默认是 true,对其进行设置 true 或 false 可以控制是否执行 JavaScript 代码:
function main(splash, args)
splash:go("https://blog.csdn.net/xw1680?")
splash.js_enabled = false -- 禁止执行 js
splash:wait(0.5)
local title = splash:evaljs("document.title")
return title=title
end
当我们禁止执行 JavaScript 代码后,重新调用 evaljs 方法执行了 JavaScript 代码,此时运行这段代码,会抛出异常,如下图所示:
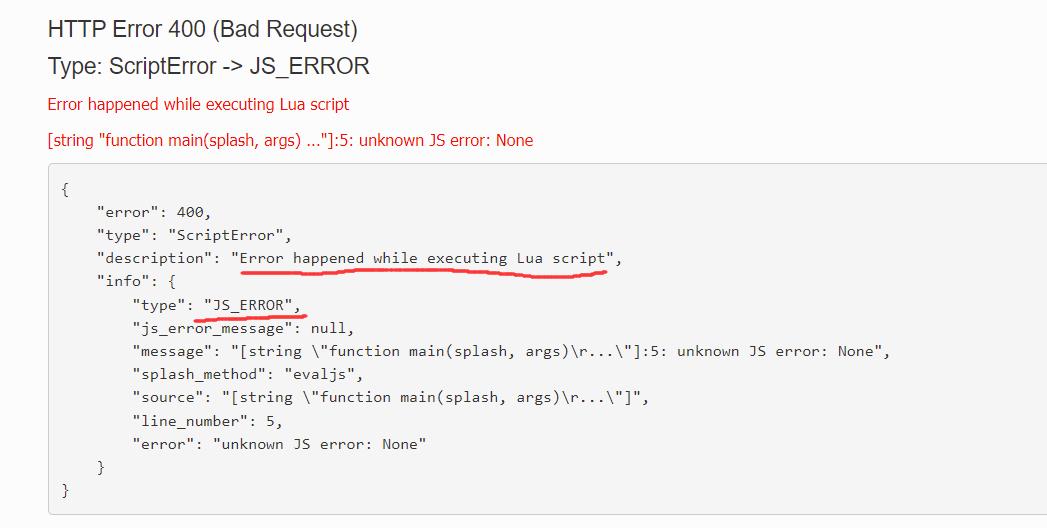
一般不设置此属性,默认开启。
resource_timeout 属性:用于设置页面加载的超时时间,单位为秒。如果设置为 0 或 nil(类似 Python 中的 None),代表不检测超时。示例代码如下:
function main(splash)
splash.resource_timeout = 0.1 --设置超时时间为0.1秒 在0.1秒内没有响应,即抛出异常
splash:go("https://blog.csdn.net/xw1680?")
return splash:png()
end
此属性适合在页面加载速度较慢的情况下设置。如果超过某个时间后页面依然无响应,则直接抛出异常并忽略。
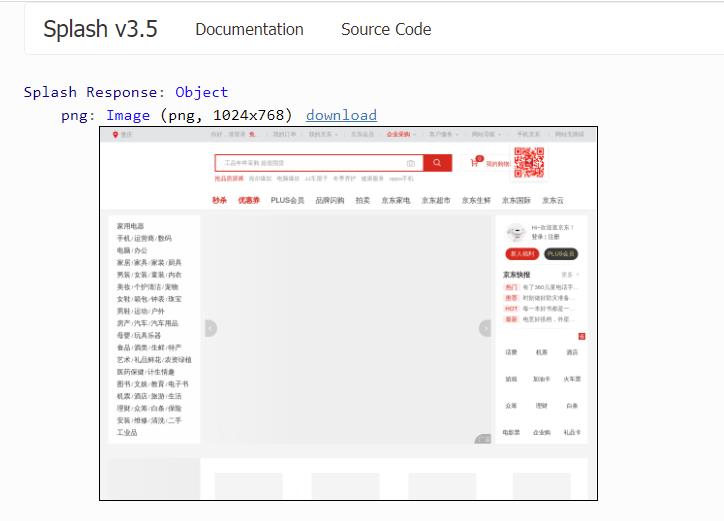
images_enabled 属性: 用于设置是否加载图片,默认是加载。禁用该属性可以节省网络流量并提高网页加载速度。但是:禁用图片加载可能会影响 JavaScript 渲染。因为禁用图片后,外层 DOM 节点的高度会受影响,进而影响 DOM 节点的位置。因此,如果 JavaScript 对图片节点有操作的话,其执行就会受到影响。另外:Splash 使用了缓存。如果一开始加载出来了网页图片,然后禁用了图片加载, 再重新加载页面,之前加载好的图片可能还会显示出来,这时直接重启 Splash 即可。禁用 images_enabled 属性示例代码如下:
function main(splash)
splash.images_enabled = false
splash:go("https://www.jd.com/")
return png=splash:png()
end
这样返回的页面截图不会带有任何图片,加载速度也会快很多,如下图所示:
splash.plugins_enabled 属性: 可以控制浏览器插件(如 Flash 插件) 是否开启。默认情况下,此属性是 false,表示不开启。可以使用如下代码控制其开启和关闭 plugins_enabled:
splash.plugins_enabled = true/false
scroll_position 属性: 控制页面上下滚动或左右滚动,是一个比较常用的属性。示例如下:
function main(splash)
splash:go("https://www.jd.com/")
splash.scroll_position = y=600
return png=splash:png()
end
控制页面向下滚动 600 像素值,运行结果如下图所示:
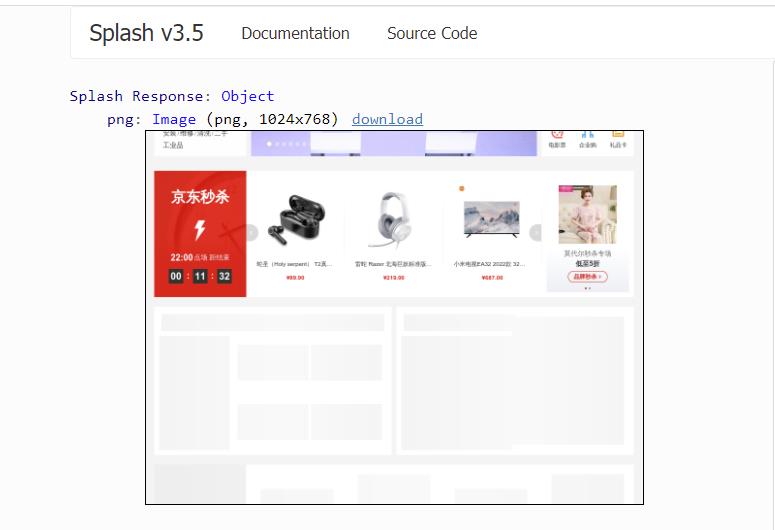
如果要让页面左右滚动,可以传入 x 参数,代码如下:
splash.scroll_position = x=100, y=200
4、splash 对象的方法:
go 方法: 用来请求某个链接,可以模拟 GET 和 POST 请求,同时支持传入请求头、表单等数据,用法如下:
ok, reason = spalsh:gourl, baseurl=nil,headers=nil,http_method="GET",body=nil,formdata=nil
-- 参数说明:
--1.url:请求的URL
--2.baseurl:可选参数, 默认为空, 表示资源加载的相对路径。
--3.headers:可选参数, 默认为空, 表示请求头
--4.http_method:可选参数, 默认为GET,同时支持 POST
--5.body:http_method 为POST时的表单数据,使用的 Content-type 为 application/json, 是可选参数,默认为空。
--6.formdata:http_method 为POST时的表单数据,使用的Content-type为application/x-www-form-urlencoded
--是可选参数, 默认为空。
该方法的返回值是 ok 变量和 reason 变量的组合,如果 ok 为空,代表页面加载出现了错误,reason 中包含错误的原因,否则代表页面加载成功。示例代码如下:
function main(splash)
local ok, reason = splash:go"http://www.httpbin.org/post", http_method="POST", body="name=AmoXiang"
if ok then
return splash.html()
end
end
这里模拟了 POST 请求,并传入了 POST 的表单数据,如果页面加载成功,则返回页面的源代码。运行结果如下图所示:
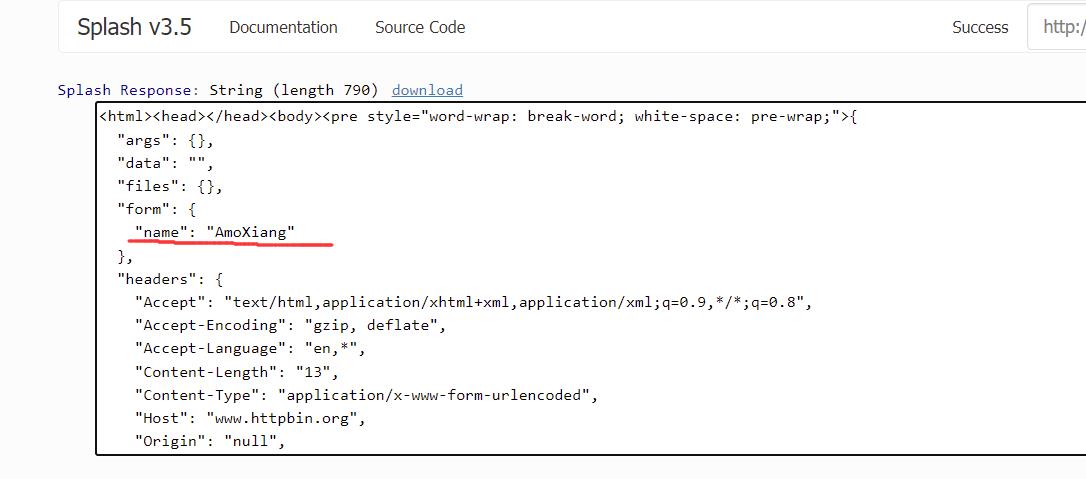
可以看到,成功实现了 POST 请求并发送了表单数据。
wait() 方法: 用于控制页面等待时间,语法如下:
ok, reason = splash:waittime,cancel_on_redirect=false,cancel_on_error=true
--参数说明如下:
--1.time:等待的时间,单位为秒。
--2.cancel_on_redirect:表示如果发生了重定向就停止等待,并返回重定向结果。可选参数,默认为false,
--3.cancel_on_error:如果页面加载错误就停止等待, 可选参数,默认为false。
其返回值同样是 ok 变量和 reason 变量的组合。示例代码如下:
function main(splash)
splash:go"https://blog.csdn.net/xw1680"
splash:wait(2)
return html=splash.html()
end
执行上面的代码,可以访问笔者博客主页并等待2秒,随后返回页面源代码,如下图所示:
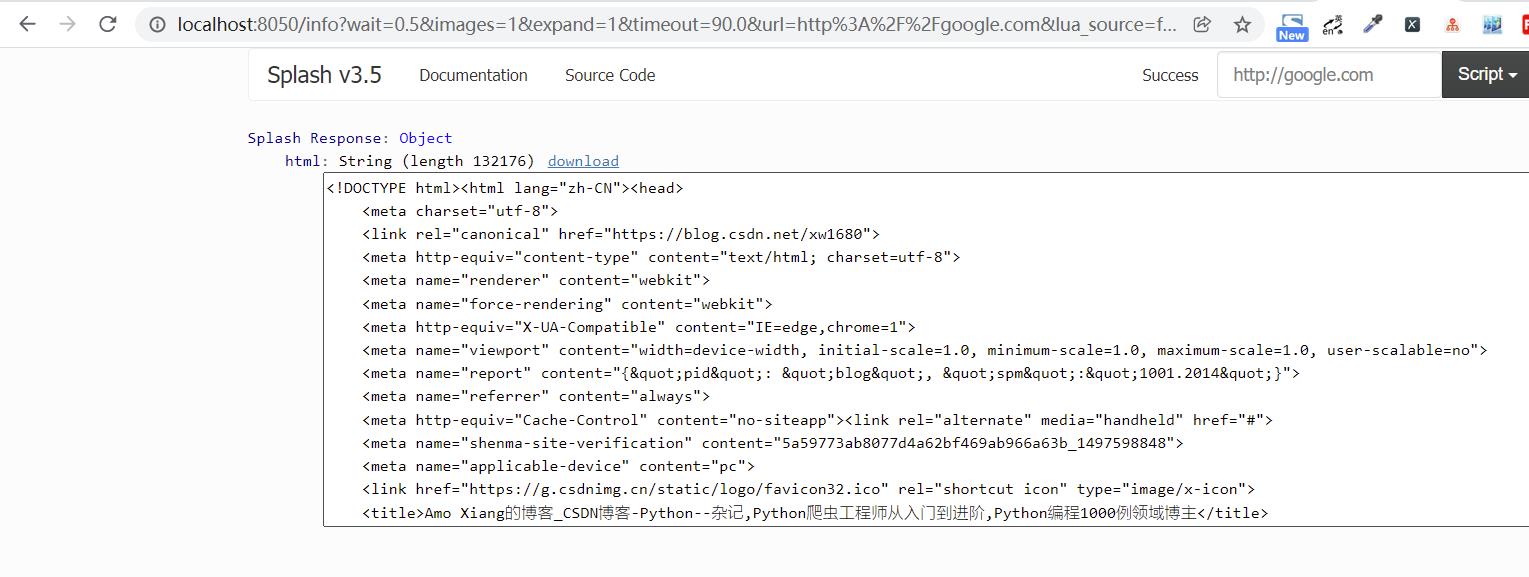
jsfunc 方法: 可以直接调用 JavaScript 定义的方法,但是需要用双中括号把调用的方法包起来,相当于实现了 JavaScript 方法到 Lua 脚本的转换。示例代码如下:
function main(splash, args)
local get_span_count = splash:jsfunc([[function ()
let body = document.body;
const spanList = body.getElementsByTagName("span");
return spanList.length;
]])
splash:go"https://blog.csdn.net/xw1680"
return ("There are % s SPAN"):format(get_span_count())
end
首先,声明了一个 JavaScript 定义的方法,然后在页面加载成功后调用此方法计算出页面中 span 节点的个数。关于 JavaScript 到 Lua 脚本的更多转换细节,参考官方文档: https://splash.readthedocs.io/en/stable/scripting-ref.html#splash-jsfunc
evaljs(): 此方法用于执行 JavaScript 代码并返回最后一条 JavaScript 语句的返回结果,其用法如下:
result = splash:evaljs(js)
例如,可以用下面的代码获取页面标题:
local title = splash:evaljs("document.title")
runjs() 方法: 可以执行 JavaScript 代码,它的功能与 evaljs() 方法的功能类似,但是更偏向于执行某些动作或声明某些方法。例如:
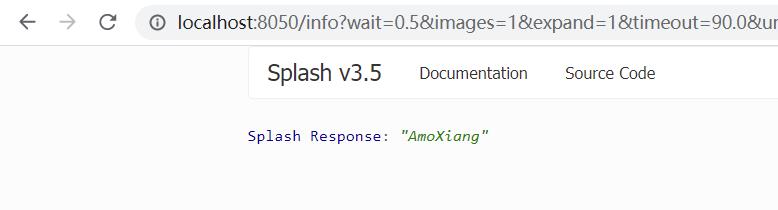
function main(splash, args)
splash:go"https://blog.csdn.net/xw1680"
splash:runjs("person = function() return 'AmoXiang'")
local result = splash:evaljs("person()")
return result
end
这里先用 runjs 方法声明了一个 JavaScript 方法 foo,然后通过 evaljs 方法调用 foo 方法得到的结果,如下图所示:
html 方法:用于获取页面的源代码,是一个非常简单且常用的方法,示例代码如下:
function main(splash, args)
splash:go("https://www.httpbin.org/get")
return splash:html()
end
运行结果如下:
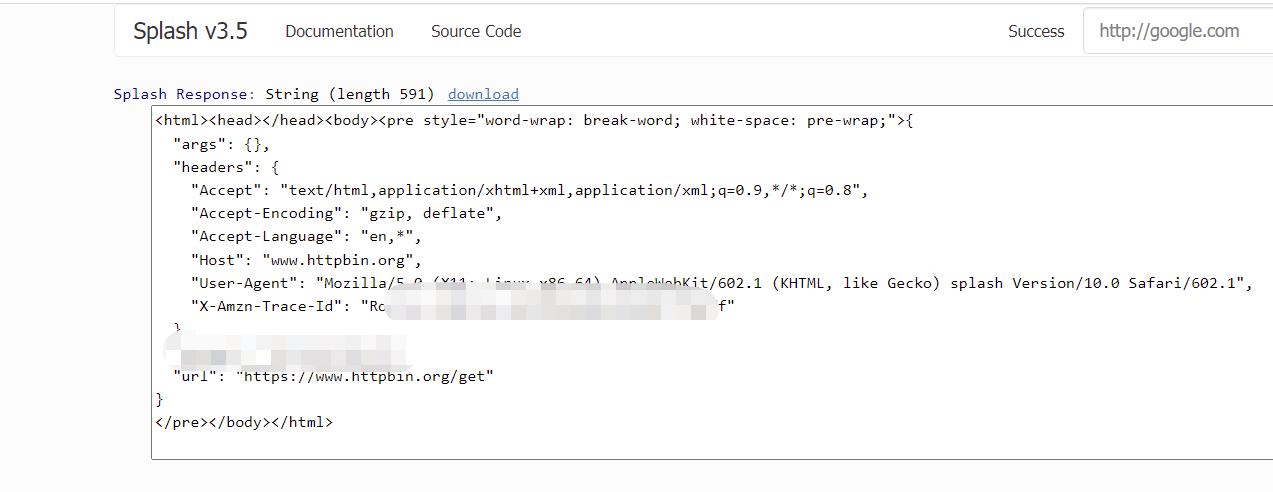
png 方法: 此方法用于获取 PNG 格式的页面截图,示例如下:
function main(splash, args)
splash:go("https://blog.csdn.net/xw1680/")
return splash:png()
end
jpeg 方法: 获取 JPEG 格式的页面截图,示例如下:
function main(splash, args)
splash:go("https://blog.csdn.net/xw1680/")
return splash:jpeg()
end
har 方法: 获取页面加载过程的描述信息,示例如下:
function main(splash, args)
splash:go("https://blog.csdn.net/xw1680/")
return splash:har()
end
运行结果如下图所示:
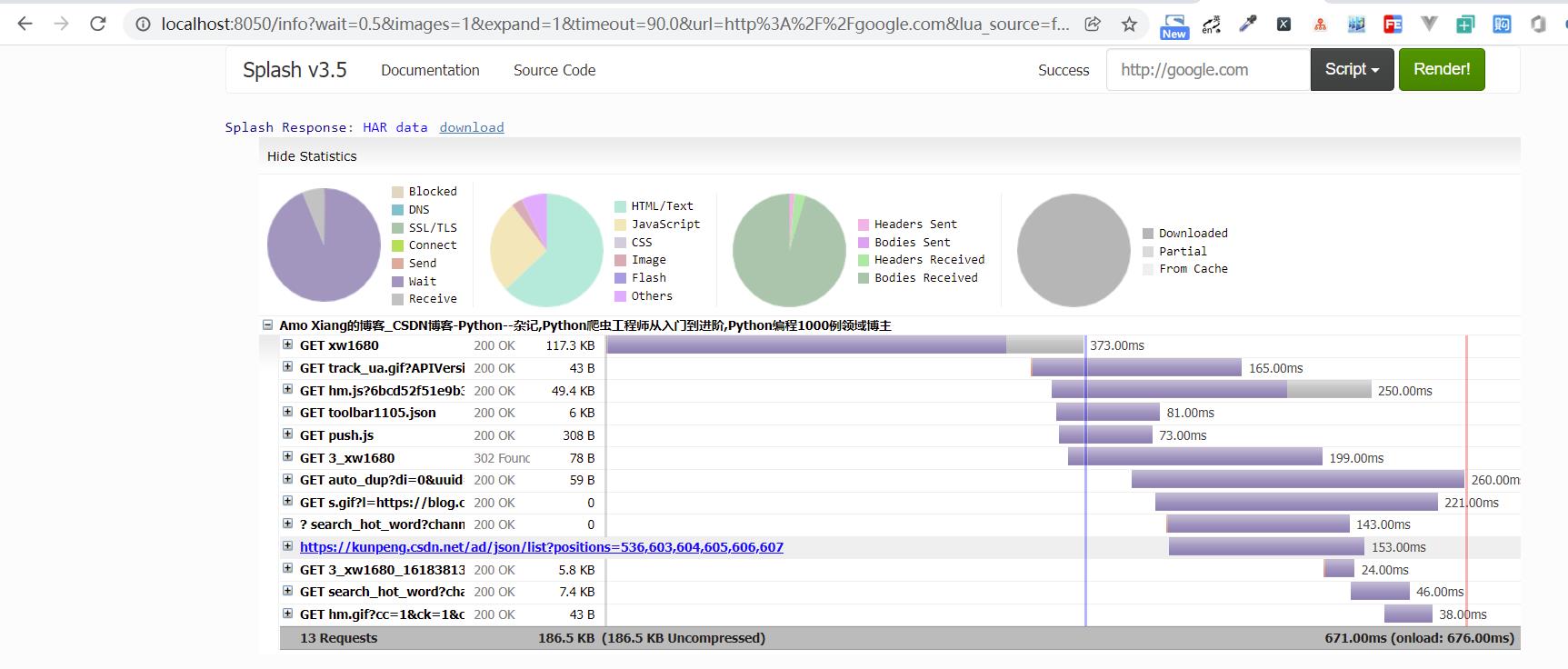
这张图里显示了博客页面加载过程中的每个请求记录的详情。
url 方法: 获取当前正在访问的 URL,示例如下:
function main(splash, args)
splash:go("https://blog.csdn.net/xw1680/")
return splash:url()
end
运行结果如下图所示:
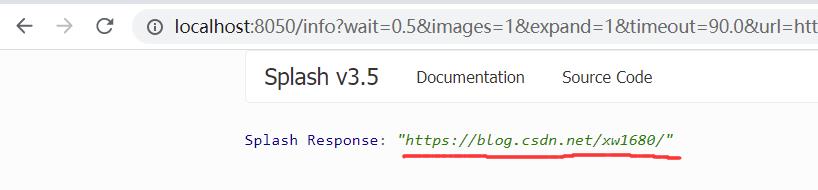
set_user_agent 方法: 设置浏览器的 User-Agent,示例如下:
function main(splash)
splash:set_user_agent('Splash')
splash:go("http://httpbin.org/get")
return splash:html()
end
这里我们将浏览器的 User-Agent 属性设置为了 Splash, 运行结果如下图所示:
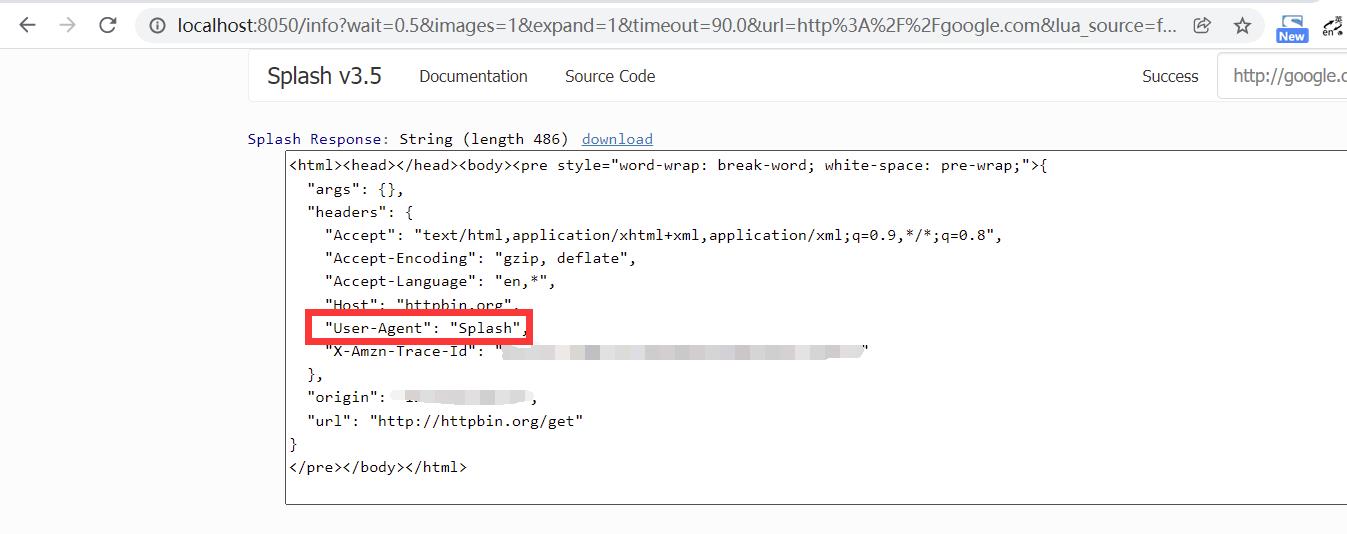
可以看到,设置的 User-Agent 属性值生效了。
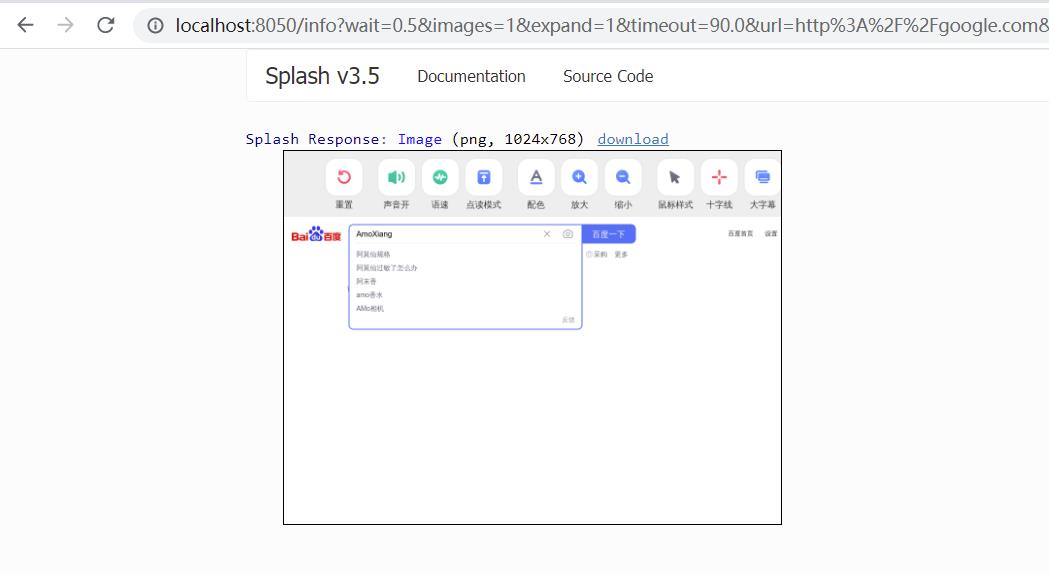
select() 方法: 选中符合条件的第一个节点,如果有多个节点符合条件只会返回一个,其参数是 css 选择器。示例代码如下:
function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('AmoXiang')
splash:wait(3)
return splash:png()
end
先访问百度官网,然后用 select 方法选中搜索框,随后调用 send_text 方法填写了文本,最后返回网页截图。运行结果如下图所示:
select_all() 方法: 选中所有符合条件的节点,其参数是 CSS 选择器。示例:
function main(splash)
local treat = require('treat')
assert(splash:go("http://quotes.toscrape.com/"))
assert(splash:wait(0.5))
local texts = splash:select_all('.quote .text')
local results =
for index, text in ipairs(texts) do
results[index] = text.node.innerHTML
end
return treat.as_array(results)
end
运行结果如下:

可以发现,成功获取了10个节点的正文内容。
mouse_click() 方法: 可以模拟鼠标点击操作,传入的参数为坐标值 x 和 y。也可以直接选中某个节点直接调用此方法,示例如下:
function main(splash)
splash:go("https://www.baidu.com")
input = splash:select("#kw")
input:send_text('Splash')
splash:wait(3)
submit = splash:select('#su')
submit:mouse_click()
splash:wait(5)
return splash:png()
end
首先选中页面的输入框,输入文本 Splash,然后选中提交按钮,调用了 mouse_click() 方法提交查询,之后等待5秒,就会返回页面截图,如下图所示:
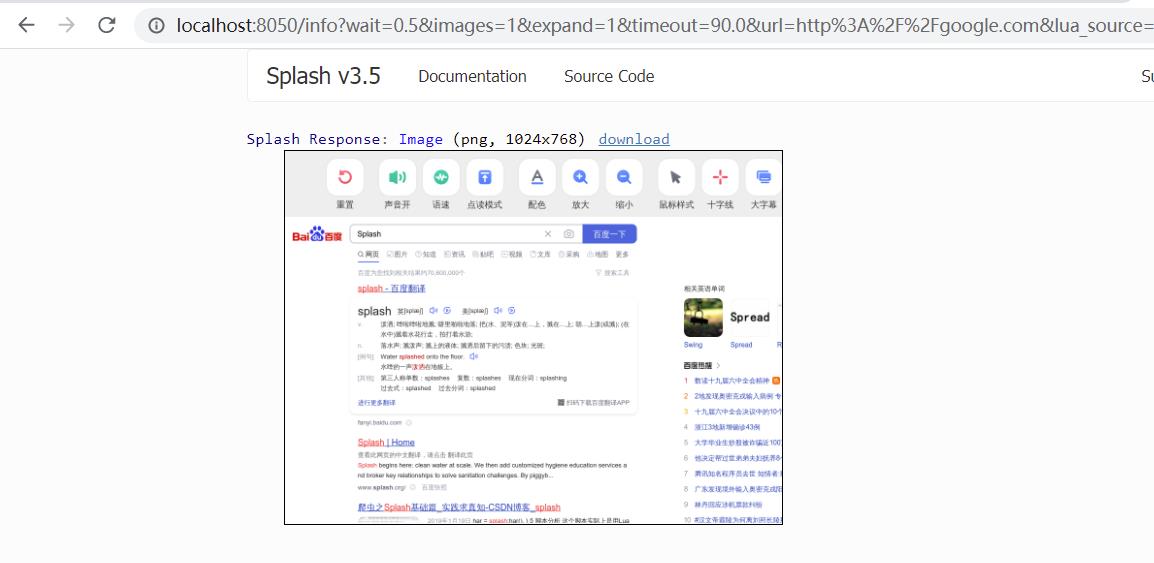
可以看到,成功获取了查询后的页面内容,模拟了百度搜索操作。至此,splash 对象的常用方法介绍完毕,还有一些方法这里就不逐一进行介绍了,如:获取 cookie 等,更加详细和权威的说明可以参见官方文档:https://splash.readthedocs.io/en/stable/scripting-ref.html,此页面介绍了 splash 对象的所有方法。另外,还有针对页面元素的方法,见官方文档:
https://splash.readthedocs.io/en/stable/scripting-element-object.html
5、调用 Splash 提供的 API:
前面简单介绍了 Splash Lua 脚本的用法,但这些脚本是在 Splash 页面里运行测试的,如何才能利用 Splash 渲染页面?Splash 怎样才能和 Python 程序结合使用并爬取 JavaScript 渲染的页面?其实,Splash 给我们提供了一些 HTTP API,我们只需要请求这些 API 并传递相应的参数即可获取页面渲染后的结果,下面介绍开始学习 API。
render.html: 获取 JavaScript 渲染的页面的 HTML 代码,API 地址是 Splash 的运行地址加上此 API 的名称,例如:http://localhost:8050/render.html,用 curl 工具测试一下,如下图所示:
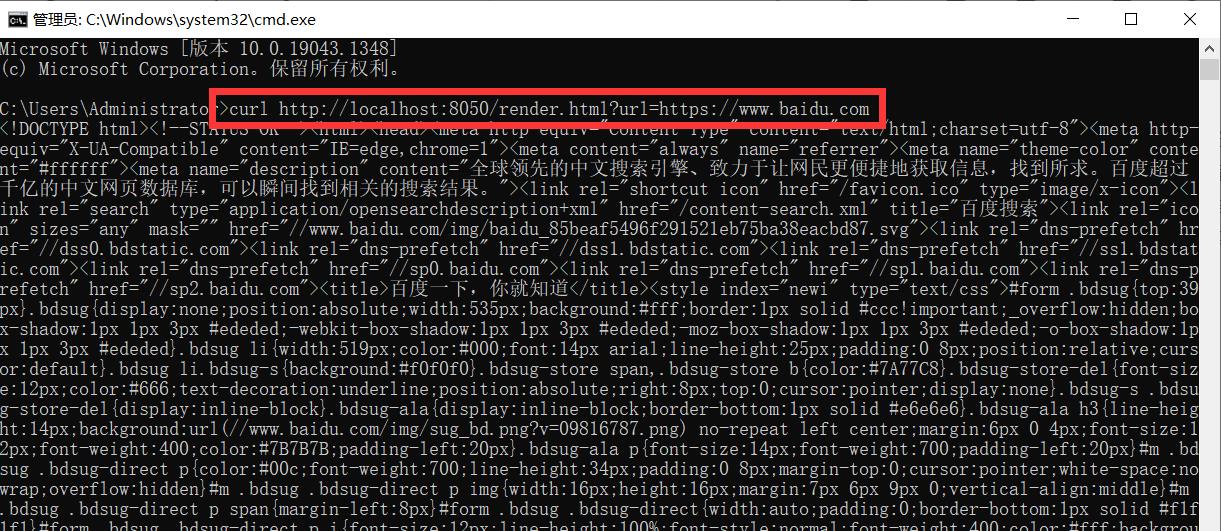
此处给 API 传递了一个 url 参数,以指定渲染的 URL,返回结果即为页面渲染后的源代码。用 Python 实现的代码如下:
# -*- coding: utf-8 -*-
# @Time : 2021/12/15 22:41
# @Author : AmoXiang
# @FileName: demo1.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import requests
url = "http://localhost:8050/render.html?url=https://www.baidu.com"
response = requests.get(url)
print(response.text)
这样就可以成功输出百度页面渲染后的源代码了。此 API 还有其他参数,例如:wait,用来指定等待秒数。如果要确保页面完全加载出来,就可以设置此参数,例如:
# -*- coding: utf-8 -*-
# @Time : 2021/12/15 22:41
# @Author : AmoXiang
# @FileName: demo1.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import requests
url = "http://localhost:8050/render.html?url=https://www.jd.com&wait=5"
response = requests.get(url)
print(response.text)
增加等待时间后,得到响应的时间会相应变长,如这里我们等待大约5秒钟才能获取 JavaScript 渲染后的京东页面源代码。另外,此 API 还支持代理设置、图片加载设置、请求头设置和请求方法设置,具体的用法可以参见官方文档:https://splash.readthedocs.io/en/stable/api.html#render-html
render.png: 用于获取页面截图,其参数比 render.html 要多几个,例如 width 和 height 用来控制截图的宽和高,返回值是 PNG 格式图片的二进制数据。示例如下:
# -*- coding: utf-8 -*-
# @Time : 2021/12/15 22:51
# @Author : AmoXiang
# @FileName: demo2.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import requests
url = "http://localhost:8050/render.png?url=https://www.jd.com&wait=5&width=1000&height=700"
response = requests.get(url)
with open("jd.png", "wb") as file:
file.write(response.content)
得到的图片如下图所示:

这样就成功获取了京东首页渲染完成后的页面截图,详细的参数设置可以参考官网文档:https://splash.readthedocs.io/en/stable/api.html#render-png
render.jpeg: 此 API 和 render.png 类似,不过它返回的是 JPEG 格式图片的二进制数据。另外,此 API 比 render.png 多一个参数 quality,该参数可以设置图片质量。https://splash.readthedocs.io/en/stable/api.html#render-jpeg
render.har: 此 API 用于获取页面加载的 HAR 数据,运行结果非常多,是一个 JSON 格式的数据,里面包含页面加载过程中的 HAR 数据。如下图所示:
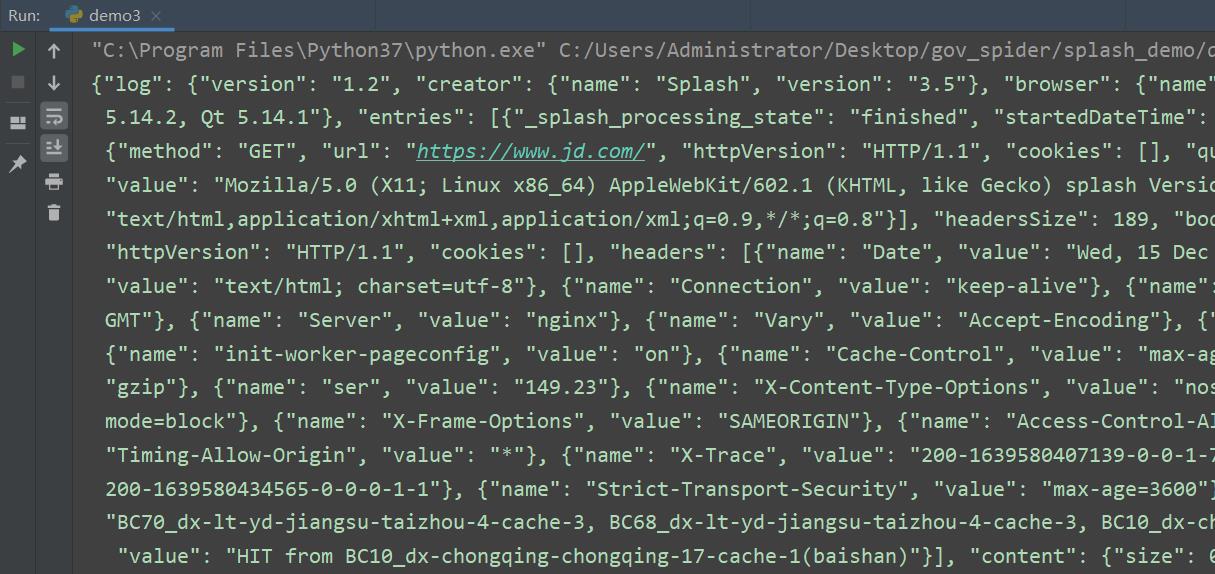
render.json: 此 API 包含前面介绍的所有 render 相关的 API 的功能,返回值是 JSON 格式的数据,我们可以通过传入不同的参数控制返回结果,例如:传入 html=1,返回结果会增加页面源代码;传入 png=1,返回结果会增加 PNG 格式的页面截图;传入 har=1,返回结果会增加页面的 HAR 数据。参考官方文档:https://splash.readthedocs.io/en/stable/api.html#render-json
execute: 此 API 才是最为强大的 API。之前介绍了很多关于 Splash Lua 脚本的操作,用此 API 即可实现与 Lua 脚本的对接。要爬取一般的 JavaScript 渲染页面,使用前面的 render.html 和 render.png 等 API 就足够了,但如果要实现一些交互操作,这些 API 还是心有余而力不足,就需要使用 execute 了。实现一个最简单的脚本:
# -*- coding: utf-8 -*-
# @Time : 2021/12/15 22:59
# @Author : AmoXiang
# @FileName: demo3.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import requests
from urllib.parse import quote
lua = """
function main(splash)
return 'hello splash'
end
"""
url = "http://localhost:8050/execute?lua_source=" + quote(lua)
response = requests.get(url)
print(response.text)
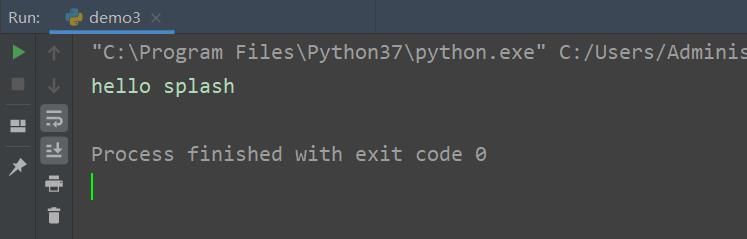
运行结果如下:
实例:
# -*- coding: utf-8 -*-
# @Time : 2021/12/15 23:15
# @Author : AmoXiang
# @FileName: demo4.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import requests
from urllib.parse import quote
lua = """
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://www.httpbin.org/get")
return 以上是关于JavaScript 动态渲染页面爬取 —— 基于 Splash的主要内容,如果未能解决你的问题,请参考以下文章
JavaScript 动态渲染页面爬取 —— 基于 Selenium
JavaScript 动态渲染页面爬取 —— 基于 Selenium