JavaScript 动态渲染页面爬取 —— 基于 Selenium
Posted Amo Xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript 动态渲染页面爬取 —— 基于 Selenium相关的知识,希望对你有一定的参考价值。
一、安装 Selenium
利用 Ajax 接口 爬取数据的方法通常有两种:
- 一种是深挖其中的逻辑,把请求需要的参数的构造逻辑完全找出来,在使用 Python 代码复现,构造 Ajax 请求;
- 另一种是直接模拟浏览器的运行,绕过这个过程,因为在浏览器里是可以看到这个数据的,所以如果能把看到的数据直接爬取下来,当然就能获取对应的信息了。
两种方式各有优劣,具体采用哪一种,需要根据实际情况进行分析。举个简单例子:如果你的工作时间紧任务重,老板数据要得着急,网站请求参数构造的逻辑又相对复杂,我们可以采取第 2 种方式先拿到数据,性能什么的可以先暂时忽略。
题外话:就我个人而言,并不太喜欢使用 Selenium。如果所有数据都依赖于 Selenium 进行抓取,性能太低,提供的 API 也并不是太稳定,并且现在针对 Selenium 特征检测的网站也不少,但是 Selenium 做一些辅助操作是非常好的。
本文主要介绍第二种方法,模拟浏览器的运行,爬取数据。Selenium 是一个自动化测试工具,利用它可以驱动浏览器完成特定的操作,例如点击、下拉、拖动等,还可以获取浏览器当前呈现的页面的源代码,做到所见即所爬,对于一些 JavaScript 动态渲染的页面来说,这种爬取方式还是非常有效的。官方学习文档:https://selenium-python.readthedocs.io/installation.html
在开始使用 Selenium 之前,要满足下面 3 个条件:
(1) 确保你的电脑上已经正确安装好了浏览器。(建议:安装 Chrome 浏览器,后续博文也是以 Chrome 浏览器 讲解为主)。没有 Chrome 浏览器的读者,自行打开下面的百度网盘链接进行下载。
链接:https://pan.baidu.com/s/1FpM6lXNf4nUoEtJrQVKHnw
提取码:k2s2
--来自百度网盘超级会员V7的分享
(2) 正确安装好 Python 的 Selenium 库。命令如下:
pip/pip3 install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com selenium
(3) 安装一个 ChromeDriver。 不同平台安装的方式不太一样,这里以 Windows 和 MacOS 举例说明。
-
点击 Chrome 的菜单,帮助 ⇒ 关于 Chrome,即可查看 Chrome 的版本号,在这里我的版本是 96.0.4664.45,如图所示:

记住 Chrome 版本号,在后面选择 ChromeDriver 版本时需要用到。 -
下载 ChromeDriver。打开 ChromeDriver 的官方网站,链接为:https://sites.google.com/chromium.org/driver/downloads。官网打不开,参考下面其他下载地址进行下载:
下载地址:https://sites.google.com/a/chromium.org/chromedriver/(官网) 其他下载地址:https://chromedriver.storage.googleapis.com/index.html https://npm.taobao.org/mirrors/chromedriver/(自选一个)可以看到到目前为止最新支持的 Chrome 浏览器版本为 97,最新版本以官网为准,如图所示:
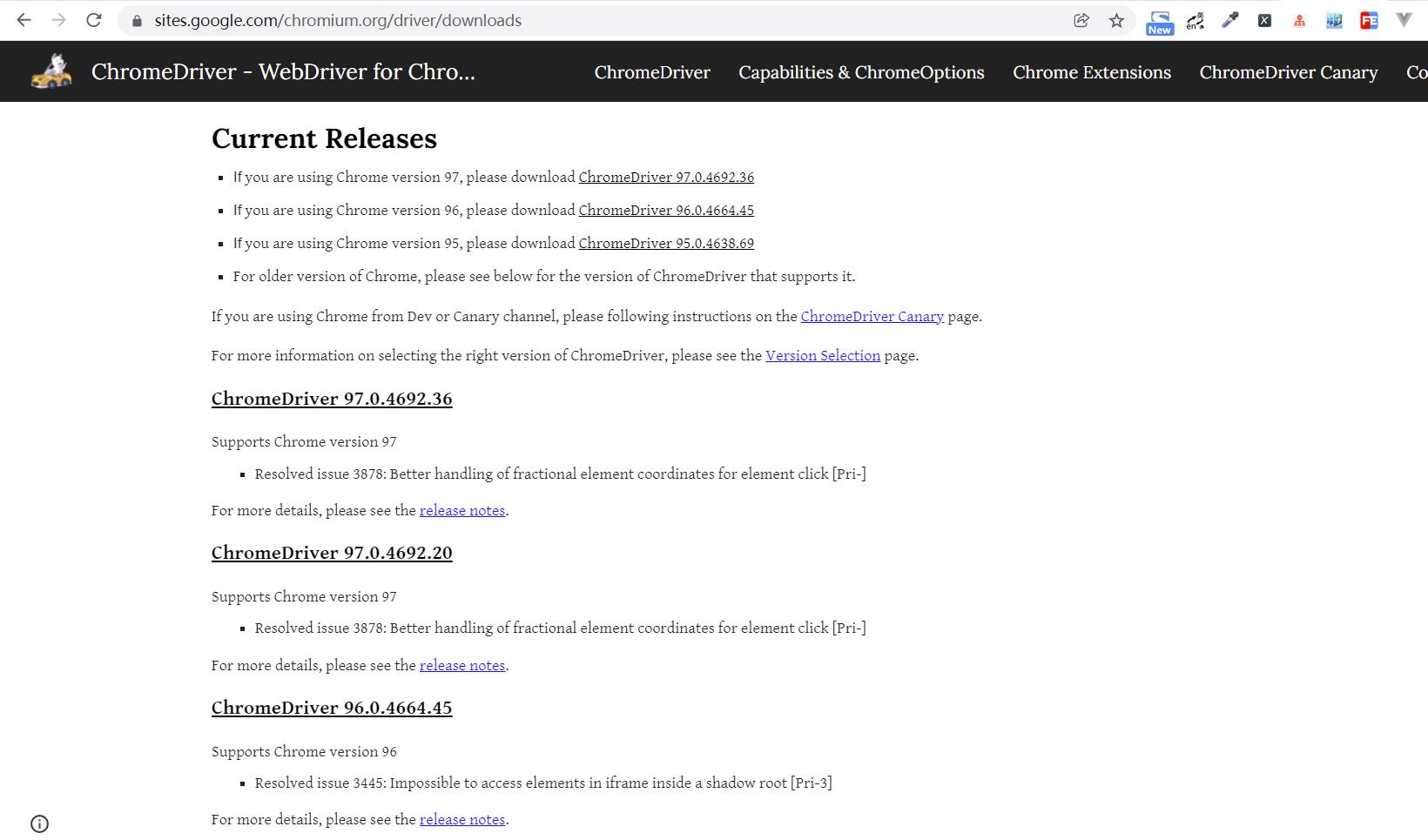
每个版本都有相应的支持 Chrome 版本介绍,请找好自己的 Chrome 浏览器版本对应的 ChromeDriver 版本再下载,否则可能导致无法正常工作。由于我这边的 ChromeDriver 版本是 96.0.4664.45,匹配方法:先是找第一个,96,一定要找到 然后找第二个,0,一定要找到 然后找第三个,4664,应该是有的 最后找第四个,45:有就最好,直接点击去就是了。没有的话也没关系,找和45最靠近的,点进去。找到对应的下载列表,如图所示:

Windows 系统就下载 win32.zip,Mac 系统 Intel 芯片 下载 mac64.zip,Mac 系统 M1 芯片 下载 mac64_m1.zip,Linux 系统下载 linux64.zip,下载解压之后会得到一个 ChromeDriver 的可执行文件。 -
下载完成后将 ChromeDriver 的可执行文件配置到环境变量下。在 Windows 下,建议直接将 chromedriver.exe 文件拖到 Python 的 Scripts 目录下,如图所示:

也可以单独将其所在路径配置到环境变量,环境变量的配置方法请自行解决。在 Linux、Mac 下,需要将可执行文件配置到环境变量或将文件移动到属于环境变量的目录里。例如移动文件到 /usr/bin 目录,首先命令行进入其所在路径,然后将其移动到 /usr/bin:sudo mv chromedriver /usr/bin 备注:某些 Mac 电脑可能会遇到权限问题当然也可以将 ChromeDriver 配置到 $PATH,首先可以将可执行文件放到某一目录,目录可以任意选择,例如将当前可执行文件放在 /usr/local/chromedriver 目录下,接下来可以修改 ~/.profile 文件,命令如下:
export PATH="$PATH:/usr/local/chromedriver" MacOS 推荐使用以下命令: cd Desktop sudo cp chromedriver /usr/local/bin/chromedriver Password: ls /usr/local/bin | grep chromedriver chromedriver保存然后执行:即可完成环境变量的添加。
source ~/.profile -
验证安装。配置完成之后,就可以在命令行下直接执行 chromedriver 命令了。命令行下输入:
chromedriver输入控制台有类似输出,如图所示:
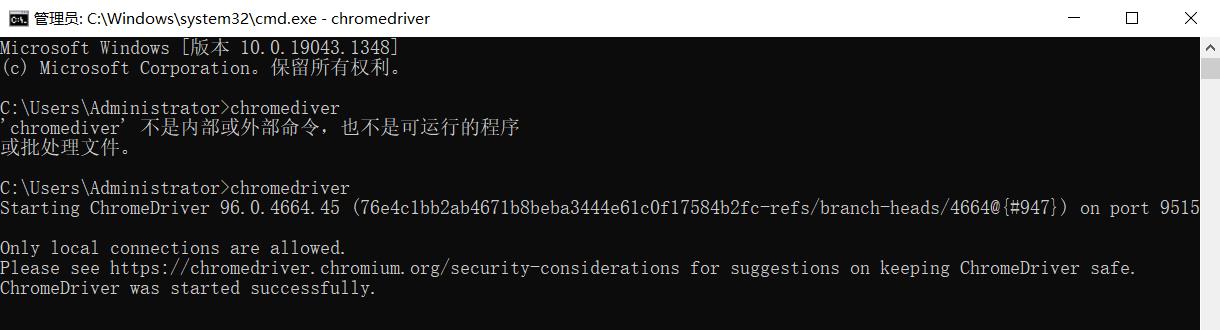
如果有类似输出则证明 ChromeDriver 的环境变量配置好了。随后再在程序中测试,执行如下 Python 代码:# -*- coding: utf-8 -*- # @Time : 2021/12/6 23:53 # @Author : AmoXiang # @FileName: selenium_test.py # @Software: PyCharm # @Blog :https://blog.csdn.net/xw1680? from selenium import webdriver browser = webdriver.Chrome()运行之后会弹出一个空白的 Chrome 浏览器,证明所有的配置都没有问题,如果没有弹出,请检查之前的每一步的配置。如果弹出之后闪退,则可能是 ChromeDriver 版本和 Chrome 版本不简容,请更换 ChromeDriver 版本。如果没有问题,接下来我们就可以开始使用 Selenium 来实现所见即所爬了。Linux 系统,大佬请自己处理。
二、Selenium 的使用
1、基本用法:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:16
# @Author : AmoXiang
# @FileName: demo1.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome() # 初始化浏览器对象并赋值给 browser
# webdriver.Firefox()
# webdriver.Edge()
# webdriver.Safari()
try:
# 向参数url传入要请求网页的URL即可
browser.get(url="https://www.baidu.com") # 使用get方法请求网页
_input = browser.find_element_by_id("kw") # 查找节点
# 等价 _input = browser.find_element(By.ID, "kw")
_input.send_keys("AmoXiang") # 输入文字
_input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_all_elements_located((By.ID, "content_left")))
print(browser.current_url) # 获取当前页面的url
print(browser.get_cookies()) # 获取cookie
print(browser.page_source) # 页面源码
finally:
browser.close()
2、查找节点:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:38
# @Author : AmoXiang
# @FileName: demo2.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
# ############## 查找单个节点 ###############
one = browser.find_element_by_id('list-data')
two = browser.find_element_by_css_selector('#list-data')
three = browser.find_element_by_xpath('//*[@id="list-data"]')
# 等价于下面这个方法
_one = browser.find_element(By.ID, 'list-data')
print(one, two, three, _one)
# ############## 查找多个节点 ###############
lis = browser.find_elements_by_css_selector()
# 等价于下面这个:
# browser.find_elements(By.CSS_SELECTOR, '#list-data li')
print(lis)
browser.close()
3、节点交互:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:52
# @Author : AmoXiang
# @FileName: demo3.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
input_ = browser.find_element_by_id('searchWord')
input_.send_keys('统计公报')
time.sleep(1)
input_.clear()
time.sleep(3)
input_.send_keys('决策预算')
button = browser.find_element_by_id('searchbtn')
button.click()
browser.close()
4、动作链:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:56
# @Author : AmoXiang
# @FileName: demo4.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable') # 获取拖拽的节点
target = browser.find_element_by_css_selector('#droppable') # 拖拽至目标节点
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
time.sleep(5)
browser.close()
5、运行 JavaScript:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:06
# @Author : AmoXiang
# @FileName: demo5.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
# 实际工作中,我们可能会计算每次拖动的距离
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
有了 execute_script() 方法,那些没有被提供 API 的功能几乎都可以用运行 javascript 的方式实现。
6、获取节点信息:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:10
# @Author : AmoXiang
# @FileName: demo6.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
browser = webdriver.Chrome()
url = 'http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml'
browser.get(url)
logo = browser.find_element_by_xpath('//a[@class="logo"]/img')
print(logo)
# 使用get_attribute()方法获取属性,传入想要获取的属性名即可
print(logo.get_attribute('src'))
# TODO 2.获取文本值
search_btn = browser.find_element_by_id("searchbtn")
print(search_btn.text)
# TODO 3.获取 ID、位置、标签名和大小
print(search_btn.id)
print(search_btn.location)
print(search_btn.tag_name)
print(search_btn.size)
7、切换 Frame:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:19
# @Author : AmoXiang
# @FileName: demo7.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
8、延时等待:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:22
# @Author : AmoXiang
# @FileName: demo8.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
# 隐式等待
# browser.implicitly_wait(10)
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
# input_ = browser.find_element_by_class_name('logo')
# print(input_)
# 显示等待
wait = WebDriverWait(browser, 10)
input_ = wait.until(EC.presence_of_element_located((By.ID, 'searchWord')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#searchbtn')))
print(input_, button)
9、前进和后退:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:37
# @Author : AmoXiang
# @FileName: demo9.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
time.sleep(2)
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list_2.shtml')
time.sleep(2)
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list_3.shtml')
time.sleep(2)
browser.back()
time.sleep(3)
browser.forward()
time.sleep(3)
browser.close()
10、Cookie:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
print(browser.get_cookies())
browser.add_cookie('name': 'name',
'value': 'jd', 'domain': 'www.jd.com')
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies()) # 大部分删除了,可能还剩下一些
11、选项卡管理:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:42
# @Author : AmoXiang
# @FileName: demo10.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) # 获取当前开启的所有选项卡
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')
12、反屏蔽:
现在有很多网站增加了对 Selenium 的检测,大多数情况下,检测的基本原理是检测当前浏览器窗口下的 window.navigator 对象中是否包含 webdriver 属性。 正常使用浏览器时,这个属性为 undefined,一旦使用了 Selenium,它就会给 window.navigator 对象设置 webdriver 属性。很多网站通过 JavaScript 语句判断是否存在 webdriver 属性,如果存在直接屏蔽。一个典型的案例网站:http://tjj.hubei.gov.cn/tjsj/tjgb/ndtjgb/sztjgb/,就是使用上述原理,检测是否存在 webdriver 属性,如果我们使用 Selenium 直接抓取该网站的数据,网站返回如下图所示的页面:
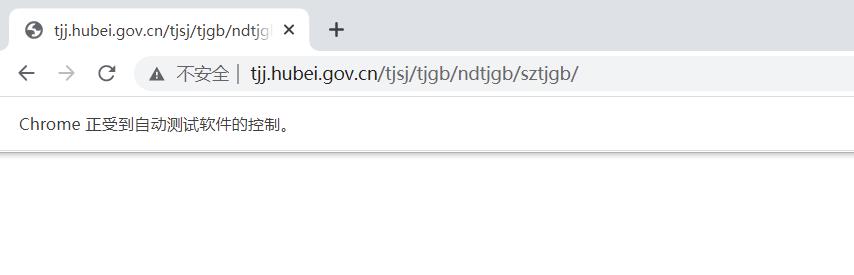
在 Selenium 中,可以用 CDP(即 Chrome Devtools Protocol, Chrome 开发工具协议) 解决这个问题,利用它可以实现在每个页面刚加载的时候就执行 JavaScript 语句,将 webdriver 属性 置空。这里执行的 CDP 方法 叫作 Page.addScriptToEvaluateOnNewDocument,将上面的 JavaScript 语句传入其中即可。另外,还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息,代码实现如下:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:53
# @Author : AmoXiang
# @FileName: demo11.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
'source': 'Object.defineProperty(navigator, "webdriver", get: () => undefined)'
)
browser.get('http://tjj.hubei.gov.cn/tjsj/tjgb/ndtjgb/sztjgb/')
这样就能加载整个页面了,如下图所示:

注意:在大多数时候,以上方法可以实现 Selenium 的反屏蔽。但也存在一些特殊网站会对 WebDriver 属性 设置更多的特征检测,这种情况下可能需要具体排查。
13、无头模式:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 2:10
# @Author : AmoXiang
# @FileName: demo12.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless') # 无头模式:一定程度上节省资源加载的时间和网络宽带
browser = webdriver.Chrome(options=option)
browser.set_window_size(1366, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('preview.png')
至此今天的案例就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习爬虫的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
以上是关于JavaScript 动态渲染页面爬取 —— 基于 Selenium的主要内容,如果未能解决你的问题,请参考以下文章