Hadoop2.7.7伪分布式环境搭建(保姆级教程)
Posted tangyi2008
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop2.7.7伪分布式环境搭建(保姆级教程)相关的知识,希望对你有一定的参考价值。
Hadoop2.7.7伪分布式配置详解
学习大数据的路上,肯定少不了Hadoop的陪伴。
在学习Hadoop之初,一件"痛苦"的事情莫过于装环境,没有环境,练不了HDFS命令,写不了MapReduce程序,后续的HBase、Hive无从下手。
为了学好Hadoop,于是下决心,一定把环境装好,于是,跟着老师做,跟着网上学,别人都顺理成章、一气呵成;而轮到自己时,总在怀疑自己的眼睛、自己的手、自己的电脑、自己的…
- 软件或者系统版本与老师不一致
- 没有完全跟着老师做,比如老师用的用户名是
user1, 而你总想取自己的名字zhangsan,结果在后面配置相应的目录时出错了 - 在安装的过程中漏掉了某些细节,比如老师随手切换了目录,而你还在原目录中,纠结为什么
ls出来的内容与老师的不同… - 失误导致的错,比如在格式化HDFS时,
hdfs namenode -format,而你写的是hdfs namenode-format,一个空格,敲出了两种境界 - …
对初学者的建议:掌握整体过程及每一步的作用,按部就班的操作,仔仔细细的核对。
本教程按如下顺序进行:
【资源准备】 => 【环境准备】 => 【JDK的安装】 => 【Hadoop的安装】 => 【伪分布式的配置】 => 【启动与测试】 => 【常见错误及解决办法】
零、资源准备
- 虚拟机相关:
- vmware:vmware_177981.zip
- ubuntu18-desktop:ubuntu-18.04.5-desktop-amd64.iso
- Hadoop相关
- jdk1.8:jdk-8u261-linux-x64.tar.gz
- hadoop2.7.7:hadoop-2.7.7.tar.gz
- 辅助工具
- putty:putty.exe
- winscp:WinSCP-5.19.5-Portable.zip
链接:https://pan.baidu.com/s/1kjcuNNCY2FxYA5o7Z2tgkQ
提取码:nuli
除了vmware(你懂的…),以上资源均来源于官网,putty和winscp都是便捷式软件,无需安装
一、环境准备
1. 安装虚拟机
本教程使用vmware安装ubuntu18.05系统
系统设置
CPU选择2核心;内存使用2-4G; 硬盘选择50G以上,动态分配
具体步骤可参考:
https://blog.csdn.net/tangyi2008/article/details/120311293
当然你可以选用其他的虚拟机,比如使用VBox作为虚拟机软件,同样,操作系统可以选CentOS等其他Linux系统。
如果是小白,建议严格按这里的步骤
2. 环境准备
1) 创建新用户test
为了避免不必要的麻烦,这里统一用户名,创建一个新用户xiaobai。
创建用户
sudo useradd -m xiaobai -s /bin/bash
使用sudo命令,需要需要输入当前用户的登录密码才能创建;密码输入后如果没任何提示,说明创建成功
如果提示
useradd: user 'xiaobai' already exists, 表明这个用户名已经存在
设置密码
sudo passwd xiaobai

密码尽量使用简单易记的,比如
123456,毕竟我们只是在学习,没有多少机密文件值得你设置自己都记不清的密码。设置密码的时候,光标不会跳(千万不要以为键盘坏了☺)
当你看到
password updated successfully,表示密码设置成功
为xiaobai增加管理员权限
为了方便部署,避免一些对新手来说比较棘手的权限问题,这里为xiaobai增加管理员权限
sudo adduser test sudo

当然也可以修改文件/etc/sudoers(对于新手无需理会)
切换到用户xiaobai
su - xiaobai
su命令加参数
-的目的是切换用户的同时,会切换到相应用户的Home目录这里输入的密码是刚刚为xiaobai用户设置的密码
2) 安装ssh-server
sudo apt install openssh-client openssh-server
这里使用了sudo命令,输入的密码是xiaobai用户的密码
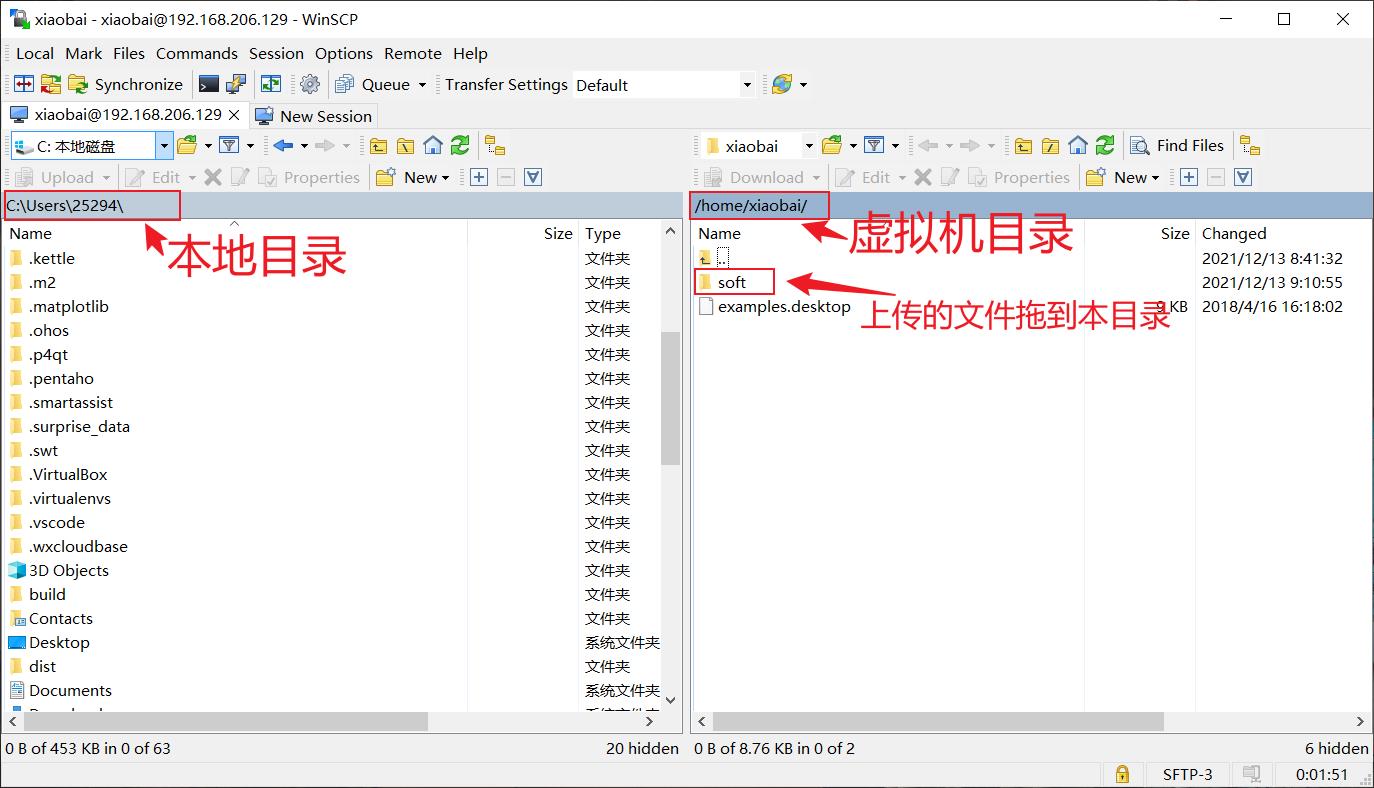
3) 上传相关资源
在Home目录下创建soft目录,使用winscp上传jdk和hadoop到soft目录
cd
mkdir soft
查看虚拟机ip
ip a
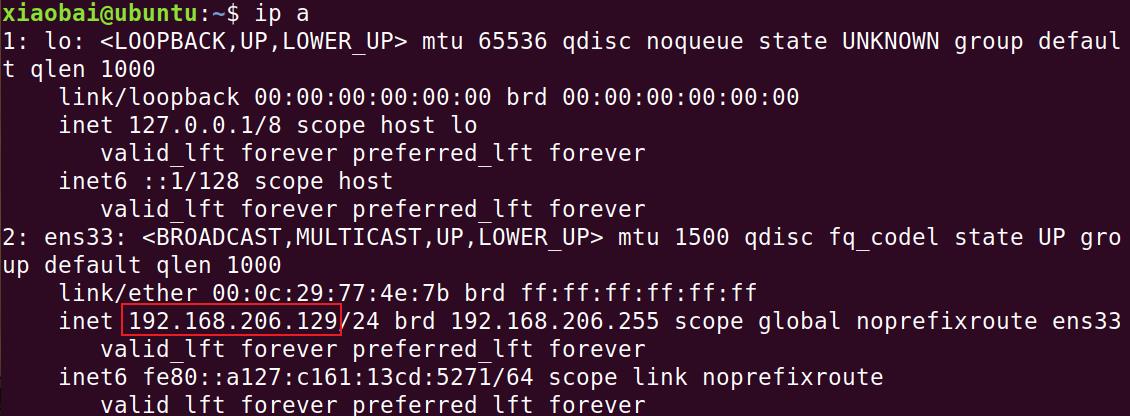
具体的ip地址以你命令输出为准。
创建连接
解压WinSCP-5.19.5-Portable.zip,打开WinSCP.exe,设置相应的连接参数,然后点Login进行连接。

上传文件
将本地目录(左边)需要上传的文件拖入虚机机相应目录。
[4)] 使用putty连接服务器
这一步不是必须的操作,使用putty主要是通过ssh连接虚拟机,进行远程操作而不需要进入虚拟机,相应的替代品有Xshell、secureCRT等
打开putty.exe,设置相应的连接。

5)设置主机名
修改主机名为node1
sudo hostname node1
如果提示
[sudo] password for xiaobai:,表示要执行sudo命令,需要输入xiaobai的登录密码,后面出现类似情况不再介绍
上面命令修改的主机名是临时生效,当虚拟机重启会恢复成原来的主机名,这里修改配置文件使用其永久修改。打开hostname文件, 配置hostname为node1。
sudo vi /etc/hostname
注意,对于小白,如果不想用vi命令,可以使用
sudo gedit /etc/hostname打开类似windows上的记事本进行文件的编辑,后面类似情况自行处理。简单使用方式:进入文件后,输入字母
i进入插入模式 => 修改文件内容为node1 => 按Esc键进入命令行模式 => 输入:进入底行模式 => 输入x或者wq保存推出。如果文件修改后不想保存,进行底行模式后输入
q!进行不保存退出。
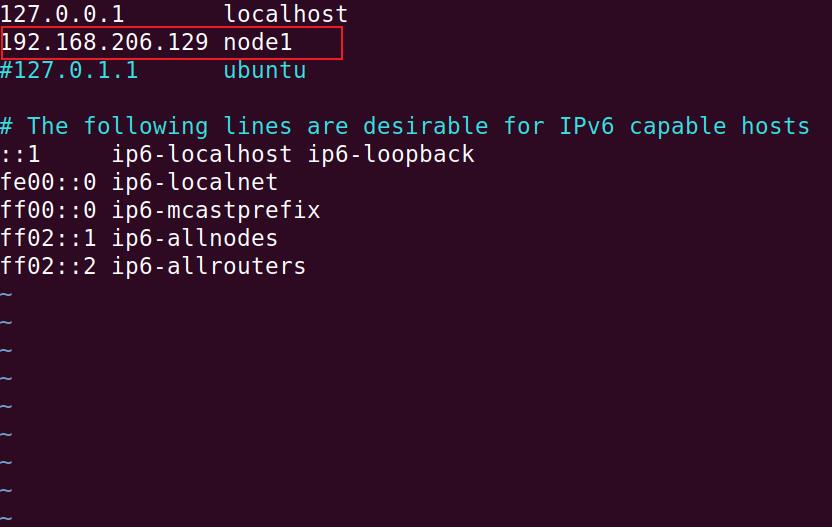
打开hosts文件配置hosts
sudo vi /etc/hosts
6)检查和关闭防火墙
打开终端,安装防火墙管理工具。命令:
sudo apt install ufw
查看防火墙状态。命令:
sudo ufw status
可以看出默认为关闭

若未关闭,使用下面的命令进行防火墙关闭
sudo ufw disable
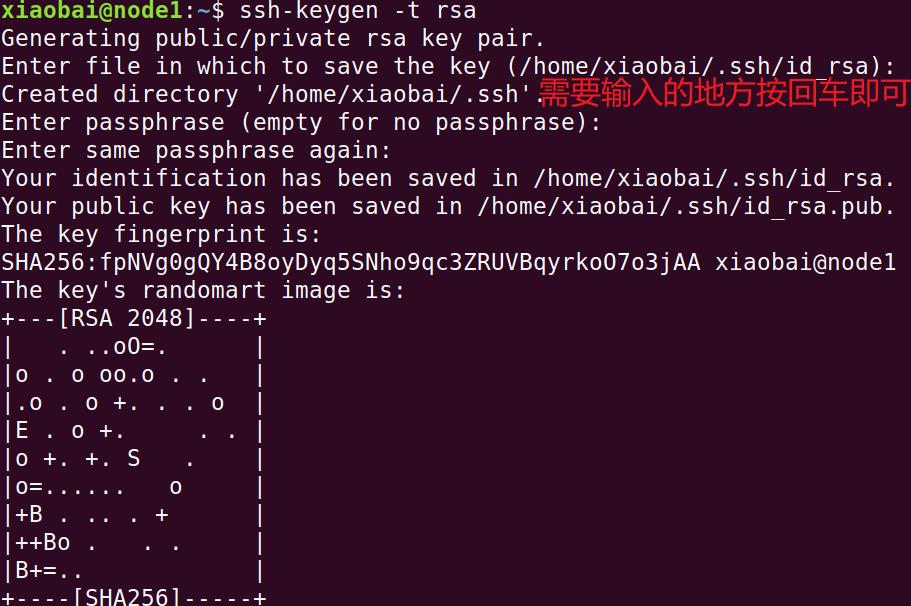
7)设置免密登录
生成密钥对
ssh-keygen -t rsa
拷贝公钥到主机
ssh-copy-id -i ~/.ssh/id_rsa.pub node1
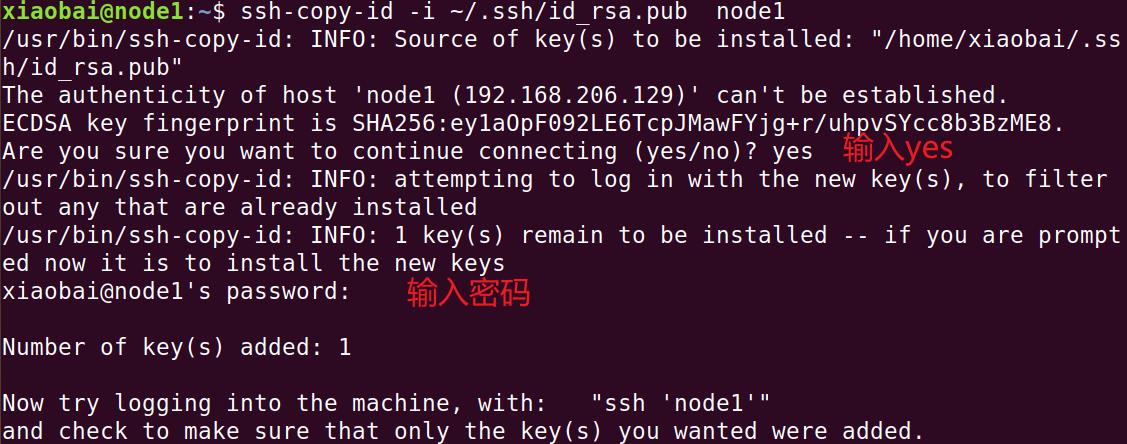
测试免密登录是否成功,
如果没有提示输入密码,则免密登录成功
ssh node1
二、安装JDK
注意:在Home目录(可以使用
~表示Home目录)下面,创建opt目录,所有要安装的软件都放在这个目录
将jdk上传到~/soft目录,确保文件已经上传,输入命令ls ~/soft进入验证

接下来解压文件
mkdir ~/opt
tar -xvf ~/soft/jdk-8u261-linux-x64.tar.gz -C ~/opt
设置软连接
cd ~/opt
ln -s jdk1.8.0_261/ jdk
配置环境变量,打开bash配置文件
cd
vi .bashrc
按i进入插入模式,在末尾添加如下代码,然后按esc退出编辑,输入:x保存
export JAVA_HOME=/home/xiaobai/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
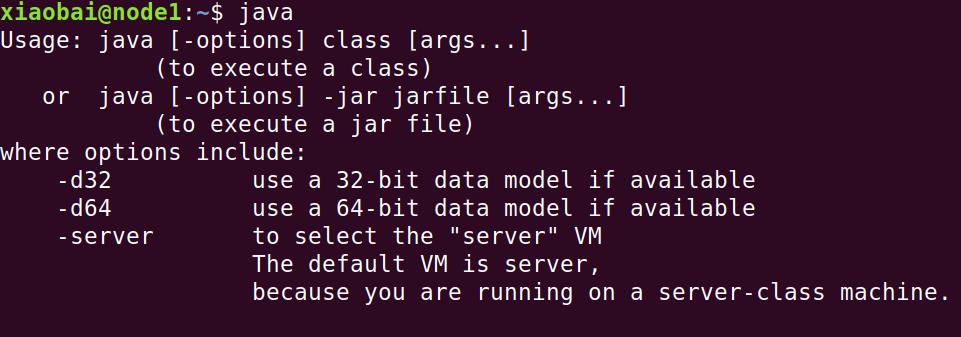
输入以下命令使修改生效,可用java命令验证配置是否成功
source .bashrc
java
三、安装Hadoop
请确保前面已经将hadoop的压缩包上传到了~/soft目录,使用命令ls ~/soft

解压文件
tar -xvf ~/soft/hadoop-2.7.7.tar.gz -C ~/opt
设置软连接
cd ~/opt
ln -s hadoop-2.7.7/ hadoop
配置环境变量
使用命令vi ~/.bashrc打开配置文件,添加以下代码到文件末尾,步骤与配置JDK环境变量相同
export HADOOP_HOME=/home/xiaobai/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Hadoop目录介绍
ls ~/opt/hadoop

Hadoop目录简介:
- bin: 存放对Hadoop相关服务进行操作的脚本,包括 hadoop, hdfs, …
- sbin: 存放启动和停止Hadoop相关服务的脚本,比如start-dfs.sh, start-yarn.sh, hadoop-daemon.sh, …
- etc: 配置文件的目录
- share: 存放Hadoop的依赖jar包、文档、和官方案例
- lib: 存放Hadoop的本地库(对数据进行压缩解压缩功能)
修改配置文件hadoop-env.sh
将JAVA_HOME的值改为jdk的绝对路径/home/xiaobai/opt/jdk
vi ~/opt/hadoop/etc/hadoop/hadoop-env.sh
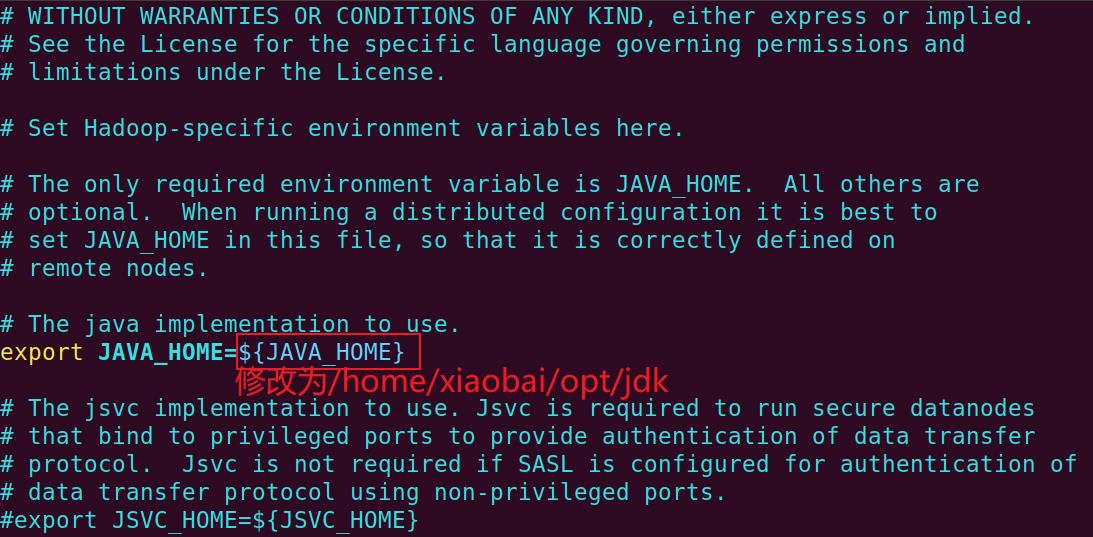
保存修改
验证Hadoop是否安装成功
hadoop
四、配置Hadoop伪分布式
Hadoop主要有三种模式,一般在学习过程中使用伪分布模式基本就可以了
| 模式 | 概念 | 特点 | 用途 |
|---|---|---|---|
| 单机模式 | Hadoop默认模式 | 1.没有分布式文件系统HDFS 2.MapReduce处理的是本地Linux的文件数据 | 一般仅用于本地MapReduce程序的调试 |
| 伪分布模式 | 是在单机上,模拟一个分布式的环境 | 具备Hadoop的主要功能 | 常用于调试程序 |
| 完全分布式模式 | 也叫集群模式,是将Hadoop运行在机器上,各个机器按照相关配置运行相应的hadoop守护进程 | 在多台机器上运行,是真正的分布式环境 | 常用于生产 |
主要的配置文件
| 配置文件 | 配置内容 |
|---|---|
| hadoop-env.sh | 配置与环境相关的参数,比如JAVA_HOME目录 |
| core-site.xml | 配置Hadoop集群相关参数 |
| hdfs-site.xml | 配置HDFS相关参数 |
| mapred-site.xml | 配置MapReduce相关参数 |
| yarn-site.xml | 配置YARN相关参数 |
| slaves | 配置从节点 |
在安装的过程中,已经配置了 hadoop-env.sh中的JAVA_HOME参数,接下来分别配置其他5个配置文件
切换到配置文件目录
cd ~/opt/hadoop/etc/hadoop
1. core-site.xml
| 配置项 | 值 | 说明 |
|---|---|---|
| fs.defaultFS | hdfs://<hostname>:9000 | 配置默认的文件系统,这里配置NameNode地址,9000是RPC通信端口 |
| hadoop.tmp.dir | /home/<用户名>/opt/hadoop/tmp | 其他临时目录的父目录 |
打开core-site.xml文件
vi core-site.xml
在configuration标签中加入以下代码,保存
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xiaobai/opt/hadoop/tmp</value>
</property>
注意:
上面的配置项要配置到
<configuration>标签中,后面的配置项类似hadoop.tmp.dir配置的目录一定要是当前用户有控制权限的目录
更多参数请参考官网:https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-common/core-default.xml
2. hdfs-site.xml
| 配置项 | 默认值 | 说明 |
|---|---|---|
| dfs.replication | 3 | 数据副本个数,伪分布时设为1 |
| dfs.namenode.name.dir | file://$hadoop.tmp.dir/dfs/name | namenode存着数据存放的本地目录 |
| dfs.datanode.data.dir | file://$hadoop.tmp.dir/dfs/data | datanode相关数据存放的本地目录 |
打开hdfs-site.xml文件
vi hdfs-site.xml
往configuration加入设置,保存
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/xiaobai/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/xiaobai/opt/hadoop/tmp/dfs/data</value>
</property>
更多参数请参考官网:https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
3. mapred-site.xml
| 配置项 | 默认值 | 说明 |
|---|---|---|
| mapreduce.framework.name | local | MapReduce的执行模式,默认是本地模式,另外可以设置成classic(采用MapReduce1.0模式运行) 或 yarn(基于YARN框架运行). |
| mapreduce.job.ubertask.enable | false | 是否允许开启uber模式,当开启后,小作业会在一个JVM上顺序运行,而不需要额外申请资源 |
| dfs.namenode.secondary.http-address | 0.0.0.0:50090 | secondary namenode 的http服务地址和端口 |
| dfs.namenode.secondary.https-address | 0.0.0.0:50091 | secondary namenode 的https服务地址和端口 |
默认情况下没有这个配置文件,可以根据样本文件mapred-site.xml.template复制一份。
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
往configuration加入设置,保存
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node1:50091</value>
</property>
更多参数请参考官网:https://hadoop.apache.org/docs/r2.7.7/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
4. yarn-site.xml
| 配置项 | 默认值 | 说明 |
|---|---|---|
| yarn.resourcemanager.hostname | 0.0.0.0 | ResourceManager的主机名 |
| yarn.nodemanager.aux-services | NodeManager上运行的附属服务 |
打开yarn-site.xml文件
vi yarn-site.xml
往configuration加入设置,保存
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
更多参数请参考官网:https://hadoop.apache.org/docs/r2.7.7/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
5. slaves
该文件配置从服务器的地址,一个服务器地址占一行。
打开slaves
vi slaves
将默认的localhost修改成node1
node1
五、启动与测试
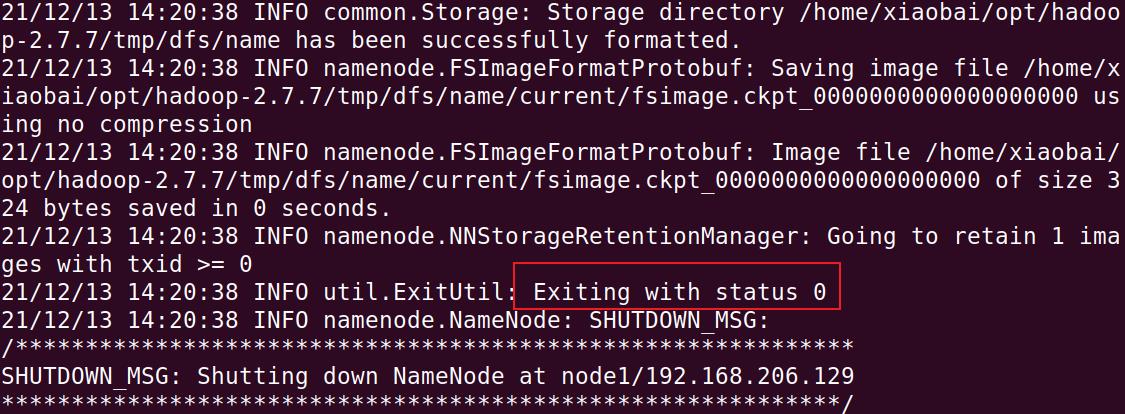
1. 格式化
在第一次启动Hadoop时,一定要记得对HDFS进行格式化
hdfs namenode -format
2. 启动
start-all.sh

3. 查看进程
jps
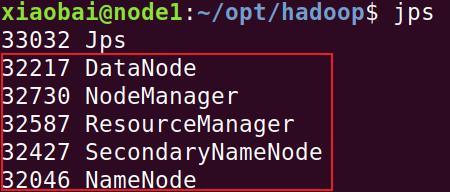
jps(Java Virtual Machine Process Status Tool)是java提供的一个显示当前所有java进程pid的命令,适合在linux/unix平台上简单察看当前java进程的一些简单情况。jps命令类似于unix系统里的ps命令(主要是用来显示当前系统的进程情况,有哪些进程以及进程id),它的作用是显示当前系统的java进程情况及进程id。
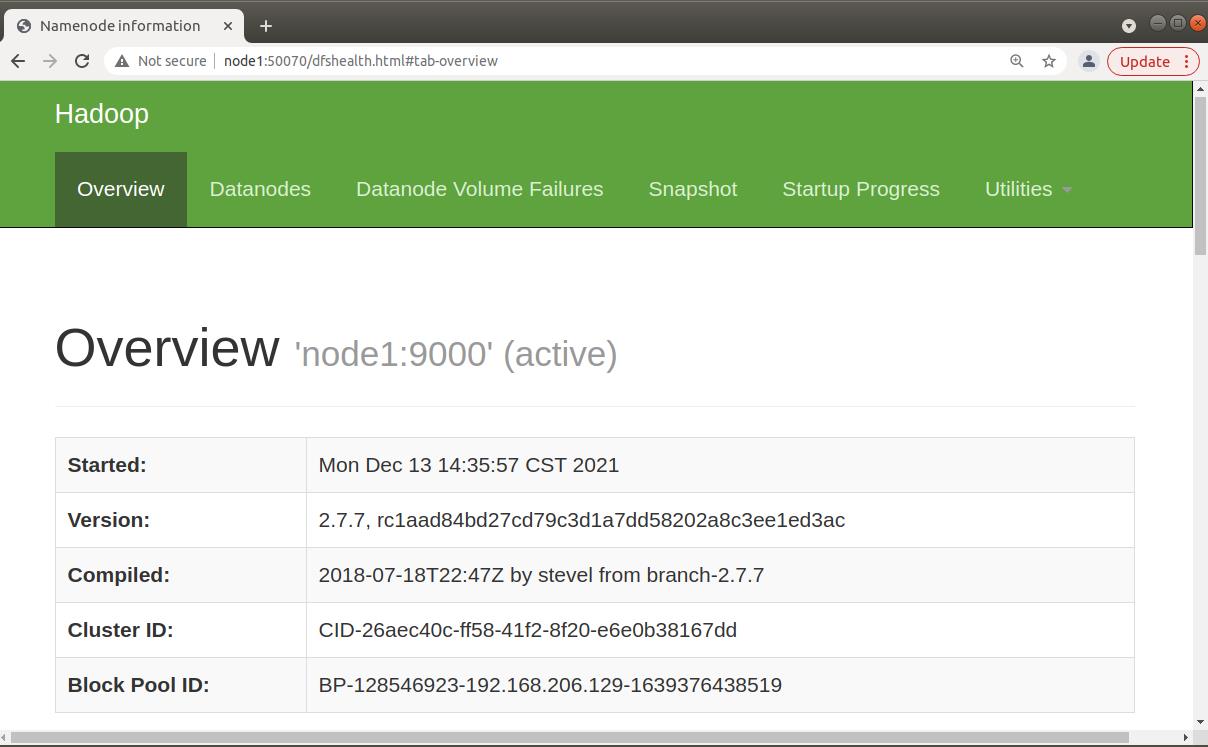
4. 通过web访问实验总结
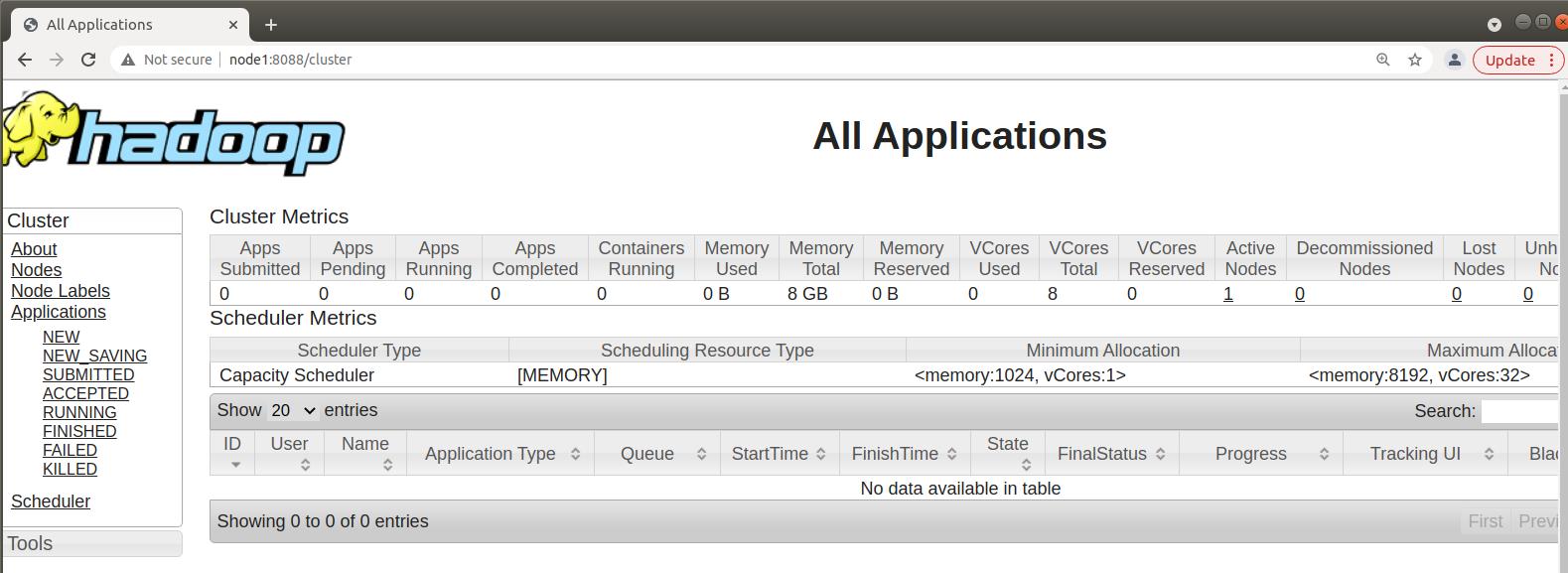
在虚拟机中,使用浏览器打开如下两个网址,可以查看HDFS的NameNode和YARN的ResourceManager相关信息
node1:50070
node1:8088
5. 测试
使用hdfs命令上传一个文件到HDFS文件系统
#切换到Home目录
cd
#编辑一个本地文件,比如输入:a b c a a a b
vi test.txt
#上传到HDFS根目录
hdfs dfs -put test.txt /
运行mapreduce示例代码,进行词频统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /test.txt /output

查看运行结果
#查看输出目录
hdfs dfs -ls /output
#查看输出内容
hdfs dfs -cat /output/part*

至此,表明你的Hadoop伪分布式搭建完成!!!
如果有错误,可以查看第六部分内容:常见问题及解决方案
6. Hadoop启动服务总结
在第2步中,我们启动Hadoop时使用的start-all.sh, 在下面的提示信息中显示 This script is Deprecated,也就是说这个启动脚本是被弃用的状态,并且建议我们Instead use start-dfs.sh and start-yarn.sh
下面就Hadoop的服务启动进行简单的总结:
1)整体启动和关闭
start-all.sh
stop-all.sh
2)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
3) 各个模块分开启动/停止
(1)整体启动/停止HDFS
start-dfs.sh
stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh
stop-yarn.sh
六、常见错误及解决办法
1. 出现command not found错误
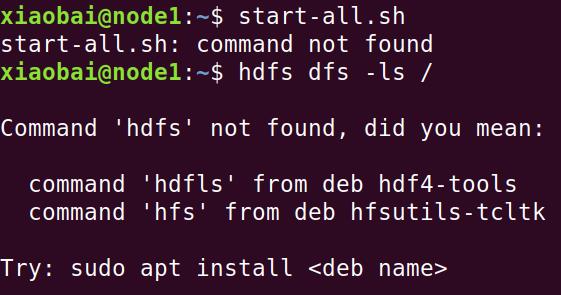
1)检查~/.bashrc文件中是否配置了正确的PATH
2)如果~/.bashrc设置正确,是否没有执行source ~/.bashrc使环境变量生效
2. 所有命令都运行不了
如果你发现不止安装的程序命令,就连原系统的内置命令都使用不了(比如ls、vi、cat等),很明显,你在修改.bashrc时,将PATH路径设置错了。最常见的是错误就是在设置PATH时,PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin,把$PATH:漏掉了,这就相当于现在的PATH路径只有两个值$HADOOP_HOME/bin和$HADOOP_HOME/sbin。
解决办法:
1)恢复默认的PATH路径:
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
2)修改~/.bashrc文件,检查设置PATH的地方是否漏掉了$PATH:
3. 不小心多次格式化
多次格式化导致DataNode 与 NameNode namespaceID不一致,导致启动HDFS失败,这里告诉最直接暴力的解决办法, 清空$hadoop.tmp.dir这个目录,以本文为例:
stop-all.sh
#本教程配置的hadoop.tmp.dir目录为/home/xiaobai/opt/hadoop/tmp
rm -fr /home/xiaobai/opt/hadoop/tmp
4. NameNode启动不成功
1) NameNode没有格式化
2) 环境变量配置错误
3) Ip和hostname绑定失败,需要通过ip a查看ip地址,重新配置/etc/hosts文件,设置正确的ip和hostname
4)hostname含有特殊符号如.(符号点),会被误解析
5. 万能大法
一切的错误,最好的解决办法是查看日志
Hadoop的默认日志文件目录在$HADOOP_HOME/logs, 比如在本教程中,在~/opt/hadoop/logs

这里列举两个示例:
1)提示Content is not allowed in prolog错误
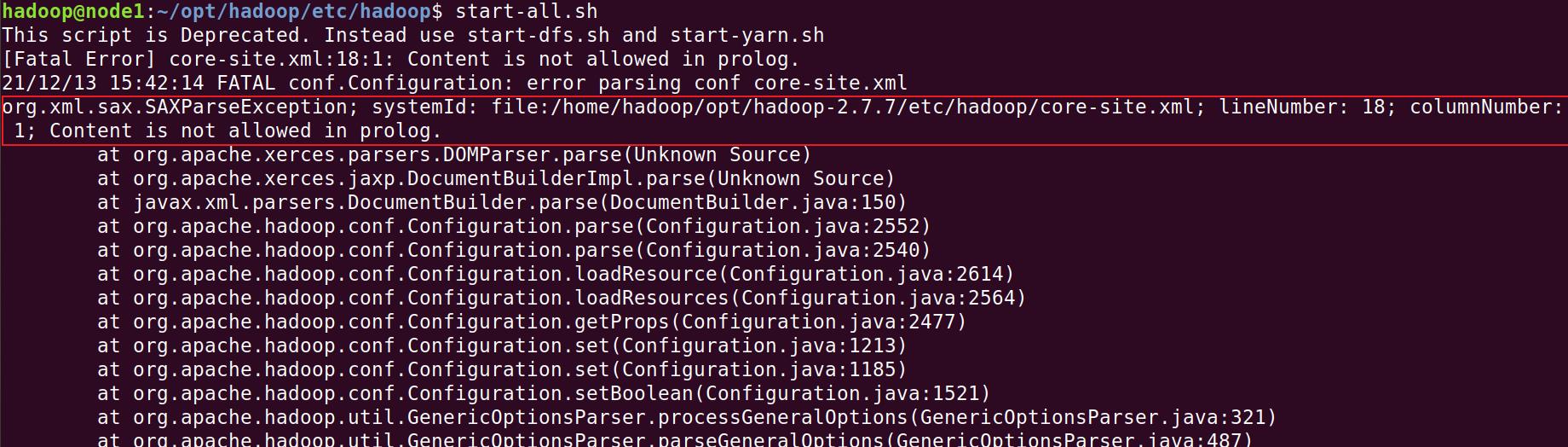
这个错误比较明显,显示在core-site.xml文件的第18行第1列有一个字符不认识,使用命令vi查看相应配置,修改即可。注意,这里不建议使用gedit打开文件查看,因为如果有不可见字符,gedit也看不见,难以查错。
2)jps时查看进程少启动了部分服务,比如下面示例中发现没有启动NodeManager
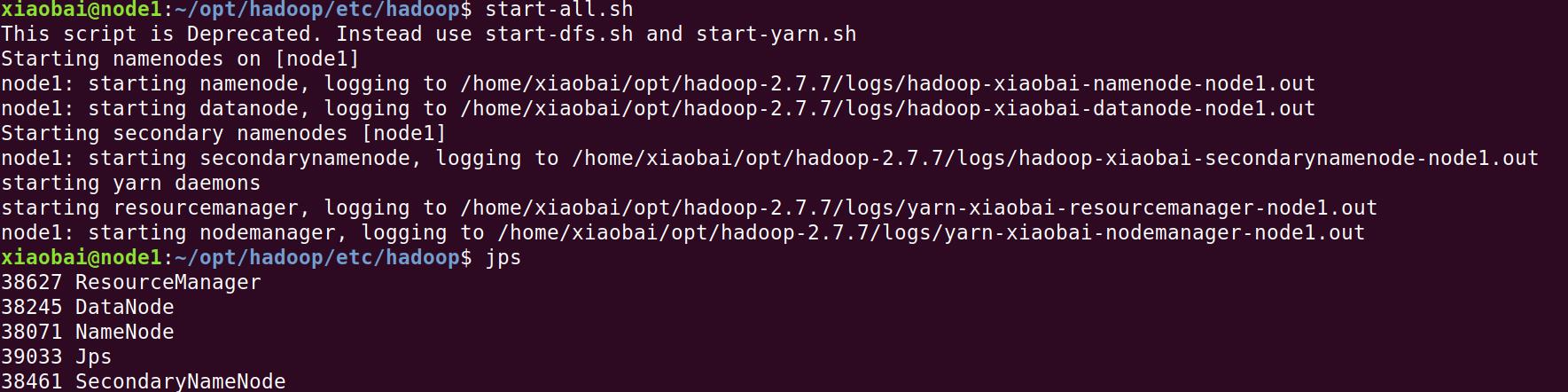
这种错误最好最直接的方式是查看日志文件,而不是去Baidu,去Google,因为各自的问题都不尽一致,必须找准备病因,才能药到病除。
进入日志目录
cd ~/opt/hadoop/logs
ls
NodeManager属于YARN组件的服务,在ls的结果中可以迅速找到相应的日志文件yarn-xiaobai-nodemanager-node1.log
使用tail命令查看最后50行日志内容:
tail -n 50 yarn-xiaobai-nodemanager-node1.log
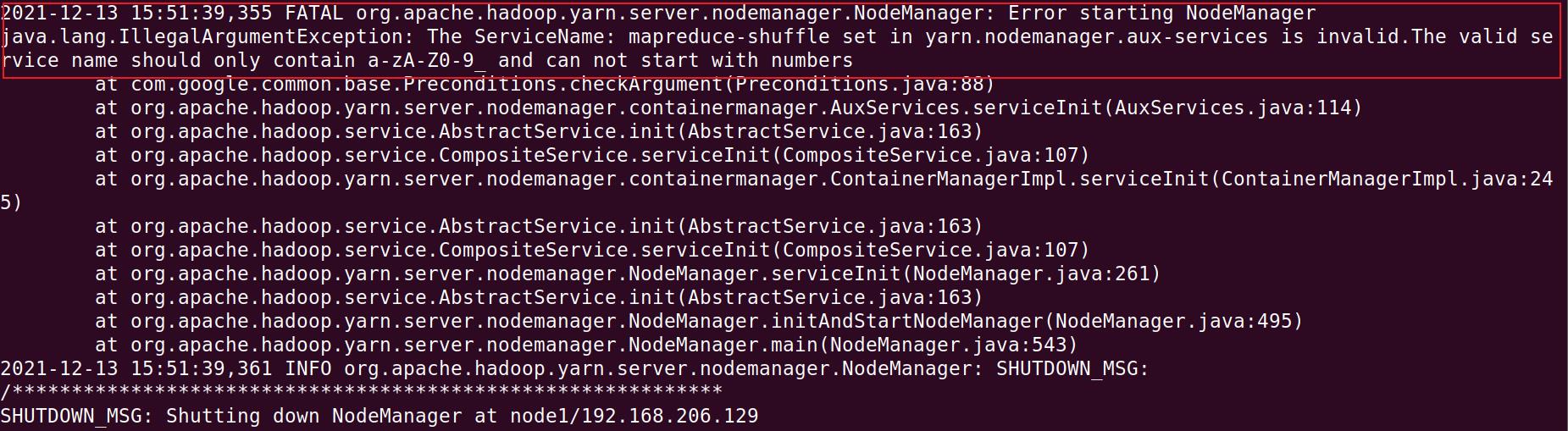
错误原因为:The ServiceName: mapreduce-shuffle set in yarn.nodemanager.aux-services is invalid.The valid service name should only contain a-zA-Z0-9_ and can not start with numbers。
意思是说服务名无效,只能由 a-zA-Z0-9_ 组成并且不能以数字开始,错误很明显了,错误原因是yarn-site.xml这个配置文件中配置了无效的服务名,打开该配置文件,检查并修改相应配置项即可。
以上是关于Hadoop2.7.7伪分布式环境搭建(保姆级教程)的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop 3.1.3 分布式集群搭建,超详细,保姆级教程
IT保姆级❤️开发测试环境搭建教程大集合热门技术+工具类(持续更新)
Hadoop完全分布式集群搭建 centos 6.5(保姆级教程)