Maix Bit(K210)保姆级入门上手教程---环境搭建
Posted Silent Knight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Maix Bit(K210)保姆级入门上手教程---环境搭建相关的知识,希望对你有一定的参考价值。
Maix Bit(K210)快速上手系列—环境搭建
Maix Bit(K210)保姆级入门上手教程—外设基本使用
Maix Bit(K210)保姆级入门上手教程—自训练模型之云端训练
这是K210快速上手系列文章,主要内容是,设备连接,环境准备,运行第一个程序
阅读文章前提:python基础,K210是使用Micropython脚本语法的,因此需要一些python基础,如果无python基础,可以先去学习。
文章目录
一、简介
1、K210是什么?
K210是一款 64 位双核带硬件 FPU、卷积加速器、FFT、Sha256 的 RISC-V CPU 的;我们使用的是MaixPy( Micropython 移植到 K210的项目),所以学习是是需要python基础的。
2、Maix Bit是什么?
Maix Bit是一款基于K210的最小系统版,系统引脚全部引出,上手的话推荐这个,主要是便宜。
官网购买链接

3、MaixPy能做什么?
上面说了,我们是使用MaixPy来操作K210款芯片的,MaixPy是使用Micropython,语法的。从Micropython,就可以知道我们操作是使用python来进行操作的,python语法简单,容易上手。因此基于MaixPy的项目,能迅速上手,而且容易理解语法简单。
我们已经理解了,MaixPy简单容易上手,那么到底能做什么呢?
MaixPy支持常规MCU操作+AI硬件加速+麦克风阵列算法,而且算力很高(高达 1TOPS 算力核心模块),适合AIOT领域的应用。说人话就是,它可以搞MCU的东西,比如ADC、GPIO、PWM等操作,也可以搞图像识别,可以跑YOLO算法,人脸识别等,也可以搞声音处理,对声波进行过滤等。使用MaixPy最重要是上手简单快速,这个是它最大的优势。
当然也可以不使用它,可以使用C语言进行开发,使用官方的SDK即可。
K210官方SDK
4、简单感受MaixPy的便捷和快速上手
普通MUC使用C语言操作I2C(基于STM32 HAL库)
// I2C初始化
#include "i2c.h"
I2C_HandleTypeDef hi2c1;
void MX_I2C1_Init(void)
hi2c1.Instance = I2C1;
hi2c1.Init.ClockSpeed = 400000;
hi2c1.Init.DutyCycle = I2C_DUTYCYCLE_2;
hi2c1.Init.OwnAddress1 = 0;
hi2c1.Init.AddressingMode = I2C_ADDRESSINGMODE_7BIT;
hi2c1.Init.DualAddressMode = I2C_DUALADDRESS_DISABLE;
hi2c1.Init.OwnAddress2 = 0;
hi2c1.Init.GeneralCallMode = I2C_GENERALCALL_DISABLE;
hi2c1.Init.NoStretchMode = I2C_NOSTRETCH_DISABLE;
if (HAL_I2C_Init(&hi2c1) != HAL_OK)
Error_Handler();
void HAL_I2C_MspInit(I2C_HandleTypeDef* i2cHandle)
GPIO_InitTypeDef GPIO_InitStruct = 0;
if(i2cHandle->Instance==I2C1)
__HAL_RCC_GPIOB_CLK_ENABLE();
GPIO_InitStruct.Pin = GPIO_PIN_6|GPIO_PIN_7;
GPIO_InitStruct.Mode = GPIO_MODE_AF_OD;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF4_I2C1;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
__HAL_RCC_I2C1_CLK_ENABLE();
void HAL_I2C_MspDeInit(I2C_HandleTypeDef* i2cHandle)
if(i2cHandle->Instance==I2C1)
__HAL_RCC_I2C1_CLK_DISABLE();
HAL_GPIO_DeInit(GPIOB, GPIO_PIN_6);
HAL_GPIO_DeInit(GPIOB, GPIO_PIN_7);
Maix Bit操作I2C
# 内容来自官网文档
from machine import I2C # 导入内置库
# I2C初始化
i2c = I2C(I2C.I2C0, freq=100000, scl=28, sda=29) # 定义一个I2C对象, 使用I2C0, 频率100kHz,SCL引脚是IO28, SDA 引脚是IO29
devices = i2c.scan() # 调用函数扫描设备
print(devices) # 打印设备
使用Python一句话就可以初始化I2C,进行使用了,而C语言需要很多语句,可以说十分的便捷了
二、Maix bit硬件
1、Maix bit需要用到的基本硬件
主板+2.4寸屏幕+摄像头+数据线+内存卡+读卡器
注意:官方标配并没有内存卡、数据线和读卡器,需要自己在官网上买

这个是官方推荐标配:

2、Maix bit硬件接线
注意,没接好线前,不要上电。接线的注意如下图已经标出,如图接线即可。

有一点非常需要注意:摄像头下面两端都需要装好螺丝和螺母,且摄像头底部不能接触到芯片,否则芯片可能会烧掉。

3、测试Maix Bit硬件
安装好就可以上电测试了,测试主要测试摄像头和屏幕正常不正常(这时候不需要装SD卡)
一开始上电正常

按下RESET键后迅速按下BOOT键一段时间,进入测试阶段,
测试可以扭动摄像头头部,这里可以手动对焦。

三、环境准备
1.github加速器
这个是必备的,因为我们需要访问github去下载源码,而国内访问github不使用加速器普遍比较慢,甚至不能访问,这里推荐一个加速器,最重要是免费和操作简单。
加速器基本使用,点击exe文件运行,然后点击设置

选择GITHUB加速选项,然后保存设置

点击重启后端即可正常访问github
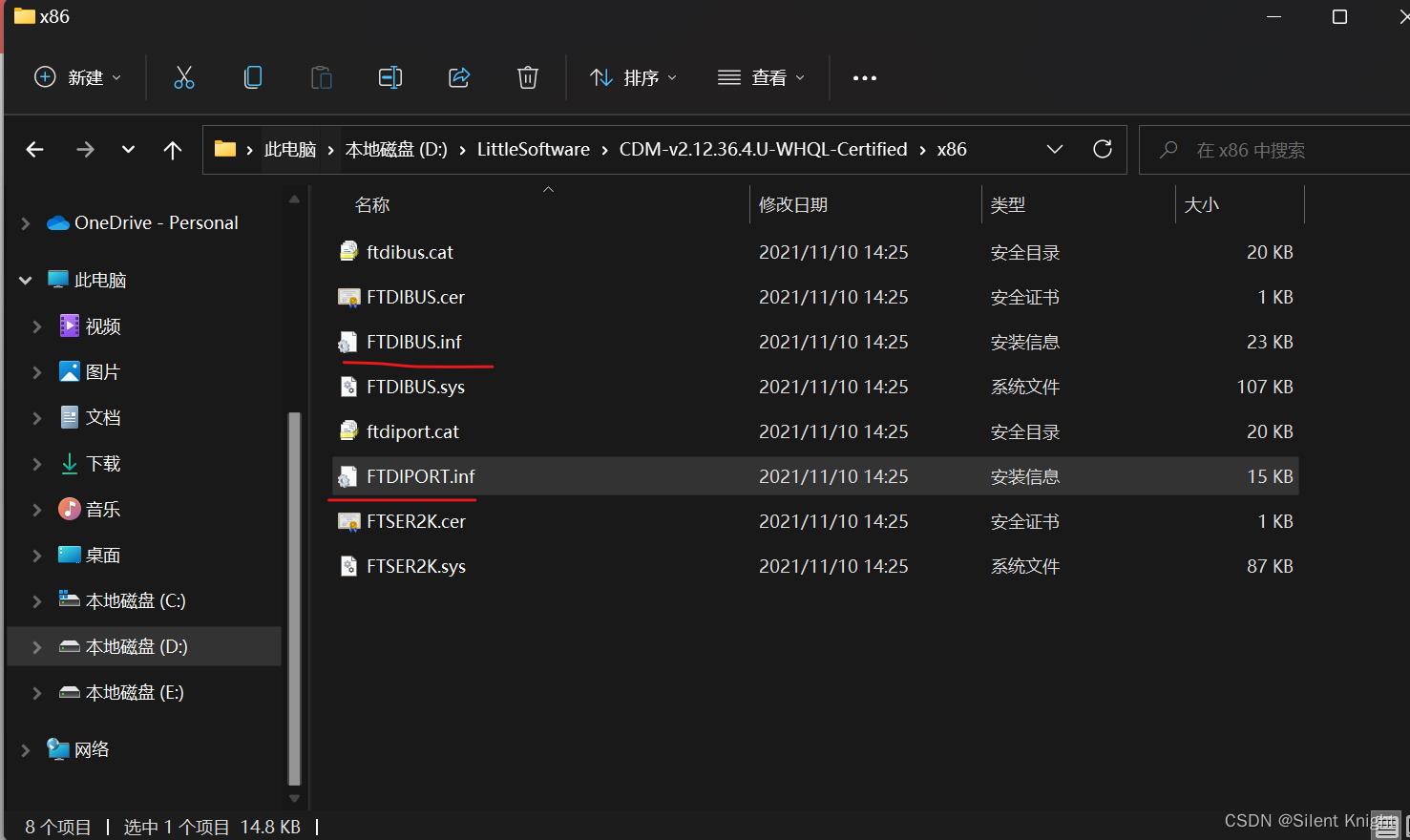
2.驱动安装
新版用Maix Bit的使用的驱动是CH552,安装新版的就行,不必安装ch340 ch341 驱动

驱动安装:解压后,右键选择安装
3.固件下载
我们从一开始测试板子的时候就可以知道,已经是有默认的固件了,但是需求不一样,用到的固件不一样。我们需要学会如何去下载固件。
a:固件本体
一般有这几类固件,我们需要下载最新和最全那个
固件下载链接
这里下载第15个,第15个是拿到板子默认的那个。在readme.txt有不同版本固件的描述

参考资料
b:安装固件软件
安装固件,我们需要用到kflash_gui软件,下载最新的即可。这里需要访问github,记得使用加速器加速(上面有加速器的下载和使用)
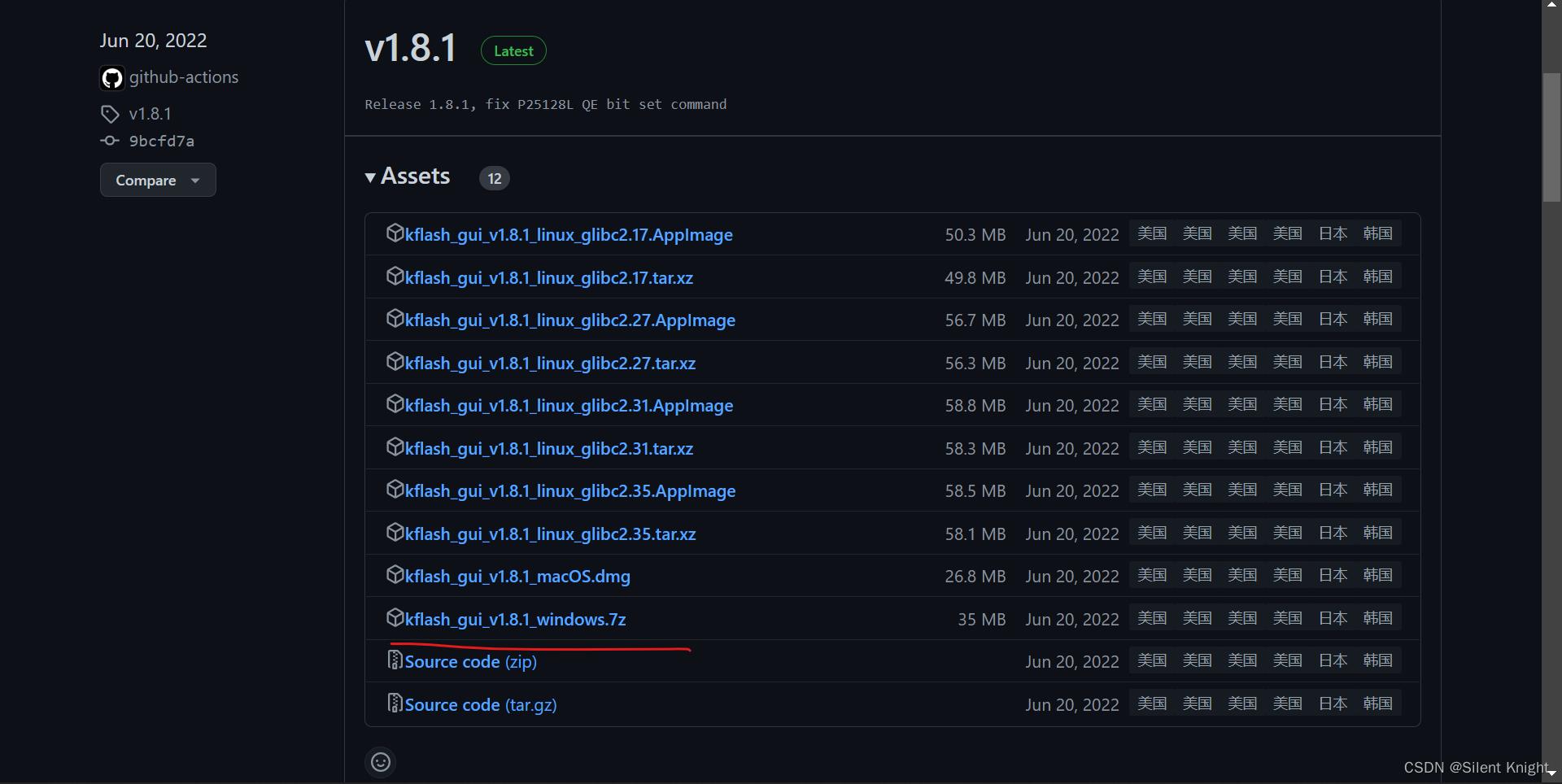
c:安装固件
选择下载的固件,我这里下载的是V0.6.2和默认固件版本是一样的,所以屏幕显示和测试时候屏幕显示一样
端口选择:带USB的那个
其他选项默认即可
3.mpfs串口工具
我们需要与开发板进行连接,而我们安装的驱动的CH552,也就是串口驱动,我们能够通过它与开发板上的串口进行通信。
有了驱动,还需要一个向驱动发送数据的工具,就是串口工具,这里使用mpfs,使用命令行进行下载
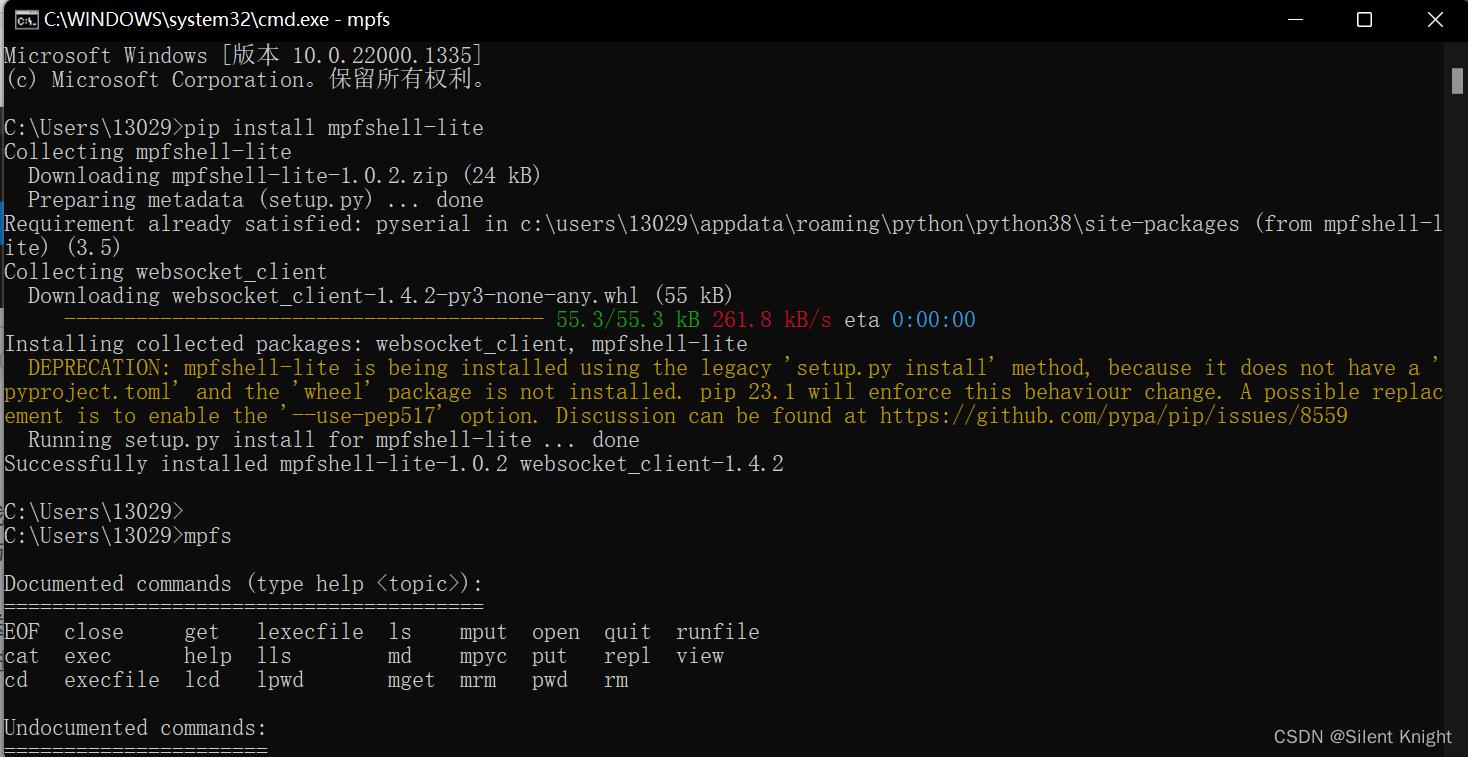
a.mpfs串口工具下载
命令:pip install mpfshell-lite
b.mpfs连接串口
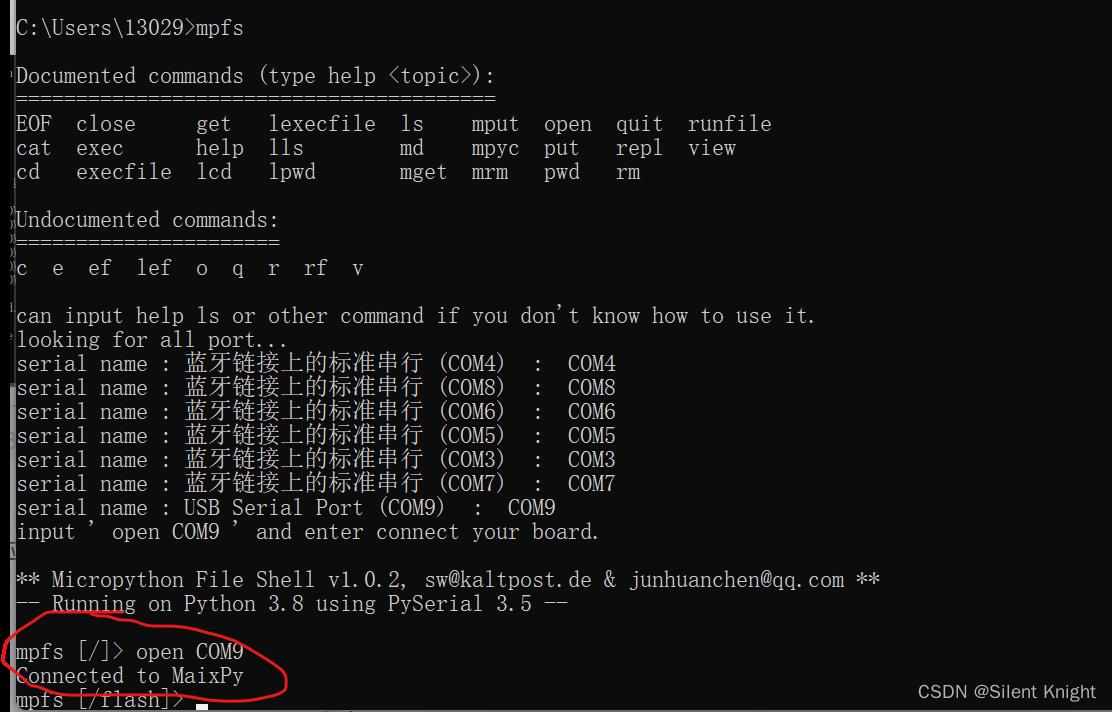
输入命令mpfs即可看到有什么串口就可以进行操作
命令:mpfs

使用open COMX,即可连接到相应的串口
命令:open
这里我COM9就Maix Bit所在串口(有输出提示,USB Serial Port),命令行输入open COM9就连接到开发板了
第一个命令:
hello world

命令:exec print
4、普通串口工具使用
这里建议使用MobaXterm,使用它可以直接使用串口进行连接到开发板。使用普通串口工具作用就相当于使用python的命令行,类似PC端上使用python命令行,连接上一样是有>>>和能够使用python语法
类似下图
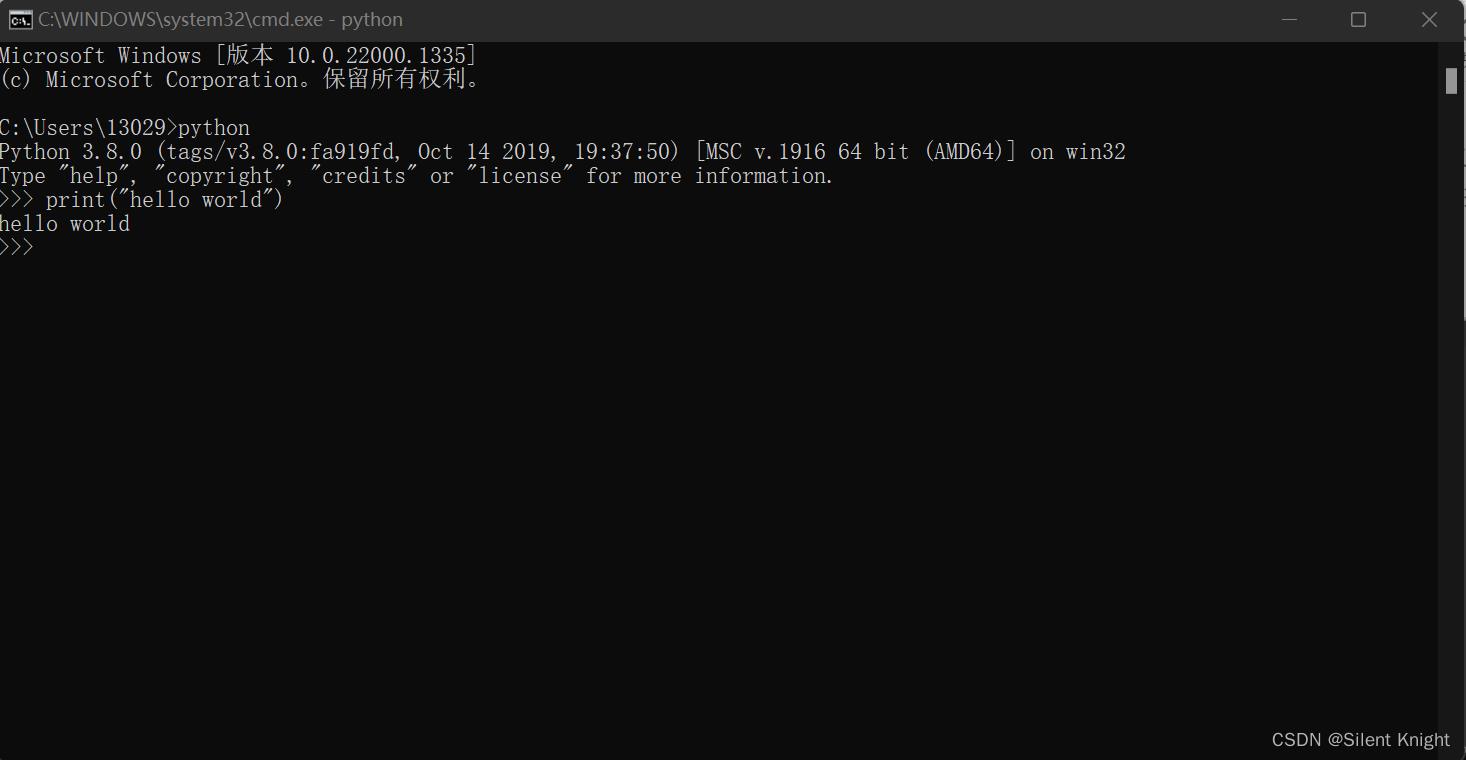
安装好,连接上我们的开发板,这里COM9是开发板的端口,波特率115200
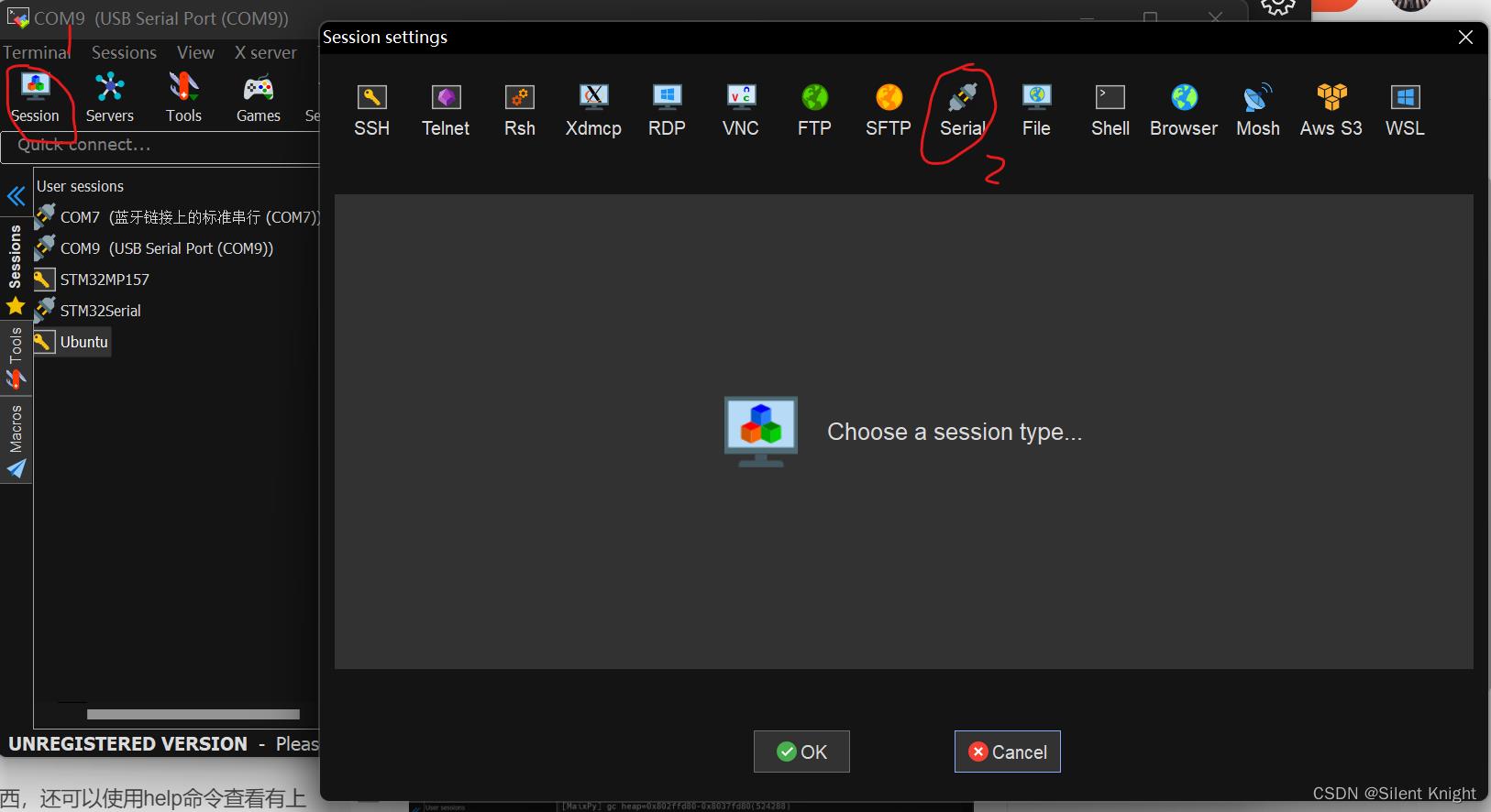

连接到开发板之后就会用>>>,我们就直接可以使用python语法进行操作了
直接使用print就可以打印东西,还可以使用help()查看有上面操作

5.串口工具连接不上的问题的解决
a:固件没刷好
解决方案一:重刷固件
b:驱动没装好
解决方案二:可能是串口驱动没装好或者不是新版的Maix Bit,是旧版用的CH340,CH341。这里可以通过查看设备管理器进行查看
这个是安装成功的样子,有USB Serial Port(带麦克风,新版的Maix Bit)

c:Python本身正在运行程序,一般是boot.py文件中(开机自动运行的程序)有死循环,而且没有休眠的操作
默认程序就是这样,这种情况下,一般是IDE能连接上串口(详细怎么使用IDE连接串口,看文章往下看,具体有怎么使用IDE连接到开发板),需要将默认的程序中的死循环去除,发送到开发板的boot.py文件

发送操作如下,记得把while True 去除
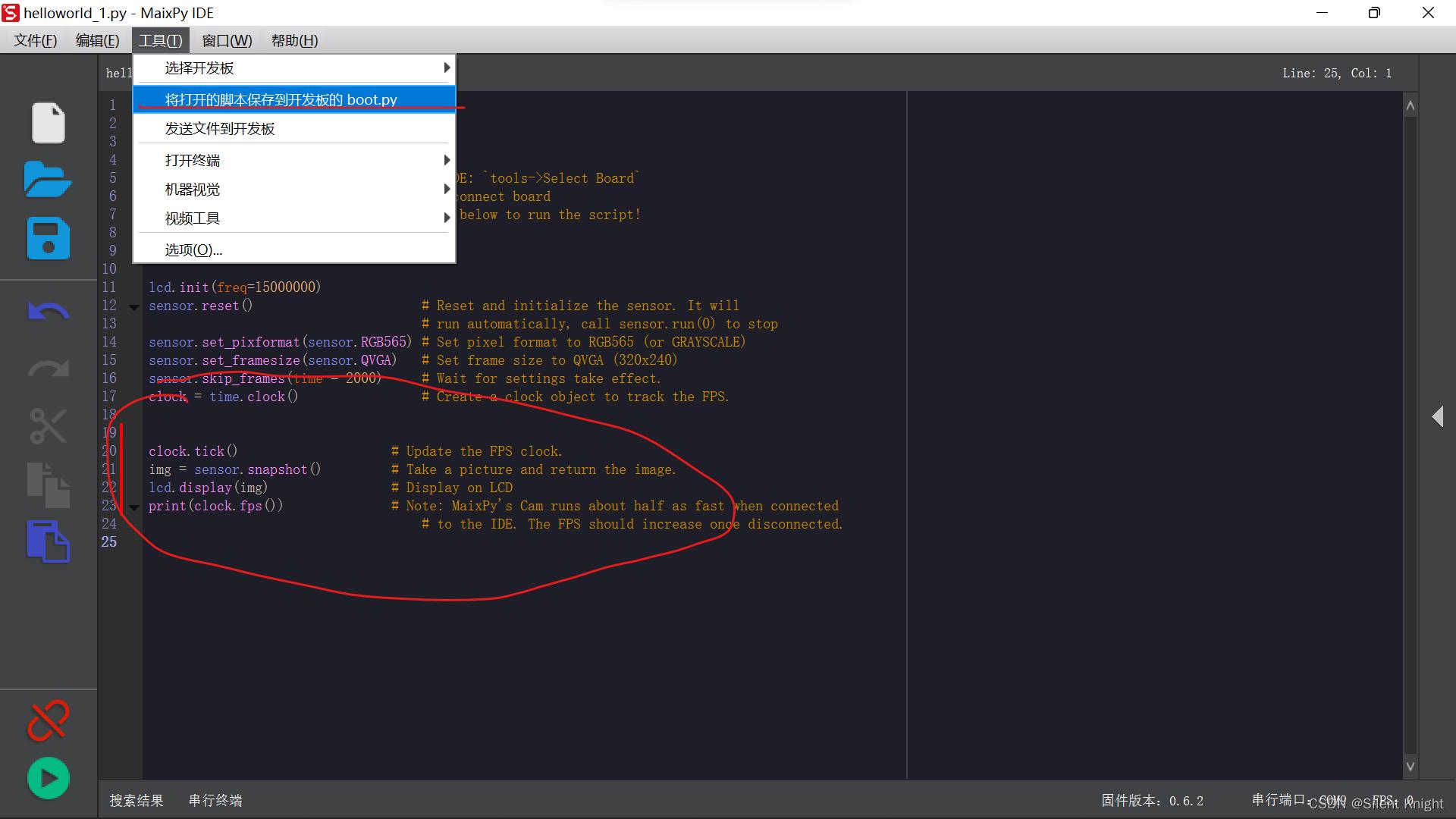
一般完成这个就可以通过mpfs进行连接了
d:串口被不知名进程占用
需要清楚注册表或者重启,一般清楚注册表就可以了
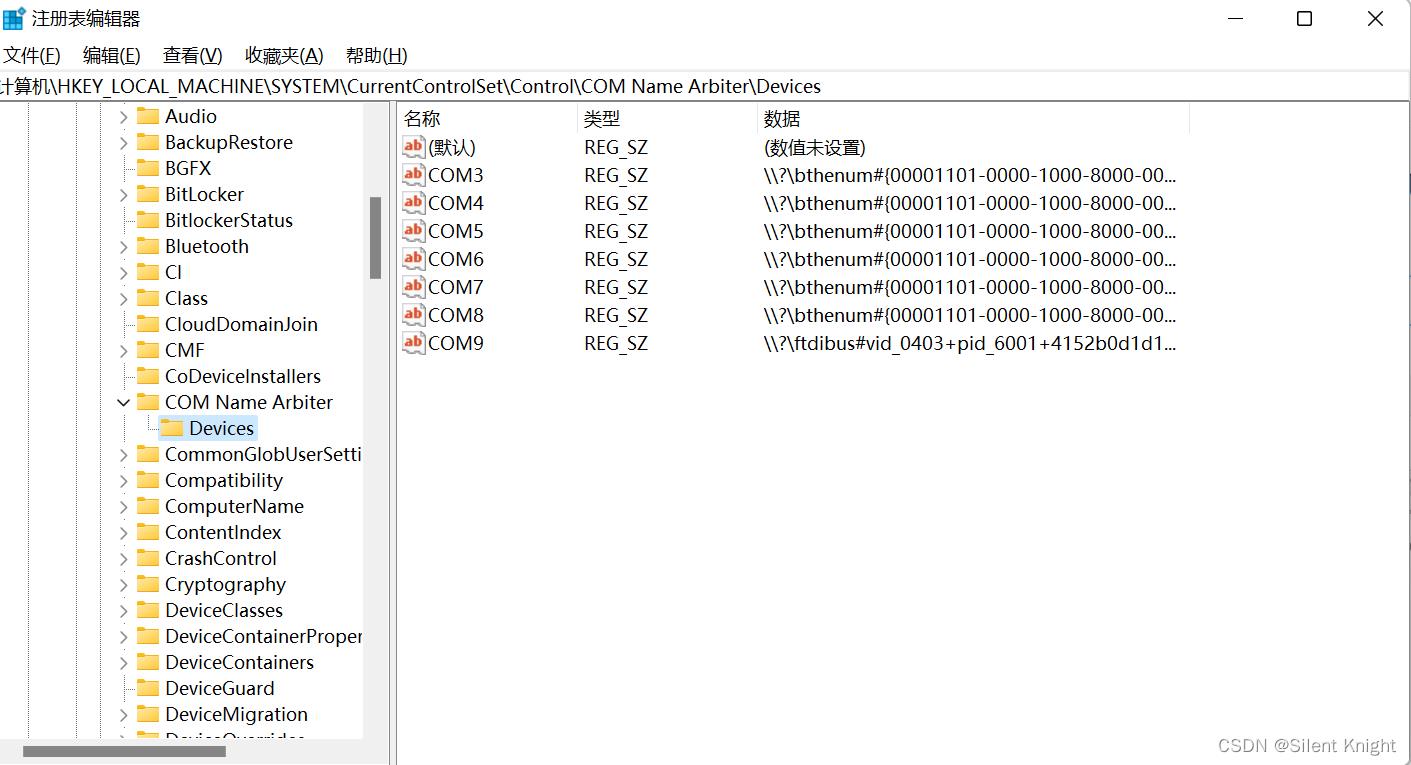
操作如下:打开命令行,输入regedit
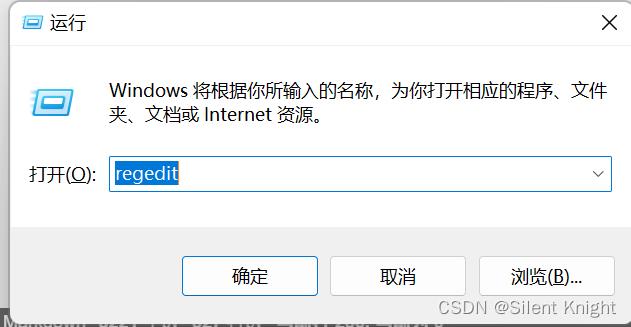
找到目录:HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Control\\COM Name Arbiter\\Devices,然后删除注册表(删除已经安装好CH552的串口,设备管理器中能查看),我这里是COM9,右键COM9,点击删除即可,然后重新拔插USB
6.MaixPy IDE下载
下载最新的exe文件安装即可
IDE下载
安装完成界面:
四、第一个程序
1、使用串口调试助手运行第一个程序
使用到的命令参考
我们直接使用串口调试助手在板子运行第一个程序
首先我们在任意位置需要创建一个py文件,内容:
print("hello world")
获取py文件位置:
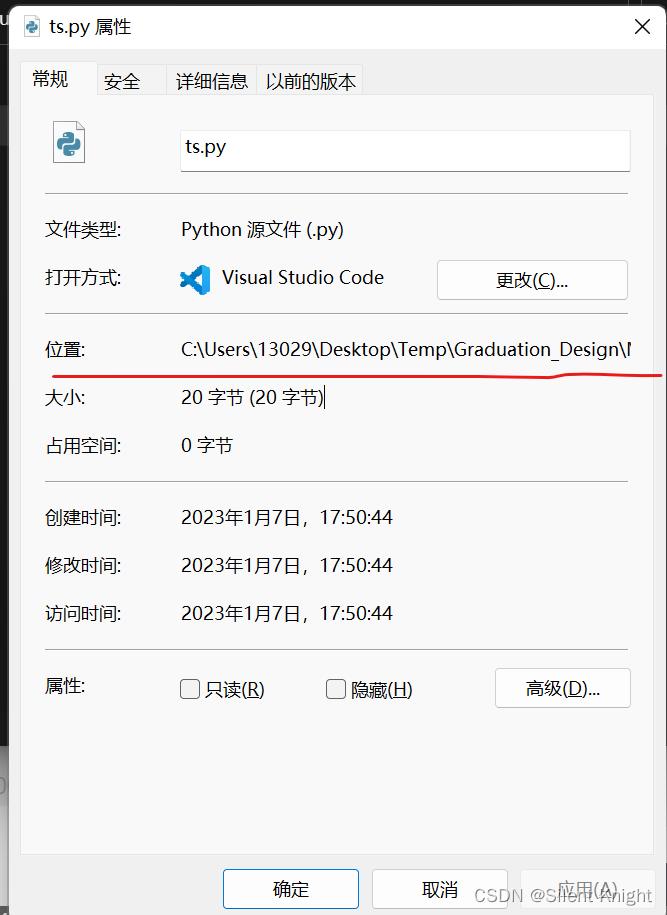
将串口调试助手的工作目录切换到刚刚定位创建py的目录:
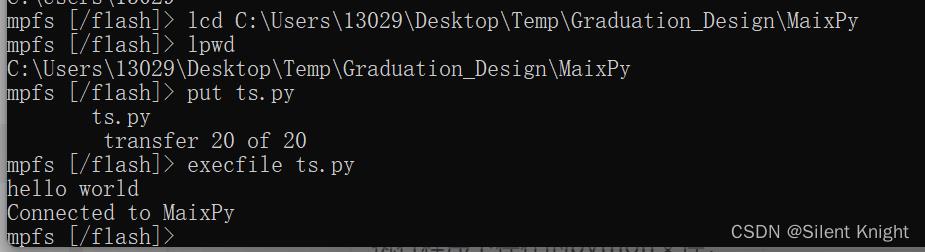
命令:lcd C:\\Users\\13029\\Desktop\\Temp\\Graduation_Design\\MaixPy
将文件上传到开发板:
命令:put ts.py
运行程序:
命令:execfile ts.py
2、MaixPy IDE 运行第一个程序
将默认程序注释,只留下我们的print程序,这里运行的程序是一次性的,关机就没有了。具体想要永久将文件存放到开发板和选择开机启动程序,可以使用mpfs或者IDE发送文件到开发板
# Hello World Example
#
# Welcome to the MaixPy IDE!
# 1. Conenct board to computer
# 2. Select board at the top of MaixPy IDE: `tools->Select Board`
# 3. Click the connect buttion below to connect board
# 4. Click on the green run arrow button below to run the script!
'''
import sensor, image, time, lcd
lcd.init(freq=15000000)
sensor.reset() # Reset and initialize the sensor. It will
# run automatically, call sensor.run(0) to stop
sensor.set_pixformat(sensor.RGB565) # Set pixel format to RGB565 (or GRAYSCALE)
sensor.set_framesize(sensor.QVGA) # Set frame size to QVGA (320x240)
sensor.skip_frames(time = 2000) # Wait for settings take effect.
clock = time.clock() # Create a clock object to track the FPS.
while(True):
clock.tick() # Update the FPS clock.
img = sensor.snapshot() # Take a picture and return the image.
lcd.display(img) # Display on LCD
print(clock.fps()) # Note: MaixPy's Cam runs about half as fast when connected
# to the IDE. The FPS should increase once disconnected.
'''
print("hello world")
在工具栏中选择相应的开发板:
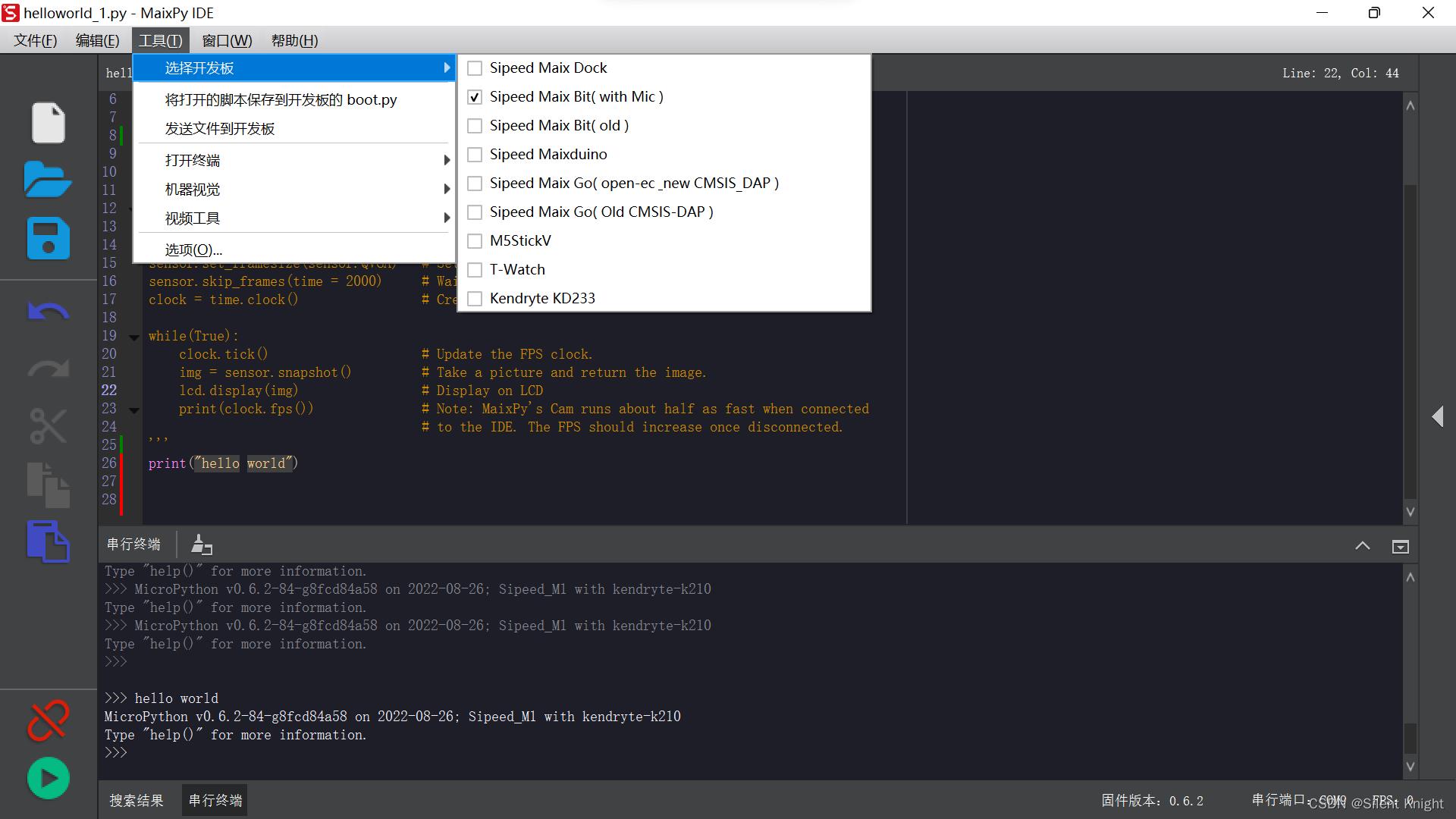
利用IDE连接串口:
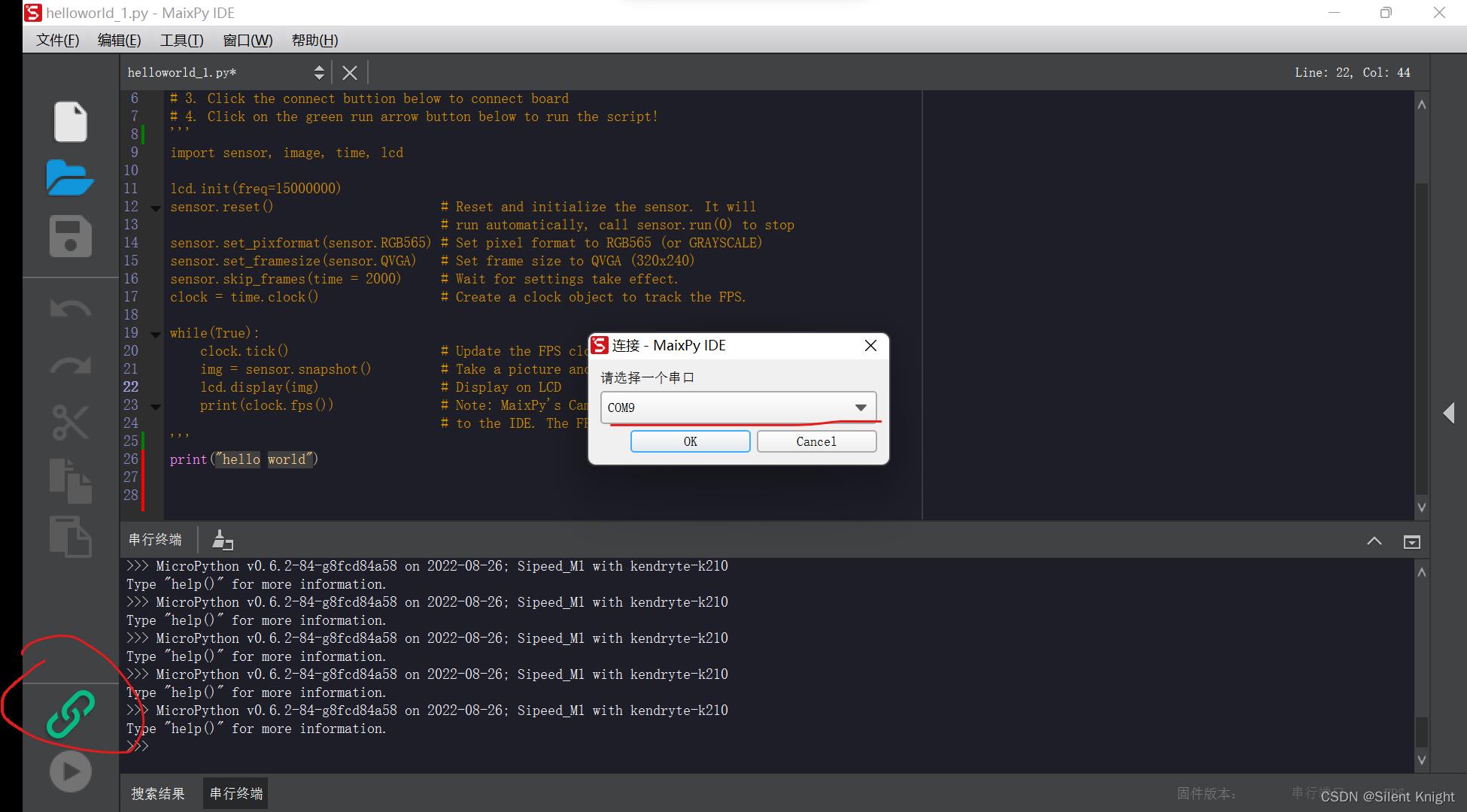
连接成功后,点击绿色的运行按钮,开发板将运行IDE中的程序,并会在调试助手输出相应信息。会输出hello world 和固件信息
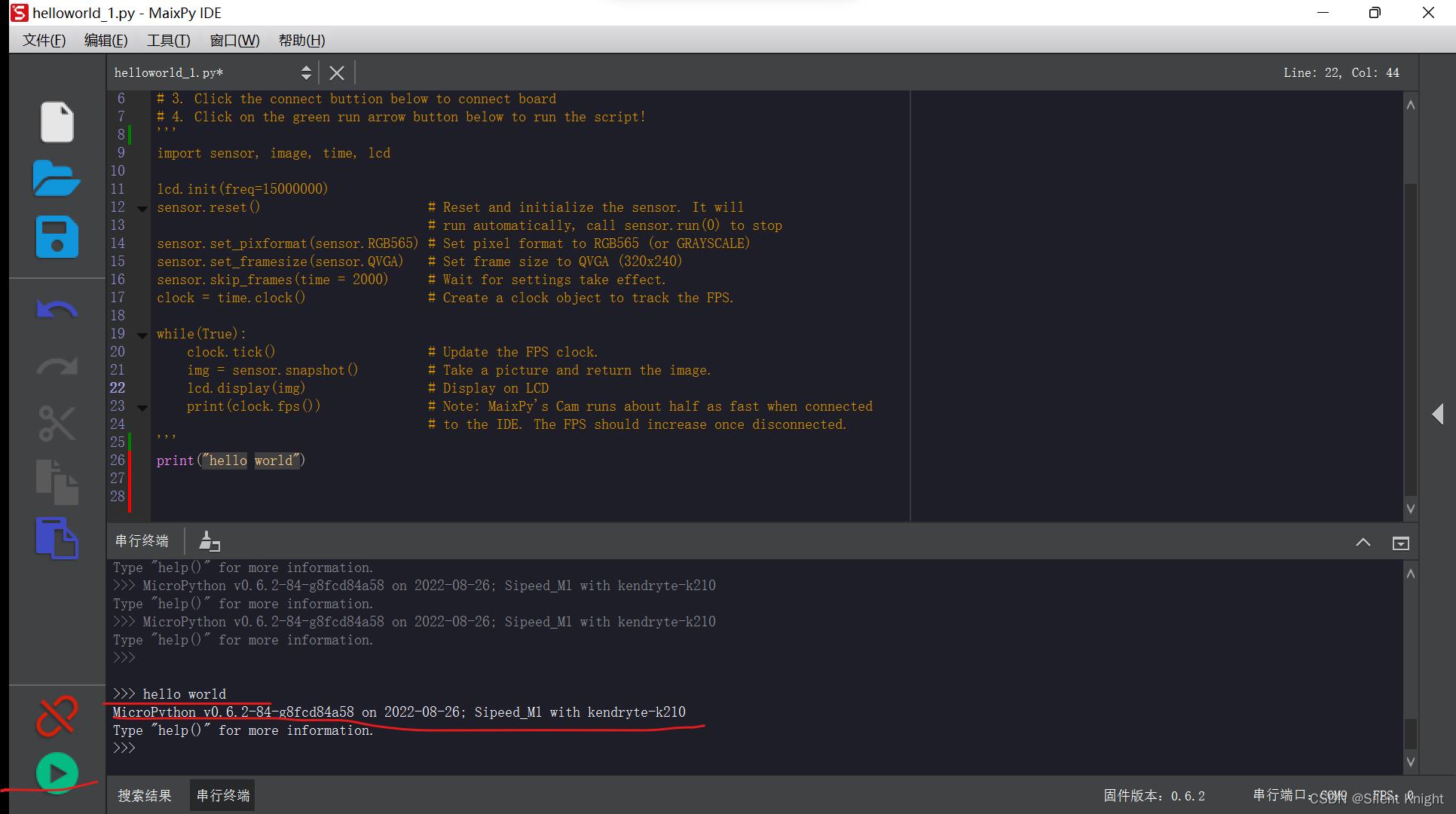
四、总结
至此,我们已经成功上手了Maix Bit这款板子,比较麻烦就是开发环境的搭建。搭建好环境,我们就能通过串口调试助手或者IDE去运行我们的第一个程序
五、参考资料
MaixPy文档简介
MaixPy精选文章
Maix Bit资料下载
Maix Bit入门视频
K210官方SDK
Sipeed开源社区
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
XML快速入门的保姆级教程!!!
简介

基础语法

<?xml version='1.0' ?><!--文档第一行必须声明-->
<users>
<user id='1'>
<name>dhy</name>
<br/><!--自闭合标签-->
</user>
<user id='2'>
<name>xpy</name>
<br/><!--自闭合标签-->
</user>
</users>
组成部分


约束

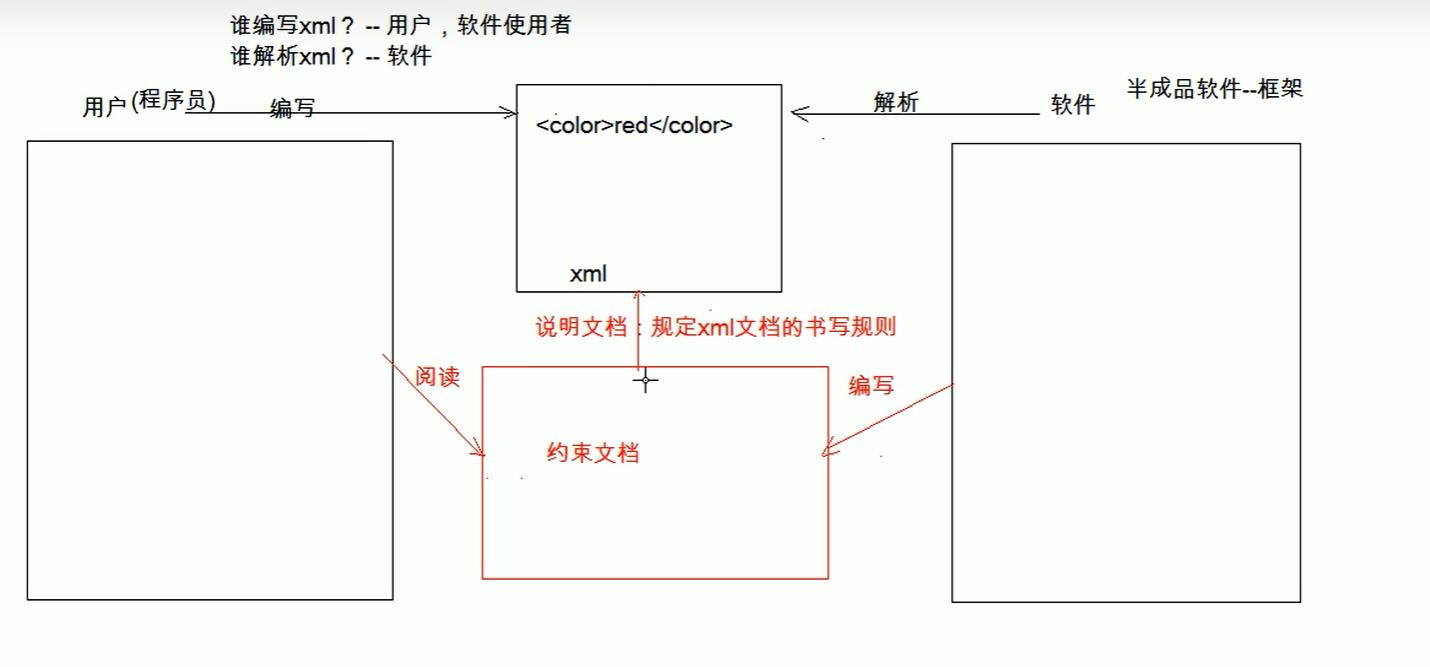
约束分类
- DTD: 一种简单的约束技术
- Schema: 一种复杂的约束技术
DTD
1.引入DTD到xml文档中
- 内部dtd,将约束规则定义在xml文档中
- 外部dtd,将约束规定定义在外部的dtd文件中

dtd:
<!--ELEMENT用来定义标签-->
<!--stus标签下能放stu子标签,又因为这里是stu+,跟正则表达式一样,这里stu子标签至少出现一次-->
<!ELEMENT stus (stu+)>
<!--stu标签里面能够出现name,age,sex标签,并且必须按照顺序出现-->
<!ELEMENT stu (name,age,sex)>
<!--PCDATA代表类型是字符串-->
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!--ATTLIST声明一个属性,stu标签有属性,属性名叫numebr,属性类型为ID,ID表名该number的属性值必须唯一-->
<!--number属性是#REQUIRED,表明该属性必须出现-->
<!ATTLIST stu number ID #REQUIRED> <!--ATTLIST用来定义属性-->
xml:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE stus SYSTEM "stu.dtd">
<stus>
<stu number="s001">
<name>dhy</name>
<age>18</age>
<sex>man</sex>
</stu>
</stus>
内部dtd用的很少,下面给出一种演示:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE stus [
<!--ELEMENT用来定义标签-->
<!--stus标签下能放stu子标签,又因为这里是stu+,跟正则表达式一样,这里stu子标签至少出现一次-->
<!ELEMENT stus (stu+)>
<!--stu标签里面能够出现name,age,sex标签,并且必须按照顺序出现-->
<!ELEMENT stu (name,age,sex)>
<!--PCDATA代表类型是字符串-->
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!--ATTLIST声明一个属性,stu标签有属性,属性名叫numebr,属性类型为ID,ID表名该number的属性值必须唯一-->
<!--number属性是#REQUIRED,表明该属性必须出现-->
<!ATTLIST stu number ID #REQUIRED> <!--ATTLIST用来定义属性-->
]>
<stus>
<stu number="s001">
<name>dhy</name>
<age>18</age>
<sex>man</sex>
</stu>
</stus>
schema
- 首先是dtd约束的局限性,schema相对于dtd来说,它可以对内容进行限定。
schema文档
* Schema:
* 引入:
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
xmlns="http://www.itcast.cn/xml">
schema的约束文档“student.xsd”
<?xml version="1.0"?>
<xsd:schema xmlns="http://www.itcast.cn/xml"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn/xml" elementFormDefault="qualified">
<xsd:element name="students" type="studentsType"/> <!--声明一个student元素,类型是studentsType,下面会定义studentsType这个类型-->
<xsd:complexType name="studentsType">
<xsd:sequence> <!--这里声明Sequence,表示按顺序出现下面元素-->
<!--下面一行声明student标签,类型为studentType类型,最少出现minOccurs 0次,最多出现maxOccurs无限次-->
<xsd:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType> <!--这里对前面定义的studentsType这个类型进行定义-->
<xsd:complexType name="studentType">
<xsd:sequence> <!--这里声明Sequence,表示按顺序出现下面元素-->
<!--下面定义3个元素,并指定这三个元素的类型-->
<xsd:element name="name" type="xsd:string"/> <!--姓名是xsd:string字符串类型,这是是schema约束规定的类型,不需要我们自定义-->
<xsd:element name="age" type="ageType" /> <!--年龄定义ageType类型-->
<xsd:element name="sex" type="sexType" /> <!--性别定义sexType类型-->
</xsd:sequence>
<!--定义student标签的属性number,类型是numberType类型,必须出现-->
<xsd:attribute name="number" type="numberType" use="required"/>
</xsd:complexType> <!--这里对前面定义的studentType这个类型进行定义-->
<!--下面3个类型是简单类型,简单类型内部不定义其他标签,并且简单类型有相应的值,可以对值进行限定-->
<xsd:simpleType name="sexType">
<xsd:restriction base="xsd:string"> <!--基本的限定类型为schema自定义的字符串string类型-->
<xsd:enumeration value="male"/> <!--使用枚举类型限定sexType类型的值,要么是female,要么是male-->
<xsd:enumeration value="female"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="ageType">
<xsd:restriction base="xsd:integer"> <!--限定ageType的值是integer类型,数字-->
<xsd:minInclusive value="0"/> <!--限制最小值是0-->
<xsd:maxInclusive value="256"/> <!--限制最大值为256-->
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="numberType">
<xsd:restriction base="xsd:string"> <!--限定numberType类型的值为字符串string类型-->
<xsd:pattern value="heima_\\d{4}"/> <!--限制这个numberType类型值的格式必须为“heima_”+4个数字-->
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
<!--schema文档本身就是一个xml文档。这个文档看起来很复杂,其实与前面的dtd文档类似-->
xml文件student.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
下面是schema文档的引入规则(比较复杂,其实我们看得懂即可,以后使用的时候配置文件一般会提供,我们修改即可)
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
显示当前约束的版本,这是一个版本的命名空间,并给这个命名空间设置前缀为xsi。这是一种固定格式
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
第二部分是当前schema约束文档的路径,并使用命名空间给schema文档的路径起一个名字。以后如果我们想要使用schema文档的元素,必须加上命名空间。
如想使用students标签,必须写作“http://www.itcast.cn/xml:students”,如果都要加上会很麻烦。因此在下面我们给命名空间加一个前缀。
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
比如我们声明一个前缀“xmlns:a="http://www.itcast.cn/xml"”,以后我们使用student.xsd约束的元素的时候,就使用a表示命名空间,如“a:students”
使用的所有student.xsd文档的文件必须都要写a:
当我们只引入一个约束文档的时候,也可以不给命名空间加前缀,而是元素前面什么都不写,默认使用了当前唯一的命名空间。
如果我们引入多个约束文档,必须给约束文档定义命名空间。而2个元素文档的标签元素可能相同,必须使用命名空间来区分这些约束。
如果使用命名空间,看起来会很长,因此我们可以给命名空间起一个前缀名,这样看起来就简洁很多
-->
<a:students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
xmlns:a="http://www.itcast.cn/xml">
<a:student number="heima_0001">
<a:name>zhangsan</a:name>
<a:age>23</a:age>
<a:sex>male</a:sex>
</a:student>
</a:students>
解析
解析:操作xml文档,将文档中的数据读取到内存中。
- 我们对xml文档会进行2种操作——解析与写入(解析使用得比较多,而写入用得比较少)
- 解析(读取):将文档中的数据读取到内存中
- 写入:将内存中的数据保存到xml文档中。持久化的存储
- 解析xml的方式:服务器端一般使用DOM思想,而在移动端会使用SAX思想。(一般标记型语言文档也是下面2类解析方式)
DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树
* 优点:操作方便,可以对文档进行CRUD的所有操作
* 缺点:占内存SAX:逐行读取,基于事件驱动的。
* 优点:不占内存。
* 缺点:只能读取,不能增删改
- xml常见的解析器:
JAXP:sun公司提供的解析器,支持dom和sax两种思想
DOM4J:一款非常优秀的解析器
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
PULL:Android操作系统内置的解析器,sax方式的。
Jsoup
- 步骤:
1. 导入jar包
2. 获取Document对象
3. 获取对应的标签Element对象
获取Document对象的方式有3种(下面代码我们使用第一种)
1) 从一个URL,文件或字符串中解析HTML;
2) 使用DOM或CSS选择器来查找、取出数据;
3) 可操作HTML元素、属性、文本;
4. 获取数据(比如我们可以获取文本内容等)
首先,同样记得将对应的jar包放入一个文件夹(如libs),并将这个文件add as library。然后我们创建java的类,使用java语言来对XML文档进行解析(java可以调用用于解析XML的相关jar包的功能,从而实现XML的解析)。
演示:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class main {
public static void main(String[] args) throws IOException {
//1、导入jsoup的相关jar包(完成)
//2、获取Document对象。我们通过xml文档来获取该文档的Document对象。
//首先通过当前的jsoupDemo1的Class对象获取类加载器,再使用类加载器的getResource方法获取相关xml文档的URL,根据URL的getPath方法获取此URL的String路径
//2.1获取student.xml的path
String path = main.class.getClassLoader().getResource("stu.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document,通过Jsoup的parse方法,同时可以指定解析字符集(字符串必须与XML文件的字符集一致)
Document dom = Jsoup.parse(new File(path), "utf-8");//这里接收File对象,必须将XML文档的path转换为File对象。
//3.获取元素对象 Element——public class Elements extends ArrayList<Element>(将Elements看做一个存放Element元素的ArrayList集合即可)
Elements elements = dom.getElementsByTag("name");
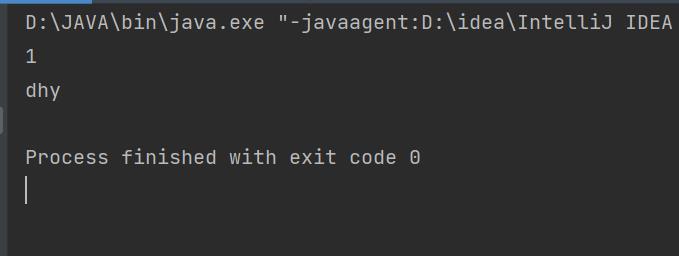
System.out.println(elements.size());//既然Elements可以看作一个ArrayList集合,长度使用size()方法
for(int x=0 ; x<elements.size() ; x++) {
//3.1获取name的Element对象
Element element = elements.get(x);//使用ArrayList集合的get方法
//3.2获取数据
String text = element.text();
System.out.println(text);
}
}
}
Jsoup:工具类,可以解析html或xml文档,返回Document对象
- parse(静态方法):解析html或xml文档,返回Document
* parse(File in, String charsetName):解析xml或html文件的。
* parse(String html):解析xml或html字符串
* parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
/**
* Jsoup对象功能:解析xml或html文档,并返回document对象
* parse方法的三个重载形式
*/
public class main {
public static void main(String[] args) throws IOException {
//1、parse(File in, String charsetName):解析xml或html文件的。
String path = main.class.getClassLoader().getResource("stu.xml").getPath();
Document doc1 = Jsoup.parse(new File(path), "utf-8");
// System.out.println(doc1);//将整个student.xml文档的内容显示出来
//2.parse(String html):解析xml或html字符串
String str = "<?xml version=\\"1.0\\" encoding=\\"UTF-8\\" ?>\\n" +
"<students>\\n" +
"\\t<student number=\\"heima_0001\\">\\n" +
"\\t\\t<name id=\\"itcast\\">\\n" +
"\\t\\t\\t<xing>张</xing>\\n" +
"\\t\\t\\t<ming>三</ming>\\n" +
"\\t\\t</name>\\n" +
"\\t\\t<age>18</age>\\n" +
"\\t\\t<sex>male</sex>\\n" +
"\\t</student>\\n" +
"\\t<student number=\\"heima_0002\\">\\n" +
"\\t\\t<name>jack</name>\\n" +
"\\t\\t<age>18</age>\\n" +
"\\t\\t<sex>female</sex>\\n" +
"\\t</student>\\n" +
"</students>";//这里直接将student.xml的内容复制过来即可
Document doc2 = Jsoup.parse(str);
// System.out.println(doc2);//将整个student.xml文档的内容显示出来
//3.parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象(多用于解析网络HTML页面)
URL url = new URL("https://baike.baidu.com/item/jsoup/9012509?fr=aladdin");//代表网络中的一个资源路径。我们在这里解析一个html页面演示
Document doc3 = Jsoup.parse(url, 10000);//第二个参数设置的是超时的时间
System.out.println(doc3);//打印出对应页面的html源代码
}
}
Document:文档对象。代表内存中的dom树(Document对象继承Elements对象,其获取Elements的方法也是继承自这个Elements对象)
- 在XML中,Document对象主要用来获取Element对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
代码演示:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class main {
public static void main(String[] args) throws IOException {
//获取Document对象
String path = main.class.getClassLoader().getResource("stu.xml").getPath();
Document doc = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象了。
//3.1获取所有student对象的Elements集合
Elements elements = doc.getElementsByTag("student");
// System.out.println(elements);//打印出2个student对象的源代码
System.out.println("-----------");
//3.2根据id的属性值,获取相应的的元素对象的集合(返回单个的Elements对象,因为id的值唯一)
Element ly = doc.getElementById("ly");
// System.out.println(ly);//打印id值为“ly”的元素的代码
System.out.println("-----------");
//3.3 获取属性名为id的元素对象们(既获取包含id属性的标签)
Elements elements1 = doc.getElementsByAttribute("id");
// System.out.println(elements1);//只要标签中有包含id属性,就都会被打印出来
System.out.println("-----------");
//3.4获取 number属性值为s001的元素对象
Elements elements2 = doc.getElementsByAttributeValue("number", "s001");//根据标签属性以及属性值查找标签
System.out.println(elements2);//属性值number值为“s001”的标签会被打印
System.out.println("-----------");以上是关于Maix Bit(K210)保姆级入门上手教程---环境搭建的主要内容,如果未能解决你的问题,请参考以下文章
神器!200元开发板运行神经网络模型,吊打OpenMV!(保姆级教程)