Linux伪分布式安装Hadoop2.7.7
Posted 一位不愿透露姓名的肥宅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux伪分布式安装Hadoop2.7.7相关的知识,希望对你有一定的参考价值。
1、上传并解压压缩包
使用Finalshell或idea等链接工具上传安装包至安装目录
解压压缩包
#进入安装目录
cd /soft # /soft 改为你的安装目录
#解压安装包
tar -zxvf hadoop-2.7.7.tar.gz
#重命名文件夹
mv hadoop-2.7.7 hadoop2、修改配置文件
需要修改5个配置文件,进入hadoop目录下的的etc/hadoop目录
cd /soft/hadoop/etc/hadoop配置hadoop-env.sh文件,指定hadoop运行时jdk的路径
vim hadoop-env.sh
export JAVA_HOME=/soft/jdk配置core-site.xml文件,配置hadoop的文件系统
<!--配置hdfs的namenode的地址,使用的时hdfs协议-->
<property>
<name>fs.defaultFS</name>
<!-- hadoop是你自己配置的主机名,代表当前虚拟机 -->
<value>hdfs://hadoop:9000</value>
</property>
<!--配置hadoop运行时产生数据的存储目录, 不是临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/soft/data/hadoop/tmp</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>配置 hdsf-site.xml文件,配置文件系统的文件备份数量,这里伪分布式只有一台机器所以配置为1
<property>
<name>dfs.replication</name>
<value>1</value>
</property>配置mapred-site.xml文件,指定mapreduce程序运行在yarn上
<!--指定mapreduce运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>配置yarn-site.xml文件,指定yarn集群的resourcemanager地址
<!--指定resourcemanager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>iZm5efuuoqohgx35d3zs4eZ</value>
</property>
<!--指定mapreduce执行shuffle时获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://0.0.0.0:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>3、启动脚本配置与修改环境变量
1.编辑start-dsf.sh 和stop-dsf.sh 文件
cd /soft/hadoop/sbin
#在start-dsf.sh 和stop-dsf.sh 文件中加入以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root2.编辑start-yarn.sh 文件和stop-yarn.sh
#在start-yarn.sh和stop-yarn.sh 文件中加入以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root3.配置环境变量
vim /etc/profile
#hadoop
export HADOOP_HOME=/soft/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH4.重新加载配置文件
source /etc/profile4、初始化并启动
初始化hdfs
hdfs namenode -format启动hadoop
start-all.sh启动成功后使用jps命令可以看到以下进程
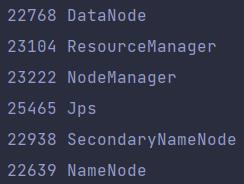
使用浏览器访问虚拟机的50070端口,如果访问成功,则说明伪分布式环境搭建成功
以上是关于Linux伪分布式安装Hadoop2.7.7的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop2.7.7 centos7 完全分布式 配置与问题随记
Hadoop2.7.7 API: yarn-site.xml 解析