Masked Autoencoders Are Scalable Vision Learners 论文研读
Posted herosunly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Masked Autoencoders Are Scalable Vision Learners 论文研读相关的知识,希望对你有一定的参考价值。
| NLP | CV |
|---|---|
| Transformer | ViT |
| BERT | MAE |
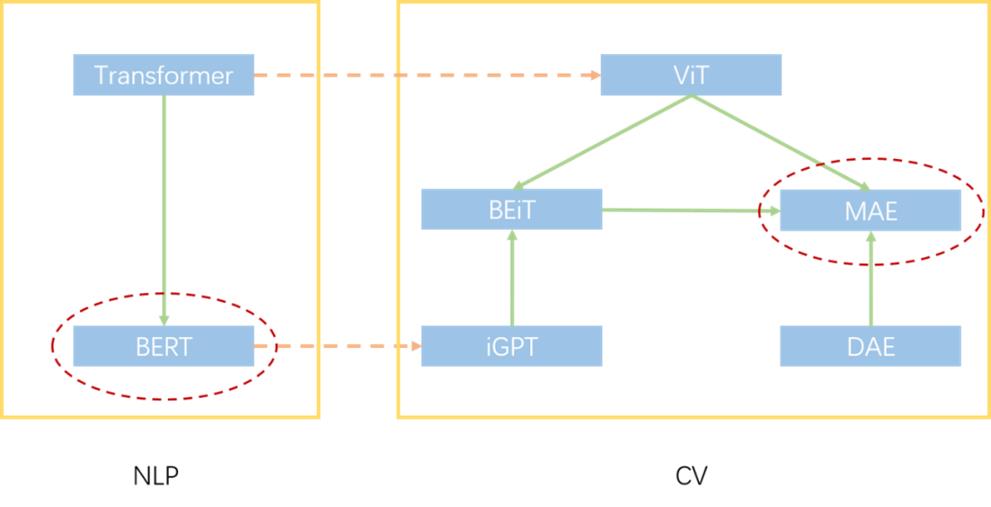
1. 标题
Masked Autoencoders Are Scalable Vision Learners指的是带掩码的自编码器是可扩展的视觉学习器。其中这里的Autoencoders指的是模型的输入和输出都是相同的,简单来说Autoencoder=encoder+decoder。
作者其中包括了ResNet的第一作者何恺明大神。
2. 摘要
MAE的方法比较简单:对输入图片进行随机块的mask,然后对mask块中的像素进行重构。核心设计主要是源于两点。
第一,设计了非对称的编码器和解码器架构,其中编码器仅对没有进行mask的区域进行编码,解码器是轻量级的,能够重构原始的图片。
第二,如果对图片中绝大多数的区域进行mask,比如75%,就会得到一个很有意义的自监督任务。
通过上述两个设计,就能够更加有效地训练大模型,如训练速度提升3倍,并且提高训练的精度。
在ViT-Huge的模型中仅仅使用100W的数据就能得到(87.8%)的准确率。在下游任务进行迁移学习的效果优于有监督的预训练。
3. 模型架构
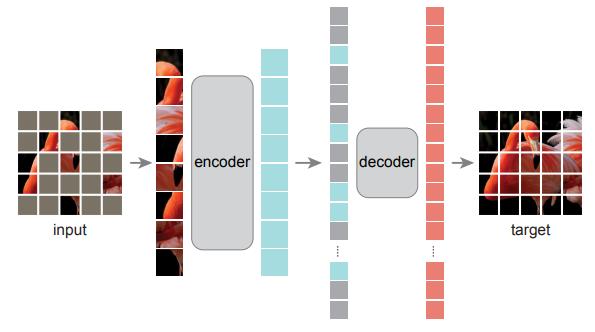
其中masked的块被涂成灰色(绝大部分)。将没有masked的区域作为encoder(ViT)的输入,将其输出填入到新构建的长向量中。灰色部分只包含了位置向量填入到新构建的长向量中。然后将长向量输入到decoder中,最终还原出整个原来的图片。encoder的模型复杂度大于decoder。
4. 结论
简单的算法具有一定的扩展性,是深度学习的核心。在NLP中,简单的自监督学习方法得到了成功的应用。但在计算机视觉中,预训练范式绝大多数还是有监督的方法。在本研究中,使用了autoencoder进行类似于NLP的自监督学习。
在另一方面,由于图像和语言数据的本质并不相同,所以必须谨慎进行处理。在NLP中,一个词是一个语义的单元,包含的语义信息是比较多的。在图像中,虽然每个patch包含一定的语义信息。但它并不是一个语义的segment。MAE能够学习到比较好的语义表达。
以上是关于Masked Autoencoders Are Scalable Vision Learners 论文研读的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch笔记 - MAE: Masked Autoencoders Are Scalable Vision Learners
PyTorch笔记 - MAE: Masked Autoencoders Are Scalable Vision Learners
PyTorch笔记 - MAE: Masked Autoencoders Are Scalable Vision Learners
论文笔记: Masked Autoencoders Are Scalable Vision Learners