论文笔记: Masked Autoencoders Are Scalable Vision Learners
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记: Masked Autoencoders Are Scalable Vision Learners相关的知识,希望对你有一定的参考价值。
1 整体思路
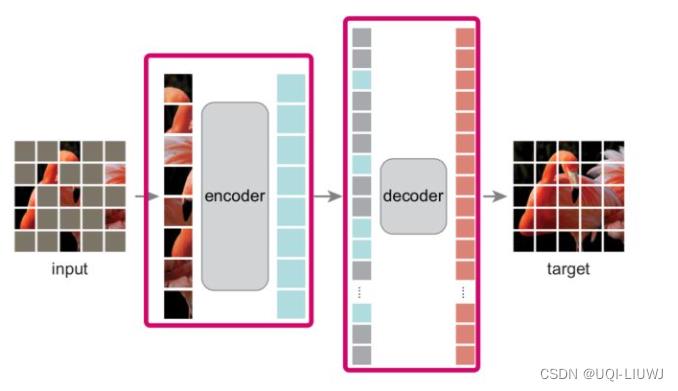
- 效仿BERT中MLM的思路,随机mask掉输入图像的部分patch,并重建这些被mask掉的patch
机器学习笔记: ELMO BERT_UQI-LIUWJ的博客-CSDN博客
- 模型结构是一个非对称的encoder-decoder
- encoder仅在可见的(没有被mask的)patch上运行
- 使用ViT
- 和ViT类似,也是通过线性映射和位置编码,来得到patch的embedding(输入)‘
- 通过一系列transformer block处理结果集
- 仅编码器用于生成图像表示
- 轻量级decoder从潜在表示和masked token上重建原始图像
- 输入是由一下两块组成
- 经过encoder编码的未被mask的patch
- masked tokens
- 每个masked token都是一个共享的学习向量,表示要预测的缺失patch
- 具有另一系列Transformer模块
- 仅在预训练期间用于执行图像重构任务
- ——>解码器可以以独立于编码器设计的方式灵活地设计
- 输入是由一下两块组成
- encoder仅在可见的(没有被mask的)patch上运行
- 损失函数计算像素空间中重建图像和原始图像之间的均方误差(MSE):只计算被mask的patch的损失,类似于BERT
2 实验结果

以上是关于论文笔记: Masked Autoencoders Are Scalable Vision Learners的主要内容,如果未能解决你的问题,请参考以下文章
Masked Autoencoders Are Scalable Vision Learners 论文研读
ConvMAE:Masked Convolution 遇到 Masked Autoencoders
PyTorch笔记 - MAE(Masked Autoencoders) PyTorch源码
PyTorch笔记 - MAE(Masked Autoencoders) PyTorch源码
PyTorch笔记 - MAE(Masked Autoencoders) PyTorch源码
PyTorch笔记 - MAE: Masked Autoencoders Are Scalable Vision Learners