视频编码器的智能化——AI辅助编解码的ASIC解决方案
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频编码器的智能化——AI辅助编解码的ASIC解决方案相关的知识,希望对你有一定的参考价值。

点击上方“LiveVideoStack”关注我们
在此次LiveVideoStackCon 2021 音视频技术大会 北京站,来自镕铭半导体的刘迅思详细列举了目前常用的AI辅助编解码的方法,论述如何在硬件和软件层面将AI结合编解码的实践,探索新的标准和新一代编码器结合AI应该如何设计。
文 | 刘迅思
整理 | LiveVideoStack
大家好,我是来自NETINT镕铭半导体的刘迅思,本次要跟大家分享的主题是视频编码器的智能化。
为什么要分享这个话题?直白的说主要的是为了带货,因为目前公司最新推出了基于带有AI功能的硬件ASIC编码器、编码卡,当然更重要的是我们觉得它也是未来视频编解码一个很重要的方向。
我知道来LiveVideoStackCon 音视频技术大会的老师,可能很多都是做AI算法、编码算法,或是应用开发的。作为一家芯片公司,打个比方,我们就有点像是“种菜”的,诸位老师就像是“大厨”,我一个“种菜”的和大家说种出来的菜能做成什么样的美食,很容易得到一些不信任的目光。说到这个也很有意思,前两天看到LVS的一位讲师的朋友圈,提到之前写PPT的时候非常谨慎,咨询很多专家,总是担心PPT内有什么错误,但现在却不像之前那样,为什么呢?他说,现在更欢迎听众来提出一些不同的意见。对我来说其实也是一样的,非常期待大家听完能有一些反馈给到我们。这其实也是公司三年以来在国内跟数据中心的客户合作的一种模式,因为客户很多都是业务方、应用方,我们会反馈给客户更多底层的信息,客户也同样反馈给我们很多应用端的信息,互相协作可以把事情做得很好。

本次分享的内容主要有以下几点:首先是我们理解的AI辅助编码在学术界研究的主要方向;其次是正在落地的商业化实践;还会基于以上内容,分享ASIC编码器在软硬件实现上有什么样的区别;接着会介绍ASIC编码器的优势场景;最后会跟大家探讨一下未来基于ASIC以及基于硬件的视频编解码器应该是什么样子。
1. 研究方向
首先,介绍学术界的一些研究方向。

总的来说,可分为两大类:一类是基于传统的,也就是264、265,基于残差,基于DCT变换来开发一些编码的工具,并且我们还会在每一个编码工具上基于神经网络来做一些优化;而另外一类,则是完全抛开这些工具,直接使用神经网络来做编解码的压缩。
1.1像素概率建模
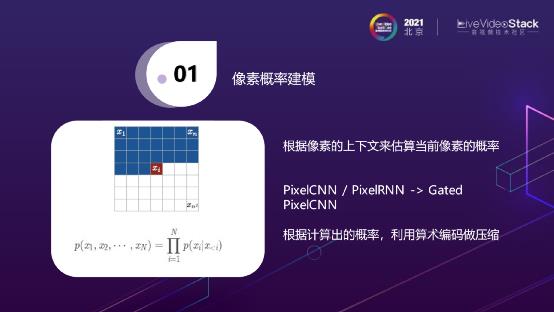
第一种是像素概率建模。其原理是,它认为每一个像素点其实是可以根据上下文的一些像素的概率估算出来的,比如 ,当前像素值可以根据它之前
,当前像素值可以根据它之前 一直到
一直到 的这些值的概率,做一个联合概率,计算得出
的这些值的概率,做一个联合概率,计算得出 的值。比较著名的一些神经网络,如最早发布的PixelCNN和PixelRNN,这是两个不同的算子,用CNN和RNN来做像素概率建模,后续又有了Gated PixelCNN,或者叫conditional PixelCNN。
的值。比较著名的一些神经网络,如最早发布的PixelCNN和PixelRNN,这是两个不同的算子,用CNN和RNN来做像素概率建模,后续又有了Gated PixelCNN,或者叫conditional PixelCNN。
其实在做像素概率建模的时候需要一个掩模,它的原理是从之前的像素来推断出当前像素,这就意味着在计算时,需要将后续的像素点做掩模遮蔽掉,但在遮蔽的时候有可能会挡住之前一些像素点,造成一些盲点,Gated PixelCNN就是为了解决盲点的问题。说起来感觉可能比较复杂,这个算法其实是有比较常见的应用的,像大家可能用过一些APP是拍摄一张自己现在的照片,然后可以推算出当你七十岁时会长成什么样子,这就是用上述算法来实现的。它其实最早是用来做图像生成的,用于编解码时,之前看到有的paper会这么做,用像素概率建模来预测当前图片的预测值,然后根据图片的真实值,用真实值减去预测值得到残差。我们对残差做编码,然后在解码端用像素概率建模来恢复整个图像,再将残差添加回去。
1.2AutoEncoder、Variational Auto-Encoder(VAE)

另外很大的一类就是AutoEncoder,它的原理是通过无监督学习来做编解码。这个模型也比较简单,一个 输入后先做encoder,通过不同的卷积提取出这一帧图片的高维数据特征,然后用decoder将其还原,还原后进行输出。在做无监督学习时,我们的最终目标是输出和输入之间的差值最小,所以需要不停地训练encoder和decoder之间卷积网络的参数,将差值做到最小。当然,其中也有很多不同的做法,有的是用不同的算子,CNN、RNN,用双向RNN、LSTM等来做。另外,还有代价函数的不同,有的是用MSE(均方差)来做,有的是用MS-SSIM来做差值。
输入后先做encoder,通过不同的卷积提取出这一帧图片的高维数据特征,然后用decoder将其还原,还原后进行输出。在做无监督学习时,我们的最终目标是输出和输入之间的差值最小,所以需要不停地训练encoder和decoder之间卷积网络的参数,将差值做到最小。当然,其中也有很多不同的做法,有的是用不同的算子,CNN、RNN,用双向RNN、LSTM等来做。另外,还有代价函数的不同,有的是用MSE(均方差)来做,有的是用MS-SSIM来做差值。
这个模型最大的问题是很容易会欠拟合,因为它的参数很多,输出和输入之间可能会没办法训练出很好的模型。基于这个,有人提出在encoder之后可以做一步量化,在decoder之后做一步反量化。此时我们看到如图公式是一个典型的RDO公式,D是输入和输出的差值,λ是拉格朗日常数,R是根据不同量化取得的值,这个公式的意义就是在量化一定的情况下保证差值最小。
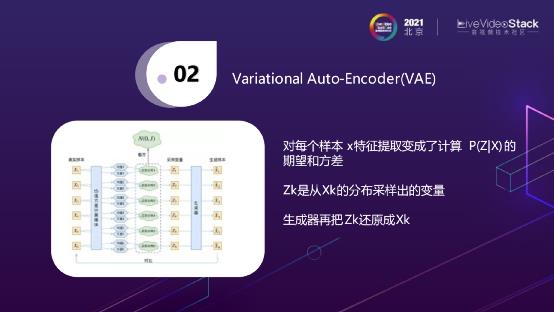
Variational Auto-Encoder(VAE)是一种变形的AutoEncoder,刚刚讲到AutoEncoder是使用卷积来做,做完以后会得到一个高维的矩阵,保存了它所有的特征。而VAE的做法则是在每个样本输入后,会得到一个均值和方差,它认为每个样本其实是正态分布的,有了均值和方差就能画出一个正态分布的函数。那么在这个正态分布的函数里就可以采样它的变量,相当于每个 会对应出一个
会对应出一个 ,在解码器生成的时候再把
,在解码器生成的时候再把 还原成一个真实的样本。
还原成一个真实的样本。
1.3光流估计

前面提到的是AutoEncoder,还有一个最近比较热门的就是光流估计。
光流估计之前很多都是用OpenCV的方法来做,比较稀疏的光流可以用传统的图像算法来做光流估计,与传统的编解码算法有点像,编解码算法我们也会做运动补偿和运动估计,但编解码是基于宏块或者根据CU来做运动估计的。光流估计是会对每一个像素点都会预测它的光流,因为是用一整个卷积来计算整个的光流,它认为每一个像素点都能计算出它的光流。之前比较有名的光流估计的模型是FlowNet2,大家有兴趣的可以了解一下。光流估计中有一个比较大的问题是如何产生有光流真值的训练图片,也就是在训练的时候如何确定训练出来的图片的光流值是对的,所以很多人会用显卡生成一些假的图像来做训练。
1.4感知编码

如图是感知编码一个比较典型的应用,在视频会议开始时只要传送每一位与会者的面部照片,后续只要告诉解码器某一与会者的头是向左转或向右转,解码端基于对抗网络就可以生成这名与会者所对应动作的视频。在传输时只需要将关键帧用传统编码器进行编码,在解码端使用对抗网络生成图片,并用关键帧来做训练,实际输出效果与H.264相比可以降低非常多的码率。
1.5语义编码
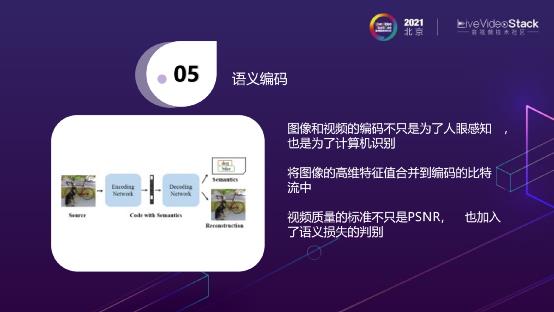
目前存在的编码,无论是视频或是图片,它其实不仅仅是给人眼看的,有很多是直接用来输出给AI的。我们在传输传统图片信息之外,还需要传输一些高维的特征值。举个例子,这里有一辆车和一只狗,在编码完成之后,在decoder时不仅仅可以decoder出画面,同时也可以decoder出之前物体识别的信息结果,即图片中有一辆车和一只狗。
未来视频质量评价的标准可能不仅仅是PSNR、SSIM,图像也会加入语义损失的判断,即图像或视频经过压缩之后是否会产生语义的损失。
1.6传统编码工具的优化
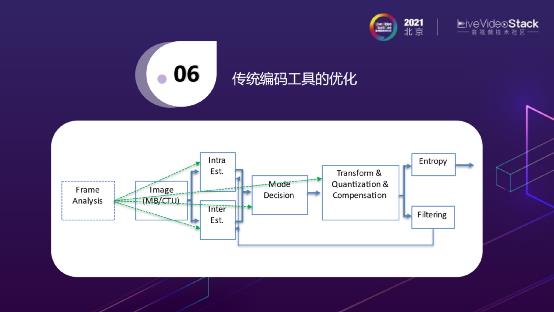
接下来介绍基于传统编码工具的优化。如上图所示,传统编码算法无论是264还是265,一个Image输入进来,首先需要进行帧间或帧内的预测,然后要做Mode Decision确定到底选哪一种方式,然后做量化、做Transform,最后还做环内的滤波,做Entropy去编出bitrate。

在每一个编码工具的模块上面其实都会有一些AI的方法来进行优化。如帧内预测时,有人提出用CNN优化预测模式。标准规定的预测范围其实很小,使用CNN可以扩大预测范围;帧间预测时,双向参考块我们现在一般的做法都是采用线性的组合,乘上一个固定的比例算出当前预测块的值。那是不是除了线性组合,我们还可以用CNN来做一些非线性的组合。另外,插值的时候,不是简单的做一些半像素的插值,是不是可以利用CNN进行半像素插值;另外还有一个比较有意思的方向就是跨通道的预测,就是说一个YUV的视频,可能只知道Y值,怎么才能推断出它的U值和V值?在这点上,AV1有一个标准是Cfl,HEVC有一个CCP的扩展标准,来做跨通道预测。既然是做预测,那么大家可能也会想到用CNN来做一些非线性、跨通道的预测。

此外刚刚说到变换,也有使用CNN做预处理,训练出类似ICT变换的图像变换。我相信除了这些以外,有很大一块AI辅助编解码的工作其实是用来做滤波的。滤波分环外滤波和环内滤波,区别在于解码端输出滤波完的图片,是不是会用来做参考帧,如果不做参考帧,就是环外滤波,做参考帧就是环内滤波。那这里就有很多学术界的方法来实现,其实它基本上是基于不同的输入,输入的时候不光输入YUV,还要输入QP、 block info、 解码帧、相邻帧输入、残差、帧内预测信号,根据这些做滤波输出不一样的效果。环内滤波主要讲HEVC,因为环内滤波分DF和SAO,在不同的阶段会插入不同的网络,有的是在DF和SAO之间,有点是在DF之前,有的是在SAO之后。这个理念一个是说根据不同的QP我要训练出不同的滤波的网络来,不像现在SAO只有一个模型来做滤波,可能基于不同的QP来做,另一个是基于不同的Loss来做。
2. 商业化实践

前面提到的是一些学术界的研究,Paper有很多,下面会介绍一些商业化落地的实践。

分了这几个类型,有做预处理的,有做ROI、超分辨率、逆色调映射、码率自适应算法优化的。
2.1预处理优化

做预处理AI的其实有很多,分大类的话有视频降噪、背景替换、内容审核、场景检测。这个图是很典型的做背景替换的,把背景抠出来之后直接做背景替换。这个功能其实在我们自己新一代的产品, Quadra芯片当中我们也实现了这个功能。
2.2ROI感兴趣区域编码

这个也是我们真实的,在新一代Quadra上跑的一个实时的视频,做了ROI感兴趣区域,上图是两个视频里面截取的两帧,都是500kbp/s的视频,我们用YOLOv4 (p2 5:55)对图片中每一个人脸都做了划区域,可以看到右边这一张图特别是这个女生的脸,跟左边这一张图比就会差很多,这就是我们划完以后对人脸设定了一些比较低的QP,然后来做一些精细化的处理。
2.3超分辨率

另外还有很大的一类是做超分。左边是一个EGVSR,不是很新的超分模型,但是效果很好,对计算量的要求其实比较低。超分是分图像的超分还有视频的超分两类。图像的超分最早的就是SRCNN,这是最早提出用CNN网络来做超分的一个Paper,这个模型最早是说把一个低分辨率的视频收进来以后,先把它扩大成一个高分辨率的视频,然后再来做计算。在这个基础上后来又推出了FSRCNN,就是说进来的视频不需要放大,基于低分辨率的视频先做卷积,最后会做一个反卷积来吧低分辨率的视频变成高分辨率的视频。ESPCN也是类似的做法,也是直接在一个低分辨率的视频下面去做一些特征的一些计算。后续也有用对抗网络来做超分,DRCN是用RNN来做超分,就是不同的算子来做超分。
除了这些大家也知道其实对视频来说最大的压缩不是在图像的本身上面,最大的压缩是在帧间信息上面,基于这个也有专门针对视频的一些超分算法,有的是做运动补偿,就是我基于目前的这一帧和它相邻的这一帧,因为用AI,所以就用光流估计做出每一个像素点运动的估计和补偿,相当于当前的这一帧我先基于它的图像做一次超分,然后再用帧间的运动补偿来做一次残差的计算,然后我把当前图像的超分加上残差来做视频间的超分。另外一种方法其实更彻底,前面那种运动补偿还有点像264、265,后面这种更彻底,不需要去对齐相邻帧和当前帧的运动补偿,我在网络中输入的时候不是输一帧,而是输好几帧进去,直接通过网络取空间和时间信息来做超分。
2.4逆色调映射

逆色调映射说起来可能没人听得懂,但是其实说白了就是怎么把一个SDR的视频转成HDR的视频。
我归纳下来,其实它最主要解决的问题就是这三点:SDR到HDR它的亮度范围扩展、另外是它的色域从BT.709变成BT.2020色域转换、8bit 位宽转 10 bit。这里面有很多神经网络来做逆色调映射。
2.5码率自适应算法优化

这个可能跟编码算法的关系可能就不大了,它是用来做码率自适应算法的。之前快手发表了一个很好的论文,专门讲码率自适应算法。码率自适应其实分两种,一种是Buffer-based,就是基于客户端的播放缓冲区buffer情况决策。其实都是基于客户端,Rate-based则是基于预测的带宽决策。基本上基于AI的都是用Buffer-based来做这个事情的,这个是说客户端会去看自己的当前buffer的缓存区,当缓存区比较小的时候,说明带宽其实不够,所以会把bitrate调小,buffer比较大的时候说明带宽很高,那又会把bitrate调高。基于这样一个决策。
但是这个决策往往很多时候会失败,因为它这时候没办法预测下一次网络的带宽是什么样的情况,可能就会想这种情况下就基于强化学习的算法来做一个码率自适应的ABR的算法优化。
左边就是一种类型的强化学习的算法,它是做Actor和Critic的一个算法,Actor它会根据不同的策略take action,会进入不同的state,critic会根据不同的state和action去打分,然后告诉Actor你下一次要怎么做,基本上是这样一个做法。
3. 软硬件实现
后面讲的是我们的本行,我们的软硬件的实现是怎么做的。

NETINT其实实在这个月,我们开始开放给客户正式的测试,就是我们新一代的Quadra的芯片。
3.1硬件架构
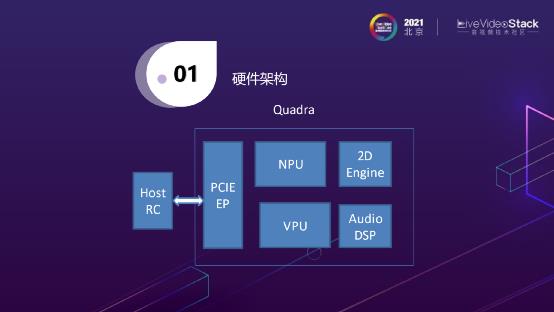
这个硬件架构比较简单。我们这个Quadra的芯片是为了编解码专门设计的一个芯片,我们一开始的目的是做硬件编解码,当然之前三年在跟客户交流的业务沟通过程中,我们发现了除了编解码之外我们还需要加一些其他的硬件模块,所以我们在里面会加入一个NPU,也会有Audio DSP来做视、音频的编解码,除了这个,还有2D的引擎来做旋转、缩放、加水印这些硬件加速的工作。Host端这边沿用上一代产品的NVM标准的存储协议来交互。
3.2软件架构
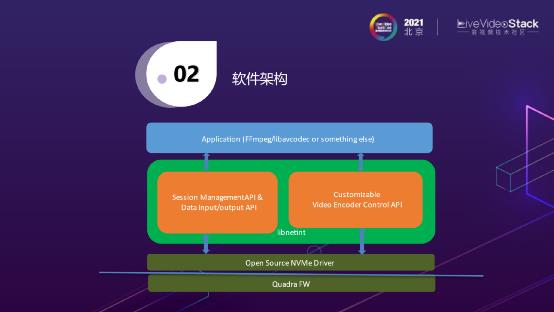
这是它的软件架构,这样做的好处是底层为Quadra FW,用户端是不需要装驱动的,可以使用标准的Open Source NVMe驱动,无论是Linux、Windows还是android系统。并且基本适配于所有的CPU和OS,包括国产的一些OS,因为它们都有NVMe的存储驱动;在此之上我们会提供一个libnetint的API库,主要做一些不同实例的管理、参数的设置;最上层会支持FFmpeg的框架来调用。编解码是这样的一个架构,AI也是一样的,因为我们的AI是为了服务编解码的,所以我们会在FFmpeg中加入一些Filter,来做AI的计算。
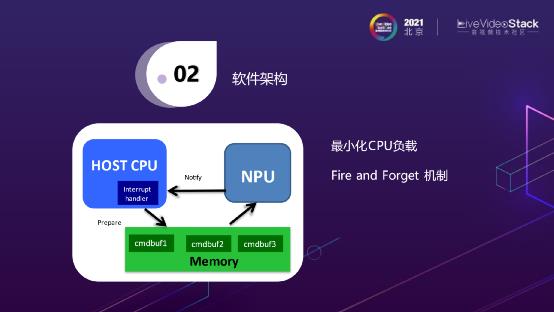
这个是我们之前设计的一个方法,其实不仅仅是NPU,CPU也是一样的,我们应该如何最小化CPU的负载,所有我们有一个Fire and Forget 机制,即后置PC在准备完一些cmdbuf,打给NPU以后是不会再作等待的,是一个异步的调用。直到NPU有一些中断过来时,后置PC才会做这些回调的处理。
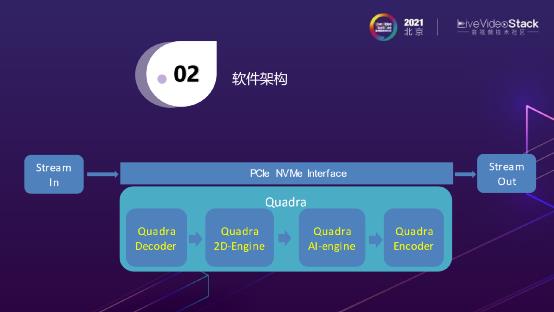
如图是整个数据流,Stream进来后,通过PCIe NVMe Interface,其中所有的东西都是在我们的芯片当中完成的,从Decoder开始到缩放,到AI-engine,计算完成后再Encoder,最后出去的是一个Stream Out,在这中间是完全不需要CPU参与,也不需要和主机进行交互的。
4. 优势场景
接下来会介绍到我们认为的基于ASIC的硬件编码,在哪些场景下比较具有优势。

对于我们来说,首先要解决的问题是确定我们到底要做强编码的产品还是强AI的产品?本次分享的主要是AI辅助编码,对于我们来说,还是以编码为主,AI来做辅助,这也就牵扯到芯片中到底要有多大的AI算力来配多大的编码密度。因为芯片是一个面积和功耗强相关的东西,当我们将功耗控制到一定程度时可以做高密度的使用。目前我们Quadra单卡的功耗是在25W以下,这意味着可以做成u.2的形式,之前我们有配置服务器多的时候可以插24张卡,形成一个高密度编码的整机的服务器,所以对于我们来说,最终答案是选择提供合适的AI算力,主要强调编码功能。
第二点是高密度和虚拟化,高密度意味着我们在计算TCO的时候并不是算每一张卡的编码成本,而是计算服务器加上卡的编码成本。除此之外,做硬件虚拟化就是我们通过一些虚拟化的支持,不管是SR-IOV,将一张卡虚拟成多个设备给不同的虚拟机用,还是做成一个编码池,将整个编码池提供给不同的虚拟机用。这些都是通过硬件来做虚拟化的,代价会比较低。
还有一个最大的场景,也就是低延迟的场景,这是硬件编码器与软件编码器相比最具有优势的场景。低延迟不仅仅是指它的延迟比较低,另外延迟也是恒定的,不管这一帧有多复杂,它的延迟都是恒定的,这对一些特殊的业务来说好处是非常大的,如云桌面、云游戏。
另外,还有4K/8K 高分辨率。当分辨率达到4K/8K时,编码的标准可能已经不能用了264了,需要用到265,甚至更高的一些编码标准来做编码,此时对CPU的算力要求会非常大,此时ASIC编码器硬件成本的优势就会体现出来。
最后一点我们深有体会,其实就算是做直播的客户,做转码系统的客户,大部分的精力也并不是花在编解码上,而是会花在媒资管理、分布式存储、推流拉流、以及任务调度中。因为这是其核心业务,将编码的东西交由硬件来做,客户可以更聚焦业务。这也是我们觉得硬件编码器比较有优势的一个地方。
5. 未来
最后探讨一下未来,这其实是一个开放的话题,即未来的硬件编码器会是什么样子?
就像新一代的芯片一样,不仅仅包含编解码,而且已经在加入AI相关的功能,后续是不是还会有一些新的硬件功能融入进来,这是一个值得思考的问题。另外一个问题是说,未来的编码器是不是还会像现在一样只提供一些数据流的推送,只提供一些不同编码格式的选择,还是说可以将整个基本的编码工具暴露给客户。因为我们觉得编解码是计算模式相对固定,但算力消耗越来越大的东西,倒推20年,大家觉得有什么事情是这样的?就是图像渲染,所以有了GPU出现。OpenGL是一套非常好的工具,它将GPU图像渲染中需要做的一些场景抽象出来,形成各种各样的API,通过调用API就可以实现图像渲染中所有的逻辑。那么,对于编解码来说,是不是也有这样的一套框架,这就是我们所想的未来硬件编码器的样子。
讲师招募
LiveVideoStackCon 2022 音视频技术大会 上海站,正在面向社会公开招募讲师,无论你所处的公司大小,title高低,老鸟还是菜鸟,只要你的内容对技术人有帮助,其他都是次要的。欢迎通过 speaker@livevideostack.com 提交个人资料及议题描述,我们将会在24小时内给予反馈。
喜欢我们的内容就点个“在看”吧!

以上是关于视频编码器的智能化——AI辅助编解码的ASIC解决方案的主要内容,如果未能解决你的问题,请参考以下文章
视频物联网智能编码,机器视觉编码新体系,AI Image Codec,走向实用的AI图像编解码...
SoundStream VS Lyra: 谷歌今年新推出的两款AI音频编解码器有何不同?