实时音频编解码之十九 基于AI的语音编码(LPCNet)
Posted shichaog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时音频编解码之十九 基于AI的语音编码(LPCNet)相关的知识,希望对你有一定的参考价值。
本文谢绝任何形式转载,谢谢。
自2012年Opus编码器推出以来经过近10年,2020年的新冠大流行使得实时音视频会议和虚拟增强会议需求进一步增加,Opus是这类场景中非常优秀的音频编码器,但AI技术可以进一步提升音视频效果。
Satin
Satin是微软于2021年2月官宣的一款基于AI的语音编码器,其目标是替代Silk编码器,Silk是Skype使用的语音编码器,Opus中LPC部分也是基于Silk编码器,Satin的特性如下:
从6kbps开始可以支持超带宽语音
从17kbps开始可以支持全带宽语音
更高的比特率可以带来更好的编码质量
即使在高丢包率的情况下音频质量依然很高
更好的冗余算法,在突发丢失情况下提供更好的保护
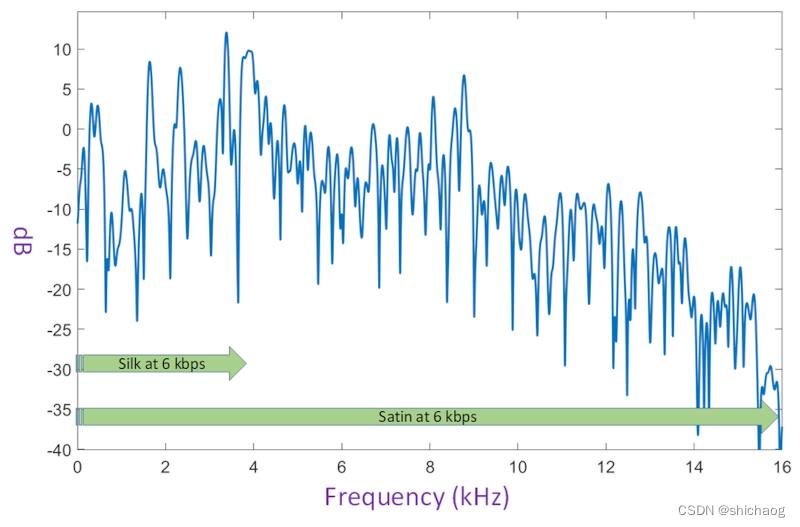
Satin已经在微软Teams和Skype的双向通话中使用,显然未来是会扩展到多人通话中。Satin的目标是替换掉Silk/Opus编码器。
为了在6kbps码率下达到超带宽,Satin根据对语音产生、建模和心理声学的深入理解来提取和编码信号的稀疏表示,在进一步降低所需比特率时,Satin仅对较低频带进行编码和传输某些参数,在解码侧,Satin使用深度学习网络从接收到的低频带参数以及附加信息估计高频带参数,这种方法虽然使用超低比特率编码超带宽信号,但是计算复杂度大大提高。分析输入语音信号以提取低维表示需要大量计算,在深度神经网络上进行实时推理会增加更多的复杂性。

和其他编码器相比,Satin独立编码各个包,所以丢失一个包并不会影响后续包的编解码质量,由于Satin能够以6kbps的低速率提供出色的音频,因此可以灵活使用增加比特率来添加冗余和前向纠错,以便快速恢复丢包。
LPCNet
WaveNet是DeepMind 2016提出的方法,其不对语音做任何先验假设,用神经网络从数据中学习分布,其不直接预测语音样本值,而是通过一个采样过程来生成语音,其语音质量比之前的所有基于参数声码器多要好,但是其生成语音太慢,主要是因为为了或得足够大的感受野使得卷积层太深太复杂,这使得计算量有几十GFLOPS,因此DeepMind和GoogleBrain提出了WaveRNN,用RNN提示计算效率并采用权重稀疏化方法进一步降低计算量,但其计算量仍然需要10GFLOPS,相对于不需要1GFLOPS的基于信号处理的编码器而言,这仍然高了近两个数量级。自然而然将信号处理和深度学习方法结合以达到实时计算和性能提升的目的,LPCNet正式在这一想法下诞生的编码器。
WaveRNN主要由一层GRU、两层全连接以及softmax激励层组成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-20DSLn3N-1652586220899)(https://github.com/fatchord/WaveRNN/blob/master/assets/wavernn_alt_model_hrz2.png?raw=true)] 摘自https://github.com/fatchord/WaveRNN
LPCNet是基于WaveRNN的低复杂度语音编码器,通过将线性预测技(对声道建模)和WaveRNN相结合以达到低复杂度语音合成和压缩,其计算复杂度在3GFLOPS以下,许多带支持SIMD指令低功耗移动端处理器(手机和嵌入式系统)都可以支持这一计算复杂度,Jean-Marc Valin是LPCNet和Opus编码器的主要贡献者之一,因而LPCNet信号处理部分使用Opus部分实现方法,开源代码中包含了推理和基于Keras的训练代码。
线性预测是一种简单高效的谱包络建模方法,但是激励信号却没有如此简单高效的方法,LPCNet的谱包络建模还是使用线性预测方法实现,谱特性平坦的激励使用神经网络建模。下图是LPCNet的基本结构,它包括一个工作频率为16 kHz的采样率网络和一个处理10 ms帧(160个采样)的帧率网络,帧率网络为采样率网络提供一个条件向量输入,这个条件向量一帧计算一次,并在该帧时间内保持不变。提取的特征是18个Bark倒谱系数和两个基频参数(周期和相关性),对于低比特率编码应用场景,接收端收到的倒谱系数和基频参数通常经过量化压缩,网络的左侧部分(黄色)每帧计算一次,其结果在整个帧中对于右侧的采样率网络保持不变,compute prediction 模块基于t时刻之前的采样点根据线性预测方法估计的当前采样点值,对输出的采样点
s
t
s_t
st使用去加重滤波后输出。


图 LPCNet框架结构
条件参数
模型使用交叉熵准则训练,用softmax计算预测值误差
e
t
e_t
et分布和真实值分布的交叉熵,测试时仅包含特征,训练时输入还包括利用利用BFCC特征按LPC合成预测值
p
t
p_t
pt,原始语音
s
t
−
1
s_t-1
st−1和
e
t
−
1
e_t-1
et−1,输出参考为
e
t
e_t
et,
e
t
=
s
t
−
p
t
e_t=s_t-p_t
et=st−pt即是输入(延迟)也是输出参考。
p
t
p_t
pt是从特征BFCC计算得到而非直接从原始语音
s
t
s_t
st计算得到,这是因为解码端接收到的特征只有BFCC和pitch以及pitch corr,通过从BFCC预测
p
t
p_t
pt以减少训练和测试/部署推理之间的不匹配问题,此外,因为训练时使用了原始语音作为label,计算模型损失,但是在测试时只有特征(在部署时接收到的只有特征),因而对原始语音加了不同均方误差的噪声以减弱预测误差累积,为了增加训练数据多样性,使用一些随机的二阶IIR滤波器(零极点均在单位圆内的最小相位系统),这些滤波器的增益是随机的,滤波器的传输函数为:
H
(
z
)
=
1
+
b
1
z
−
1
+
b
2
z
−
2
1
+
a
1
z
−
1
+
a
2
z
−
2
H(z) = \\frac1+b_1z^-1 + b_2z^-21+a_1z^-1+a_2z^-2
H(z)=1+a1z−1+a2z−21+b1z−1+b2z−2
,其中
a
1
,
a
2
,
b
1
,
b
2
a_1, a_2, b_1, b_2
a1,a2,b1,b2均服从extU(0, 0.75)分布,这可以确保零极点位于单位圆内,进而保证滤波器的稳定性,训练时将pitch处理成64维embedding,然后接在原来的特征之后,构成102维特征,因此第一个卷积层使用128个filter,第二个卷积层使用102个filter,以便和输入的102维一致,网络输入的
μ
−
l
a
w
\\mu-law
μ−law值先处理成128维embedding,输出分布直接与u-law对应,8bit对应于126维的分布,输出层大小为256,条件向量
f
\\mathbf f
f也是也是128维。由于LPC是基于编码的量化BFCC参数计算得到的,因而和真实语音计算的LPC并不一致,但是从模型最终结果看影响很小,神经网络具有可以弥补这一差异。
左侧帧率模块用于给右侧采样率模块提供条件参数,首先10ms的帧提取的20个输入特征参数通过两层卷积,由于卷积核大小为1x3,因而具有5帧的感受野(两帧向前,两帧向后),两层卷积之后的结果和输入特征相加之后输入两层全连接层,全连接层最终输出 f \\mathbf f f为128维的帧率特征向量,这一帧率特征向量在10ms帧保持不变。
预加重和量化
一些语言合成模型,如WaveNet使用8比特µ-law量化以便最终输出限制在256个可能值。8比特µ-law量化考虑了语音采样值主要集中在0附近幅度较小的地方这一统计分布特征,幅值越大概率越小,因此给幅值小的区间更多比特以减小量化误差,幅值大的区间用较少的比特,以达到整体较优,导出对数特性的压缩曲线。由于语音信号能量通常集中在低频段,µ-law高频段的白量化噪声通常听觉上式可以感知到的。为了避免这一问题,一些方法如WaveRNN将输出扩展为16比特,而LPCNet方法采用的是对训练数据使用预加重滤波
H
(
z
)
=
1
−
α
z
−
1
,
α
=
0.85
H(z)=1-\\alpha z^-1, \\alpha =0.85
H(z)=1−αz−1,α=0.85,先提升一下高频能力,合成语音是再用去加重滤波
D
(
z
)
=
1
1
−
α
z
−
1
D(z)=\\frac11-\\alpha z^-1
D(z)=1−αz−11压一压高频段能量后再输出,这使得奈奎斯特频率点的噪声减少16dB,这极大减少了高频带可感知的噪声。
线性预测
语音采样率较高,相邻采样点之间有很强的相关性,可以利用自回归对采样过程建模,即当前采样点依赖于若干先前点,误差可建模为高斯白噪声。为了减少计算复杂度,声道响应使用全极点线性滤波器建模,设t时刻的采样点为
s
t
s_t
st,则线性预测的输出为:
p
t
=
∑
k
=
1
P
a
k
s
t
−
k
p_t = \\sum \\limits_k=1^Pa_ks_t-k
pt=k=1∑Pakst−k
其中P为线性预测的阶数,
a
k
a_k
ak和前文LPC系数意义一样,首先将18个Bark频带谱转为线性频率谱密度(PSD),然后使用逆FFT将PSD转为自相关,再使用Levinson-Durbin方法计算LPC系数,从Brak频带谱计算LPC系数的原因是这样可以不编码传输LPC系数,使得传输带宽需求进一步下降,尽管低分辨的Bark倒谱使得解码侧计算LPC系数不够准确,但是采样率网络对其有部分补偿效果。
采样率网络的LPC输入有助于提升网络效率和预测准确性,采样率网络也可以用于预测激励(预测残差),这可以减少µ-law量化噪声,这是因为激励通常经过归一化处理,因而其幅度比预加重信号小。
输出层
为了在不显著增加前一层大小的情况下更容易计算输出概率,将两个全连接层(图中DualFC)输出对应点权重相加,
d
u
a
l
_
f
c
(
x
)
=
a
1
∘
tanh
(
W
1
x
)
+
a
2
∘
tanh
(
W
2
x
)
dual\\_fc(\\mathbf x) = \\mathbf a_1 \\circ \\tanh(\\mathbf W_1 \\mathbf x) + \\mathbf a_2 \\circ \\tanh(\\mathbf W_2 \\mathbf x)
dual_fc(x)=a1∘tanh(W1x)+a2∘tanh(W2x)
其中
W
1
\\mathbf W_1
W1和
W
2
\\mathbf W_2
W2是权重矩阵,
a
1
\\mathbf a_1
a1和
a
2
\\mathbf a_2
a2是权重向量,DualFC输出使用softmax激活方法计算可能激励
e
t
e_t
et的概率
P
(
e
t
)
P(e_t)
P(et),
稀疏矩阵
为了保持低复杂度,对于最大的GRUA使用稀疏矩阵方法,并未使用逐个元素稀疏方法,而是基于块的稀疏方法,训练过程中逐步将最小幅度块强制为零,直到达到期望的稀疏率,LPCNet作者发现按16x1分块模型效果最好且容易向量化结果。
softmax分布
p
(
x
)
=
∏
t
=
1
T
p
(
x
t
∣
x
1
,
⋯
,
x
t
−
1
)
p(\\mathbf x) = \\prod \\limits_t=1^Tp(x_t|x_1,\\cdots,x_t-1)
p(x)=t=1∏Tp(xt∣x1,⋯,xt−1) 以上是关于实时音频编解码之十九 基于AI的语音编码(LPCNet)的主要内容,如果未能解决你的问题,请参考以下文章
16比特语音的采样点取值范围是[-32768,32767],softmax直接输出采样点维度需要65536,这样的计算量太多了,因而使用µlaw映射以减少softmax大小,将[-32768,32767]映射为[0,255],首先对采样点归一化为[-1,1],然后改区间值通过µlaw映射为[0,255],µlaw的映射公式如下:
f
(
x
t
)
=
s
i
g
n
(
x
t
)
ln
(
1
+
μ