DQN学习使用混合规则的柔性车间AGV实时调度(关注点:状态奖励函数的设置)
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DQN学习使用混合规则的柔性车间AGV实时调度(关注点:状态奖励函数的设置)相关的知识,希望对你有一定的参考价值。
1 文章简介
本文原文可查阅文献:
本文针对对象为柔性车间,提出了一种基于混合规则的自适应深度强化学习(DRL) AGV实时调度方法,以最小化完工时间和延迟率为目标。
2 状态设置
主要考虑任务状态和AGV状态,如下:
(1)任务数量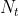 ,表示当前需要运输的任务总数。
,表示当前需要运输的任务总数。
(2)当前任务的平均剩余时间:
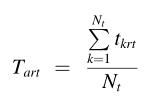
(3)当前任务的平均运行距离
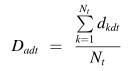
(4)备选AGV的工作状态,用二进制数表示,空闲为0,不空闲为1.
(5)AGV的行驶速度。
3 奖励函数
设计奖励函数是为了评估行动和优化政策。本研究旨在降低agv实时调度的完工时间和延迟率。为了在同一维度上评价这两个指标,引入时间成本和延迟成本的概念如下:

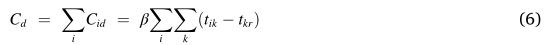
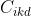 :表示AGV i操作任务k的延迟成本;
:表示AGV i操作任务k的延迟成本;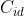 :AGV i 的总延迟成本;
:AGV i 的总延迟成本;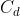 :整个调度的总延迟成本
:整个调度的总延迟成本
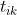 :任务k的运输时间;
:任务k的运输时间;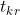 :AGV i的总延迟时间
:AGV i的总延迟时间

 :AGV i执行任务k的时间成本;
:AGV i执行任务k的时间成本;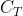 :总调度时间成本;T:makespan
:总调度时间成本;T:makespan
随着上述成本的降低,调度绩效将得到改善。因此,根据延迟成本和时间成本定义奖励函数如下:
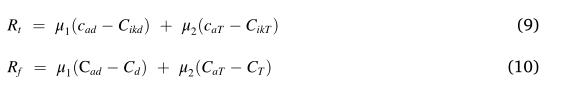
 :用于评估单个任务的行动的当前奖励;
:用于评估单个任务的行动的当前奖励;
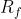 :用于评估调度的整体性能的最终奖励;
:用于评估调度的整体性能的最终奖励;
 :单个任务的平均延迟成本和平均时间成本
:单个任务的平均延迟成本和平均时间成本
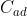 /
/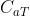 :整个调度的平均延迟成本和平均时间成本
:整个调度的平均延迟成本和平均时间成本
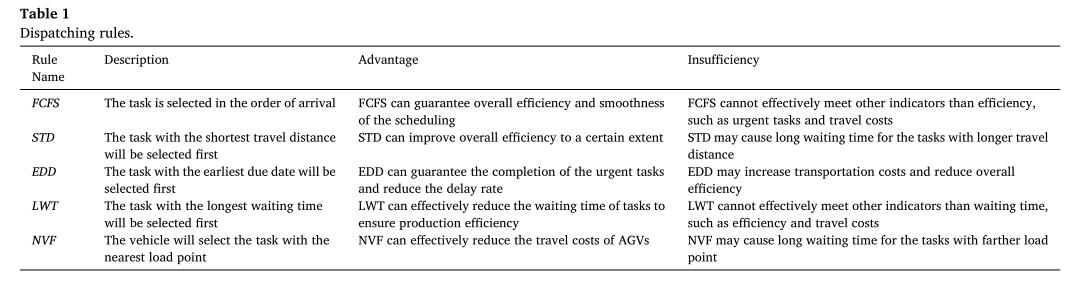
4 动作
5 体系结构
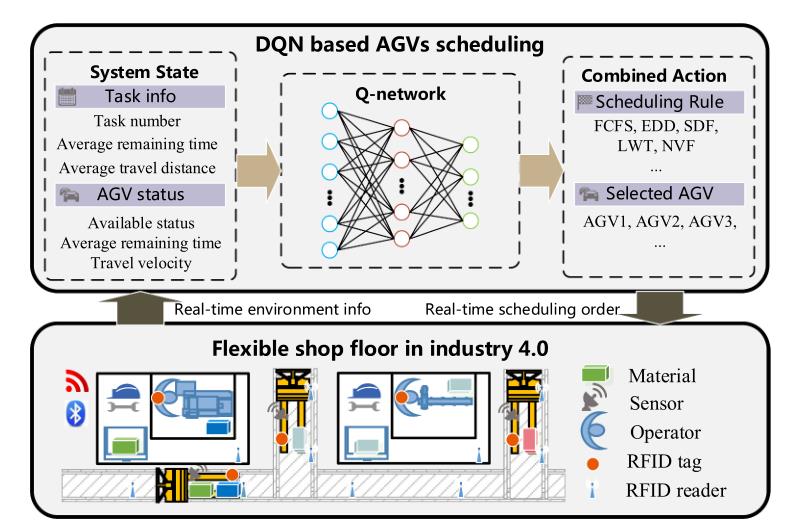
算法框架:
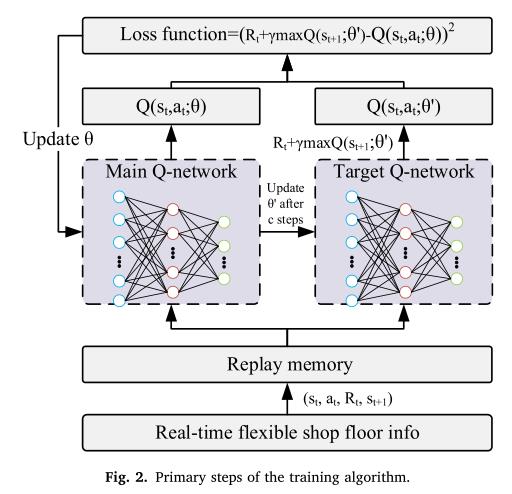
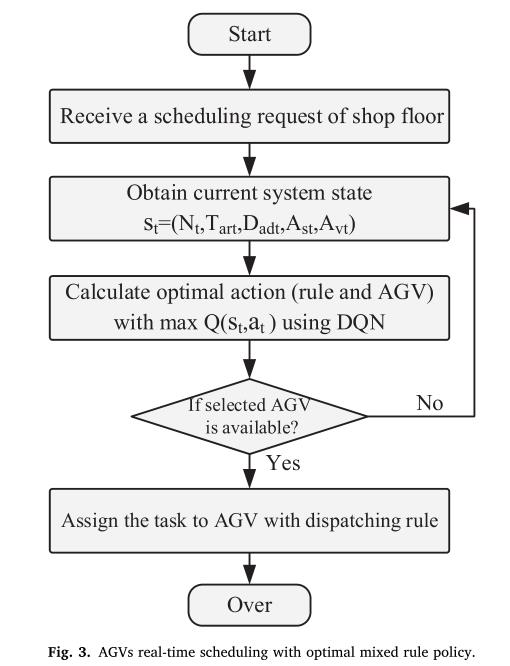
6 效果
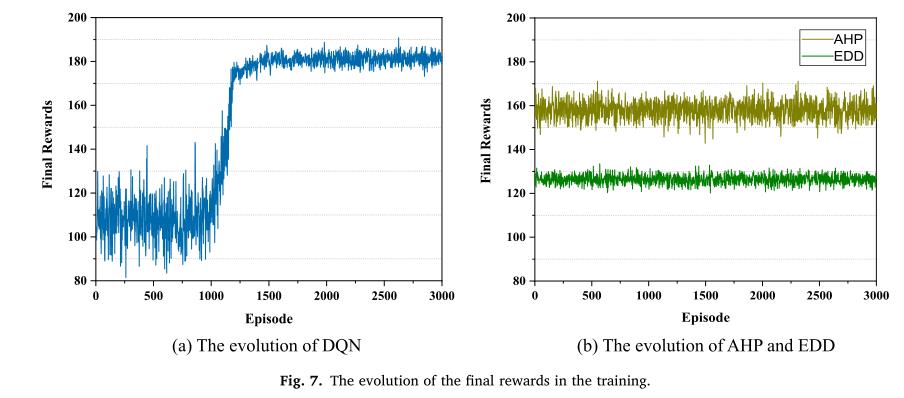
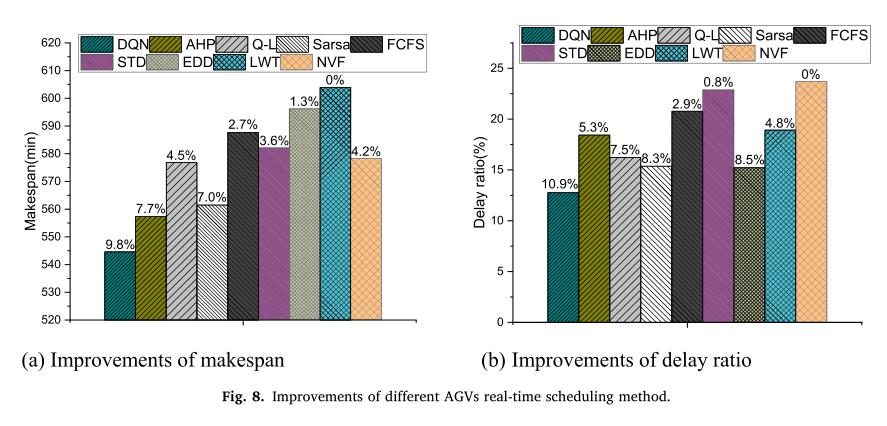
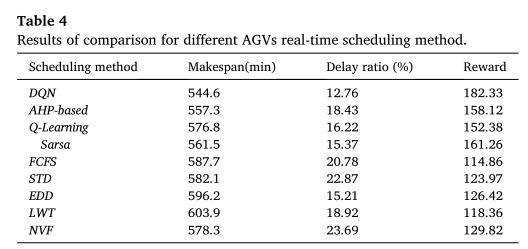
以上是关于DQN学习使用混合规则的柔性车间AGV实时调度(关注点:状态奖励函数的设置)的主要内容,如果未能解决你的问题,请参考以下文章
用Python实现基于遗传算法(GA)求解混合流水车间调度问题(HFSP)
Tensorflow2.0实现|用Python实现多智能体强化学习(MARL)求解两AGV流水车间联合(Two-AGV-FSP)调度问题