Tensorflow2.0实现|用Python实现多智能体强化学习(MARL)求解两AGV流水车间联合(Two-AGV-FSP)调度问题
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow2.0实现|用Python实现多智能体强化学习(MARL)求解两AGV流水车间联合(Two-AGV-FSP)调度问题相关的知识,希望对你有一定的参考价值。
注:这篇文章与代码实现仅为个人实践小项目,没有出处!除此处代码展示,还可前往个人
复现环境:
2 tensorflow==2.2.0
3 Keras==2.3.0
简单描述:
(1)state空间长度为机器的数量,取值,若机器的输入输出缓冲区及机器上存在工件,取“2”,否则,取“1”.
(2)action:AGV的Action为所到达的机器位置
(3)奖励:机器到达时间-所选工件在当前机器的完工时间
(4)状态转移,AGV将工件从上道工件完工机器输出缓冲区送至下道机器的输入缓冲区;
(5)采用了两种经验回放方式进行测试:
a:普通的经验回放机制
b:优先经验回放机制
注:此文章仅提供MARL_Two_AGV_FSP的求解思路和流程,不为最优结果,相关状态、动作、奖励等设置仅做了简单处理。
相关文献阅读可见:
强化学习|多智能体深度强化学习(博弈论—>多智能体强化学习)
论文阅读|《Bi-level Actor-Critic for Multi-agent Coordination》(AAAI 2020)(附带源码链接)
论文阅读|《作业车间制造系统中单台多载自动导引车实时无死锁控制策略》
论文阅读|《带阻塞约束的无缓冲作业车间单元调度与自动导引车》
论文阅读|《用蚁群算法求解作业车间与AGVs无路径冲突的集成调度问题》
论文阅读|《强化学习在加工时间可变的机器人流水车间调度中的应用》
具体代码如下:
1 Environment/Flow_Shop.py
class Job:
def __init__(self,idx,handling_time):
self.index=idx
self.handling_time=handling_time
# self.waiting_time=0
# self.using_time=[]
self.start=0
self.end=0
self.Current_Operation=0
self.Cur_PT=None
self.arrive=0
def finish(self):
del self.handling_time[0]
def handling(self,start,machine):
self.start=start
self.Cur_PT=self.handling_time[machine]
self.end=self.start+ self.Cur_PT
def wait_time(self,t):
return t-self.end
class Machine:
def __init__(self,idx):
self.index=idx
self.IB=[] #输入缓冲区
self.OB=[] #输出缓冲区
self.Processed=[]
self.Processing=None
self.using_time=[]
self.start=0
self.end=0
def state(self):
'''
There are 4 state for this machine:
(1)OB is empty and machine is idle;
(2)OB is empty and machine is busy;
(3)OBi is occupied and machine is idle;
(4)OBi is occupied and machine is busy.
:param t:
:return: 1/2/3/4
'''
if self.Processing==None and self.OB==[] and self.IB==[]:
return 1
else:
return 2
def handling(self):
if self.IB[0].arrive>=self.end:
self.start=self.IB[0].arrive
else:
self.start = self.end
self.IB[0].handling(self.start,self.index)
self.end = self.IB[0].end
self.Processing = self.IB[0]
del self.IB[0]
def change_end(self,t):
self.end = t
def update(self,t):
if self.IB==[] and self.Processing==None:
if self.end<t:
self.end=t
elif self.IB==[] and self.Processing!=None:
if self.end <= t:
self.OB.append(self.Processing)
self.Processed.append(self.Processing.index)
self.Processing = None
self.using_time.append([self.start, self.end])
elif self.IB!=[] and self.Processing!=None:
while True:
if self.end <= t:
self.OB.append(self.Processing)
self.Processed.append(self.Processing.index)
self.using_time.append([self.start, self.end])
if self.IB!=[] :
if self.IB[0].arrive<=t:
self.handling()
else:
break
else:
self.Processing=None
break
else:
break
else: #到达便进行加工
if self.end<=t and self.IB[0].arrive<=t:
self.change_end(t)
self.handling()
def put_in_Job(self,Job): #Job <type:class>
self.IB.append(Job)
class AGV:
def __init__(self):
self.trace=[0]
self.using_time=[]
self._on=[]
self.Current_Site=0
self.start=0
self.end=0
def send_to(self,site,s,t,load=None):
self.start=s
self.end=self.start+t
self.using_time.append([self.start,self.end])
self._on.append(load)
self.Current_Site=site
self.trace.append(site)
class Two_Robots_FS_Env:
def __init__(self,args):
self.J_num=args.n
self.PT=args.PT
self.M_num=args.m
self.AGV_num=args.AGV_num
self.agv_trans=args.agv_trans
self.Create_Item()
self._s=None #当前状态
self.next_s=None
self.terminal_state=[1 for i in range(self.M_num)]
self.terminal_state[-1]=2
def C_max(self):
t=0
for J in self.Jobs:
if t<J.end:
t=J.end
return t
def Create_Item(self):
self.Machines=[]
for i in range(self.M_num):
M=Machine(i)
self.Machines.append(M)
self.Jobs=[]
for k in range(self.J_num):
J=Job(k,self.PT[k])
self.Jobs.append(J)
self.AGVs=[]
for j in range(self.AGV_num):
A=AGV()
self.AGVs.append(A)
def update_Item(self,t):
for i in range(self.M_num):
self.Machines[i].update(t)
def Env_State(self):
_s=[]
for i in range(self.M_num):
_s.append(self.Machines[i].state())
self.next_s=_s
def update_state(self):
self._s=self.next_s
self.next_s=None
def cul_trans_t(self,agv_num,cur_s,target_s):
if cur_s<=target_s:
return sum(self.agv_trans[agv_num][cur_s:target_s])
else:
return sum(self.agv_trans[agv_num][target_s:cur_s])
def candidate_mch(self):
M_id=[]
for i in range(self.M_num):
if self.Machines[i].OB!=[] or self.Machines[i].Processing!=None:
M_id.append(i)
return M_id
def rest_work(self):
while True:
if self.Machines[-1].IB!=[] or self.Machines[-1].Processing!=None:
self.Machines[-1].update(self.Machines[-1].end)
else:
break
def scheduling(self,t,action,agv_num):
done=False
'''
state transiction time point ,in this point ,agv has two succesive movement:
(1)from agv current site to target machine(call as param <action>);
(2)trasfer job from action machine to next machine(site :action +1)
:param t:
:param action:
:param agv:
:return: new_t
in which new_t means new time point
besides,update flow shop environment state
'''
agv=self.AGVs[agv_num]
# first transfer: unload
if agv.Current_Site==action:
trans_time1=0
else:
trans_time1=self.cul_trans_t(agv_num,agv.Current_Site,action)
agv.send_to(action,t,trans_time1,load=None)
t1=t+trans_time1
self.update_Item(t1)
#judge whether agv need to waiting beside machine
wait=0
if self.Machines[action].OB!=[] :
select_Job=self.Machines[action].OB[0] #action:target machine
if select_Job.end>t1:
wait=select_Job.end-t1
elif self.Machines[action].Processing!=None:
wait=self.Machines[action].end-t1
select_Job=self.Machines[action].Processing
else:
reward=-99
return t1,self.next_s,reward,done
JC=select_Job.end
t2 = t1 + wait
self.update_Item(t2)
self.Machines[action].OB.remove(select_Job)
targrt_site=action+1
trans_time2=self.agv_trans[agv_num][action]
agv.send_to(targrt_site, t2, trans_time2, load=select_Job.index)
#next time point
t3=t2+trans_time2
select_Job.arrive=t3
self.Machines[action + 1].put_in_Job(select_Job)
self.update_Item(t3)
RA=t1
if agv==0:
reward=self.r1(JC,RA)
else:
reward = self.r1(JC, RA)
self.Env_State()
if self.next_s==self.terminal_state:
done=True
self.rest_work()
return t3,self.next_s,reward,done
#this step is use for MADDPG:
def step(self,actions,t):
t_n=[]
obs_n = []
reward_n = []
done_n = []
info_n = {'n': []}
d=False
for i in range(len(actions)):
if not d:
t0,s,r,d=self.scheduling(t[i],actions[i],i)
# print(d)
if d:
obs_n.append(s)
t_n.append(t0)
reward_n.append(r)
done_n.append(d)
if len(t_n)==1:
obs_n.append(s)
t_n.append(t0)
reward_n.append(r)
done_n.append(d)
return t_n,obs_n, reward_n, done_n, info_n
else:
obs_n.append(s)
t_n.append(t0)
reward_n.append(r)
done_n.append(d)
return t_n, obs_n, reward_n, done_n, info_n
#reward function 1:used to minimise robot idle(delay) time
def r1(self,JC,RA):
return JC-RA
#reward function 2:used to minimise job waiting time
def r2(self,JC,RA):
return RA-JC
def reset1(self):
self.Create_Item()
self.agv1 = AGV()
self.agv2 = AGV()
self._s = None # 当前状态
self.next_s = None
for Ji in self.Jobs:
self.Machines[0].put_in_Job(Ji)
self.Machines[0].handling()
self.Env_State()
done=False
t=[0,0]
return t,self.next_s,done
def reset(self):
self.Create_Item()
self.agv1 = AGV()
self.agv2 = AGV()
self._s = None # 当前状态
self.next_s = None
for Ji in self.Jobs:
self.Machines[0].put_in_Job(Ji)
self.Machines[0].handling()
self.Env_State()
done=[False,False]
t=[0,0]
s=[self.next_s,self.next_s]
return t,s,done
if __name__=="__main__":
from Gantt_graph import Gantt
from simple_MADRL.Params import args
import random
random.seed(64)
fs=Two_Robots_FS_Env(args)
t, state, done=fs.reset()
t_i=[0,0]
while True:
for i in range(2):
action_choice=[]
for j in range(len(fs.Machines)-1):
if fs.Machines[j].OB!=[] or fs.Machines[j].Processing!=None:
action_choice.append(j)
if action_choice!=[]:
action=random.choice(action_choice)
t_i[i],next_state,reward,done=fs.scheduling(t_i[i],action,i)
state=next_state
Gantt(fs.Machines,fs.AGVs)
if done:
# Gantt(fs.Machines, fs.AGVs)
break
if done:
break
print(state)
Gantt(fs.Machines, fs.AGVs)
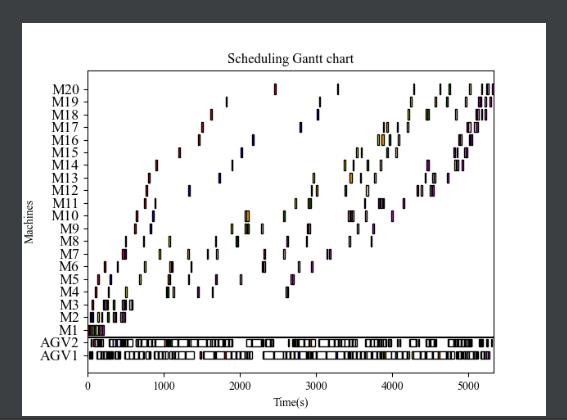
2 Environment/Gantt_graph.py
import matplotlib.pyplot as plt
import numpy as np
#注:此处的Machine和AGV分别表示Machine类列表和AGV类列表
def Gantt(Machines,agvs):
plt.rcParams['font.sans-serif'] = ['Times New Roman'] # 如果要显示中文字体,则在此处设为:SimHei
plt.rcParams['axes.unicode_minus'] = False # 显示负号
M = ['red', 'blue', 'yellow', 'orange', 'green', 'palegoldenrod', 'purple', 'pink', 'Thistle', 'Magenta',
'SlateBlue', 'RoyalBlue', 'Cyan', 'Aqua', 'floralwhite', 'ghostwhite', 'goldenrod', 'mediumslateblue',
'navajowhite','navy', 'sandybrown', 'moccasin']
Job_text=['J'+str(i+1) for i in range(100)]
Machine_text=['M'+str(i+1) for i in range(50)]
t = 0
for k in range(len(agvs)):
for m in range(len(agvs[k].using_time)):
if agvs[k].using_time[m][1] - agvs[k].using_time[m][0] != 0:
if agvs[k]._on[m]!=None:
plt.barh(k, width= agvs[k].using_time[m][1]- agvs[k].using_time[m][0],
height=0.6,
left=agvs[k].using_time[m][0],
color=M[agvs[k]._on[m]],
edgecolor='black')
else:
plt.barh(k, width=agvs[k].using_time[m][1] - agvs[k].using_time[m][0],
height=0.6,
left=agvs[k].using_time[m][0],
color='white',
edgecolor='black')
# plt.text(x=agvs[k].using_time[m][0]+(agvs[k].using_time[m][1] - agvs[k].using_time[m][0])/2-2,
# y=k-0.05,
# s=Machine_text[agvs[k].trace[m]]+'-'+Machine_text[agvs[k].trace[m+1]],
# fontsize=5)
if agvs[k].using_time[m][1]>t:
t=agvs[k].using_time[m][1]
for i in range(len(Machines)):
for j in range(len(Machines[i].using_time)):
if Machines[i].using_time[j][1] - Machines[i].using_time[j][0] != 0:
plt.barh(i+k+1, width=Machines[i].using_time[j][1] - Machines[i].using_time[j][0],
height=0.8, left=Machines[i].using_time[j][0],
color=M[Machines[i].Processed[j]],
edgecolor='black')
# plt.text(x=Machines[i].using_time[j][0]+(Machines[i].using_time[j][1] - Machines[i].using_time[j][0])/2 - 0.1,
# y=i+k+1,
# s=Job_text[Machines[i].Processed[j]],
# fontsize=12)
if Machines[i].using_time[j][1]>t:
t=Machines[i].using_time[j][1]
list=['AGV1','AGV2']
list1=['M'+str(_+1) for _ in range(len(Machines))]
list.extend(list1)
plt.xlim(0,t)
plt.hlines(k + 0.4,xmin=0,xmax=t, color="black") # 横线
plt.yticks(np.arange(i + k + 2), list,size=13,)
plt.title('Scheduling Gantt chart')
plt.ylabel('Machines')
plt.xlabel('Time(s)')
plt.show()
3 Environment/Test1.py
'''
start date: 2021/9/14
from thesis:
Arviv,,Kfir等.Collaborative reinforcement learning for a two-robot job transfer flow-shop scheduling problem[J].
INTERNATIONAL JOURNAL OF PRODUCTION RESEARCH,2016,54(4):1196-1209.
'''
import random
import numpy as np
random.seed(64)
def Generate(n,m,machine_speed,AGV_speed_pair):
AGV_speed= [[5, 15], [15, 25], [25, 35]]
Mch_speed=[[15,25],[25,45]]
AGV1_speed,AGV2_speed=AGV_speed[AGV_speed_pair[0]],AGV_speed[AGV_speed_pair[1]]
Ms=Mch_speed[machine_speed]
PT=[]
for i in range(n):
PT_i=[random.randint(Ms[0],Ms[1]) for i in range(m)]
PT.append(PT_i)
agv_trans=[]
agv1_trans = [random.randint(AGV1_speed[0],AGV1_speed[1]) for i in range(1,m)]
agv2_trans=[random.randint(AGV2_speed[0],AGV2_speed[1]) for i in range(1,m)]
agv_trans.extend([agv1_trans,agv2_trans])
return PT ,agv_trans
n,m=5,5
agv_speed_pair=[0,0]
machine_speed=0
PT ,agv_trans=Generate(n,m,machine_speed,agv_speed_pair)
for i in range(2):
agv_trans[i].append(0)
# print(np.array(PT))
# print()
# print(np.array(agv_trans))4 simple_MADRL/brain.py
import os
from keras.models import Sequential, Model
from keras.layers import Dense, Lambda, Input, Concatenate
from keras.optimizers import *
import tensorflow as tf
from keras import backend as K
HUBER_LOSS_DELTA = 1.0
def huber_loss(y_true, y_predict):
err = y_true - y_predict
cond = K.abs(err) < HUBER_LOSS_DELTA
L2 = 0.5 * K.square(err)
L1 = HUBER_LOSS_DELTA * (K.abs(err) - 0.5 * HUBER_LOSS_DELTA)
loss = tf.where(cond, L2, L1)
return K.mean(loss)
class Brain(object):
def __init__(self, args,brain_name):
self.state_size = args.m
self.action_size = args.m-1
self.weight_backup = brain_name #保存神经网络参数的地址
self.batch_size = args.batch_size
self.learning_rate = args.learning_rate
self.test = args.test
self.num_nodes = args.number_nodes
self.dueling = args.dueling
self.optimizer_model = args.optimizer
self.model = self._build_model()
self.model_ = self._build_model()
def _build_model(self):
if self.dueling:
x = Input(shape=(self.state_size,))
# a series of fully connected layer for estimating V(s)
y11 = Dense(self.num_nodes, activation='relu')(x)
y12 = Dense(self.num_nodes, activation='relu')(y11)
y13 = Dense(1, activation="linear")(y12)
# a series of fully connected layer for estimating A(s,a)
y21 = Dense(self.num_nodes, activation='relu')(x)
y22 = Dense(self.num_nodes, activation='relu')(y21)
y23 = Dense(self.action_size, activation="linear")(y22)
w = Concatenate(axis=-1)([y13, y23])
# combine V(s) and A(s,a) to get Q(s,a)
z = Lambda(lambda a: K.expand_dims(a[:, 0], axis=-1) + a[:, 1:] - K.mean(a[:, 1:], keepdims=True),
output_shape=(self.action_size,))(w)
else:
x = Input(shape=(self.state_size,))
# a series of fully connected layer for estimating Q(s,a)
y1 = Dense(self.num_nodes, activation='relu')(x)
y2 = Dense(self.num_nodes, activation='relu')(y1)
z = Dense(self.action_size, activation="linear")(y2)
model = Model(inputs=x, outputs=z)
if self.optimizer_model == 'Adam':
optimizer = Adam(lr=self.learning_rate, clipnorm=1.)
elif self.optimizer_model == 'RMSProp':
optimizer = RMSprop(lr=self.learning_rate, clipnorm=1.)
else:
print('Invalid optimizer!')
model.compile(loss=huber_loss, optimizer=optimizer)
if self.test:
if not os.path.isfile(self.weight_backup):
print('Error:no file')
else:
model.load_weights(self.weight_backup)
return model
def train(self, x, y, sample_weight=None, epochs=1, verbose=0): # x is the input to the network and y is the output
self.model.fit(x, y, batch_size=len(x), sample_weight=sample_weight, epochs=epochs, verbose=verbose)
def predict(self, state, target=False):
if target: # get prediction from target network
return self.model_.predict(state)
else: # get prediction from local network
return self.model.predict(state)
def predict_one_sample(self, state, target=False):
return self.predict(state.reshape(1,self.state_size), target=target).flatten()
def update_target_model(self):
self.model_.set_weights(self.model.get_weights())
def save_model(self):
self.model.save(self.weight_backup)5 simple_MADRL/dqn_agent.py
import numpy as np
import random
from simple_MADRL.brain import Brain
from simple_MADRL.uniform_experience_replay import Memory as UER
from simple_MADRL.prioritized_experience_replay import Memory as PER
MAX_EPSILON = 1.0
MIN_EPSILON = 0.01
MIN_BETA = 0.4
MAX_BETA = 1.0
class Agent(object):
epsilon = MAX_EPSILON
beta = MIN_BETA
def __init__(self, bee_index, brain_name, args):
self.state_size = args.m
self.action_size = args.m-1
self.bee_index = bee_index
self.learning_rate = args.learning_rate
self.gamma = 0.95
self.brain = Brain(args,brain_name)
self.memory_model = args.memory
if self.memory_model == 'UER':
self.memory = UER(args.memory_capacity)
elif self.memory_model == 'PER':
self.memory = PER(args.memory_capacity, args.prioritization_scale)
else:
print('Invalid memory model!')
self.target_type = args.target_type
self.update_target_frequency = args.target_frequency
self.max_exploration_step = args.maximum_exploration
self.batch_size = args.batch_size
self.step = 0
self.test = args.test
if self.test:
self.epsilon = MIN_EPSILON
def greedy_actor(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
return np.argmax(self.brain.predict_one_sample(state))
def find_targets_per(self, batch):
batch_len = len(batch)
states = np.array([o[1][0] for o in batch])
states_ = np.array([o[1][3] for o in batch])
p = self.brain.predict(states)
p_ = self.brain.predict(states_)
pTarget_ = self.brain.predict(states_, target=True)
x = np.zeros((batch_len, self.state_size))
y = np.zeros((batch_len, self.action_size))
errors = np.zeros(batch_len)
for i in range(batch_len):
o = batch[i][1]
s = o[0]
# a = o[1][self.bee_index]
a = o[1]
r = o[2]
s_ = o[3]
done = o[4]
t = p[i]
old_value = t[a]
if done:
t[a] = r
else:
if self.target_type == 'DDQN':
t[a] = r + self.gamma * pTarget_[i][np.argmax(p_[i])]
elif self.target_type == 'DQN':
t[a] = r + self.gamma * np.amax(pTarget_[i])
else:
print('Invalid type for target network!')
x[i] = s
y[i] = t
errors[i] = np.abs(t[a] - old_value)
return [x, y, errors]
def find_targets_uer(self, batch):
batch_len = len(batch)
states = np.array([o[0] for o in batch])
states_ = np.array([o[3] for o in batch])
p = self.brain.predict(states)
p_ = self.brain.predict(states_)
pTarget_ = self.brain.predict(states_, target=True)
x = np.zeros((batch_len, self.state_size))
y = np.zeros((batch_len, self.action_size))
errors = np.zeros(batch_len)
for i in range(batch_len):
o = batch[i]
s = o[0]
# a = o[1][self.bee_index]
a = o[1]
r = o[2]
s_ = o[3]
done = o[4]
t = p[i]
old_value = t[a]
if done:
t[a] = r
else:
if self.target_type == 'DDQN':
t[a] = r + self.gamma * pTarget_[i][np.argmax(p_[i])]
elif self.target_type == 'DQN':
t[a] = r + self.gamma * np.amax(pTarget_[i])
else:
print('Invalid type for target network!')
x[i] = s
y[i] = t
errors[i] = np.abs(t[a] - old_value)
return [x, y]
def observe(self, sample):
#普通经验回放
if self.memory_model == 'UER':
self.memory.remember(sample)
# priority memory replay
elif self.memory_model == 'PER':
_, _, errors = self.find_targets_per([[0, sample]])
self.memory.remember(sample, errors[0])
else:
print('Invalid memory model!')
def decay_epsilon(self):
# slowly decrease Epsilon based on our experience
self.step += 1
if self.test:
self.epsilon = MIN_EPSILON
self.beta = MAX_BETA
else:
if self.step < self.max_exploration_step:
self.epsilon = MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * (self.max_exploration_step - self.step)/self.max_exploration_step
self.beta = MAX_BETA + (MIN_BETA - MAX_BETA) * (self.max_exploration_step - self.step)/self.max_exploration_step
else:
self.epsilon = MIN_EPSILON
def replay(self):
if self.memory_model == 'UER':
batch = self.memory.sample(self.batch_size)
x, y = self.find_targets_uer(batch)
self.brain.train(x, y)
elif self.memory_model == 'PER':
[batch, batch_indices, batch_priorities] = self.memory.sample(self.batch_size)
x, y, errors = self.find_targets_per(batch)
normalized_batch_priorities = [float(i) / sum(batch_priorities) for i in batch_priorities]
importance_sampling_weights = [(self.batch_size * i) ** (-1 * self.beta)
for i in normalized_batch_priorities]
normalized_importance_sampling_weights = [float(i) / max(importance_sampling_weights)
for i in importance_sampling_weights]
sample_weights = [errors[i] * normalized_importance_sampling_weights[i] for i in range(len(errors))]
self.brain.train(x, y, np.array(sample_weights))
self.memory.update(batch_indices, errors)
else:
print('Invalid memory model!')
def update_target_model(self):
if self.step % self.update_target_frequency == 0:
self.brain.update_target_model()6 simple_MADRL/get_file_name.py
import os
ARG_LIST = ['learning_rate', 'optimizer', 'memory_capacity', 'batch_size', 'target_frequency', 'maximum_exploration',
'first_step_memory', 'replay_steps', 'number_nodes', 'target_type', 'memory',
'prioritization_scale']
def get_name_brain(args, idx):
args=vars(args)
file_name_str = '_'.join([str(args[x]) for x in ARG_LIST])
return './results_agents_landmarks/weights_files/' + file_name_str + '_' + str(idx) + '.h5'
def get_name_rewards(args):
args=vars(args)
file_name_str = '_'.join([str(args[x]) for x in ARG_LIST])
return './results_agents_landmarks/rewards_files/' + file_name_str + '.csv'
def get_name_timesteps(args):
args=vars(args)
file_name_str = '_'.join([str(args[x]) for x in ARG_LIST])
return './results_agents_landmarks/timesteps_files/' + file_name_str + '.csv'7 simple_MADRL/Params.py
import argparse
from Environment.Test1 import n,m,PT,agv_trans
parser = argparse.ArgumentParser()
#params for Flow_shop:
parser.add_argument('--n',default=n,type=int,help='Job number')
parser.add_argument('--m',default=m,type=int,help='Machine number')
parser.add_argument('--PT',default=PT,type=list,help='Processing time Matrix')
parser.add_argument('--agv_trans',default=agv_trans,type=list,help='AGV transport time bewteen machines')
parser.add_argument('--AGV_num',default=2,type=int,help='AGV number')
#params for Brain:
parser.add_argument( '--batch_size', default=64, type=int, help='Batch size')
parser.add_argument( '--learning_rate', default=0.00005, type=float, help='Learning rate')
parser.add_argument( '--number_nodes', default=256, type=int, help='Number of nodes in each layer of NN')
parser.add_argument( '--dueling', action='store_true', help='Enable Dueling architecture if "store_false" ')
parser.add_argument( '--optimizer', choices=['Adam', 'RMSProp'], default='RMSProp',
help='Optimization method')
#params for Agent:
parser.add_argument( '--memory', choices=['UER', 'PER'], default='PER')
parser.add_argument( '--memory_capacity', default=1000000, type=int, help='Memory capacity')
parser.add_argument( '--prioritization_scale', default=0.5, type=float, help='Scale for prioritization')
parser.add_argument( '--target_type', choices=['DQN', 'DDQN'], default='DDQN')
parser.add_argument( '--target_frequency', default=10000, type=int,
help='Number of steps between the updates of target network')
parser.add_argument( '--maximum_exploration', default=100000, type=int, help='Maximum exploration step')
parser.add_argument( '--test', action='store_true', help='Enable the test phase if "store_false"')
parser.add_argument( '--episode-number', default=5000, type=int, help='Number of episodes')
parser.add_argument('-fsm', '--first-step-memory', default=0, type=float,
help='Number of initial steps for just filling the memory')
parser.add_argument('-rs', '--replay-steps', default=4, type=float, help='Steps between updating the network')
parser.add_argument( '--render', action='store_false', help='Turn on visualization if "store_false"')
parser.add_argument('-re', '--recorder', action='store_true', help='Store the visualization as a movie '
'if "store_false"')
args = parser.parse_args()8 simple_MADRL/prioritized_experience_replay.py
import random
from simple_MADRL.sum_tree import SumTree as ST
class Memory(object):
e = 0.05
def __init__(self, capacity, pr_scale):
self.capacity = capacity
self.memory = ST(self.capacity)
self.pr_scale = pr_scale
self.max_pr = 0
def get_priority(self, error):
return (error + self.e) ** self.pr_scale
def remember(self, sample, error):
p = self.get_priority(error)
self_max = max(self.max_pr, p)
self.memory.add(self_max, sample)
def sample(self, n):
sample_batch = []
sample_batch_indices = []
sample_batch_priorities = []
num_segments = self.memory.total() / n
for i in range(n):
left = num_segments * i
right = num_segments * (i + 1)
s = random.uniform(left, right)
idx, pr, data = self.memory.get(s)
sample_batch.append((idx, data))
sample_batch_indices.append(idx)
sample_batch_priorities.append(pr)
return [sample_batch, sample_batch_indices, sample_batch_priorities]
def update(self, batch_indices, errors):
for i in range(len(batch_indices)):
p = self.get_priority(errors[i])
self.memory.update(batch_indices[i], p)9 simple_MADRL/sum_tree.py
import numpy
class SumTree(object):
def __init__(self, capacity):
self.write = 0
self.capacity = capacity
self.tree = numpy.zeros(2*capacity - 1)
self.data = numpy.zeros(capacity, dtype=object)
def _propagate(self, idx, change):
parent = (idx - 1) // 2
self.tree[parent] += change
if parent != 0:
self._propagate(parent, change)
def _retrieve(self, idx, s):
left = 2 * idx + 1
right = left + 1
if left >= len(self.tree):
return idx
if s <= self.tree[left]:
return self._retrieve(left, s)
else:
return self._retrieve(right, s-self.tree[left])
def total(self):
return self.tree[0]
def add(self, p, data):
idx = self.write + self.capacity - 1
self.data[self.write] = data
self.update(idx, p)
self.write += 1
if self.write >= self.capacity:
self.write = 0
def update(self, idx, p):
change = p - self.tree[idx]
self.tree[idx] = p
self._propagate(idx, change)
# def get_real_idx(self, data_idx):
#
# tempIdx = data_idx - self.write
# if tempIdx >= 0:
# return tempIdx
# else:
# return tempIdx + self.capacity
def get(self, s):
idx = self._retrieve(0, s)
dataIdx = idx - self.capacity + 1
# realIdx = self.get_real_idx(dataIdx)
return idx, self.tree[idx], self.data[dataIdx]
10 simpe_MADRL/simple_MARL_FSP_main.py
import numpy as np
import os
from simple_MADRL.dqn_agent import Agent
from Environment.Flow_Shop import Two_Robots_FS_Env
import matplotlib.pyplot as plt
class MAS:
def __init__(self,args):
current_path = os.path.dirname(__file__)
self.env = Two_Robots_FS_Env(args)
self.episodes_number = args.episode_number
self.render = args.render # Turn on visualization if "store_false"
self.recorder = args.recorder
self.test = args.test
self.filling_steps = args.first_step_memory
self.steps_b_updates = args.replay_steps
def run(self, agents, file1, file2):
from Environment.Gantt_graph import Gantt
total_step=0
rewards_list=[]
time_list=[]
time_step=0
x=[]
for i in range(self.episodes_number):
# x.append(i)
reward_all = 0
t,state,done=self.env.reset1()
state=np.array(state)
while True:
for j in range(len(agents)):
total_step+=1
a=agents[j].greedy_actor(state)
t[j],next_state,reward,done=self.env.scheduling(t[j],a,j)
next_state=np.array(next_state)
# if i >=1:
# print(next_state)
agents[j].observe((state, a, reward, next_state, done))
reward_all+=reward
state=next_state
time_step+=1
if total_step >= self.filling_steps:
agents[j].decay_epsilon()
if time_step % self.steps_b_updates == 0:
agents[j].replay()
agents[j].update_target_model()
if done == True:
# Gantt(self.env.Machines, self.env.AGVs)
break
if done==True:
break
# Gantt(self.env.Machines, self.env.AGVs)
if i%50==0:
rewards_list.append(reward_all)
x.append(i)
time_list.append(t)
print("Episode {p}, Score: {s}, Final Step: {t}, Goal: {g}".format(p=i, s=reward_all,
t=t, g=done))
# if not self.test:
# if i % 100 == 0:
# df = pd.DataFrame(rewards_list, columns=['score'])
# df.to_csv(file1)
#
# df = pd.DataFrame(timesteps_list, columns=['steps'])
# df.to_csv(file2)
#
# if total_step >= self.filling_steps:
# if reward_all > max_score:
# for agent in agents:
# agent.brain.save_model()
# max_score = reward_all
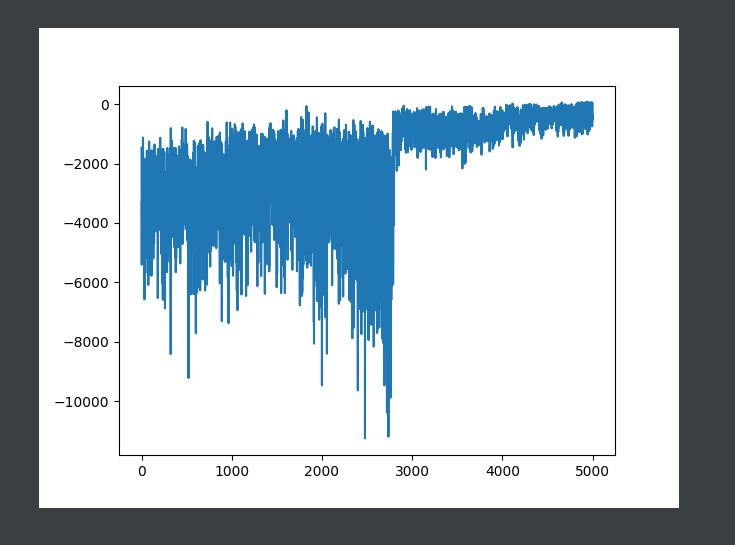
plt.plot(x,rewards_list)
plt.show()
Gantt(self.env.Machines, self.env.AGVs)
if __name__=="__main__":
from Params import args
from get_file_name import get_name_brain,get_name_rewards,get_name_timesteps
env = MAS(args)
all_agents = []
for b_idx in range(2):
brain_file = get_name_brain(args, b_idx)
all_agents.append(Agent(b_idx, brain_file, args))
rewards_file = get_name_rewards(args)
timesteps_file = get_name_timesteps(args)
env.run(all_agents, rewards_file, timesteps_file)
11 uniform_experience_replay.py
import random
from collections import deque
class Memory(object):
def __init__(self, capacity):
self.capacity = capacity
self.memory = deque(maxlen=self.capacity)
def remember(self, sample):
self.memory.append(sample)
def sample(self, n):
n = min(n, len(self.memory))
sample_batch = random.sample(self.memory, n)
return sample_batch实验效果:
以上是关于Tensorflow2.0实现|用Python实现多智能体强化学习(MARL)求解两AGV流水车间联合(Two-AGV-FSP)调度问题的主要内容,如果未能解决你的问题,请参考以下文章