注入Attention,精度涨30%!谷歌发表最新多目标“动态抠图”模型
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了注入Attention,精度涨30%!谷歌发表最新多目标“动态抠图”模型相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
只需第一帧图像+边界提示,就能将视频中各物体“抠”出来并进行轨迹跟踪:


以上就是谷歌的最新研究成果。

该方法通过在视频中引入注意力机制,成功地解决此前采用了无监督学习的多目标分割和跟踪方法的一些不足。
现在的它,不仅可以泛化到更多样、视觉上更复杂的视频中,还能处理更长的视频序列。
通过实验还发现,相比此前的模型,谷歌这个新方法在MOVi数据集上的mIoU直接提高了近30%。
为“动态抠图”引入注意力机制
方法被命名为SAVi(Slot Attention for Video)。
而此前的无监督目标分割和跟踪方法最大的问题,就是只能应用到非常简单的视频上。
为了处理视觉效果更复杂的视频,SAVi采用弱监督学习:
(1)以光流(optical flow)预测为训练目标,并引入注意力机制;
(2)在第一帧图像上给出初始提示(一般是框出待分割物体,或者给出物体上单个点的坐标),进行分割指导。
具体来说,受到常微分方程的“预测-校正器”方法的启发,SAVi对每个可见的视频帧执行预测和校正步骤。
为了描述视频物体随时间变化的状态,包括与其它物体的交互,SAVi在进行光流预测时在slot之间使用自注意力。
slot就是指视频中各物体,用不同颜色区分。
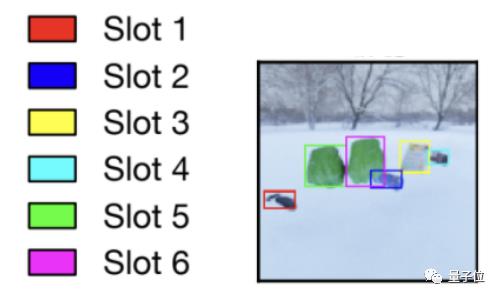
校正阶段,带有输入的slot-normalized交叉注意用于校正(更新)slot表示集。
然后预测器的输出根据时间来初始化矫正器,使模型最终能够以一致的方式随时间跟踪物体。
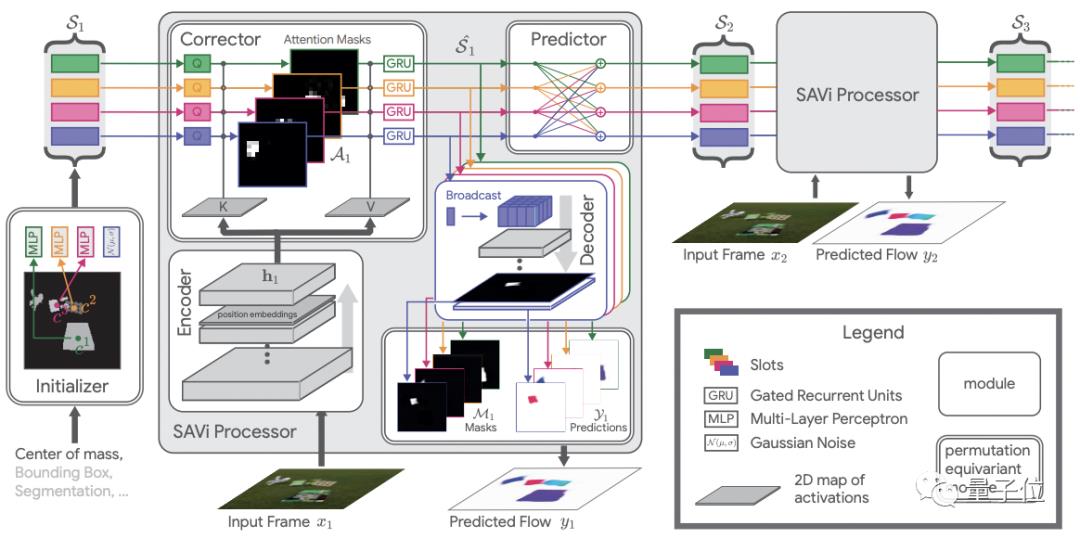
在训练中,每个视频被分成六个6帧子序列,第一帧接收提示信号,每帧两轮slot注意力。
在完全无监督视频分割中,研究人员以64的batch size训练了十万步。
没有提示,也能进行简单视频的分割和跟踪
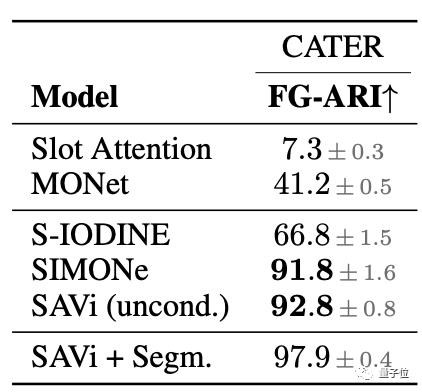
在CATER数据集上,测试表明,SAVi架构完全适用于无监督的物体表示学习。
在光流条件监督的情况下,SAVi在MOVi数据集上获得72.1%的mIoU,比基线模型CRW和T-VOS分别高了近30%和近20%。
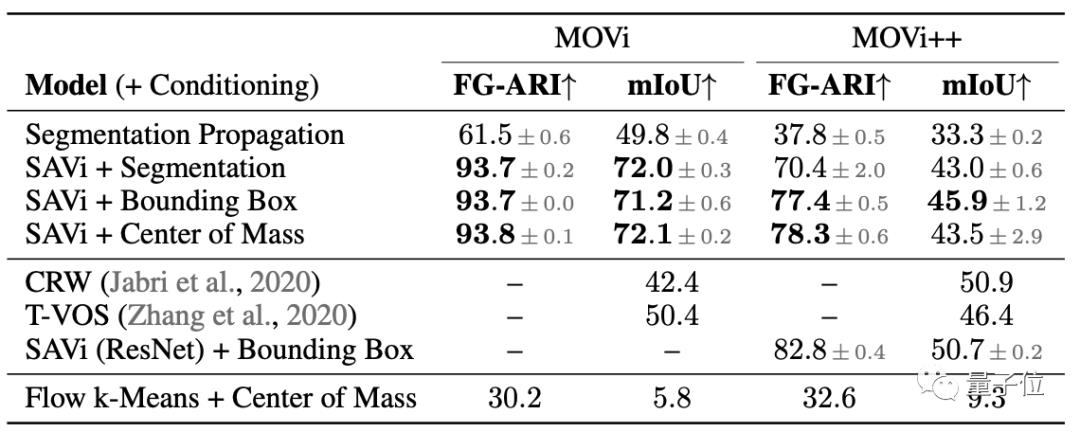
SAVi在MOVi++数据集上的mIoU得分为45.9%,比T-VOS略高一点,比CRW低了5%。
另外,还可以看到,在第一帧图像上给出质心形式的提示效果会比边界框好一点,但区别不大。
值得注意的是,即使没有任何提示,该方法也能分割一些具有简单纹理的动态场景,比如在数据集Sketchy上。

不过,在将SAVi完全用于现实世界里的复杂视频时,还有一些挑战需克服:
1、所采用的训练方法假设在训练时光流信息是可用的,而在真实视频中,这不一样有;
2、研究中所涉及的都是一些简单物体的基本运动,现实远比这个复杂。
最后,作者表示,SAVi在分割和跟踪方面仍然表现出色,在第一帧给出提示信息的做法也可能会衍生出各种相关的半监督方法。
论文地址:
https://arxiv.org/abs.2111.12594
参考链接:
[1]https://slot-attention-video.github.io/(代码即将开源)
[2]https://www.marktechpost.com/2021/11/28/google-research-open-sources-savi-an-object-centric-architecture-that-extends-the-slot-attention-mechanism-to-videos/
以上是关于注入Attention,精度涨30%!谷歌发表最新多目标“动态抠图”模型的主要内容,如果未能解决你的问题,请参考以下文章
改进YOLOv7系列:最新结合即插即用CA(Coordinate attention) 注意力机制(适用于YOLOv5),CVPR 2021 顶会助力分类检测涨点!
YOLOv7YOLOv5改进多种检测解耦头系列|即插即用:首发最新更新超多种高精度&轻量化解耦检测头(最新检测头改进集合),内含多种检测头/解耦头改进,高效涨点
YOLOv5/v7/v8改进最新主干系列BiFormer:顶会CVPR2023即插即用,小目标检测涨点必备,首发原创改进,基于动态查询感知的稀疏注意力机制构建高效金字塔网络架构,打造高精度检测器