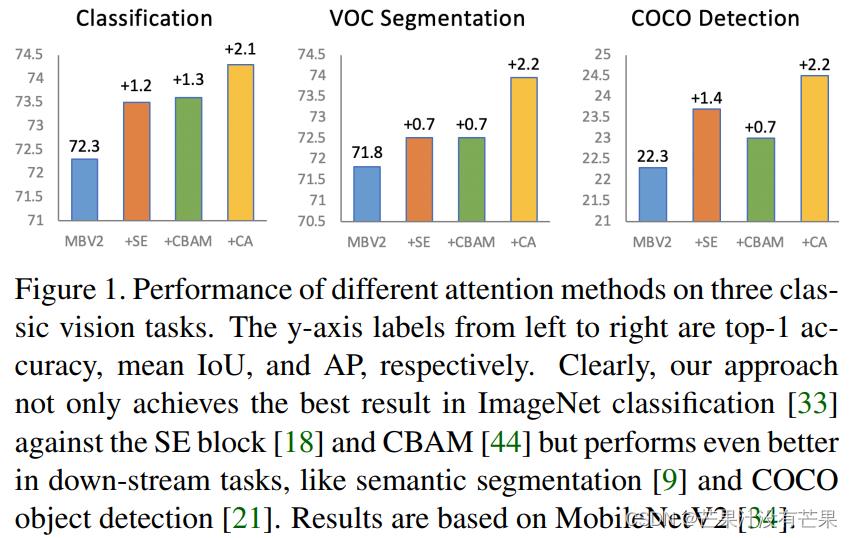
改进YOLOv7系列:最新结合即插即用CA(Coordinate attention) 注意力机制(适用于YOLOv5),CVPR 2021 顶会助力分类检测涨点!
Posted 芒果汁没有芒果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了改进YOLOv7系列:最新结合即插即用CA(Coordinate attention) 注意力机制(适用于YOLOv5),CVPR 2021 顶会助力分类检测涨点!相关的知识,希望对你有一定的参考价值。
- 💡统一使用 YOLOv5、YOLOv7 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 论文所提的
Coordinate注意力很简单,可以灵活地插入到经典的移动网络中,而且几乎没有计算开销。大量实验表明,Coordinate注意力不仅有益于ImageNet分类,而且更有趣的是,它在下游任务(如目标检测和语义分割)中表现也很好。本文结合目标检测任务应用 - 应
专栏读者的要求,写一篇关于YOLOv7+CA(Coordinate attention) 注意力机制的改进 - 重点:有不少读者已经反映该专栏的改进 在自有数据集上
有效涨点!!!同时COCO也能涨点
文章目录
一、Coordinate Attention论文理论部分

最近对移动网络设计的研究已经证明了通道注意力的显着效果(例如, Squeeze-and-Excitation 注意)用于提升模型性能,但它们通常忽略位置信息,这对于生成空间选择性注意图很重要。在本文中,我们提出了一种新的移动网络注意机制,将位置信息嵌入到通道注意中,我们称之为“坐标注意力”。与通过 2D 全局池化将特征张量转换为单个特征向量的通道注意不同,坐标注意将通道注意分解为两个 1D 特征编码过程,分别沿两个空间方向聚合特征。通过这种方式,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一个空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的注意力图,这些注意力图可以互补地应用于输入特征图以增强感兴趣对象的表示。我们的坐标注意力很简单,可以灵活地插入经典的移动网络,例如 MobileNetV2、MobileNeXt 和 EfficientNet,几乎没有计算开销。大量实验表明,我们的协调注意力不仅有利于 ImageNet 分类,而且更有趣的是,在对象检测和语义分割等下游任务中表现得更好。代码可在 大量实验表明,我们的协调注意力不仅有利于 ImageNet 分类,而且更有趣的是,在对象检测和语义分割等下游任务中表现得更好。代码可在 大量实验表明,我们的协调注意力不仅有利于 ImageNet 分类,而且更有趣的是,在对象检测等下游任务中表现得更好。。
Coordinate Attention介绍
Mobile Network设计的最新研究成果表明,通道注意力(例如,SE注意力)对于提升模型性能具有显著效果,但它们通常会忽略位置信息,而位置信息对于生成空间选择性attention maps是非常重要。
因此在本文中,作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。
与通过2维全局池化将特征张量转换为单个特征向量的通道注意力不同,coordinate注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。
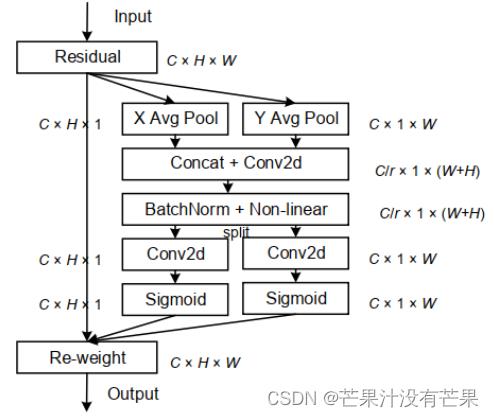
Coordinate Attention设计

图 2:提议的坐标注意块 © 与经典 SE 通道注意块的示意图比较[18] (a) 和 CBAM [44] (b)。这里,“GAP”和“GMP”分别指的是全局平均池化和全局最大池化。“X Avg Pool”和“Y Avg Pool”分别指一维水平全局池和一维垂直全局池。
Coordinate Attention Block
论文实验
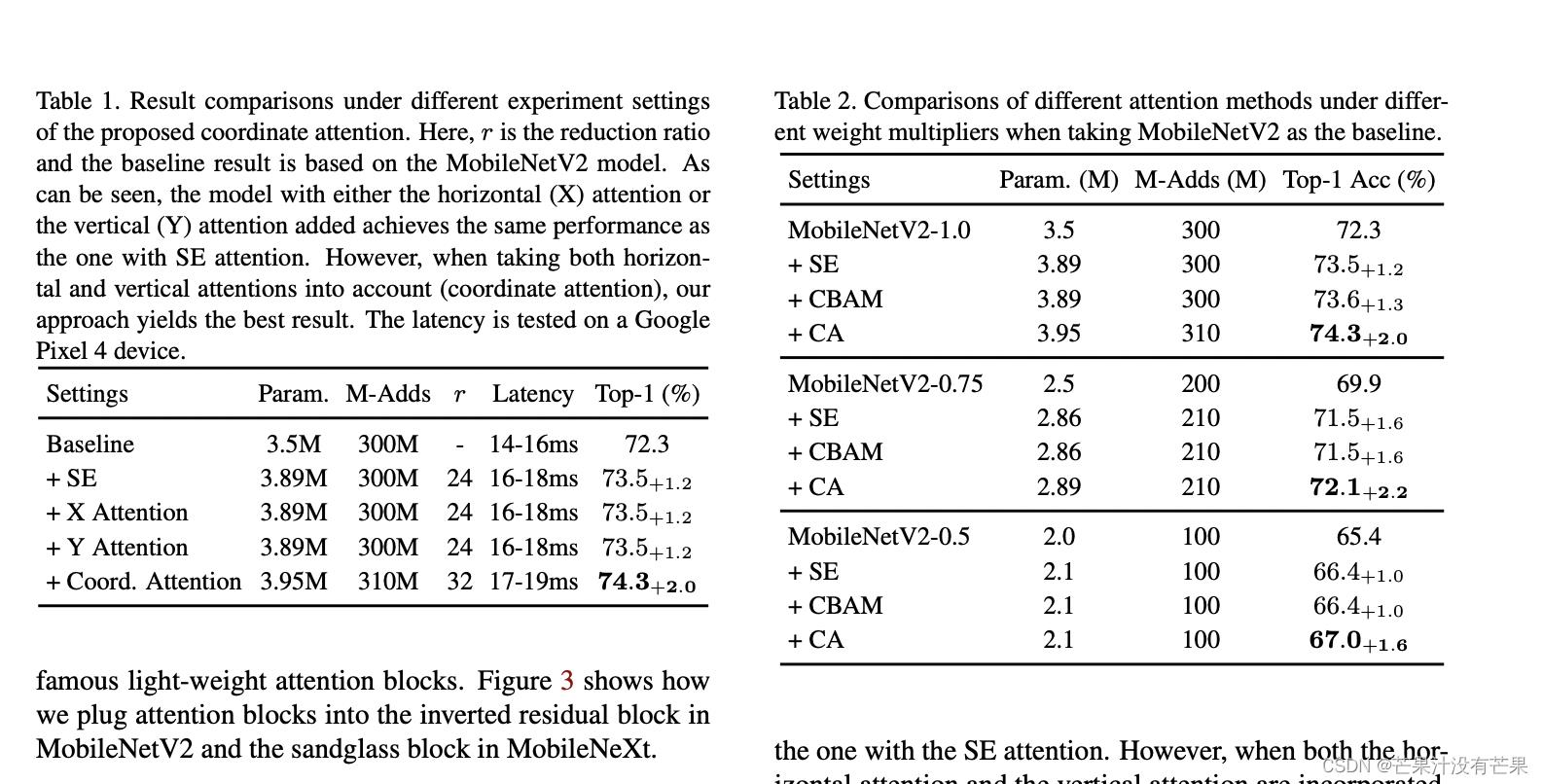
当水平注意力和垂直注意力结合时得到了最好的结果,如表1所示实验结果表明,Coordinate Information Embedding在图像分类中,可以在保证参数量的情况下提升精度。
与其他Attention注意力机制进行比较,如表2所示可以看出,添加SE attention已经使分类性能提高了1%以上。对于CBAM与SE注意相比,似乎在Mobile Network中没有提升。然而,当使用本文所提出的CA注意力时,取得了最好的结果。
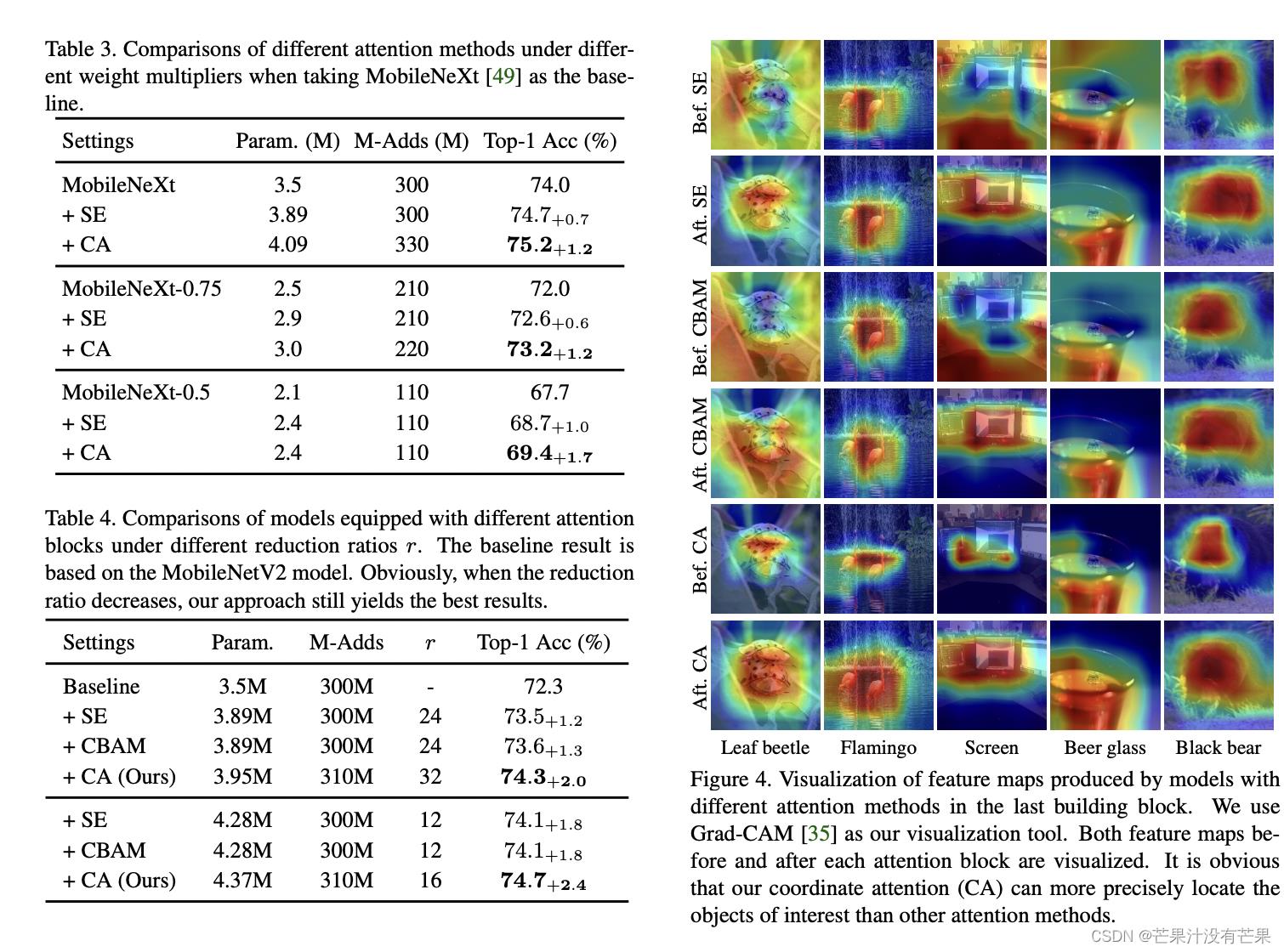
在上图中,作者还将使用不同注意力方法的模型生成的特征图进行了可视化。显然,CA注意力比SE和CBAM更有助于目标的定位。
二、结合YOLOv7 改进代码
2.1 网络配置
1.增加YOLOv7_CA.yaml文件
# YOLOv7 🚀, GPL-3.0 license
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1.0 # layer channel iscyy multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, CNeB, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]],
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, CNeB, [1024]],
[-1, 1, Conv, [256, 3, 1]],
]
# yolov7 head by iscyy
head:
[[-1, 1, SPPCSPC, [512]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[31, 1, Conv, [256, 1, 1]],
[[-1, -2], 1, Concat, [1]],
[-1, 1, C3, [128]],
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[18, 1, Conv, [128, 1, 1]],
[[-1, -2], 1, Concat, [1]],
[-1, 1, C3, [128]],
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, CA, [128]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 44], 1, Concat, [1]],
[-1, 1, C3, [256]],
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 39], 1, Concat, [1]],
[-1, 3, C3, [512]],
# 检测头 -----------------------------
[49, 1, RepConv, [256, 3, 1]],
[55, 1, RepConv, [512, 3, 1]],
[61, 1, RepConv, [1024, 3, 1]],
[[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.2 核心代码
1.在common中新增以下代码
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CA(nn.Module):
# Coordinate Attention for Efficient Mobile Network Design
'''
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting
model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a
novel attention mechanism for mobile iscyy networks by embedding positional information into channel attention, which
we call “coordinate attention”. Unlike channel attention
that transforms a feature tensor to a single feature vector iscyy via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding
processes that aggregate features along the two spatial directions, respectively
'''
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
pool_h = nn.AdaptiveAvgPool2d((h, 1))
pool_w = nn.AdaptiveAvgPool2d((1, w))
x_h = pool_h(x)
x_w = pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
然后在 在yolo.py中配置
找到./models/yolo.py文件下里的parse_model函数,将类名加入进去
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部
对应位置 下方只需要增加 代码
参考代码
elif m in [CA]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not outputss
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
2.3 运行
python train.py --cfg yolov7_CA.yaml
三、结合YOLOv5 改进代码
3.1 网络配置
1.增加YOLOv5_CA.yaml文件
# YOLOv5 🚀, GPL-3.0 license
# Parameters
nc: 80 # number o以上是关于改进YOLOv7系列:最新结合即插即用CA(Coordinate attention) 注意力机制(适用于YOLOv5),CVPR 2021 顶会助力分类检测涨点!的主要内容,如果未能解决你的问题,请参考以下文章