ClickHouse为什么这么快?3. 正则匹配算法 re 和 hyperscan 介绍
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse为什么这么快?3. 正则匹配算法 re 和 hyperscan 介绍相关的知识,希望对你有一定的参考价值。
一、什么是正则表达式?
如何匹配特定的字符串?
为了解决这个问题,定义一淘描述字符串特征的的模式, 用于查找、替换符合特征的字符串, 或者用来验证某个字符串是否符合指定的特征——这个模式就是“正则表达式”。
正则表达式最初的想法源于1940年,神经生理学家Waarren McCulloch与Walter Pitts 研究出了一种用数学方式来描述神经网络的模型,他们将神经系统中的神经为元描述成小而简单的自动控制元。
1951年, 数学家Stephen Kleene利用被他称为"正则集合"的数学符号来描述此化模型,这种表达式称为"正则表达式", 正则表达式从此成为现实。之后1968年, UNIX操作系统之父Ken Thhompson将这套符号系统引入了他的文本编辑器qed, 这种编辑器后来成了UNIXed编辑器的基础,并由ed将正则表达式引入了grep。自此以后,正则表込式被广泛地应用到各种UNIX操作系统或类UNIX操作系统中。
正则表达式是一种强大、便捷、高效的文本处理工具,其赋予了了使用者描述和分析文本的能力。从更高的层面上来说,正则表达式允许使用者掌控自己的数据为自己服务"。
掌握正则表达式,就是掌握自己的数据。
二、Hyperscan简介:一款来自Intel的高性能的开源正则表达式匹配库
Hyperscan,基于自动机(Automata) [备注0]的引擎,经过了多年开发(2008年起),2015年10月开源,这给使用DPI引擎的厂家多了一个参考选择,以往常用的库多采用PCRE,现在hyperscan可以基于DPDK提升30%的性能,对于X86架构的产品是个福音。Hyperscan 经过不断优化与完善,效率非常之高,虽然没有 pcre[备注1] 等对正则语法支持全面,但非常适用于网络设备。用户可以在网络设备数据面(Data Plane)使用hyperscan进行规则匹配,实现高性能DPI/lPS/IDS等应用。之前开源的dpdk,搭配hyperscan,简直是双剑合璧。
1) hyperscan = high performance pcre
2) 2 mode: block mode, stream mode
3) 2 space to be allcated: scratch space, stream state( for stream mode only)
Hyperscan is a high-performance multiple regex matching library available as open source with a C API. Hyperscan uses hybrid automata techniques to allow simultaneous matching of large numbers of regular expressions across streams of data.
官方主页:https://www.hyperscan.io/
源代码:https://github.com/intel/hyperscan
Developer’s Reference Guide:http://intel.github.io/hyperscan/dev-reference/
[备注0]:有限自动机(Finite Automata Machine)是计算机科学的重要基石,它在软件开发领域内通常被称作有限状态机(Finite State Machine),是一种应用非常广泛的软件设计模式。自动机 (Automata) 原来是模仿人和动物的行动而做成的机器人的意思。但是现已被抽象化为如下的机器: 时间是离散的(t=0,1,2……),在每一个时刻它处于所存在的有限个内部状态中的一个。对每一个时刻给予有限个输入中的一个。那么下一个时刻的内部状态就由现在的输入和现在的内部状态所决定。每个时刻的输出只由那个时刻的内部状态所决定。作为自动机的例子可以举出由McCulloch-pitts的神经模型组合所得到的神经网络模型、数字计算机等。
[备注1]:PCRE - Perl Compatible Regular Expressions
The PCRE library is a set of functions that implement regular expression pattern matching using the same syntax and semantics as Perl 5. PCRE has its own native API, as well as a set of wrapper functions that correspond to the POSIX regular expression API. The PCRE library is free, even for building proprietary software.
PCRE was originally written for the Exim MTA, but is now used by many high-profile open source projects, including Apache, PHP, KDE, Postfix, and Nmap. PCRE has also found its way into some well known commercial products, like Apple Safari. Some other interesting projects using PCRE include Chicken, Onyx, Hypermail, Leafnode, Askemos, Wenlin, and 8th.
在支持PCRE的大部分语法的前提下,Hyperscan增加了特定的语法和工作模式来保证其在真实网络场景下的实用性。
与此同时,大量高效算法及 Intel SIMD* 指令的使用实现了 Hyperscan 的高性能匹配。 Hyperscan适用于部署在诸如DPI/IPS/IDS/FW等场景中,目前已经在全球多个客户网络安全方案中得到实际的应用。此外,Hyperscan还支持和开源IDS/IPS产品Snort(https://www.snort.org)和Suricata (https://suricata-ids.org)集成,使其应用更加广泛。
Hyperscan算法原理
Hyperscan 以自动机理论为基础,其工作流程主要分成两个部分:编译期(compile time)和运行期(run-time)。
编译期
Hyperscan 自带 C++编写的正则表达式编译器。如图1所示,它将正则表达式作为输入,针对不同的IA平台,用户定义的模式及特殊语法,经过复杂的图分析及优化过程,生成对应的数据库。另外,生成的数据库可以被序列化后保存在内存中,以供运行期提取使用。
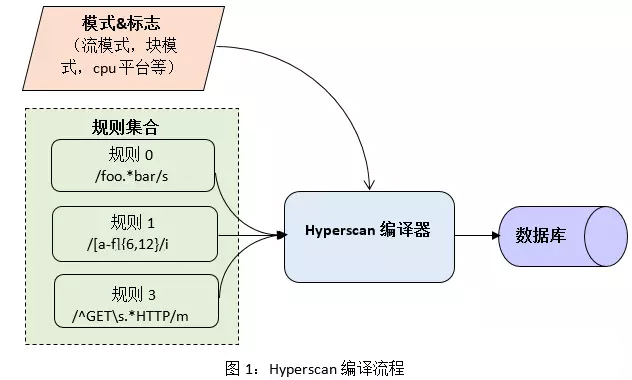
编译过程需要依据扫描的数据类型选用对应的模式:
1. 流模式(Streaming mode)目标数据是持续的流,多个数据块顺序扫描并匹配。多次函数调用期间,每一条流都需要一块内存来记录其扫描状态。
2. 块模式(Block mode)目标数据块各自独立,每个数据块可在一次函数调用中完成扫描,无需额外的记录空间。
3. 矢量模式(Vectored mode)目标数据包含一系列非连续的数据块,但是所有数据块可在一次函数调用中完成扫描,因此无需额外的记录空间。
运行期
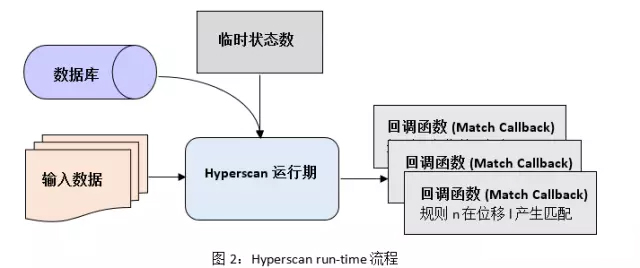
Hyperscan 的运行期是通过 C语言来开发的。图2展示了Hyperscan在运行期的主要流程。
1.用户需要预先分配一段内存,来存储临时匹配状态信息,
2.之后利用编译生成的数据库,调用Hyperscan内部的匹配引擎(NFA, DFA等)来对输入进行模式匹配。
3.Hyperscan在引擎中使用Intel处理器所具有的SIMD指令进行加速。
4.同时,用户可以通过回调函数,来自定义匹配发生后采取的行为。
由于生成的数据库是只读的,用户可以在多个CPU核或多线程场景下,共享数据库来提升匹配扩展性。
特点
功能多样
作为纯软件产品,Hyperscan支持Intel处理器多平台的交叉编译,且对操作系统无特殊限定,同时支持虚拟机和容器场景。Hyperscan 实现了对PCRE语法的基本涵盖,对复杂的表达式例如”.*”和”[^>]*”不会有任何支持问题。在此基础上,Hyperscan增加了不同的匹配模式(流模式和块模式)来满足不同的使用场景。通过指定参数,Hyperscan能找到匹配的数据在输入流中的起始和结束位置。更多功能信息请参考http://01org.github.io/hyperscan/dev-reference/。
大规模匹配
根据规则复杂度的不同,Hyperscan能支持几万到几十万的规则的匹配。与传统正则匹配引擎不同,Hyperscan支持多规则的同步匹配。在用户为每条规则指定独有的编号后,Hypercan可以将所有规则编译成一个数据库并在匹配过程中输出所有当前匹配到的规则信息。
流模式 (streaming mode)
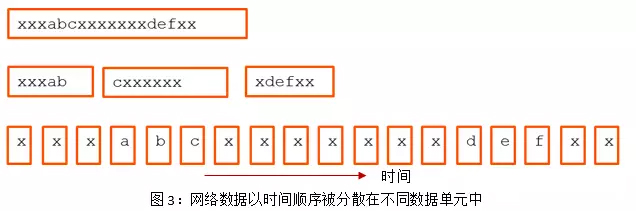
Hyperscan主要分为两种模式:块模式 (blockmode)和流模式 (streaming mode). 其中块模式为状态正则匹配引擎具有的模式,即对一段现成的完整数据进行匹配,匹配结束即返回结果。流模式是Hyperscan为网络场景下跨报文匹配设计的特殊匹配模式。在真实网络场景下,数据是分散在多报文中。若有数据在尚未到达的报文中时,传统匹配模式将无法适用。在流模式下,Hyperscan可以保存当前数据匹配的状态,并以其作为接收到新数据时的初始匹配状态。如图3所示,不管数据”xxxxabcxxxxxxxxdefx”以怎样的形式被分散在以时间顺序到达的报块中,流模式保证了最后匹配结果的一致性。另外,Hyperscan对保存的匹配状态进行了压缩以减少流模式对内存的占用。Hyperscan流模式解决了数据完整性问题,极大地简化用户网络流处理的过程。
高性能及高扩展性
Hyperscan以IntelSSSE3指令作为最低要求,使用了大量SIMD指令对匹配性能进行加速。我们基于防火墙厂商的真实规则,在Intel(R) Xeon(R) CPUE5-2699 v3 @ 2.30GHz对IPS真实网络流量进行测试。以下数据是Hyperscan的单独匹配性能(Gbps):
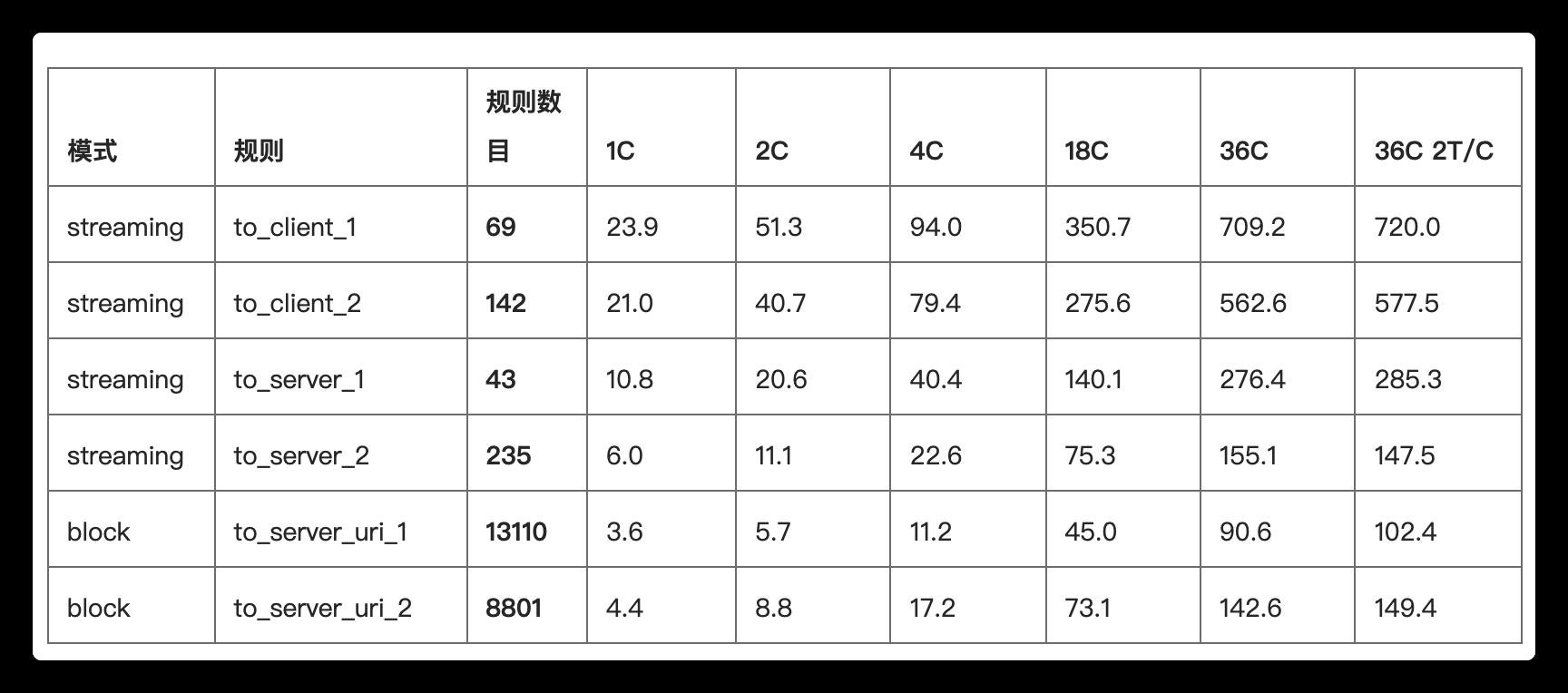
可以看到,Hyperscan在不同规则集下,单核性能可实现 3.6Gbps~23.9Gbps。
而且Hyperscan具有良好的扩展性,随着使用核数的增加,匹配性能基本处于线性增长的趋势。在网络场景中,同一规则库往往需要匹配多条网络流。Hypercan的高扩展性为此提供了有力的支持。
Hyperscan与DPDK的整合方案
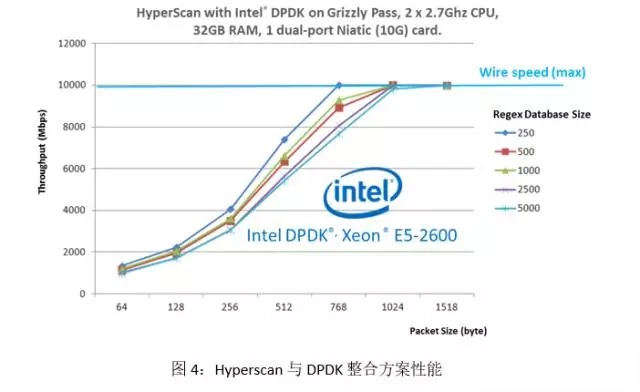
DPDK (http://dpdk.org)作为高速网络报文处理转发套件,在业界得到了极为广泛的应用。Hyperscan能与DPDK整合成为一套高性能的DPI解决方案。图4展示了Hyperscan与DPDK整合后的性能数据。我们在测试中使用了真实的规则库并以http流量作为输入。Hyperscan与DPDK的结合实现了较高的性能,且随着包大小的增长,性能可以到达物理的极限值。
性能优化建议
Hyperscan 在少量模式串时运行更快。然后随着模式串数量的增大,Hyperscan 处理速度以一种平滑的趋势变慢,而非达到某一数量阈值时的骤然降低。Hyperscan 还支持线程绑定 CPU 提高吞吐量,因此一般不需要缓冲数据来提供可用的并行处理(it is not usually necessary to buffer data to supply Hyperscan with available parallelism)。
Hyperscan 的性能受许多因素影响,主要有:
1. 模式串的数量和构成
某些模式串可以明显降低扫描性能。
2. 目标数据
包括目标数据中可以匹配或接近匹配的占比等。
3. 编译标记
4. 扫描模式
块模式下事先可以确定扫描数据的大小,拥有最高的性能。而流模式下不仅数据量未知,还需要额外存储分布在多个数据块之间的状态信息,相较而言性能最低。
5. (硬件)平台架构
Hyperscan 可以利用现代处理器的部分特性提高性能,如 Intel® Advanced Vector Extensions 2 (Intel® AVX2) 和 Intel® Bit Manipulation Instructions 2 (Intel® BMI2) 等。
总结:Hyperscan是一款基于Intel架构的成熟的正则表达式匹配库。它具有同时匹配大规模规则的强大能力,并展现了出色的匹配性能与扩展性。同时,它针对网络报文处理设计了独有的匹配模式。并且Hyperscan与DPDK的整合为DPI/IDS/IPS等产品提供了成熟高效的整套方案。
SIMD*:SIMD 单指令流多数据流(Single Instruction Multiple Data, SIMD) 是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。简单讲就是,以同步方式,在同一时间内执行同一条指令。
例子:以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。如:AMD公司引以为豪的3D NOW! 技术实质就是SIMD,这使K6-2、雷鸟、毒龙处理器在音频解码、视频回放、3D游戏等应用中显示出优异的性能。
Hyperscan正则匹配引擎QA
问题1: Hyperscan中c API包括编译和扫描两部分。那么什么是编译,什么是扫描?
答:编译就是Hyperscan根据传入的正则表达式转换对应模式数据库。就是调用,hs_compile()或hs_compile_multi()或hs_compile_ext_multi()函数的部分。而扫描就是传入数据源和回调函数,数据库,和scratch进行匹配的过程。例如块模式下调用hs_scan函数。
问题2: Hyperscan运行模式分为两种,有什么区别?
答:Hyperscan模式分为两种:
一种是块模式,块模式就是调用hs_scan函数。用户每次调用时,将对一段完成的数据块进行匹配。匹配只限于该数据块内,而与上一次的hs_scan()调用无关。
一种是流模式,在真实网络场景下,数据被拆分成多个报文发送,在只接收到部分数据流的情况下使用块模式匹配会导致跨数据流的匹配点被遗漏,可能的方法只有等全部数据流接收完成后在统一进行匹配,此举会增加内存的开销及报文处理的复杂度。
问题3:什么是草稿空间。
答:扫描数据时,Hyperscan需要少量临时内存来存储即时内部数据。hs_alloc_scratch()函数可以为给定模式数据库分配一块足够的空间。
问题4: hyperscan简单实用流程
答: (1)hs_compile_multi 更加正则表达式编译数据库。
(2)hs_alloc_scratch 创建即时数据区
(3)hs_scan 执行对应的扫描任务。
问题5: 我曾经遇到过一个难缠的问题
答:当一条流中包含规则1,规则2,规则3.当初测试hyperscan例子的时候会同时匹配上规则1,规则2,规则3.但是当用到项目中时发现匹配中了规则1,就停止了。发现错误码返回值为-3.后来发现是定义的回调函数必须加上return 0; 否则就只能匹配一条规则就终止了。并且返回值为-3.
参考资料:
https://blog.csdn.net/hhd1988/article/details/111485770
以上是关于ClickHouse为什么这么快?3. 正则匹配算法 re 和 hyperscan 介绍的主要内容,如果未能解决你的问题,请参考以下文章
ClickHouse学习笔记:ClickHouse架构概述(为什么ClickHouse这么快呢?)
大数据 OLAP ClickHouse 引擎ClickHouse 系统架构和存储引擎实现原理 : 为什么 ClickHouse 这么快? Why is ClickHouse so fast?