比Hive快279倍的数据库-ClickHouse到底是怎样的
Posted About云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了比Hive快279倍的数据库-ClickHouse到底是怎样的相关的知识,希望对你有一定的参考价值。
问题导读
1.什么是ClickHouse?
2.ClickHouse适合哪些场景?
3.为什么面向列的数据库查询如此快?
1.什么是ClickHouse
ClickHouse是一个面向列的数据库管理系统(DBMS),用于在线分析处理查询(OLAP)。
在“传统”面向行的DBMS中,数据按以下顺序存储:
换句话说,与行相关的所有值都物理地存储在彼此旁边。
面向行的DBMS的示例是mysql,Postgres和MS SQL Server。
在面向列的DBMS中,数据存储如下:
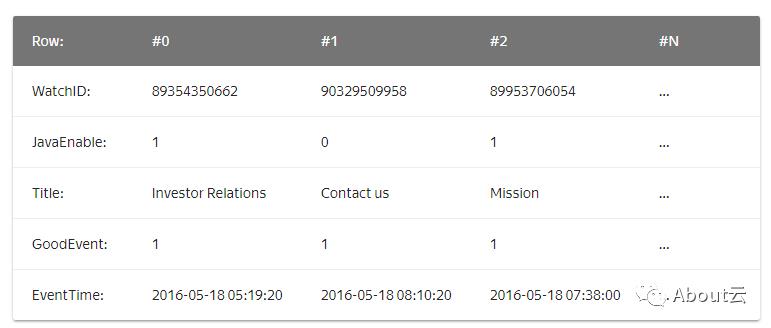
这些示例仅显示数据的排列顺序。不同列的值分别存储,同一列的数据存储在一起。
面向列的DBMS的示例:Vertica,Paraccel(Actian Matrix和Amazon Redshift),Sybase IQ,Exasol,Infobright,InfiniDB,MonetDB(VectorWise和Actian Vector),LucidDB,SAP HANA,Google Dremel,Google PowerDrill,Druid和KDB +。
存储数据的不同顺序更适合于不同的场景。数据访问场景是指进行了哪些查询,多长时间以及以何种比例进行查询;为每种类型的查询读取多少数据 - 行,列和字节;读取和更新数据之间的关系;数据大小以及如何使用本地数据;transactions是否被使用,以及它们是否隔离;数据replication和逻辑完整性的要求;每种类型的查询的延迟和吞吐量要求,等等。
系统负载越高,定制系统设置以匹配使用方案的要求就越重要,并且此定制变得越精细。没有一个系统同样适用于明显不同的场景。如果系统适应各种场景,在高负载下,系统将同样处理所有场景,或者仅适用于一种或几种可能的场景。
2.OLAP场景的关键属性
绝大多数请求都是读访问权限。
数据以相当大的批次(> 1000行)更新,而不是单行更新;或者它根本没有更新。
数据已添加到数据库,但未进行修改。
对于读取,从DB中提取了相当多的行,但只提取了一小部分列。
表格“宽”,意味着它们包含大量列。
查询相对较少(通常每台服务器数百个查询或每秒更少)。
对于简单查询,允许延迟大约50毫秒。
列值相当小:数字和短字符串(例如,每个URL 60个字节)。
处理单个查询时需要高吞吐量(每个服务器每秒最多数十亿行)。
Transactions不是必需的。
对数据一致性要求低。
每个查询有一个大表。所有表都很小,除了一个。
查询结果明显小于源数据。换句话说,数据被过滤或聚合,因此结果适合单个服务器的RAM。
很容易看出OLAP场景与其他流行场景(例如OLTP或键值访问)非常不同。 因此,如果希望获得不错的性能,尝试使用OLTP或键值DB来处理分析查询是没有意义的。 例如,如果尝试使用MongoDB或Redis进行分析,则与OLAP数据库相比,性能会非常差。
3.为什么面向列的数据库在OLAP场景中更好地工作
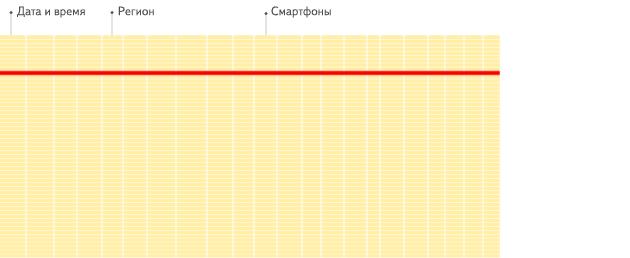
面向列的数据库更适合OLAP场景:它们在处理大多数查询时至少快100倍。 原因在下面详细解释,但事实更容易在视觉上展示:
面向行的DBMS
面向列的DBMS
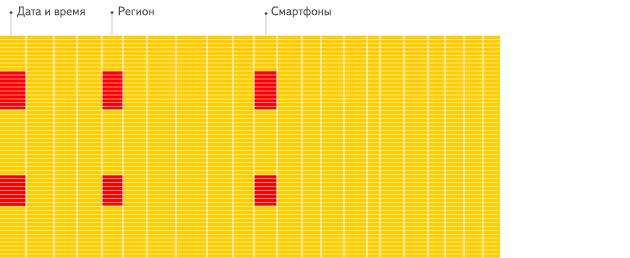
看到不同?
输入/输出
对于分析查询,只需要读取少量表列。 在面向列的数据库中,只能读取所需的数据。 例如,如果需要100列中的5列,则可以预期I / O减少20倍。
由于数据以数据包形式读取,因此更容易压缩。 列中的数据也更容易压缩。 这进一步减少了I / O量。
由于I / O减少,更多数据适合系统缓存。
例如,查询“计算每个广告平台的记录数”需要读取一个“广告平台ID”列,其占用未压缩的1个字节。 如果大多数流量不是来自广告平台,则可以预期此列的压缩率至少为10倍。 当使用快速压缩算法时,数据解压缩可以每秒至少几千兆字节的未压缩数据的速度进行。 换句话说,可以在单个服务器上以每秒大约几十亿行的速度处理该查询。 这种速度实际上是在实践中实现的。
例子:
[Bash shell] 纯文本查看 复制代码
?
|
01
以上是关于比Hive快279倍的数据库-ClickHouse到底是怎样的的主要内容,如果未能解决你的问题,请参考以下文章 |