模型论文阅读——Transformer15.Hourglass
Posted isLauraL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型论文阅读——Transformer15.Hourglass相关的知识,希望对你有一定的参考价值。
期刊
预发表arXiv
论文背景
Transformer模型在很多不同的领域都取得了SOTA,包括自然语言,对话,图像,甚至音乐。每个Transformer体系结构的核心模块是注意力模块,它为一个输入序列中的所有位置对计算相似度score。
然而,Transformer在输入序列的长度较长时效果不佳,因为它需要计算时间呈平方增长来产生所有相似性得分,以及存储空间的平方增长来构造一个矩阵存储这些score,因此将它们扩展到长序列(如长文档或高分辨率图像)是非常费时费内存的。
对于需要长距离注意力的应用,目前已经提出了几种快速且更节省空间的方法,如常见的稀疏注意力。
稀疏注意力机制通过从一个序列而不是所有可能的Pair中计算经过选择的相似性得分来减少注意机制的计算时间和内存需求,从而产生一个稀疏矩阵而不是一个完整的矩阵。
这些稀疏条目可以通过优化的方法找到、学习,甚至随机化,如Performer、Sparse Transformers、Longformers、RoutingTransformers、Reformers和BigBird。
虽然,稀疏注意力引入了许多技术来修改注意机制,但是,整体Transformer的架构并没有改变。这些稀疏注意机制降低了自我注意的复杂性,但仍然迫使模型要处理与输入相同长度的序列。
为了缓解这些问题,来自谷歌、OpenAI和华沙大学的团队提出了一种新的用于语言建模的高效Transformer架构,称之为Hourglass。
论文内容
思路建立
思路生成:
For generative Transformer models, operating at the granularity of the input sequence is necessary at least in the early and final layers, as the input must be processed at first and generated at the end . But forcing the models to operate at this granularity throughout the layer stack has both fundamental and practical shortcomings:
这种思路的两种弊端:
• Fundamentally we aim for the models to create high level representations of words, entities or even whole events – which occur at a very different granularity than single letters that the model receives on input.
• On the practical side, even layers with linear complexity can be very slow and memory-intensive when processing very long sequences at the wrong granularity.
解决这两种弊端的方法:
To alleviate these issues, we propose to change the Trans- former architecture to first shorten the internal sequence of activations when going deeper in the layer stack and then expand it back before generation.
(这部分不影响理解,不翻译了)
方法

The architecture starts with pre vanilla layers – a stack of Transformer blocks operating on the full token-level sequence. After them we insert shortening layer where k is shorten factor parameter. The sequence is shifted right before shortening, to prevent information leak. Then we recursively insert another Hourglass block operating on k times smaller scale. On the final level of shortening, we apply shortened layers – Transformer blocks operating on the smallest scale. Upsampling layer brings the resulting activations x′ back to the original resolution. After upsampling and residual, the activations are processed by token-level post vanilla layers.
① 经过 vanilla 层(有个论文提出的模型是vanilla transformer,没看过,想了解看原文叭)—— 处理的是原本完整的token
② 序列进行右移(详细看下文模型部分的解释)——防止信息泄露
③ 经过缩短层 —— 参数 k
④ Hourglass模块 —— 进行k次来缩小序列的规模
⑤ 在缩短层的最后一层使用 Transformer——让 transformer 在最小的规模上操作
⑥上采样——让序列回到原始大小
⑦ 再经过 vanilla 层
模型
总模型图:
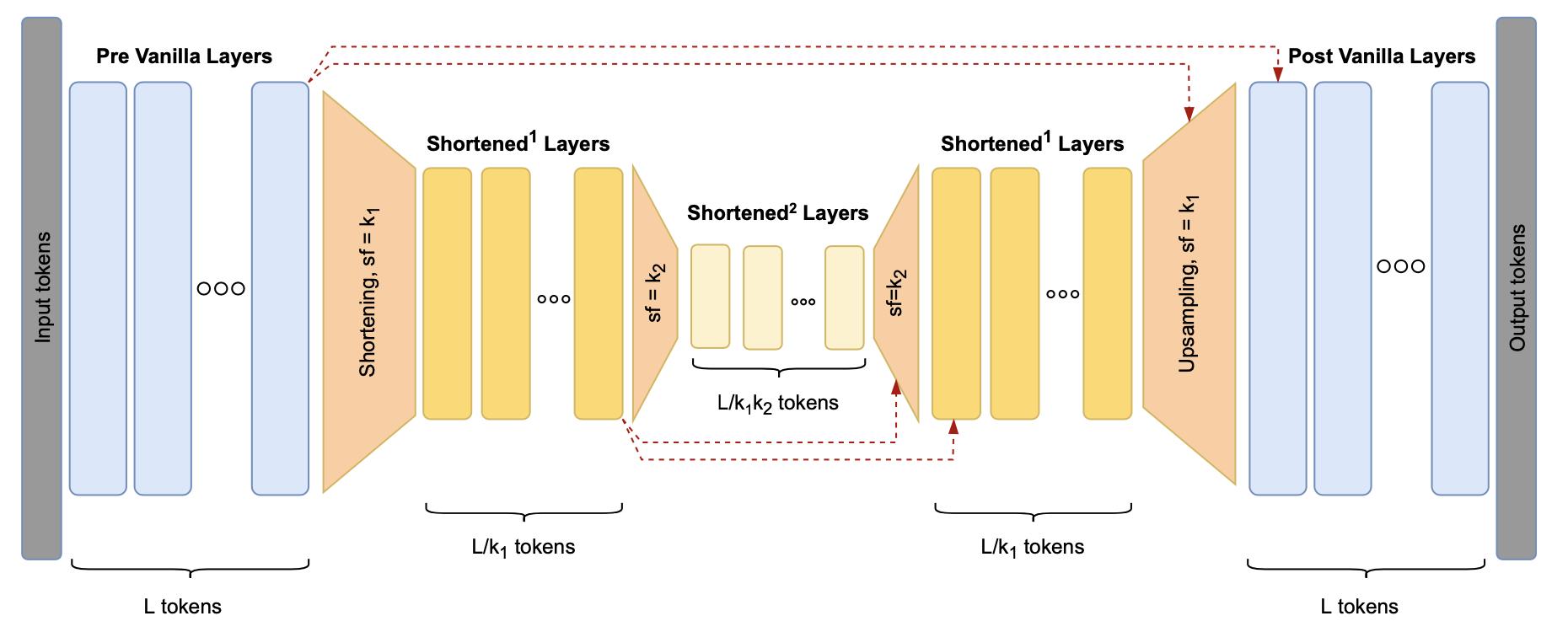
从左至右:
输入长序列L tokens vanilla层 → \\underrightarrow\\text vanilla层 vanilla层 L tokens 右移 → \\underrightarrow\\text 右移 右移 缩短k1 → \\underrightarrow\\text 缩短k1 缩短k1 L / k 1 L/k_1 L/k1 tokens 缩短k2 → \\underrightarrow\\text 缩短k2 缩短k2 L / ( k 1 k 2 ) L/(k_1k_2) L/(k1k2)tokens Transformer → \\underrightarrow\\text Transformer Transformer 上采样k2 → \\underrightarrow\\text上采样k2 上采样k2 L / k 1 L/k_1 L/k1 tokens 上采样k1 → \\underrightarrow\\text 上采样k1 上采样k1 L tokens
右移部分模型图:
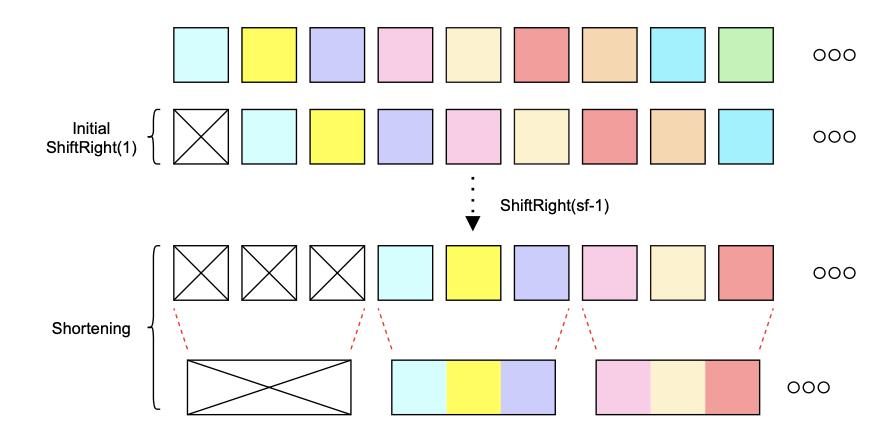
initial ShiftRight(1) 是TransformerLM(语言模型)的标准操作;
想要缩短序列,并且保证信息不泄露(可以理解为:语言模型标准操作是右移一个token,也就是第一个token为空,那么在缩短后的序列上操作,也要满足第一个token为空),需要再次右移(k-1)个tokens,图中可以看出缩小了3倍,因此k为3,也可以看出图中再次右移了2个tokens。
一个信息泄露的例子:
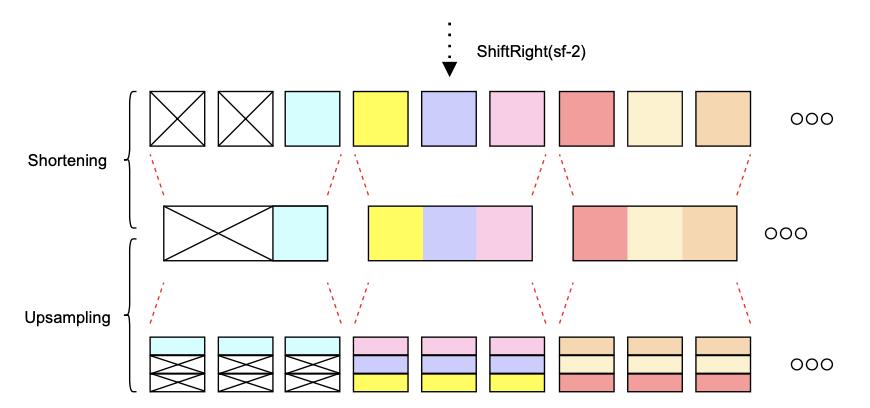 (没看懂为什么这样就信息泄露了)
(没看懂为什么这样就信息泄露了)
消融实验
1.Scaling shortened layers
【证明缩短层或者是在缩短后的序列上进行操作是有效的】
固定vanilla layer层数
k都为3

(作者表述,在过拟合之前,16层可以达到对复杂度的降低最好)
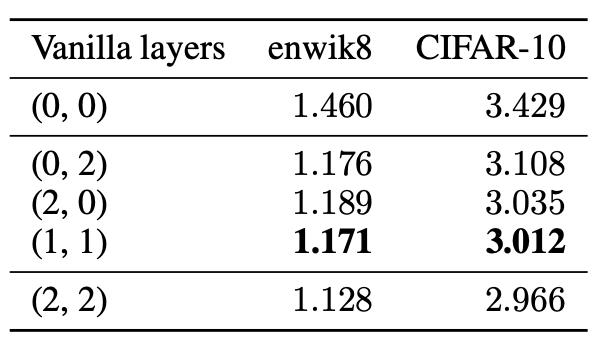
2.Impact of vanilla layers
证明vanilla层数的增加是否会提高Hourglass的性能
3.Upsampling method

4.Pooling method

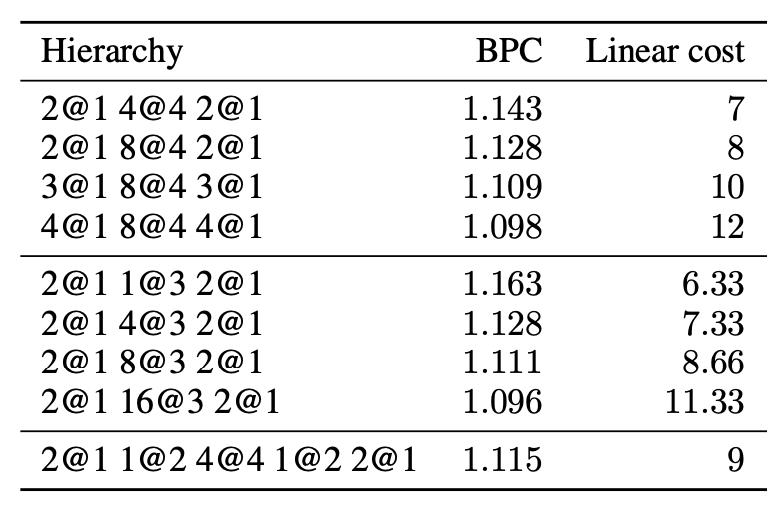
5.Shortening strategies
证明使用多大的缩短因子,采用单阶段缩短还是多阶段缩短
以上是关于模型论文阅读——Transformer15.Hourglass的主要内容,如果未能解决你的问题,请参考以下文章
1月学习进度1/31——论文阅读01“Attention is All You Need”——Transformer模型
论文泛读129Transformer 语言模型可以使用哪些上下文特征?
论文阅读之Enhancing Transformer with Sememe Knowledge(2020)
论文泛读151Transformer-F:具有学习通用句子表示的有效方法的 Transformer 网络
论文阅读A Transformer-based Approach for Source Code Summarization
论文阅读A Transformer-based Approach for Source Code Summarization