论文阅读A Transformer-based Approach for Source Code Summarization
Posted 知识的芬芳和温柔的力量全都拥有的小王同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读A Transformer-based Approach for Source Code Summarization相关的知识,希望对你有一定的参考价值。
目录
发表于 ACL 2020
地址:https://arxiv.org/pdf/2005.00653.pdf
代码:https://github.com/wasiahmad/NeuralCodeSum
一、简介
利用transformer模型来进行代码摘要生成,通过对代码token之间的成对关系建模以捕获其长期依赖来学习代码表示。实验部分和其他一些baselines作了对比,验证了模型达到了最优性能。并通过实验证明了,使用相对位置表示对源代码token之间的成对关系进行建模,相对于使用绝对位置表示的学习代码token的序列信息,可以实现重大改进。并在transformer中整合了复制注意力机制,其能够从源代码复制稀有标记(如:函数名称,变量名称),从而显著提高摘要性能。
二、方法
整体基于transformer方法,但除了transformer里的自注意力机制,还整合了复制注意力机制,并使用相对位置表示对源代码token之间的成对关系进行建模。
- 复制注意力:文章在Transformer中整合了copying mechanism复制机制,以允许既根据词汇生成单词又根据输入源代码进行复制。使用额外的注意力层来学习解码器堆栈顶部的复制分布。Copy Attention使Transformer能够从源代码复制稀有标记(例如,函数名称,变量名称),从而显著提高摘要性能。
- Encoding pairwise relationship:代码的语义表示不依赖于其token的绝对位置。相反,它们之间的相互影响会影响源代码的含义。例如,表达式a + b a + ba+b和b + a b + ab+a的语义相同。为了对输入元素之间的成对关系进行编码,将自我注意机制进行了扩展:(第j个token位于第i个token的左侧还是右侧的信息将被忽略)(位置编码部分还没有看的很明白)
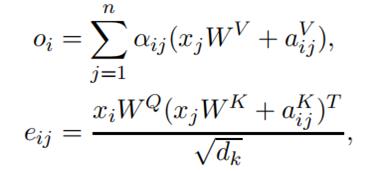
数据预处理:论文将CamelCase和snake_case形式的源代码token拆分为相应的sub-tokens(CamelCase和snake_case token化显著减少了词汇量。例如,Java源代码中唯一token的数量从292,626减少到66,650)。证明了这样的代码token拆分可以提高摘要性能。
评价指标:BLEU、METEOR、ROUGE-L
三、实验
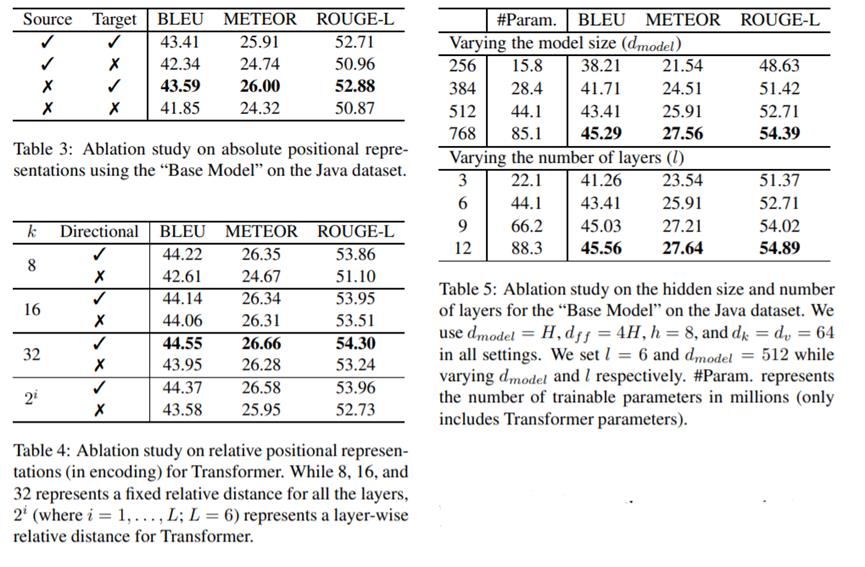
以上是关于论文阅读A Transformer-based Approach for Source Code Summarization的主要内容,如果未能解决你的问题,请参考以下文章