基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系...
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系...相关的知识,希望对你有一定的参考价值。
概述
本文关键词:
■ OLAP
■ Multidimensional information systems
■ Data warehousing
■ Databases
■ Decision support systems (DSS)
■ Executive information systems (EIS)
■ Business intelligence (BI)
■ Business analytics
■ Data mining
■ Data visualization
■ Knowledge management (KM)
What is ClickHouse ?
ClickHouse® is an open-source column-oriented database management system that allows generating analytical data reports in real-time.
A fast analytical DBMS.

ClickHouse is an open-source column-oriented DBMS (columnar database management system) for online analytical processing (OLAP) that allows users to generate analytical reports using SQL queries in real-time.
Its technology works 100-1000x faster than traditional database management systems, and processes hundreds of millions to over a billion rows and tens of gigabytes of data per server per second. With a widespread user base around the globe, the technology has received praise for its reliability, ease of use, and fault tolerance.
架构图
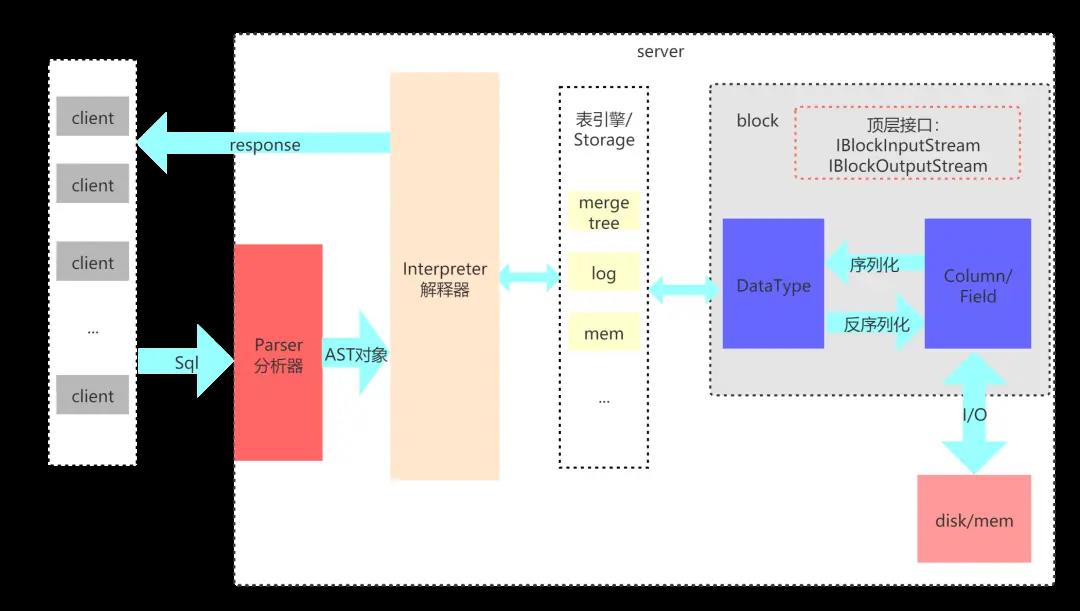
1)Parser与Interpreter
Parser和Interpreter是非常重要的两组接口:Parser分析器是将sql语句已递归的方式形成AST语法树的形式,并且不同类型的sql都会调用不同的parse实现类。而Interpreter解释器则负责解释AST,并进一步创建查询的执行管道。Interpreter解释器的作用就像Service服务层一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。首先它会解析AST对象;然后执行"业务逻辑" ( 例如分支判断、设置参数、调用接口等 );最终返回IBlock对象,以线程的形式建立起一个查询执行管道。
2)表引擎
表引擎是ClickHouse的一个显著特性,上文也有提到,clickhouse有很多种表引擎。不同的表引擎由不同的子类实现。表引擎是使用IStorage接口的,该接口定义了DDL ( 如ALTER、RENAME、OPTIMIZE和DROP等 ) 、read和write方法,它们分别负责数据的定义、查询与写入。
3)DataType
数据的序列化和反序列化工作由DataType负责。根据不同的数据类型,IDataType接口会有不同的实现类。DataType虽然会对数据进行正反序列化,但是它不会直接和内存或者磁盘做交互,而是转交给Column和Filed处理。
4)Column与Field
Column和Field是ClickHouse数据最基础的映射单元。作为一款百分之百的列式存储数据库,ClickHouse按列存储数据,内存中的一列数据由一个Column对象表示。Column对象分为接口和实现两个部分,在IColumn接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以及用于过滤的filter方法等。而这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和ColumnTuple等。在大多数场合,ClickHouse都会以整列的方式操作数据,但凡事也有例外。如果需要操作单个具体的数值 ( 也就是单列中的一行数据 ),则需要使用Field对象,Field对象代表一个单值。与Column对象的泛化设计思路不同,Field对象使用了聚合的设计模式。在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
5)Block
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了流的形式。虽然Column和Filed组成了数据的基本映射单元,但对应到实际操作,它们还缺少了一些必要的信息,比如数据的类型及列的名称。于是ClickHouse设计了Block对象,Block对象可以看作数据表的子集。Block对象的本质是由数据对象、数据类型和列名称组成的三元组,即Column、DataType及列名称字符串。Column提供了数据的读取能力,而DataType知道如何正反序列化,所以Block在这些对象的基础之上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过Block对象就能完成一系列的数据操作。在具体的实现过程中,Block并没有直接聚合Column和DataType对象,而是通过ColumnWith TypeAndName对象进行间接引用。
源代码
https://github.com/ClickHouse/ClickHouse/
源码阅读:https://clickhouse.com/codebrowser/html_report/ClickHouse/index.html
快速开始
安装:https://clickhouse.com/docs/en/getting-started/install/
教程:https://clickhouse.com/docs/en/getting-started/tutorial/
curl -O 'https://builds.clickhouse.com/master/macos/clickhouse' && chmod a+x ./clickhouse
OLAP 引子
Key Properties of OLAP Scenario
The vast majority of requests are for read access.
Data is updated in fairly large batches (> 1000 rows), not by single rows; or it is not updated at all.
Data is added to the DB but is not modified.
For reads, quite a large number of rows are extracted from the DB, but only a small subset of columns.
Tables are “wide,” meaning they contain a large number of columns.
Queries are relatively rare (usually hundreds of queries per server or less per second).
For simple queries, latencies around 50 ms are allowed.
Column values are fairly small: numbers and short strings (for example, 60 bytes per URL).
Requires high throughput when processing a single query (up to billions of rows per second per server).
Transactions are not necessary.
Low requirements for data consistency.
There is one large table per query. All tables are small, except for one.
A query result is significantly smaller than the source data. In other words, data is filtered or aggregated, so the result fits in a single server’s RAM.
It is easy to see that the OLAP scenario is very different from other popular scenarios (such as OLTP or Key-Value access). So it does not make sense to try to use OLTP or a Key-Value DB for processing analytical queries if you want to get decent performance. For example, if you try to use MongoDB or Redis for analytics, you will get very poor performance compared to OLAP databases.
OLAP场景的关键属性:
绝大多数请求都是为了读取访问。
数据以相当大的批次(>1000行)更新,而不是按单行更新;或者根本不更新。
数据被添加到数据库中,但不被修改。
对于读取,从数据库中提取了相当大量的行,但只有一小部分列。
表是"宽的",这意味着它们包含大量列。
查询相对较少(通常每台服务器每秒数百个查询或更少)。
对于简单的查询,允许大约50毫秒的延迟。
列值相当小:数字和短字符串(例如,每个URL60字节)。
处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)。
交易是没有必要的。
对数据一致性要求低。
每个查询都有一个大表。 所有的桌子都很小,除了一个。
查询结果明显小于源数据。 换句话说,数据被过滤或聚合,因此结果适合单个服务器的RAM。
很容易看出,OLAP场景与其他流行场景(如OLTP或键值访问)有很大不同。 因此,如果您想获得体面的性能,尝试使用OLTP或键值数据库来处理分析查询是没有意义的。 例如,如果您尝试使用MongoDB或Redis进行分析,与OLAP数据库相比,您将获得非常差的性能。
The different meanings of OLAP:
OLAP:On-Line Analytical Processing
OLAP 使用户几乎可以立即访问来自多维数据仓库的信息,以他们喜欢的任何方式查看信息,并清晰地指定和执行复杂的计算。
OLAP enables users to access information from multidimensional data warehouses almost instantly, to view information in any way they like, and to cleanly specify and carry out sophisticated calculations.
The Functional Requirements of OLAP Systems
In short, the functional requirements for OLAP are as follows:
■ 具有多层次参考的丰富维度结构
■ 高效的维度规范和维度计算
■ 结构(structure)和表示(representation)的分离
■ 灵活性
■ 快速即席分析
■ 多用户支持
■ Rich dimensional structuring with hierarchical referencing
■ Efficient specification of dimensions and dimensional calculations
■ Separation of structure and representation
■ Flexibility
■ Sufficient speed to support ad hoc analysis
■ Multi-user support
这些需求源于信息处理的永恒目标,决策支持与事务处理的不同优化需求、描述性建模与面向决策的信息处理的其他递归阶段的不同功能需求、不同计算架构层之间的应用范围区别,以及在全球 2000 强企业范围内经常发现的挑战。
These requirements derive from the timeless goals of information processing, the
distinct optimization requirements for decision support versus transaction processing,
the distinct functional requirements for descriptive modeling versus other recursive
stages of decision-oriented information processing, the application range distinction
between different layers of computing architectures, and the challenges frequently
found within the boundaries of Global 2000 corporations.
行存与列存
In a “normal” row-oriented DBMS, data is stored in this order:
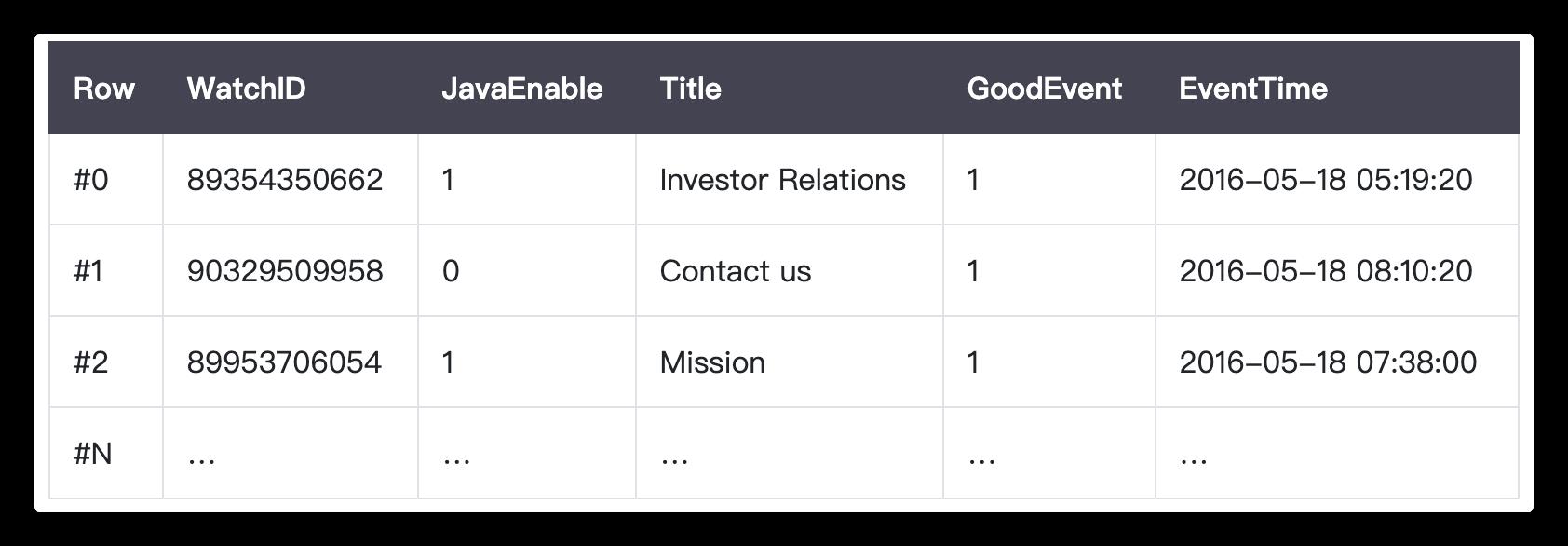
In other words, all the values related to a row are physically stored next to each other.
Examples of a row-oriented DBMS are mysql, Postgres, and MS SQL Server.
In a column-oriented DBMS, data is stored like this:
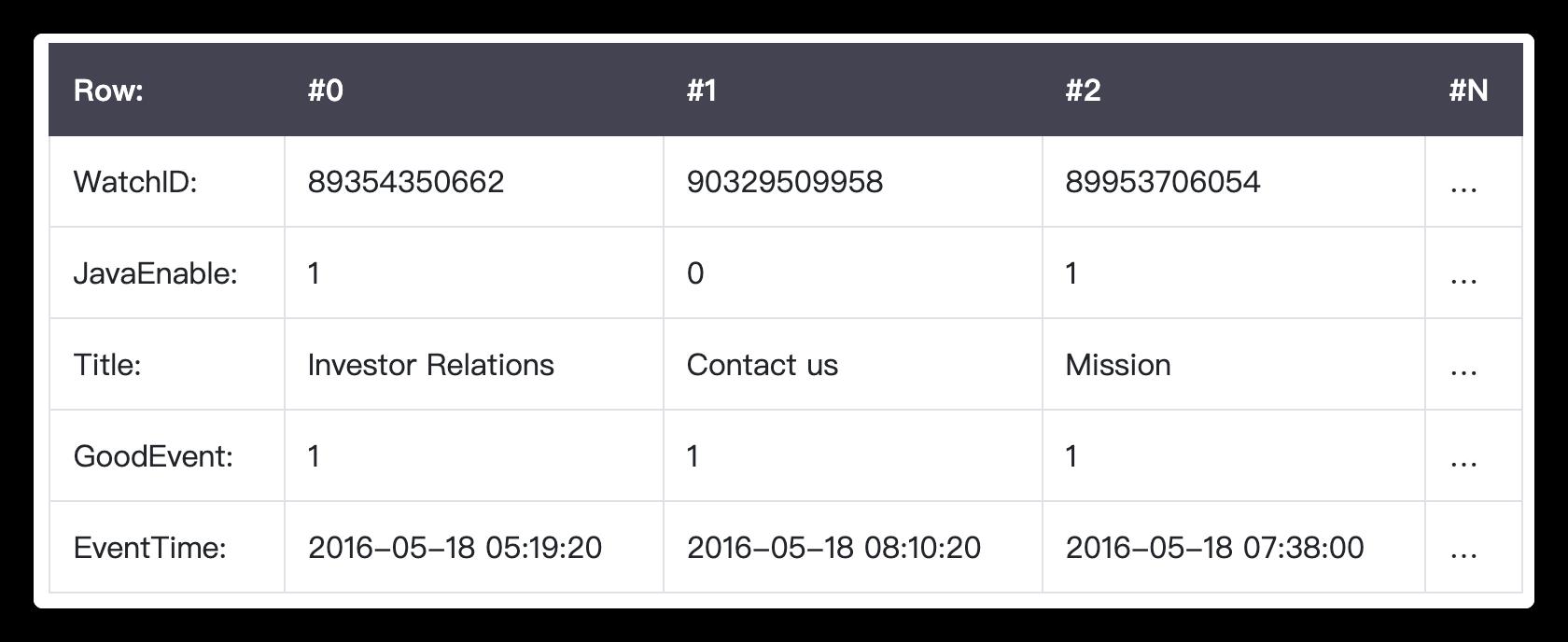
用具体的数据结构代码实例说明就是:
列式存储:
package ck
class ColumnStorageTable
var WatchID: List<String> = listOf()
var JavaEnable: List<String> = listOf()
var Title: List<String> = listOf()
var GoodEvent: List<String> = listOf()
var EventTime: List<String> = listOf()
class ColumnStorageTableData
var columnStorageTable = ColumnStorageTable()
行式存储
package ck
class RowStorageTable
var WatchID: String = ""
var JavaEnable: String = ""
var Title: String = ""
var GoodEvent: String = ""
var EventTime: String = ""
class RowStorageTableData
val lines = listOf<RowStorageTable>()
用图来形象化说明:
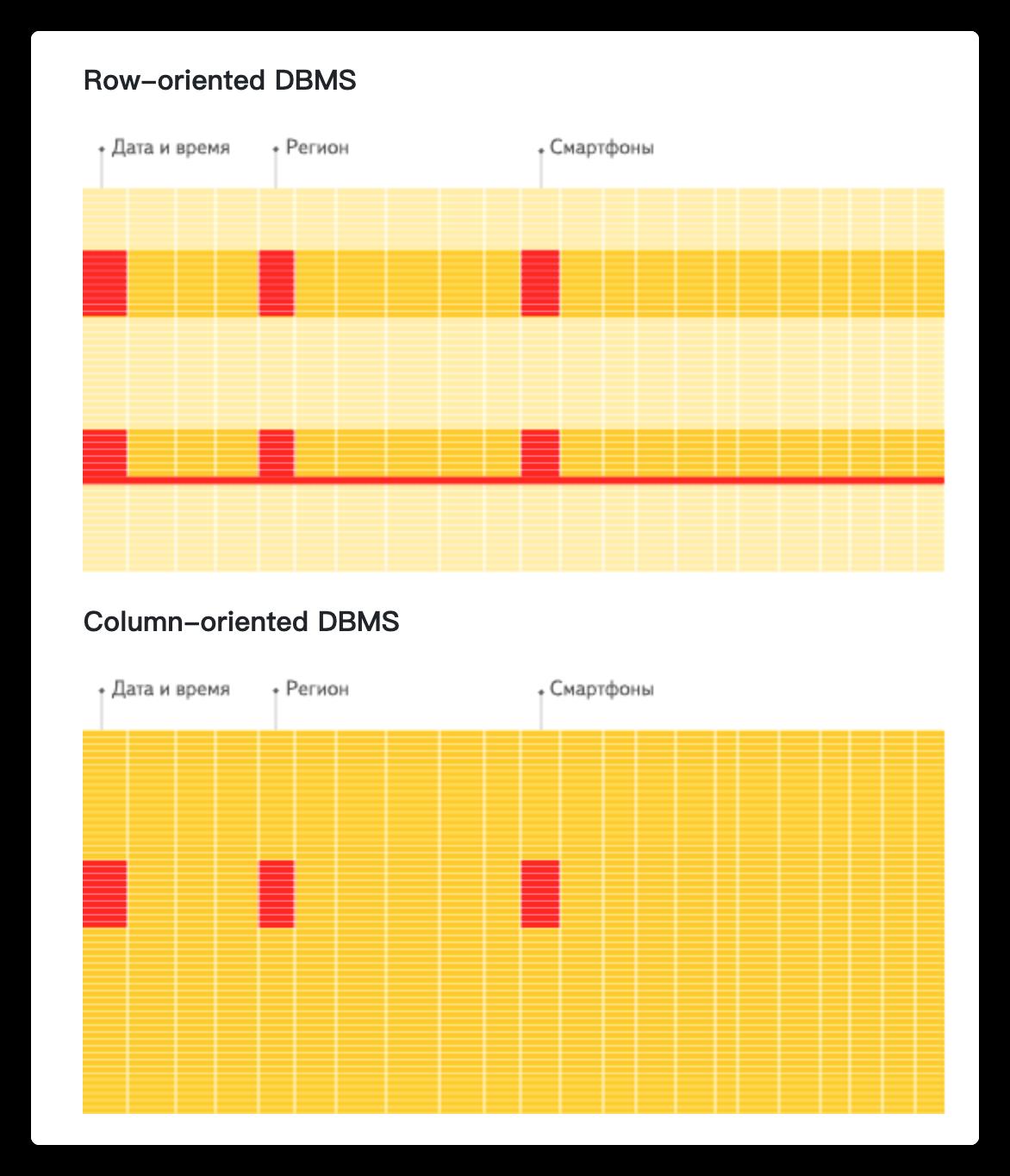
看到区别了吗?
1. 输入/输出
对于分析查询,只需要读取少量的表列。 在面向列的数据库中,您可以只读取所需的数据。 例如,如果您需要100列中的5列,则可以预期I/O减少20倍。
由于数据是在数据包中读取的,因此更容易压缩。 列中的数据也更容易压缩。 这进一步减少了I/O体积。
由于减少了I/O,更多数据适合系统缓存。
例如,查询"统计每个广告平台的记录数"需要读取一个"广告平台ID"列,该列占用未压缩的1个字节。 如果大部分流量不是来自广告平台,您可以预期此列的压缩率至少为10倍。 当使用快速压缩算法时,可以以每秒至少几千兆字节的未压缩数据的速度进行数据解压缩。 换句话说,可以在单个服务器上以大约每秒数十亿行的速度处理此查询。 这种速度实际上是在实践中实现的。
2. CPU 中央处理器
由于执行查询需要处理大量行,因此它有助于为整个向量而不是单独的行调度所有操作,或者实现查询引擎,以便几乎没有调度成本。 如果不这样做,对于任何半体面的磁盘子系统,查询解释器不可避免地会使CPU停滞不前。 将数据存储在列中并在可能的情况下按列进行处理是有意义的。
有两种方法可以做到这一点:
(1)矢量引擎。 所有操作都是针对向量编写的,而不是针对单独的值编写的。 这意味着您不需要经常调用操作,并且调度成本可以忽略不计。 操作代码包含优化的内部循环。
(2)代码生成。 为查询生成的代码中包含所有间接调用。
这不是在"normal" 数据库中完成的,因为它在运行简单查询时没有意义。 但是,也有例外。 例如,MemSQL使用代码生成来减少处理SQL查询时的延迟。 (为了进行比较,分析型DBMS需要优化吞吐量,而不是延迟。)
请注意,为了提高CPU效率,查询语言必须是声明式的(SQL或MDX),或者至少是向量(J,K)。 查询应该只包含隐式循环,允许优化。
See the difference?
1.Input/output
For an analytical query, only a small number of table columns need to be read. In a column-oriented database, you can read just the data you need. For example, if you need 5 columns out of 100, you can expect a 20-fold reduction in I/O.
Since data is read in packets, it is easier to compress. Data in columns is also easier to compress. This further reduces the I/O volume.
Due to the reduced I/O, more data fits in the system cache.
For example, the query “count the number of records for each advertising platform” requires reading one “advertising platform ID” column, which takes up 1 byte uncompressed. If most of the traffic was not from advertising platforms, you can expect at least 10-fold compression of this column. When using a quick compression algorithm, data decompression is possible at a speed of at least several gigabytes of uncompressed data per second. In other words, this query can be processed at a speed of approximately several billion rows per second on a single server. This speed is actually achieved in practice.
2.CPU
Since executing a query requires processing a large number of rows, it helps to dispatch all operations for entire vectors instead of for separate rows, or to implement the query engine so that there is almost no dispatching cost. If you do not do this, with any half-decent disk subsystem, the query interpreter inevitably stalls the CPU. It makes sense to both store data in columns and process it, when possible, by columns.
There are two ways to do this:
(1)A vector engine. All operations are written for vectors, instead of for separate values. This means you do not need to call operations very often, and dispatching costs are negligible. Operation code contains an optimized internal cycle.
(2)Code generation. The code generated for the query has all the indirect calls in it.
This is not done in “normal” databases, because it does not make sense when running simple queries. However, there are exceptions. For example, MemSQL uses code generation to reduce latency when processing SQL queries. (For comparison, analytical DBMSs require optimization of throughput, not latency.)
Note that for CPU efficiency, the query language must be declarative (SQL or MDX), or at least a vector (J, K). The query should only contain implicit loops, allowing for optimization.
典型问题场景
使用原生的 ClickHouse,在大数据量的时候会发生很多问题:
1.稳定性:ClickHouse 的原始稳定性并不好,比如说:在高频写入的场景下经常会出现 too many part 等问题,整个集群被一个慢查询拖死,节点 OOM、DDL 请求卡死都比较常见。另外,由于 ClickHouse 原始设计缺陷,随数据增长的依赖的 zookeeper 瓶颈一直存在,无法很好解决;微信后期进行多次内核改动,才使得它在海量数据下逐步稳定下来,部分 issue 也贡献给了社区。
2.使用门槛较高:会用 ClickHouse 的,跟不会用 ClickHouse 的,其搭建的系统业务性能可能要差 3 倍甚至 10 倍,有些场景更需要针对性对内核优化。
解决方案
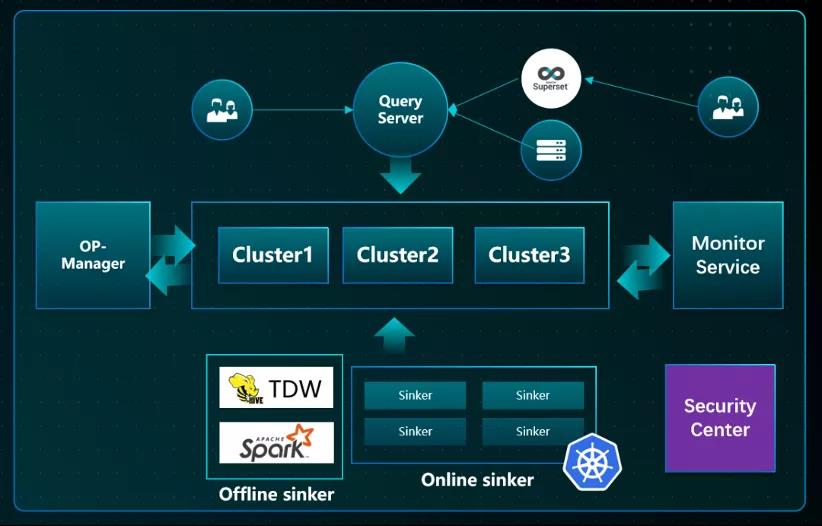
要想比较好地解决 ClickHouse 易用性和稳定性,需要生态支撑,整体的生态方案有以下几个重要的部分:
1.QueryServer:数据网关,负责智能缓存,大查询拦截,限流;
Data gateway, responsible for intelligent caching, interception of large queries, and current limiting;
2.Sinker:离线/在线高性能接入层,负责削峰、hash 路由,流量优先级,写入控频;
Offline/online high-performance access layer, responsible for peak cutting, hash routing, traffic priority, and write frequency control;
3.OP-Manager:负责集群管理、数据均衡,容灾切换、数据迁移;
Responsible for cluster management, data balancing, disaster recovery switching, and data migration;
4.Monitor:负责监控报警,亚健康检测,查询健康度分析,可与 Manager 联动;
Responsible for monitoring and alerting, sub-health testing, and health analysis, and can be linked with Manager;
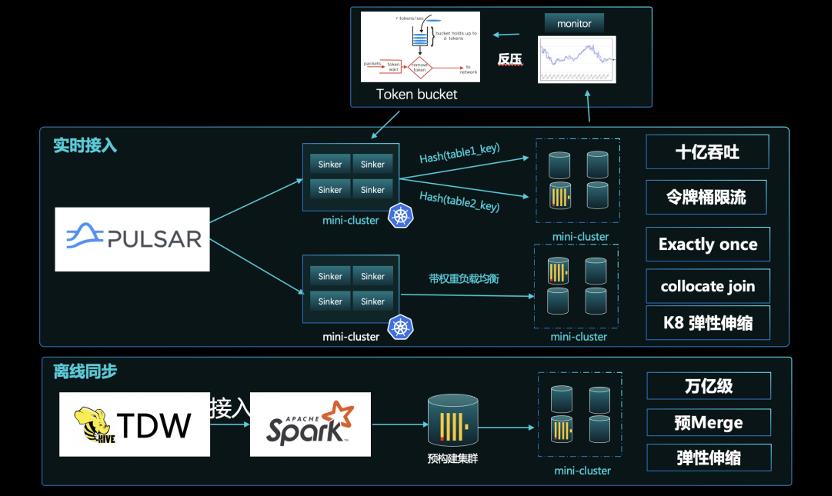
重点问题解决
1.高性能接入
(1)数据日吞吐在数十亿,实时接入方面,通过令牌、反压的方案,比较好地解决了流量洪峰的问题。
The daily data throughput is in the billions, and in terms of real-time access, the problem of peak traffic is better solved through token and back pressure solutions.
(2)通过 Hash 路由接入,使数据落地了之后可直接做 Join,无需 shuffle 实现的更快 Join 查询,在接入上也实现了精确一次。
Access is routed through Hash, so that Joins can be made directly after the data is landed. There is no need for the faster Join query implemented by shuffle, and the access is also accurate once.
(3)离线同步方案上,通过预构 Merge 成建成 Part,再送到线上的服务节点,这其实是种读写分离的思想,更便于满足高一致性、高吞吐的场景要求。
In the offline synchronization scheme, the pre-constructed Merge is used to form a Part, and then sent to the online service node. This is actually a kind of read-write separation idea, which is easier to meet the requirements of high-consistency and high-throughput scenarios.
2.极致的查询优化

ClickHouse 整个的设计哲学,要求在特定的场景下,采用特定的功能特性(选择合理的表引擎,合理分区,分片,冷热分离,排序键拆分,合理压缩LZ4等),才能得到最极致的性能。
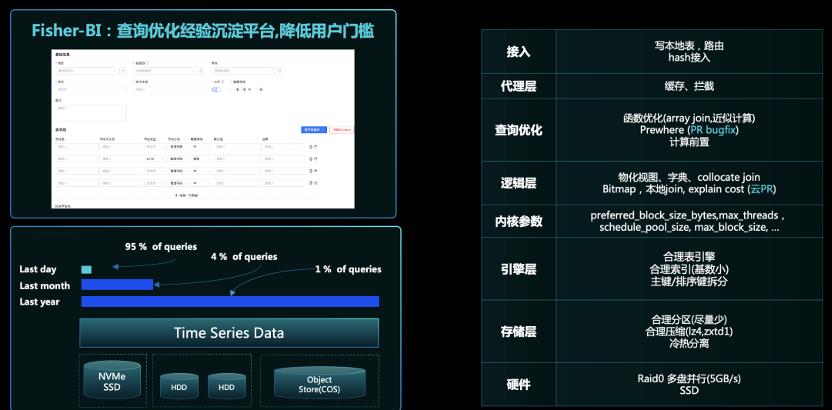
基于共建的 ClickHouse 生态,应用于典型应用场景:
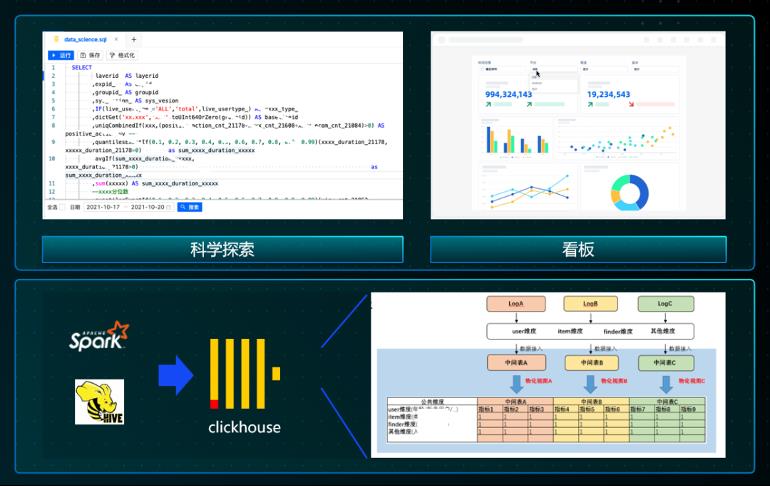
1.BI 分析/看板:由于科学探索是随机的,很难通过预构建的方式来解决,用 Hadoop 的生态只能实现小时到分钟的级别。使用 ClickHouse 单表万亿的数据量,查询 P95 在 5 秒以内。数据科学家现在想做一个验证,非常快就可以实现。
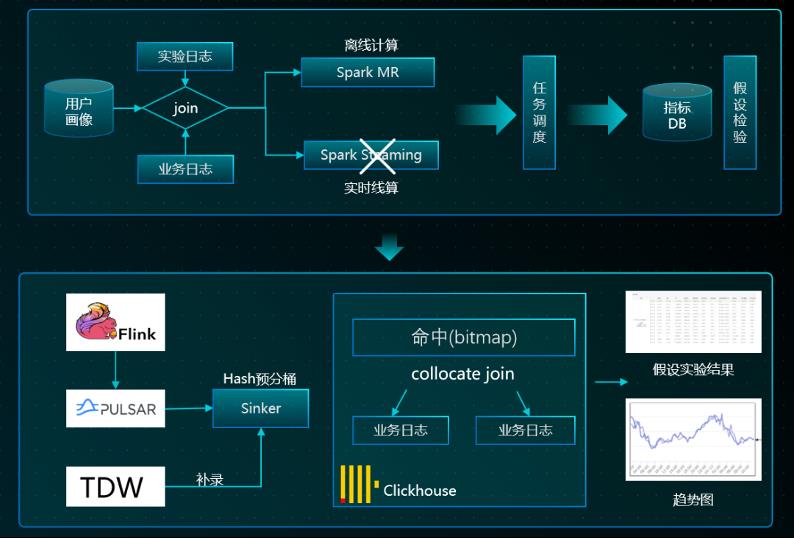
2.A/B 实验平台:早期做 A/B 实验的时候,前一天晚上要把所有的实验统计结果,预先聚合好,第二天才能查询实验结果。在单表数据量级千亿 / 天、大表实时 Join 的场景下,,从离线到实时分析的飞跃,使得 P95 响应<3S,A/B 实验结论更加准确,实验周期更短 ,模型验证更快。
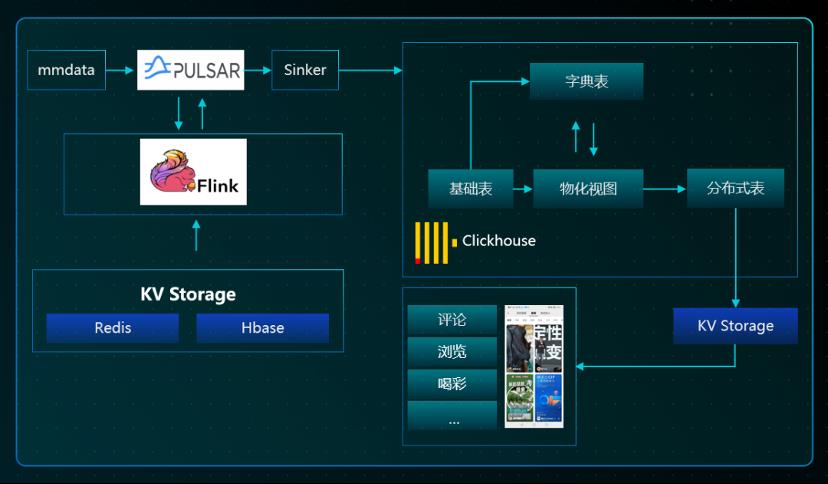
3.实时特征计算:虽然大家普遍认为 ClickHouse 不太擅长解决实时相关的问题,但最终通过优化,可以做到扫描量数十亿,全链路时延<3 秒,P95 响应近 1 秒。
性能的显著提升
集群规模1000台机器,数据量 PB 级,每天的查询量上百万,单集群 TPS 达到了亿级,而查询耗时均值仅需秒级返回。
ClickHouse OLAP 的生态相对于之前的 Hadoop 生态,性能提升了 10 倍以上,通过流批一体提供更稳定可靠的服务,使得业务决策更迅速,实验结论更准确。
存算分离的云原生数仓
ClickHouse 原始的设计和 Shard-Nothing 的架构,无法很好地实现秒级伸缩与 Join 的场景;实现存算分离的云原生数仓可以解决这个问题。
1.弹性扩容:秒级弹性能力,实现高峰查询更快,低峰成本更省;
2.稳定性:无 ZK 瓶颈,读写易分离,异地容灾;
3.易运维:数据容易均衡,存储无状态;
4.功能全:专注于查询优化与 Cache 策略、支持高效多表 Join;
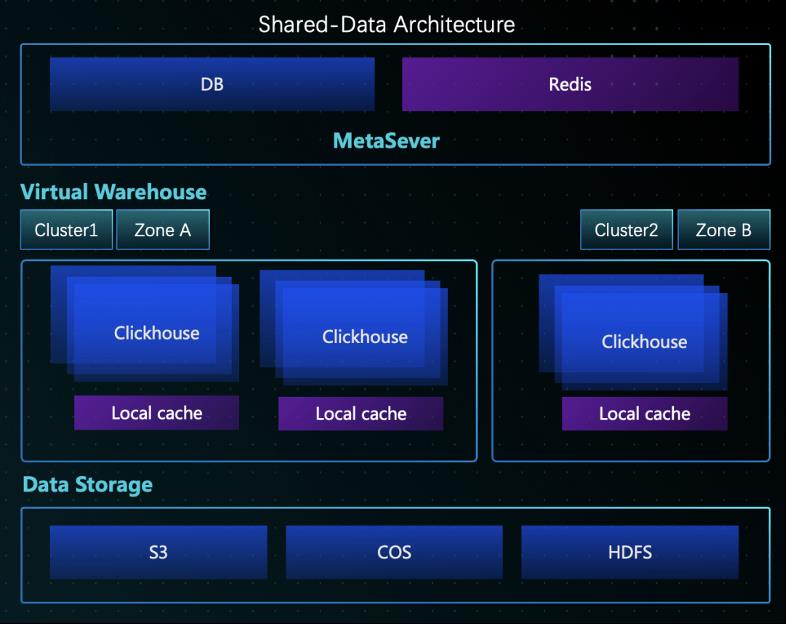
数据分片与分布式查询
Clickhouse拥有分布式能力,自然支持数据分片,数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段。ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表 ( Local Table ) 与分布式表 ( Distributed Table ) 的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
ClickHouse 稀疏索引
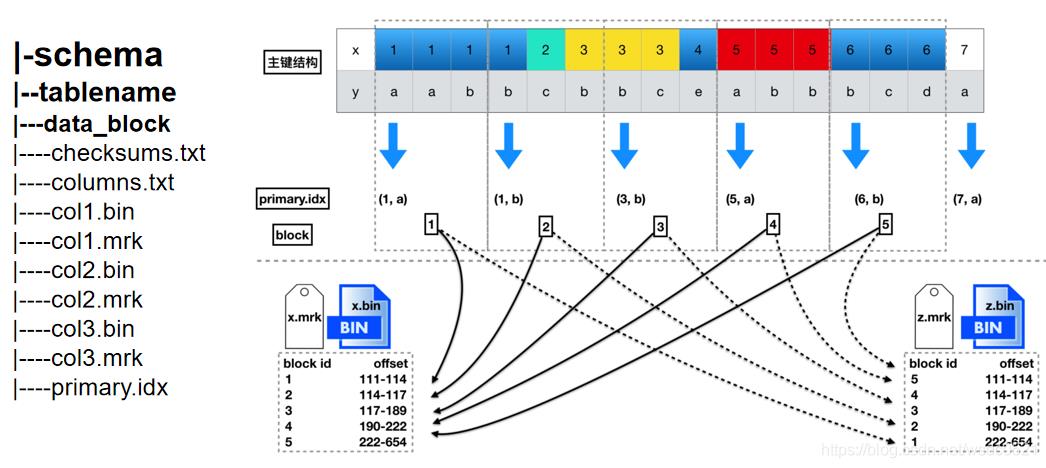
左边的结构图为/var/lib/clickhouse/data/default(schema)/(tablename)/.bin(列文件) .mrk(块偏移量) primary.idx主键索引
主键是有序数据的稀疏索引。我们用图的方式看一部分的数据(原则上,图中应该保持标记的平均长度,但是用ASCI码的方式不太方便)。 mark文件,就像一把尺子一样。主键对于范围查询的过滤效率非常高。对于查询操作,CK会读取一组可能包含目标数据的mark文件。
MergeTree引擎中,默认的index_granularity(索引粒度)设置是8192;
在CH里,主键索引用的并不是B树,而是稀疏索引。
每隔8192行数据,是1个block 主键会每隔8192,取一行主键列的数据,同时记录这是第几个block 查询的时候,如果有索引,就通过索引定位到是哪个block,然后找到这个block对应的mrk文件 mrk文件里记录的是某个block的数据集,在整列bin文件的哪个物理偏移位置 加载数据到内存,之后并行化过滤 索引长度越低,索引在内存中占的长度越小,排序越快,然而区分度就越低。这样不利于查找。 索引长度越长,区分度就高,虽然利于查找了,但是索引在内存中占得空间就多了。
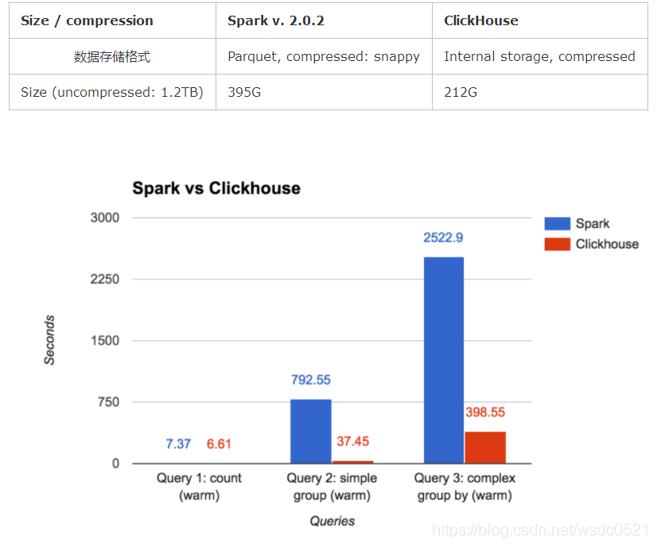
性能对比:
参考资料
https://segmentfault.com/a/1190000039292250
https://mp.weixin.qq.com/s/Hc3p2_Yx1BoSA1mR5kvNWQ
Bitsets, also called bitmaps, are commonly used as fast data structures. Unfortunately, they can use too much memory. To compensate, we often use compressed bitmaps.
Roaring bitmaps are compressed bitmaps which tend to outperform conventional compressed bitmaps such as WAH, EWAH or Concise.
https://github.com/RoaringBitmap/CRoaring
https://blog.csdn.net/wsdc0521/article/details/102837089
以上是关于基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系...的主要内容,如果未能解决你的问题,请参考以下文章
clickhouse基于ClickHouse的海量数据交互式OLAP分析场景实践
基于 EMR OLAP 的开源实时数仓解决方案之 ClickHouse 事务实现