基于 EMR OLAP 的开源实时数仓解决方案之 ClickHouse 事务实现
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 EMR OLAP 的开源实时数仓解决方案之 ClickHouse 事务实现相关的知识,希望对你有一定的参考价值。
简介:阿里云 EMR OLAP 与 Flink 团队深度合作,支持了 Flink 到 ClickHouse 的 Exactly-Once写入来保证整个实时数仓数据的准确性。本文介绍了基于 EMR OLAP 的开源实时数仓解决方案。
作者简介:阿里云 EMR-OLAP 团队;主要负责开源大数据 OLAP 引擎的研发,例如 ClickHouse,Starrocks,Trino 等。通过 EMR 产品向阿里云用户提供一站式的大数据 OLAP 解决方案。
内容框架
- 背景
- 机制梳理
- 技术方案
- 测试结果
- 未来规划
一、背景
Flink 和 ClickHouse 分别是实时流式计算和 OLAP 领域的翘楚,很多互联网、广告、游戏等客户都将两者联合使用于构建用户画像、实时 BI 报表、应用监控指标查询、监控等业务,形成了实时数仓解决方案(如图-1)。这些业务对数据的准确性要求都十分严格,所以实时数仓整个链路需要保证端到端的 Exactly-Once。
通常来说 Flink 的上游是可以重复读取或者消费的 pull-based 持久化存储(例如Kafka),要实现 Source 端的 Exactly-Once 只需要回溯 Source 端的读取进度即可。Sink 端的 Exactly-Once 则比较复杂,因为 Sink 是 push-based 的,需要依赖目标输出系统的事务保证,但社区 ClickHouse 对事务并不支持。
所以针对此情况,阿里云 EMR ClickHouse 与 Flink 团队一起深度研发,支持了 Flink 到 ClickHouse 的 Exactly-Once写入来保证整个实时数仓数据的准确性。本文将分别介绍下现有机制以及实现方案。
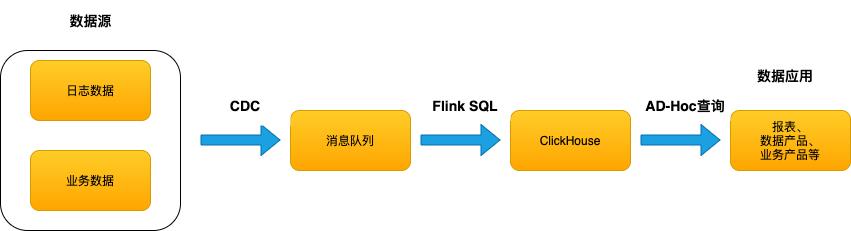
图-1 实时数仓架构
二 机制梳理
ClickHouse 写入机制
ClickHouse 是一个 MPP 架构的列式 OLAP 系统(如图-2),各个节点是对等的,通过 Zookeeper 协同数据,可以通过并发对各个节点写本地表的方式进行大批量的数据导入。
ClickHouse 的 data part 是数据存储的最小单元,ClickHouse 接收到的数据 Block 在写入时,会按照 partition 粒度进行拆分,形成一个或多个 data part。data part 在写入磁盘后,会通过后台merge线程不断的合并,将小块的 data part 合并成大块的 data part,以此降低存储和读取的开销。
在向本地表写入数据时,ClickHouse 首先会写入一个临时的 data part,这个临时 data part 的数据对客户端不可见,之后会直接进行 rename 操作,使这个临时 data part 成为正式 data part,此时数据对客户端可见。几乎所有的临时 data part 都会快速地成功被 rename 成正式 data part,没有被 rename 成功的临时 data part 最终将被 ClickHouse 清理策略从磁盘上删除。
通过上述分析,可以看出 ClickHouse 的数据写入有一个从临时 data part 转为正式 data part 的机制,加以修改可以符合两阶段提交协议,这是实现分布式系统中事务提交一致性的重要协议。
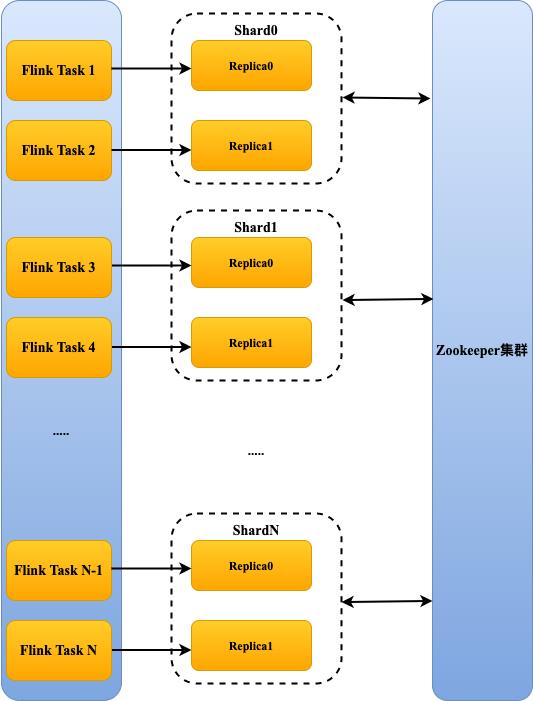
图-2 Flink 作业写入 ClickHouse
注:多个 Flink Task 可以写入同一个 shard 或 replica
Flink 写机制
Flink 作为一个分布式处理引擎,提供了基于事务的 Sink 机制,该机制可以保障写入的 Exactly-Once,相应的数据接收方需要提供遵守 XA 规范的 JDBC 。由于完整的 XA 规范相当复杂,因此,我们先对 Flink 的处理机制进行梳理,结合 ClickHouse 的实际情况,确定需要实现的接口范围。
为了实现分布式写入时的事务提交统一,Flink 借助了 checkpoint 机制。该机制能够周期性地将各个 Operator 中的状态生成快照并进行持久化存储。在 checkpoint 机制中,有一个 Coordinator 角色,用来协调所有 Operator 的行为。从 Operator 的角度来看,一次 checkpoint 有三个阶段,初始化-->生成快照-->完成/废弃 checkpoint。从Coordinator的角度来看,需要定时触发 checkpoint,以及在所有 Operator 完成快照后,触发 complete 通知。(参考附录1)
接下来介绍 Flink 中的 Operator 是如何借助事务和 checkpoint 机制来保障 Exactly-Once,Operator 的完整执行需要经过 initial、writeData、snapshot、commit 和 close 阶段。
initial 阶段:
- 从快照中取出上次任务执行时持久化的 xid 记录。快照中主要存储两种 xid,一组是未完成 snapshot 阶段的 xid,一组是已经完成了 snapshot 的 xid。
- 接下来对上次未完成 snapshot 的 xid 进行 rollback 操作;对上次已经完成了 snapshot 但 commit 未成功的 xid 进行 commit 重试操作。
- 若上述操作失败,则任务初始化失败,任务中止,进入 close 阶段;若上述操作成功,则继续。
- 创建一个新的唯一的 xid,作为本次事务ID,将其记录到快照中。
- 使用新生成的 xid,调用 JDBC 提供的 start() 接口。
writeData 阶段:
- 事务开启后,进入写数据的阶段,Operator 的大部分时间都会处于这个阶段。在与 ClickHouse 的交互中,此阶段为调用 JDBC 提供的 preparedStatement 的 addBatch() 和 executeBatch() 接口,每次写数据时都会在报文中携带当前 xid。
- 在写数据阶段,首先将数据写到 Operator 内存中,向 ClickHouse 提交内存中的批量数据有三种触发方式:内存中的数据条数达到batchsize的阈值;后台定时线程每隔一段时间触发自动flush;在 snapshot 阶段调用end() 和 prepare() 接口之前会调用flush清空缓存。
snapshot 阶段:
- 当前事务会调用 end() 和 prepare() 接口,等待 commit,并更新快照中的状态。
- 接下来,会开启一个新的事务,作为本 Task 的下一次 xid,将新事务记录到快照中,并调用 JDBC 提供的start() 接口开启新事务。
- 将快照持久化存储。
complete阶段:
在所有 Operator 的 snapshot 阶段全部正常完成后,Coordinator 会通知所有 Operator 对已经成功的checkpoint 进行 complete 操作,在与 ClickHouse 的交互中,此阶段为 Operator 调用 JDBC 提供的 commit() 接口对事务进行提交。
close 阶段:
- 若当前事务尚未进行到 snapshot 阶段,则对当前事务进行 rollback 操作。
- 关闭所有资源。
从上述流程可以总结出,Flink 通过 checkpoint 和事务机制,将上游数据按 checkpoint 周期分割成批,保障每一批数据在全部写入完成后,再由 Coordinator 通知所有 Operator 共同完成 commit 操作。当有 Operator 写入失败时,将会退回到上次成功的 checkpoint 的状态,并根据快照记录的 xid 对这一批 checkpoint 的所有 xid 进行 rollback 操作。在有 commit 操作失败时,将会重试 commit 操作,仍然失败将会交由人工介入处理。
三、技术方案
整体方案
根据 Flink 和 ClickHouse 的写入机制,可以描绘出一个Flink 到 ClickHouse 的事务写入的时序图(如图-3)。由于写的是 ClickHouse 的本地表,并且事务的统一提交由 Coordinator 保障,因此 ClickHouse 无需实现 XA 规范中标准的分布式事务,只需实现两阶段提交协议中的少数关键接口,其他接口在 JDBC 侧进行缺省即可。
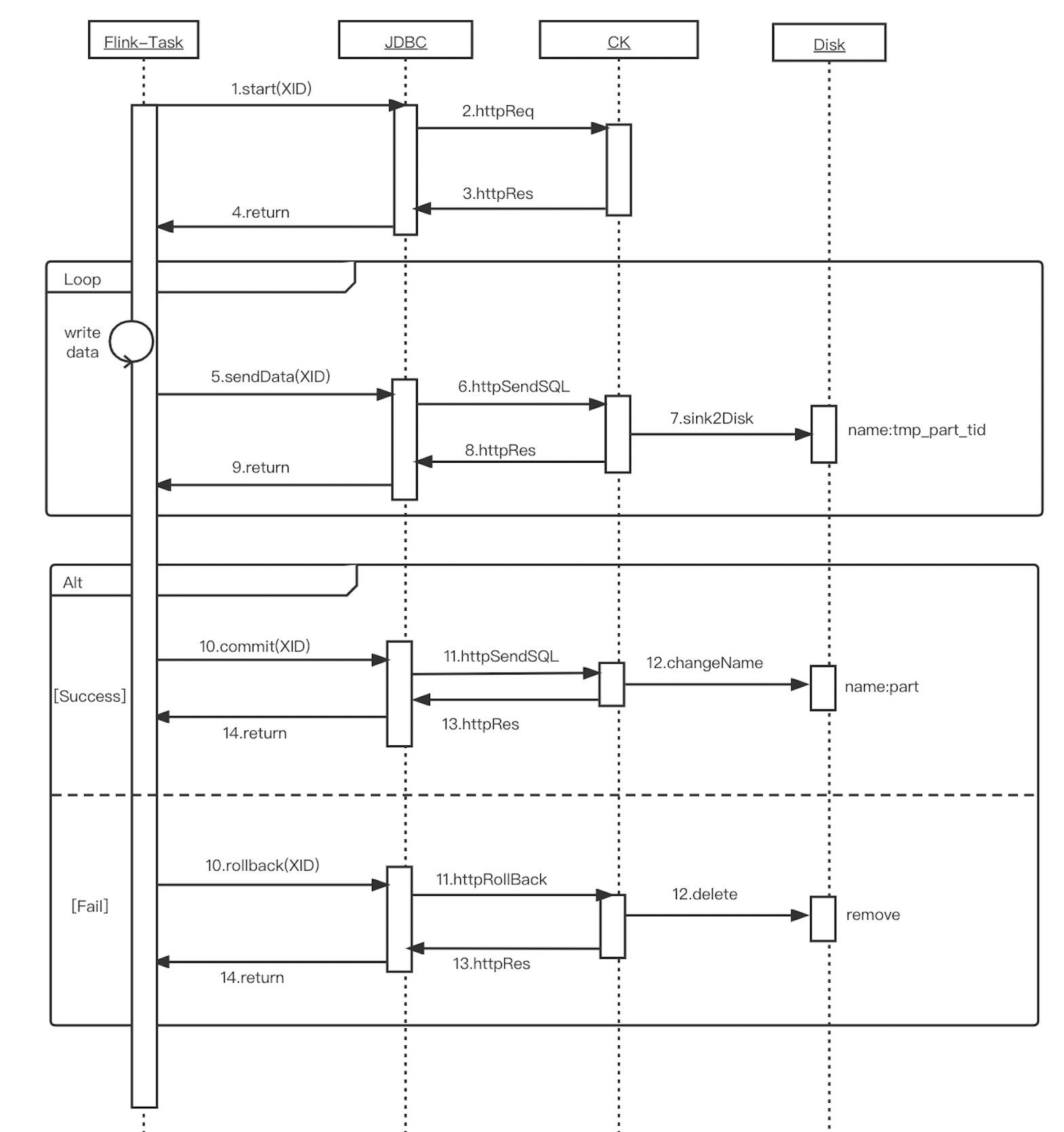
图-3 Flink 到 ClickHouse 事务写入的时序图
ClickHouse-Server
状态机
为了实现 ClickHouse 的事务,我们首先定义一下所要实现的事务允许的几种操作:
- Begin:开启一个事务。
- Write Data:在一个事务内写数据。
- Commit:提交一个事务。
- Rollback:回滚一个未提交的事务。
事务状态: - Unknown:事务未开启,此时执行任何操作都是非法的。
- Initialized:事务已开启,此时允许所有操作。
- Committing:事务正在被提交,不再允许 Begin/Write Data 两种操作。
- Committed:事务已经被提交,不再允许任何操作。
- Aborting:事务正在被回滚,不再允许任何操作。
- Aborted:事务已经被回滚,不再允许任何操作。
完整的状态机如下图-4所示:
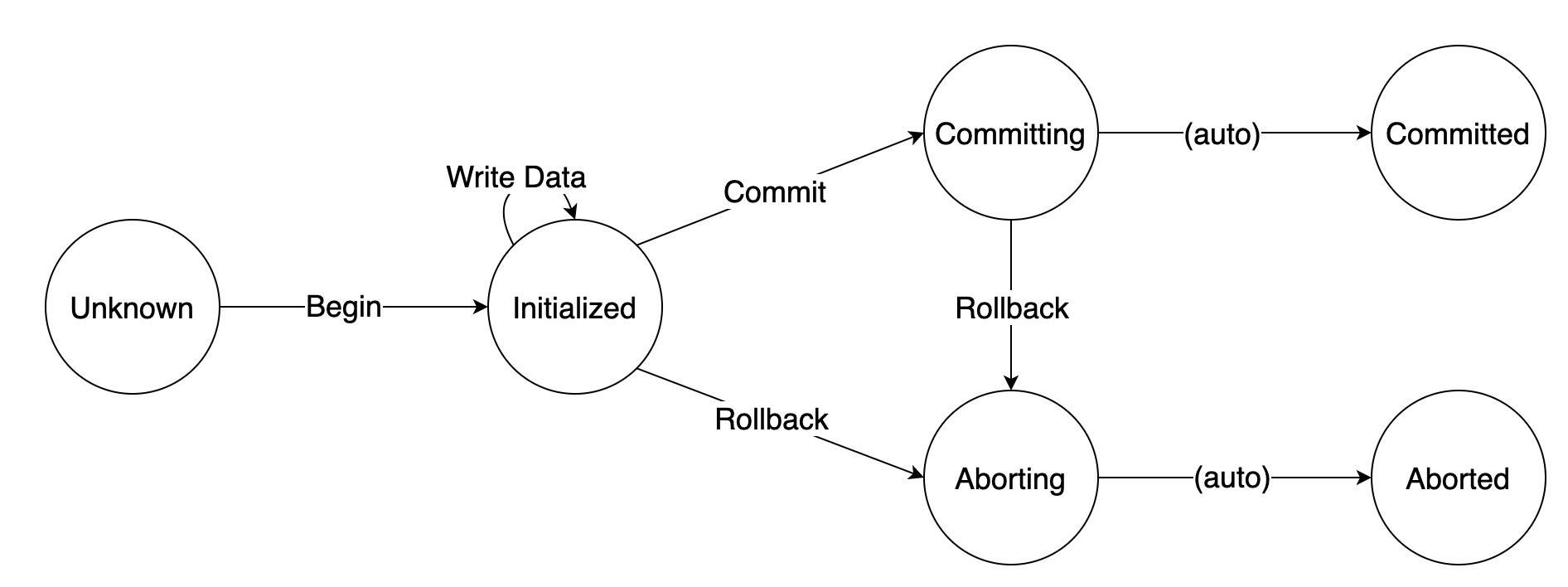
图-4 ClickHouse Server支持事务的状态机
图中所有操作均是幂等的。其中,Committing 到 Committed 和 Aborting 到 Aborted 是不需要执行任何操作的,在开始执行 Commit 或 Rollback 时,事务的状态即转成 Committing 或 Aborting;在执行完 Commit 或 Rollback 之后,事务的状态会被设置成 Committed 或 Aborted。
事务处理
Client 通过 HTTP Restful API 访问 ClickHouse Server,Client 与 ClickHouse Server 间一次完整事务的交互过程如图-5所示:
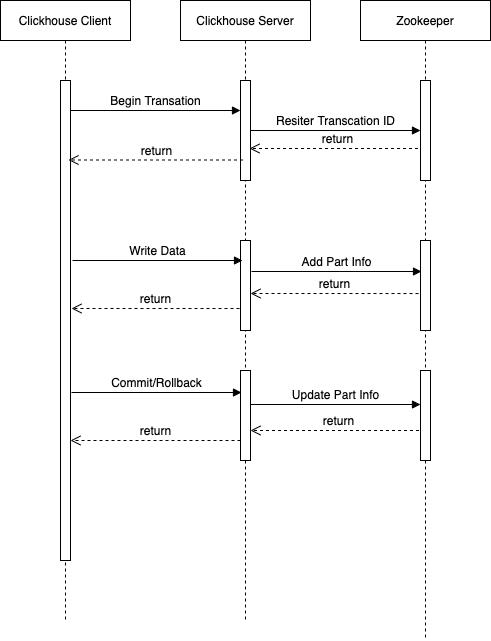
图-5 Clickhouse事务处理的时序图
正常流程:
- Client 向 ClickHouse 集群任意一个 ClickHouse Server 发送 Begin Transaction 请求,并携带由 Client 生成的全局唯一的 Transaction ID。ClickHouse Server 收到 Begin Transaction 请求时,会向 Zookeeper 注册该Transaction ID(包括创建 Transaction ID 及子 Znode 节点),并初始化该 Transaction 的状态为 Initialized。
- Client 接收到 Begin Transaction 成功响应时,可以开始写入数据。当 ClickHouse Server 收到来自 Client 发送的数据时,会生成临时 data part,但不会将其转为正式 data part,ClickHouse Server 会将写入的临时 data part 信息,以 JSON 的形式,记录到 Zookeeper 上该 Transaction 的信息中。
- Client 完成数据的写入后,会向 ClickHouse Server 发送 Commit Transaction 请求。ClickHouse Server 在收到 Commit Transaction 请求后,根据 ZooKeeper 上对应的Transaction的 data part 信息,将 ClickHouse Server 本地临时 data part 数据转为正式的 data part 数据,并更新Transaction 状态为Committed。Rollback 的过程与 Commit 类似。
异常处理:
- 如果创建 Transaction ID 过程中发现 Zookeeper 中已经存在相同 Transaction ID,根据 Zookeeper 中记录的 Transaction 状态进行处理:如果状态是 Unknown 则继续进行处理;如果状态是 Initialized则直接返回;否则会抛异常。
- 目前实现的事务还不支持分布式事务,只支持单机事务,所以 Client 只能往记录该 Transaction ID 的 ClickHouse Server 节点写数据,如果 ClickHouse Server 接收到到非该节点事务的数据,ClickHouse Server 会直接返回错误信息。
- 与写入数据不同,如果 Commit 阶段 Client 向未记录该 Transaction ID 的 ClickHouse Server 发送了 Commit Transaction 请求,ClickHouse Server 不会返回错误信息,而是返回记录该 Transaction ID 的 ClickHouse Server 地址给 Client,让 Client 端重定向到正确的 ClickHouse Server。Rollback 的过程与 Commit 类似。
ClickHouse-JDBC
根据 XA 规范,完整的分布式事务机制需要实现大量的标准接口(参考附录2)。在本设计中,实际上只需要实现少量关键接口,因此,采用了基于组合的适配器模式,向 Flink 提供基于标准 XA 接口的 XAResource 实现,同时对 ClickHouse Server 屏蔽了不需要支持的接口。
对于 XADataSource 的实现,采用了基于继承的适配器模式,并针对 Exactly-Once 的特性,修改了部分默认配置,如发送失败的重试次数等参数。
另外,在生产环境中,通常不会通过分布式表,而是通过 SLB 进行数据写入时的负载均衡。在 Exactly-Once 场景中,Flink 侧的 Task 需要保持针对某一 ClickHouse Server 节点的连接,因此不能使用 SLB 的方式进行负载均衡。针对这一问题,我们借鉴了 BalanceClickHouseDataSource 的思路,通过在 URL 中配置多个IP,并在 properties 配置中将 write_mode 设置为 Random ,可以使 XADataSource 在保障 Exactly-Once 的同时,具有负载均衡的能力。
Flink-Connector-ClickHouse
Flink 作为一个流式数据处理引擎,支持向多种数据接收端写入的能力,每种接收端都需要实现特定的Connector。针对 Exactly-Once,ClickHouse Connector 增加了对于 XADataSource 的选项配置,根据客户端的配置提供 Exactly-Once 功能。
四、测试结果
ClickHouse 事务性能测试
- 写入 ClickHouse 单批次数据量和总批次相同,Client端并发写线程不同性能比较。由图-6可以看出,无论 ClickHouse 是否开启事务, ClickHouse 的吞吐量都与 Client 端并发写的线程数成正比。开启事务时,ClickHouse 中临时 data part 不会立刻被转为正式 data part,所以在事务完成前大量临时 data part 不会参与 ClickHouse merge 过程,降低磁盘IO对写性能的影响,所以开启事务写性能较未开启事务写性能更好;但事务内包含的批次变多,临时 data part 在磁盘上的增多导致了合并时 CPU 的压力增大,从而影响了写入的性能,开启事务的写性能也会降低。
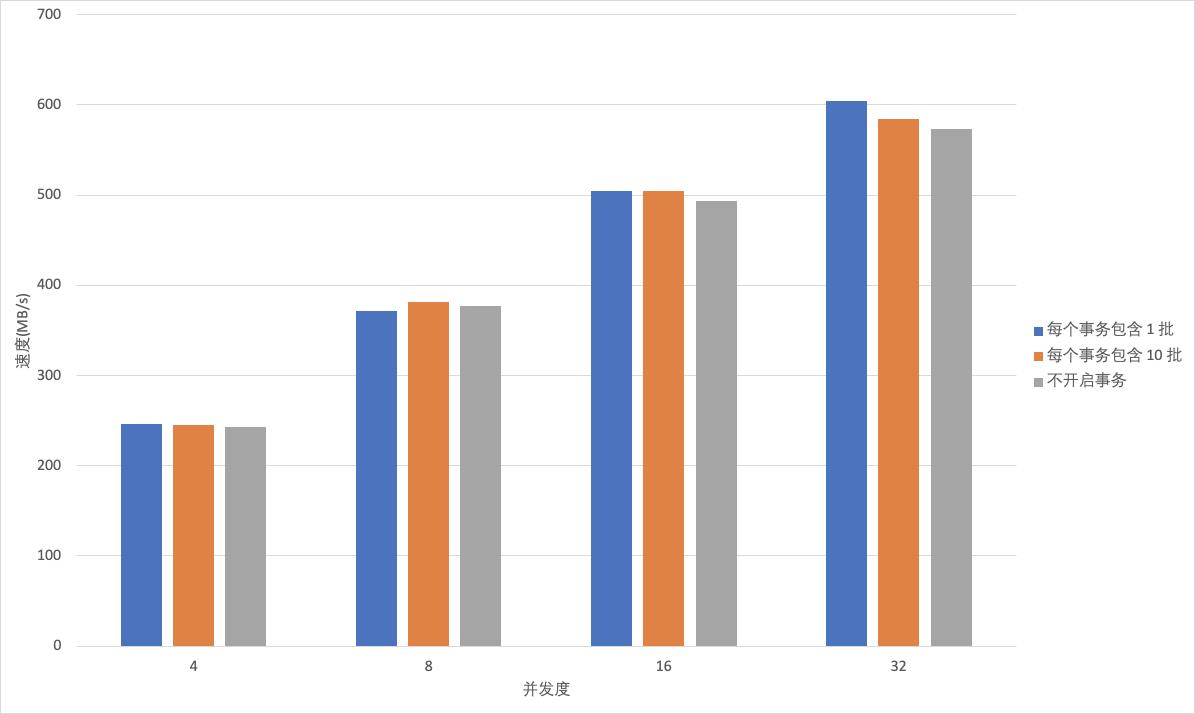
图-6 ClickHouse写入性能压测(一)
- 写入 ClickHouse 总批次 和 Client 端并发写线程相同,单批次写入 ClickHouse 数据量不同性能比较。
由图-7可以看出,无论ClickHouse 是否开启事务, ClickHouse 的吞吐量都与单批次数据量大小成正比。开启事务时,每批次数据越小,ClickHouse 的吞吐量受事务是否开启的影响就越大,这是因为每批次写入的时间在事务处理的占比较小,事务会对此产生一定的影响,因此,一次事务包含的批次数量越多,越能够减少事务对写入性能的影响;当事务包含批次的增大,事务处理时间在写入中的占比逐渐降低,ClickHouse merge 产生的影响越来越大,从而影响了写入的性能,开启事务较不开启事务写性能更好。
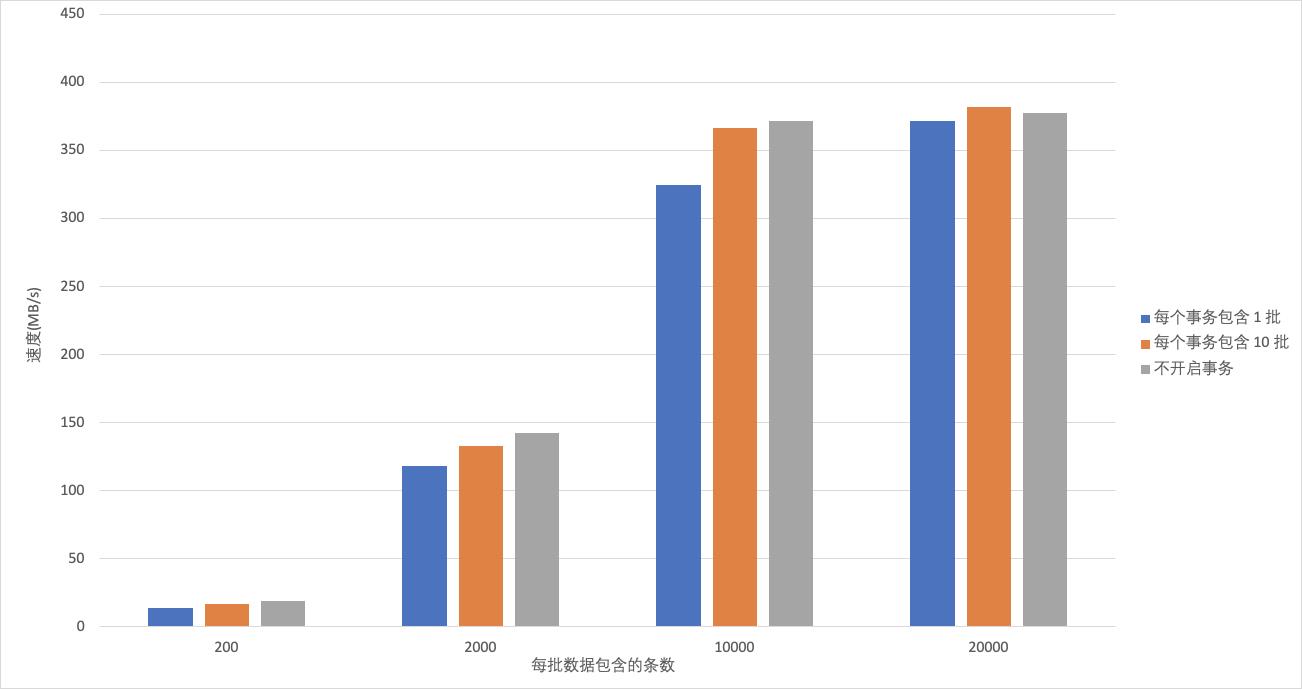
图-7 ClickHouse写入性能压测(二)
- 总体来说,开启事务对写入性能几乎没有影响,这个结论是符合我们预期的。
Flink 写入 ClickHouse 性能比较
- 对于相同数据量和不同 checkpoint 周期,Flink 写入 ClickHouse 总耗时如图-8所示。可以看出,checkpoint 周期对于不开启 Exactly-Once 的任务耗时没有影响。对于开启 Exactly-Once 的任务,在5s 到60s的范围内,耗时呈现一个先降低后增长的趋势。原因是在 checkpoint 周期较短时,开启 Exactly-Once 的 Operator 与 Clickhouse 之间有关事务的交互过于频繁;在 checkpoint 周期较长时,开启 Exactly-Once 的 Operator 需要等待 checkpoint 周期结束才能提交最后一次事务,使数据可见。在本测试中,checkpoint周期数据仅作为一个参考,生产环境中,需要根据机器规格和数据写入速度进行调整。
- 总体来说,Flink写入Clickhouse时开启 Exactly-Once 特性,性能会稍有影响,这个结论是符合我们预期的。
图-8 Flink 写入 ClickHouse 测试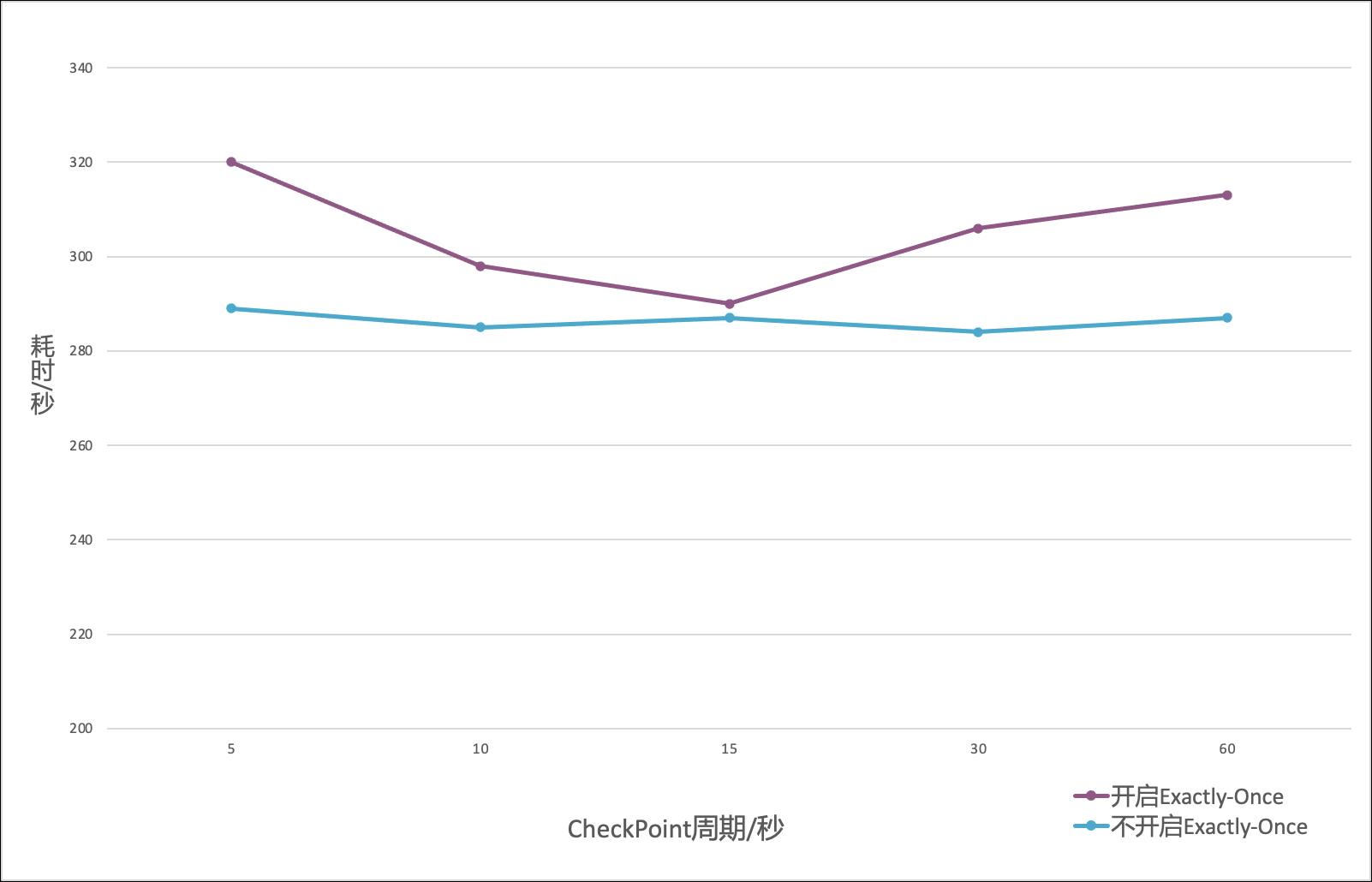
五、未来规划
该版本 EMR ClickHouse 实现的事务还不是很完善,只支持单机事务,不支持分布式事务。分布式系统一般都是通过 Meta Server 来做统一元数据管理来支持分布式事务机制。当前我们也正在规划设计 ClickHouse MetaServer 来支持分布式事务,同时可以移除 ClickHouse 对 ZooKeeper 的依赖。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于基于 EMR OLAP 的开源实时数仓解决方案之 ClickHouse 事务实现的主要内容,如果未能解决你的问题,请参考以下文章