AliExpress基于Flink的广告实时数仓建设
Posted Flink实战剖析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AliExpress基于Flink的广告实时数仓建设相关的知识,希望对你有一定的参考价值。
建设背景
广告是目前互联网流量变现的一种重要手段,广告投放的优化很大程度上依赖于广告效果数据,依托于广告曝光、点击、消耗、订单等指标调整广告投放策略,以达到最优投放效果。前期主要提供T+1效果数据,投放策略往往需要第二天才能做出调整,不能及时做出投放优化,特别在一些大促场景,实时优化显得尤为重要,需要及时调整例如人群、地域、出价等策略,以此为背景建设实时数据链路。
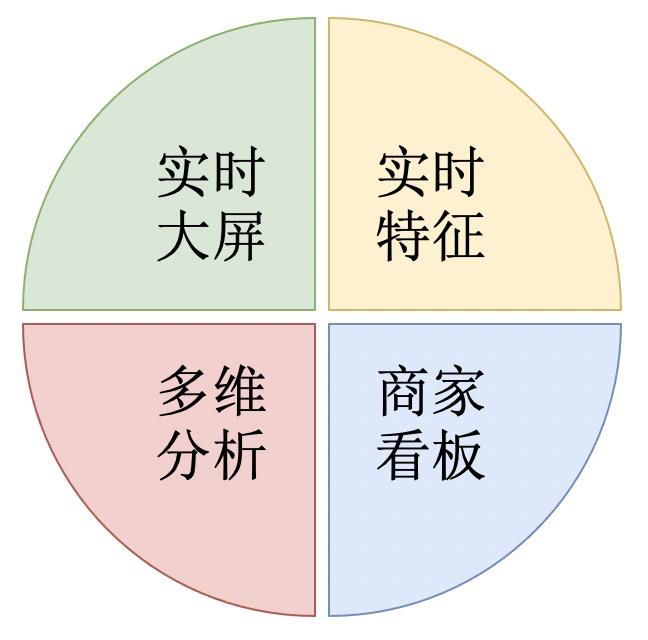
目前实时数据的场景主要有以下几种:
实时大屏:提供给运营、产品使用,展示核心的业务指标:曝光、点击、消耗等数据。
实时特征:提供给算法使用,统计用户维度的行为数据。
商家看板:提供给商家使用,展示商家的在不同维度的曝光、点击、消耗等数据。
多维分析:提供给运营、分析师使用,实时分析广告数据。
技术架构
依托新一代实时计算引擎Flink的兴起,在超高性能、数据一致性保障、SQL化编程方式等特点下推动了实时数仓的发展。
当前的整体技术架构图如下:
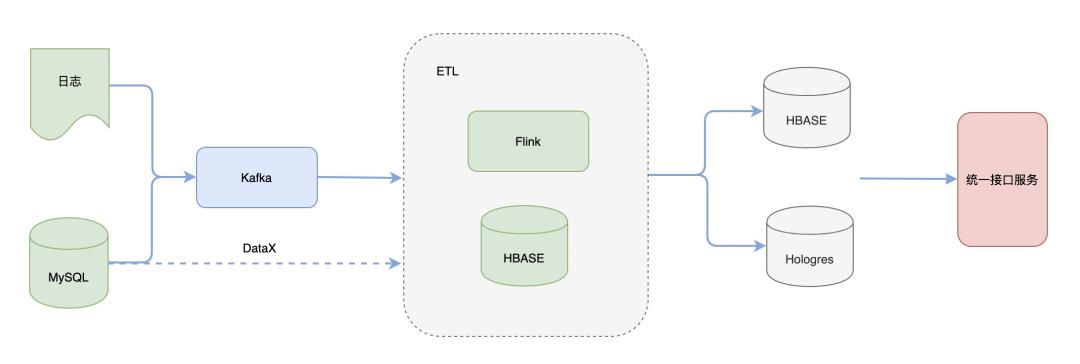
在数据加工侧,使用Flink作为计算引擎,HBASE作为维表存储数据库,Flink任务在处理的过程中会做一些数据解析、规范化、打宽、聚合等操作;
在数据服务侧,使用两种不同的存储引擎HBASE与Hologres,HBASE提供KV查询,应用于实时大屏、商家看板等固化查询场景, Hologres用于在线分析,应用于多维分析等场景,提供多维分析能力。二者由统一数据接口服务封装,对外提供查询。
数仓架构
数仓的分层搭建需要从复用、成本、质量、扩展性等方面去考虑,实时数仓的搭建,包括层次划分、命名、主题域划分、数据域划分与离线相差不大,目前划分层次如下:
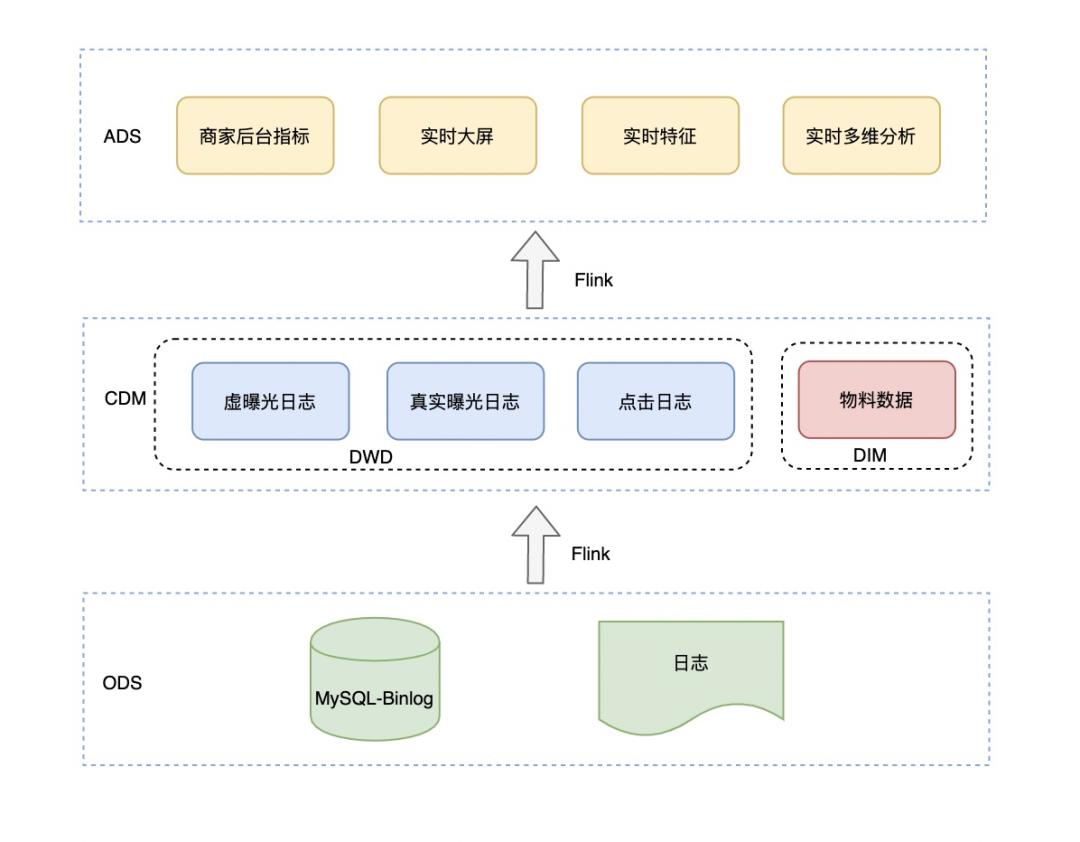
应用层:按照应用场景划分为实时大屏、商家后台实时指标、实时特征、实时多维分析,提供了不同维度的曝光、点击、消耗等数据。
层次更少:离线中会存在汇总层与集市层,但是对于实时来说层次越多延时就越大,另外问题排查的难度就越大;
实时OLAP
运营对于广告数据需求的多变性
对mysql中的数据需要某个时间点的分析结果指标
mysql中的数据是可变的,经常会执行一些update操作,例如广告预算数据,预算是可实时变更的,需要知道每小时整的预算额。使用Flink去处理这类问题成本比较高、并且也不可复用。
基于以上问题,提出了实时OLAP的架构。
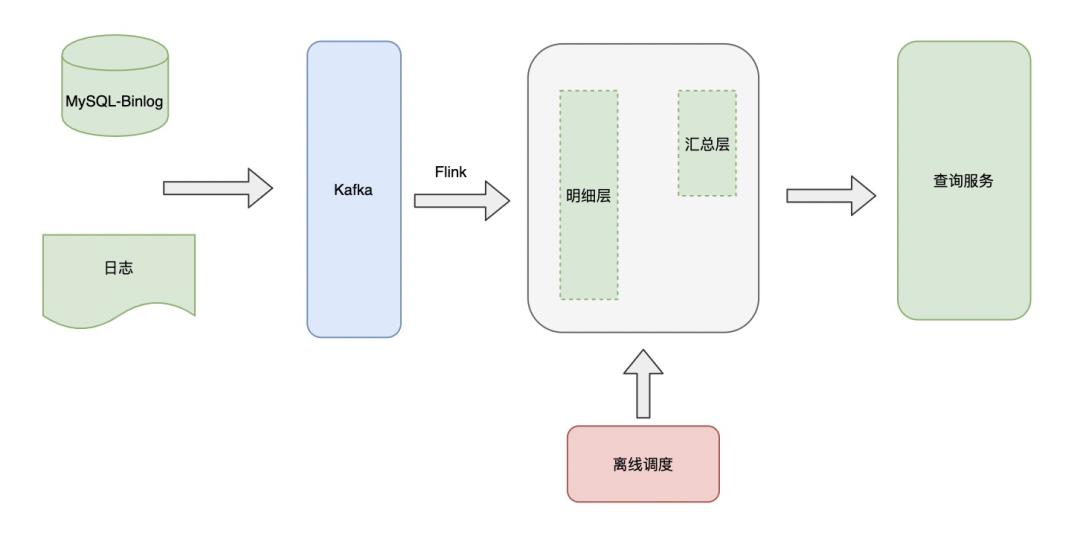
将明细数据通过Flink处理写入OLAP中,基于OLAP一方面完成在线数据查询,另外一方面通过离线调度处理OLAP中数据,进行一个简单的分层处理,最终提供给上层查询服务使用。
实时保障
整个实时数据体系保障,可分为稳定性保障、数据质量保障两个方面。
未来规划
历史推荐
数仓指标一致性
Flink-CEP 规则动态更新
关于Event-Time 所带来的的问题
不得不掌握的三种BitMap


「回顾」基于Flink的严选实时数仓实践
分享嘉宾:杨雄 网易严选 资深研发工程师
内容来源:DataFun Talk《基于Flink的严选实时数仓实践》
出品社区:DataFun
今天分享的内容主要分为四个部分,首先会介绍下严选实时数仓的背景、产生的一些问题。然后是针对这些背景和问题对实时数仓的整体设计和具体的实施方案,接着会介绍下在实时数仓的数据质量方面的工作,最后讲一下实时数仓在严选中的应用场景。
1、背景
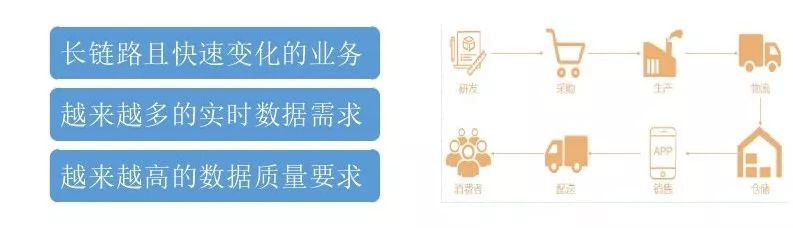
严选实时数仓项目是从17年下半年开始做的,背景总结为三个方面:
第一个是长链路且快速变化的业务,严选作为一个ODM电商,整个业务链度从商品采购、生产、仓库、到销售这个阶段可以在主站APP上购买或者分厂购买,然后通过商户配送到达消费者。链度是非常长的,这也决定数据的数据域非常广;严选作为一个成长的电商,会有很多新的业务出现。
第二个是越来越多的实时数据需求,目前需要更多的实时数据来做业务决策,需要依据销售情况做一个资源位的调整;同时有些活动也需要实时数据来增强与用户的互动。如果数据有实时和离线两种方案,优先考虑实时的,如果实时实现不了再考虑离线的方式。
第三个就是越来越高的数据质量要求,因为数据会直接影响业务决策,影响线上运营活动效果,因此对数据质量的要求越来越高。
针对这样的项目背景提出了三个设计目标,第一个是灵活可扩展,第二个是开发效率高,第三个是数据质量要求高。
2、整体设计和实现
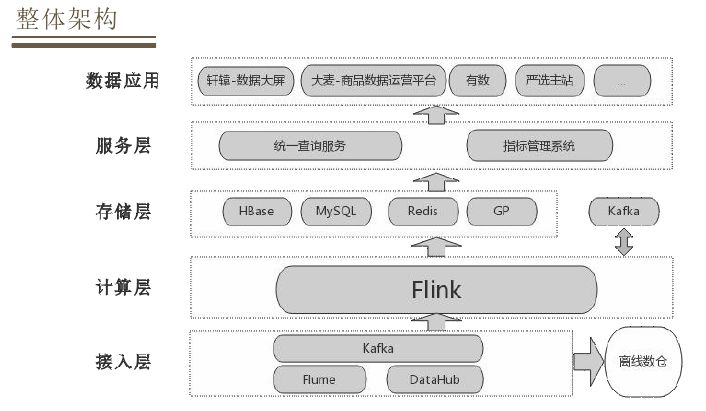
基于这样的设计目标,介绍一下整体的设计和实现方案:
实时数仓整体框架依据数据的流向分为不同的层次,接入层会依据各种数据接入工具收集各个业务系统的数据,如买点的业务数据或者业务后台的并购放到消息队列里面。消息队列的数据既是离线数仓的原始数据,也是实时计算的原始数据,这样可以保证实时和离线的原始数据是统一的。有了源数据,在计算层经过FLink+实时计算引擎做一些加工处理,然后落地到存储层中不同存储介质当中。不同的存储介质是依据不同的应用场景来选择。框架中还有FLink和Kafka的交互,在数据上进行一个分层设计,计算引擎从Kafka中捞取数据做一些加工然后放回Kafka。在存储层加工好的数据会通过服务层的两个服务:统一查询、指标管理,统一查询是通过业务方调取数据接口的一个服务,指标管理是对数据指标的定义和管理工作。通过服务层应用到不同的数据应用,数据应用可能是我们的正式产品或者直接的业务系统。后面会从数据的分层设计和具体的实现两个方面介绍。
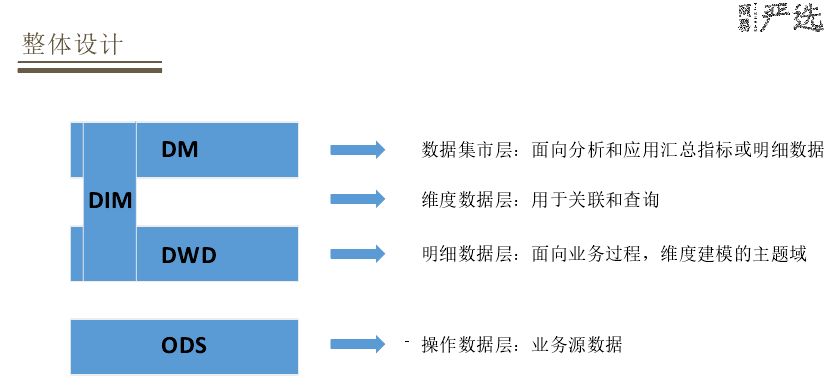
上面是对数据的整体设计,主要参考了离线数仓的设计方案,也参考了业界同行的一些做法。将数据分为四个层次:
首先是ODS层,即操作数据层,通过数据采集工具收集各个业务源数据;DWD层,明细数据层是按主题域来划分,通过维度建模方式来组织各个业务过程的明细数据。中间会有一个DIM层,维度数据层主要做一些查询和关联的操作。最上层是DM层,通过DWD层数据做一些指标加工,主要面向一些分析和应用汇总的指标或者是做多维分析的明细数据。
举例说明一下数据设计流向过程,假如要对严选主类目上当天销售和流量的统计,统计每个类目的销售量和流量从ODS层来源两部分,一部分来自访问,这是来源于埋点数据,这种数据通常比较规范,通过一些简单加工,在DWD层形成一张商品访问明细表;交易数据来自交易明细表,在ODS层来源于订单表和订单购物车表。将两个表汇聚在DWD层形成一个交易域的交易明细表,因为统计需要统计到类目维度,所以从DWD层向DM加工需要从商品维度表做一个关联,这样就可以在DM层做一些汇总统计,就可以形成DM所需要的指标数据。这里的数据分为两类,一种是实时的,一种是准实时;如果维度比较复杂,如准实时弹幕做一些配置来做到同步,如果有一些关联关系比较简单的就做成实时维表。这样的好处是能实时统计,能比较直观观察。
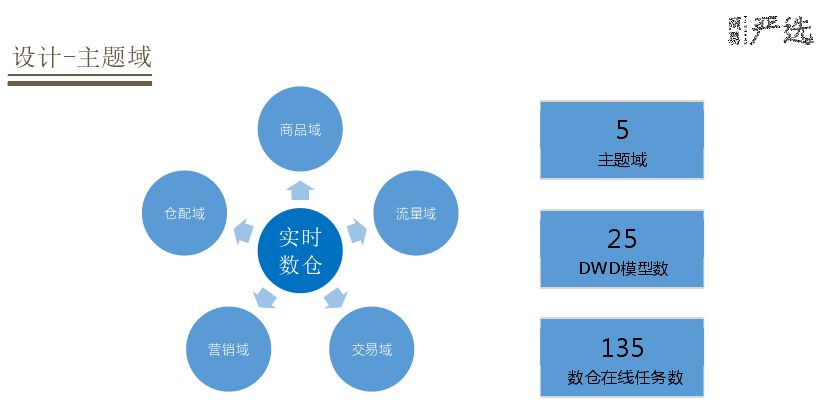
实时数仓设计分为5个主题域,分别是商品、流量、交易、营销、仓配。在这五个主题域下沉淀了25个模型,整个实时数仓在线任务数达到135。基于这样的设计方案能整体实现设计目标。

首先通过主体域的模型复用能够提高开发效率,最常用的就是交易域的实时数据。交易域的交易明细模型能够产生多个集市层模型,交易明细的字段清洗比较规范,一般两天就能开发一个模型,如果模型简单一天就能搞定。第二个就是比较灵活,在DWD层封装一些业务逻辑,快速应对一些业务调整。举例说明下,严选上线一个众筹业务,先前对交易定义都是以支付来算,但是众筹交易和支付相隔时间较长,对于离线只需要活动结束再进行统计,但是实时只关注于当天数据,这个时候统计就没有意义。因此需要将众筹数据剔除,实现时只需要在交易明细里面进行过滤,这样集市层所有指标数据都统一更改掉。第三个就是统一,数据都是按照业务域划分,管理和维护都比较方便,对于开发资源分配也比较便利。
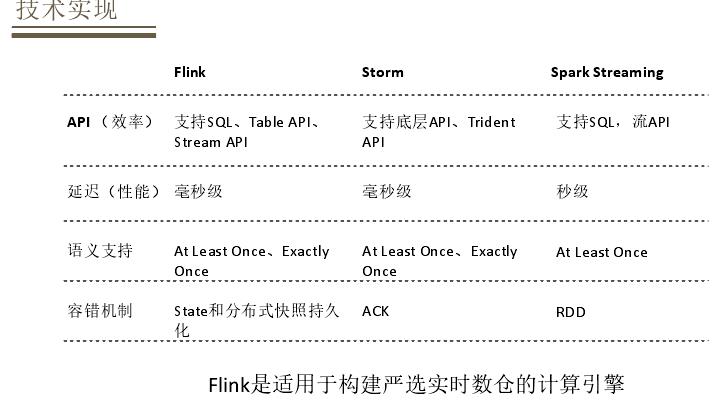
然后介绍下技术实现方面的考量,主要分为计算和存储。对于计算方面,有很多实时计算引擎,有Flink、Storm、Spark Streaming,Flink相对于Storm的优势就是支持SQL,相对于Spark Streaming又有一个相对好的性能表现。同时Flink在支持好的应用和性能方面还有比较好的语义支持和比较好的容错机制,因此构建实时数仓Flink是一个比较好的实时计算引擎选择。
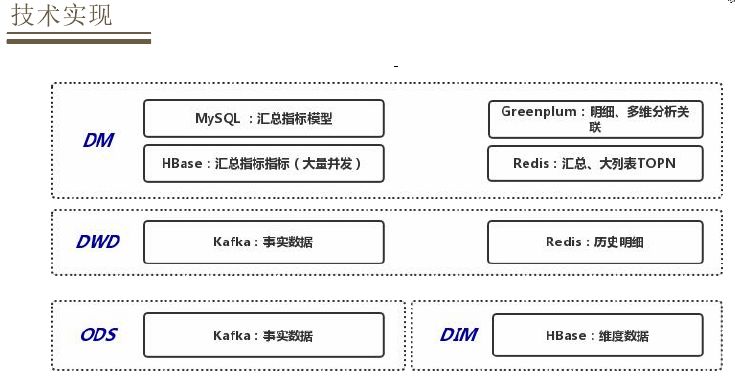
对于存储层会依据不同的数据层的特点选择不同的存储介质,ODS层和DWD层都是存储的一些实时数据,选择的是Kafka进行存储,在DWD层会关联一些历史明细数据,会将其放到Redis里面。在DIM层主要做一些高并发维度的查询关联,一般将其存放在HBase里面,对于DIM层比价复杂,需要综合考虑对于数据落地的要求以及具体的查询引擎来选择不同的存储方式。对于常见的指标汇总模型直接放在MySQL里面,维度比较多的、写入更新比较大的模型会放在HBase里面,还有明细数据需要做一些多维分析或者关联会将其存储在Greenplum里面,还有一种是维度比较多、需要做排序、查询要求比较高的,如活动期间用户的销售列表等大列表直接存储在Redis里面。
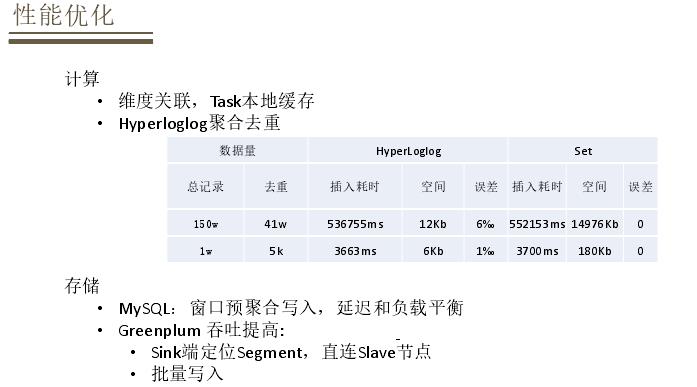
性能优化方面,在计算中采用很多维度关联,如果每一次维度关联都从HBase中调用性能受限,因此将维度数据在本地task进行一次缓存。聚合去重用一些精度去重算法,如Hyperloglog,既能保证在一个可接受的数据统计误差,又能比较好的优化存储。存储方面主要针对MySQL和Greenplum两种场景,在大数据场景下MySQL写入压力比较高,在写入之前做一个窗口预聚合,实现延迟和负载均衡,较少MySQL的写入压力。对于明细数据写入Greenplum,明细数据不适合高并发写入,因此会对要写入的表依据主键做哈希,定位要录入的segment,直接到Slave节点,批量写入数据,这样也能有效提高写入的存储量。
3、数据质量
数据质量分为两个方面来介绍,数据一致性和数据监控。
数据一致性主要针对实时与离线的数据一致性,同一个指标实时与离线都会产出。这两者一致性分为四个方面:
第一,建模方法与分层基本统一,建模基于维度建模,分层也是业内通用方法;
第二,业务上主题域和模型设计同步;
第三,数据接入与源数据统一;
最后,数据产出方面,指标定义和接口都是统一输出。
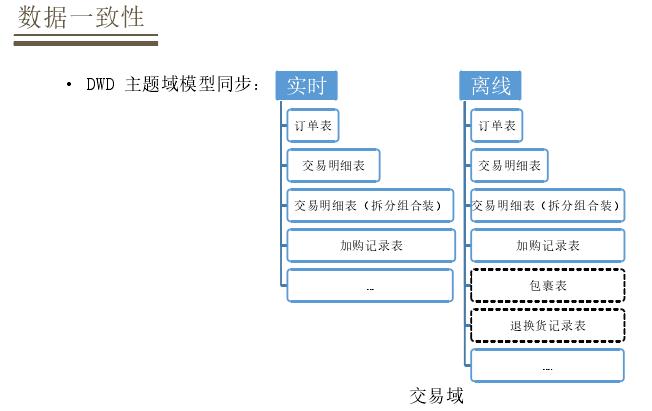
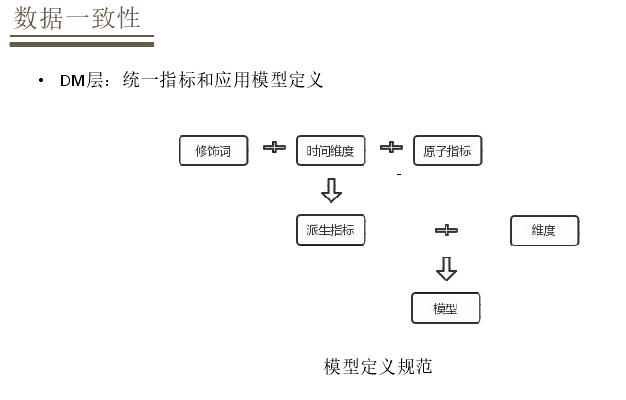
DWD层做到主题域与模型同步,按照业务过程来设计模型,这种方法对于实时和离线都是统一的。以交易域为例,在实时和离线都有订单、订单明细、组合装的交易明细,还有加购数据模型,由于开发成本原因实时模型大都是离线模型的子集。在DM层会统一定义指标和模型定义的方法,规范对于实时和离线都是适用的,定义模型会指定相应的指标和维度,指标通常是派生指标,通过原子指标+时间维度+修饰词完成派生指标的定义,再经过定义维度形成模型。
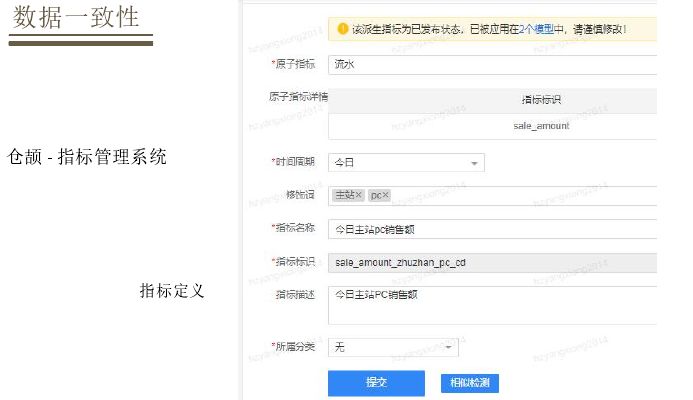
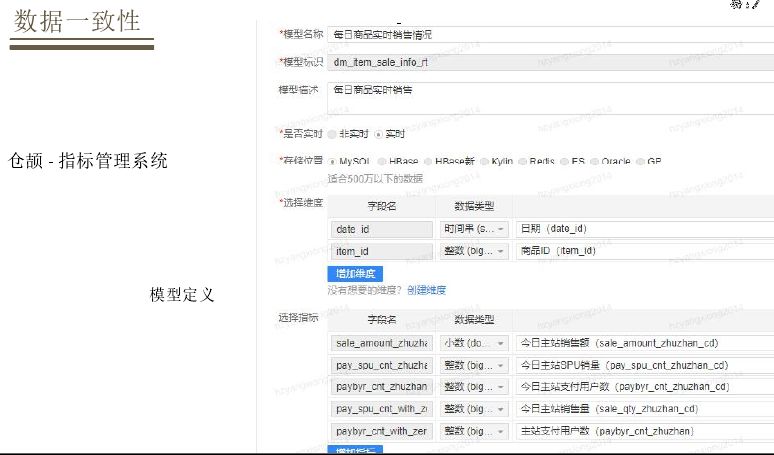
有了模型定义规范具体落地,如果要定义当日主站PC端销售,首先定义原子指标流水,时间维度今天,端是PC,然后定义派生指标,有了派生指标接着定义模型,定义为每天商品销售实时情况,做一个实时与离线的标记,选择其存储,维度选择一个是时间维度、一个是商品维度,然后加入先前的派生指标,最后生成模型。不同模型知识实时和离线标记,调用都是基于同一套接口来调用。

数据监控涉及两个方面,一个是数据平台监控。主要是对任务失败情况监控、异常日志监控、任务失败是RPS异常监控。还有任务本身运行正常,但是数据已经处理不过来,由于Flink机制,数据挤压到消费管理,通过对Kafka数据延迟监控能够及时发现问题。将问题通过监控发现,利用值班流程规范将问题及时发现和处理,及时通报和定期进行修复,来提高整个数据质量。

为了配合数据监控,正在做实时数据血缘。主要是梳理实时数仓中数据依赖关系,以及实时任务的依赖关系,从底层ODS到DIM再到DM,以及DM层被哪些模型用到,将整个链度串联起来。这样的好处是:
(1)数据/任务主动调整可以周知关联的下游;
(2)任务异常及时判断影响范围,通知产品和业务方;
(3)指标异常时借助血缘定位问题。
4、应用场景
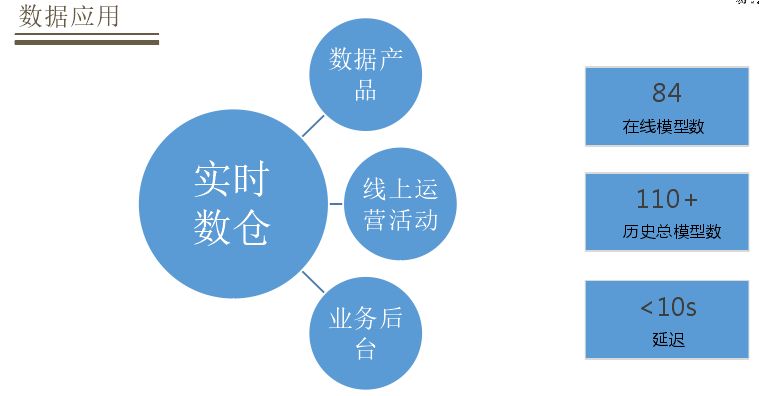
实时数仓应用场景分为三类:数据产品、线上运营活动、业务后台。在线模型数有84个,历史总模型数为110+,大部分数据延迟都在10s以内,对于数据大屏这种对延迟要求比较高数据延迟在毫秒级。


数据大屏是最常用的实时数据应用场景,有针对客服业务大屏,如大麦-商品数据运营平台、神相-流量分析平台、刑天-推广渠道管理系统。第二个是线上运营活动,如热销商品榜单、活动用户消费排行、资源位排序转化策略,业务后台仓配产能监控、物流时效监控、库存预警、商品变更通知。
5、展望
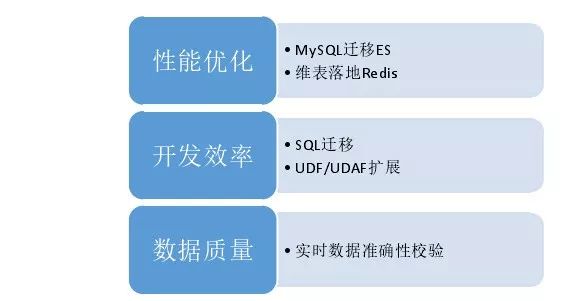
未来展望从三个方面:
第一,性能方面。模型用MySQL效率不高,后期迁移到ES上;维度表落地到Redis上进一步提高吞吐量。
第二,开发效率。开发是SQL和API两种并存,开发效率不高,后期往SQL迁移,由于SQL本身局限,进行UDF扩展。
作者介绍:
杨雄,网易严选数据技术与产品部资深研发工程师。浙江大学硕士毕业加入网易,曾参与邮箱大师、有钱、严选等多个产品的数据研发工作,在大数据开发和数据仓库都有一定经验,目前主要负责严选实时数仓构建和应用。
内推信息:
网易严选在招聘:高级/资深大数据开发,base杭州,有意者可点击"阅读原文"直接投递。
——END——
DataFun大数据交流群欢迎您的加入,感兴趣的小伙伴欢迎加管理员微信:
文章推荐:
社区介绍:
DataFun定位于最“实用”的数据科学社区,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过DataFun的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。DataFun的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun社区成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有超过一百五十位的业内专家参与分享,聚集了万余大数据、算法相关领域从业者。
以上是关于AliExpress基于Flink的广告实时数仓建设的主要内容,如果未能解决你的问题,请参考以下文章