Clickhouse MYSQL的生态的闭环
Posted AustinDatabases
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Clickhouse MYSQL的生态的闭环相关的知识,希望对你有一定的参考价值。

mysql 目前被攻击最多的就是他的OLAP的性能, 在OLTP中MYSQL 本身的性能是OK的,尤其高并发中符合MYSQL数据库的表设计和提取的方式,则数据的获取的速度是非常快的.
但其他数据库在中等数据量几千万,或者亿万级别的情况下,数据的OLAP的性能还是可以的,数据库自己就可以解决OLTP+OLAP(轻量级)的问题. 所以MYSQL本身去单打独斗必败, MYSQL 需要一个好基友,作为整体生态的闭环.
所以就的引出今天的"猪脚" CLICKHOUSE,简短的了解一下什么是clickhouse
ClickHouse是一个用于OLAP的数据分析引擎,由俄罗斯搜索巨头Yandex公司开源。
1、可支持PB级超大容量的数据库管理系统。
2、基于SQL语句, 使用成本低。
3、超亿级数据量分析的秒级响应,计算性能横向扩展。
4、海量数据即查即用。
5、提供数据的预聚合能力,进一步提升数据查询的效率。
6、列式存储, 数据压缩,降低磁盘IO和网络IO,提升计算性能,节约70%物理存储。
7、支持副本, 实现跨机房的数据容灾。
众所周知 clickhouse 数据库的存储是列式存储,列式存储的优点
针对查询,只需读取表的部分列。在列式数据库中可以只读取需要的数据。如,只需读取100列中的5列,列式存储将帮助减少20倍的I/O消耗。
数据是打包成批量读取的,压缩是容易的,同时数据按列分别存储这也更容易压缩,这进一步降低了I/O的体积。
由于I/O的降低,更多的数据将被系统缓存。
那么CLICKHOUSE 还有其他的优势吗? 让他作为MYSQL的整体生态中的OLAP的闭环.
1 CLICKHOUSE 是支持基于SQL 声明方式查询语言的,知识标准的ANSI SQL, 支持GROUP BY ,ORDER BY ,FROM , JOIN , IN 等以及子查询.
2 适合在线查询可以对数据没有任何预处理的情况下,以极低的延迟处理查询并将结果加载,展示
3 支持数据复制,支持异步的多主复制技术,在情况允许下,支持故障后的自动恢复
缺点也是有的:
没有完整的事务支持。
缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
MYSQL 和 CLICKHOUSE 对同样查询的时间的对比 ,可以看到差距巨大MYSQL不到6分钟 VS ClickHouse 0.145 second 数据量在3.5 billion


MYSQL 到CLICKHOUSE 的数据同步也是 MYSQL 整体生态的一个闭环.
clickhouse 本身支持
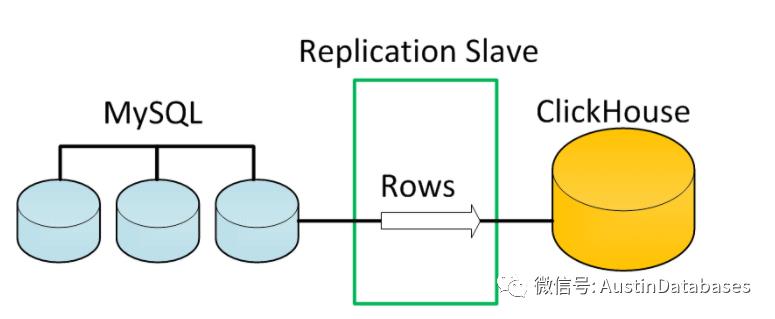
通过数据传输,将MYSQL 的数据传输到CLICKHOUSE 中,并且可以根据MYSQL的变化,将变化同步到 clickhouse
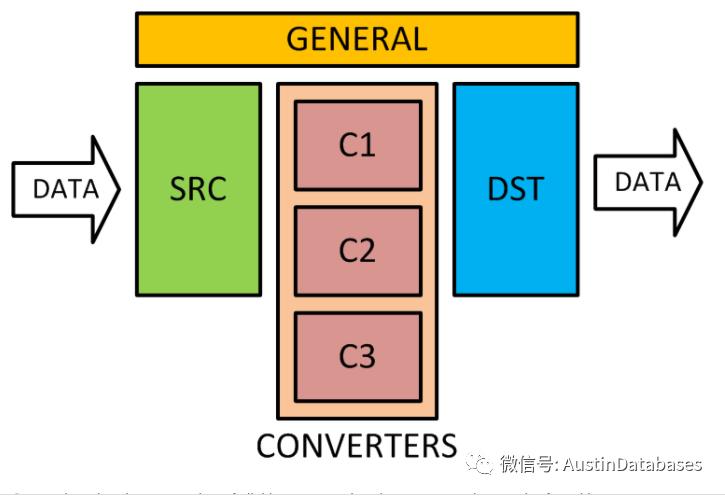
通过clickhouse中的工具可以对mysql 到 clickhouse 进行全量以及增量的数据复制
那么clickhouse可以直接成为MYSQL OLAP的工作者, 将MYSQL的短板进行FIX, 让MYSQL 本身从OLTP + OLAP 有一个完整方案.
以上是关于Clickhouse MYSQL的生态的闭环的主要内容,如果未能解决你的问题,请参考以下文章
基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系...
基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系...