2021 数学建模“华为杯”B题:空气质量预报二次建模 2 方案设计附实现代码
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021 数学建模“华为杯”B题:空气质量预报二次建模 2 方案设计附实现代码相关的知识,希望对你有一定的参考价值。

相关链接
【数学建模国赛】2021 B题:空气质量预报二次建模 1 赛后总结与分析
【2021 数学建模“华为杯”】B题:空气质量预报二次建模 2 方案设计附实现代码
【2021数学建模“华为杯”】B 题60页论文 PDF付费下载
1 赛题的详细分析(必看)
【数学建模国赛】2021 B题:空气质量预报二次建模 1 赛后总结与分析
2 方案的设计
2.1 问题一
Matlab 代码实现,见github
2.2 问题二
(1)数据预处理
缺失值的统计和异常值的统计,并用knn最邻近均值插值进行填充。算法步骤如下。也考虑过线性插值,但是线性插值,需要依靠左右相邻的元素来进行计算,但是数据存在大量的连续缺失值,就不适用了。具体代码实现见github 插值填充

python实现算法如下,完整实现,转到python 实现插值
def knn_mean(ts, n):
out = np.copy(ts)
for i, val in enumerate(ts):
if np.isnan(val):
n_by_2 = np.ceil(n/2)
lower = np.max([0, int(i-n_by_2)])
upper = np.min([len(ts)+1, int(i+n_by_2)])
ts_near = np.concatenate([ts[lower:i], ts[i:upper]])
out[i] = np.nanmean(ts_near)
return out
for indexs in data_1_actual_knn.columns:
if indexs =='time':
continue
data_1_actual_knn[indexs] = knn_mean(data_1_actual_knn[indexs].values,8)
for indexs in data_1_predict_knn.columns:
if indexs =='time':
continue
data_1_predict_knn[indexs] = knn_mean(data_1_predict_knn[indexs].values,8)
(2)特征的选择
在前面说过,分析过选择了每种污染物浓度的IAQI作为聚类算法的特征。为了再验证一遍,可以先计算法一下各个污染物浓度、各个气象条件与AQI关联度,选择关联度较高的作为聚类的特征。
(3)聚类算法
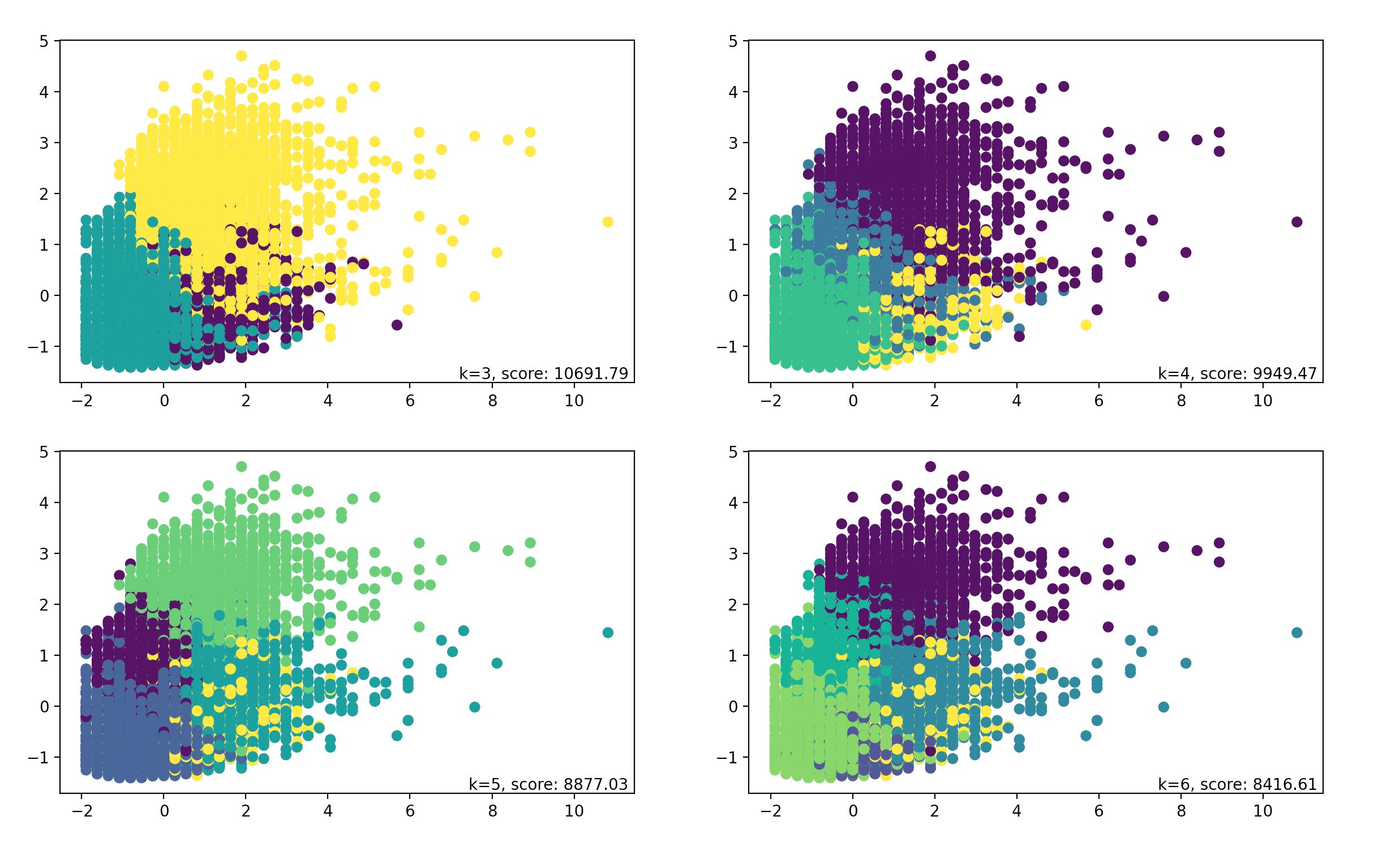
聚类需要初始化一个K值,K值的选择是一个超参数。根据查阅资料,中国的气象天气大致分为6类,那我们的K值就选择了3、4、5、6作为相互对比。评价聚类效果的标准采用Calinski-Harabas得分。下图中,得分越高代表聚类效果越佳。聚类算法就很多了,比如我都尝试过minibatchKmeans、Kmeans3D、Kmeans、DBSCAN、AgglomerativeClustering、Birch。但效果都不如Kmeans和minibatchKmeans。最终就选择了这两种算法,聚类的效果差不多,K值最终选择是3。具体实现,查看代码github 聚类算法实现
from sklearn.cluster import KMeans,MiniBatchKMeans,DBSCAN,AgglomerativeClustering,Birch
import matplotlib.pyplot as plt
def P_Kmeans(X,k,p=False):
if p==True:
for index, kk in enumerate((3,4,5,6)):
plt.subplot(2,2,index+1)
y_pred = KMeans(n_clusters=kk).fit_predict(X)
score= metrics.calinski_harabasz_score(X, y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.text(.99, .01, ('k=%d, score: %.2f' % (kk,score)),
transform=plt.gca().transAxes, size=10,
horizontalalignment='right')
plt.show()
(3)气象特征分析
对于题目中文的分析最终分类的气象条件特征,其实就是对分类的每一种类别进行污染物浓度、温度、湿度、气压、风速、风向等特征分析。比如下图中,纵坐标是AQI,第一类的气象条件、第二类的气象条件、第三类的气象条件的AQI等级都不一样。每种气象条件对应的空气指数都不一样,第一类,指数最高,第三类,指数最低,这种气象条件带来的空气质量最好。

再比如如下图,气象类别与温度的关系,还是有细微的差别的,第一类的气温偏高,第二类的气温温差大,第三类的温差较小,温度居中。这些都是这些气象条件的特征,此外还有湿度、气压、风向、风速等其他特征,不在这一一陈述。

如果想问如何做出的上面两个这种聚类结果与特征的关系图,其实就是取每一种聚类的结果的下标,用不同的颜色绘制散点。MATLAB实现
2.3 问题三
LSTM 多变量时间序列实现空气质量预测-python代码实现
(1)模型的选择
已经明确了这是一个多变量的时间序列预测问题。为什么是多变量,是因为需要同时要将多个特征作为模型的输入,而不是想简单的单个特征时间序列的预测,就只有一个输入和输出。比如销售量的预测,根据历年销售量就可以预测出,下个时间的销售量。在此题中,需要考虑6种污染物浓度、15种气象条件。这些特征之间并不是相互独立的,而是相关联的,只能一起输入模型中。时间序列的预测模型有很多,比如传统时序建模方法的ARMA/ARIMA等线性模型、利用时间特征做线性回归模型、时间序列分解模型、xgboost/LSTM模型/时间卷积神经网络模型等。
(2)LSTM模型的设计
题目要求,是用一个通用的数学模型是来分别预报A、B、C点的数据。此处只分析检测点A,其他两个点,同样的原理。数据预测的目的未来三天7月13至7月15号的数据。提供的数据有三个,A点每小时预报数据(25W条,最后采集时间是7月12号,有21列属性)、A点每个小时实测数据(19W条,最后采集时间12号,有11列属性)、A点每天实测数据(819条,最后采集时间是7月12号,有6列属性)。此处应该建立三个LSTM神经网络,每个网络输入是前三天的数据,输出是后三天的数据,输入大小时每个数据中所有属性列,输出大小和输入大小相同。比如“A点每小时的实测数据”中有11列,分别是SO2、NO2、PM10、PM2.5、O3、CO、温度、湿度、气压、风速、风向。则对应网络模型的输入输出大小是11。而其他两个文件的属性列分别是21和6,对应的模型输入输出大小也应该是21和6。在LSTM中需要设定预测的步长和预测的时间长短。对于所有数据,我选择的时间步长是6天,预测的天数是3,意思是用前3天数据预测后3天的数据,如果设定为6和2 的话,就是用前4天的数据预测后2天的数据。注意,有两个数据的采集单位是小时,那时间步长和预测天数相应是144小时和72小时。

(3)模型的训练和预测
监测点A就需要用三个数据训练模型。每小时的数据,模型输出是72小时的72条数据,需要合并成三天3条的数据,其中合并过程是除了O3外,全是取算术平均,而O3用8小时滑动平均合并。三个模型的输出再取平均,得到最终的三天预报数据。A点的每小时预报数据,拟合效果如下。三个检测点,总共需要训练9个模型。

(4)模型检验与实现
时间序列 模型检验主要由RMSE、MAE、MAPE、R、IA。相应是计算方法如下

2.4 问题四
略。。
以上是关于2021 数学建模“华为杯”B题:空气质量预报二次建模 2 方案设计附实现代码的主要内容,如果未能解决你的问题,请参考以下文章
2021 数学建模“华为杯”B题:空气质量预报二次建模 2 方案设计附实现代码
2021 数学建模国赛B题:空气质量预报二次建模 1 赛后总结与分析
2021 数学建模国赛B题:空气质量预报二次建模 1 赛后总结与分析