FlinkFlink 反压机制 导致checkpoint 失败
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkFlink 反压机制 导致checkpoint 失败相关的知识,希望对你有一定的参考价值。

1.概述
问题描述:检查点刚开始是可以的做checkpoint的,后期越来越不能够做checkpoint的情况总结
2.反压问题
2.1 什么是反压(如下图1所示)?
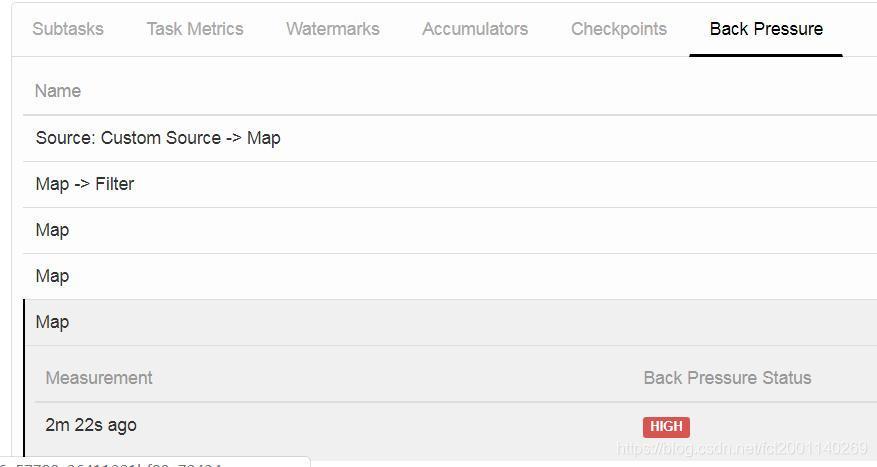
图2-1 部分算子反压表现(web ui)
2.2.flink中反压机制是干什么的?
flink中的反压机制是flink中由于个别算子接收receive数据的速度远大于处理完成数据的速度,数据在算子接收之前的数据积压(在buffer缓冲区),过多的数据积压时反压导致上游的算子接收减慢,最终导致flink整体接收数据短暂停止(如图2)【来自source的源发送数据停止】
反压机制本质是对类storm等异步处理算子之间处理快慢不同步的优化,是一种保护机制,防止算子速度不匹配大致大量数据积压在算子之间的调度器队列中(或者是缓冲区队列)中,最终导致OOM问题;

2.3 3.反压机制导致的问题
但是这样的机制也会导致另外一个问题,就是在做checkpoint的时候,刚开始可以做checkpoint,但是一段时间 之后就会checkpoint失败;这是应为当从源头发出的barrier标记通知各个算子做checkpoint时候,数据积压导致在规定时间内(checkpoint超时失败)。【如图3】
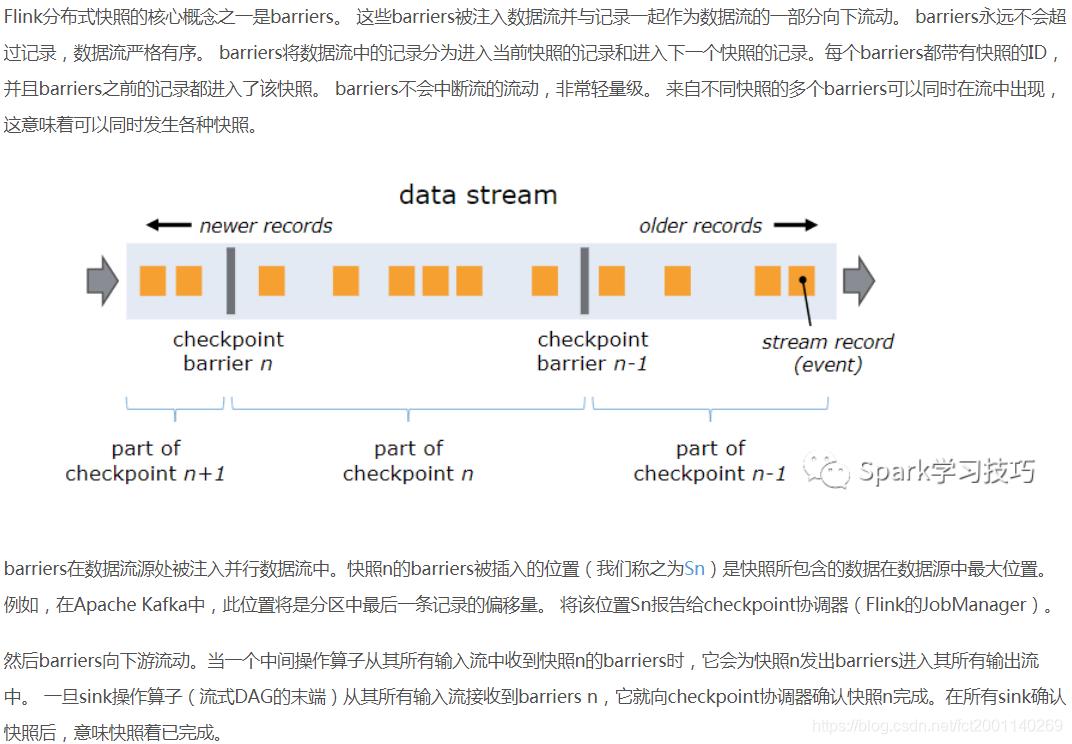
图3 盗用网上的一张图对barrier做checkpoint的机制描述
(ref: https://blog.csdn.net/rlnLo2pNEfx9c/article/details/81517928)
3.案例分析
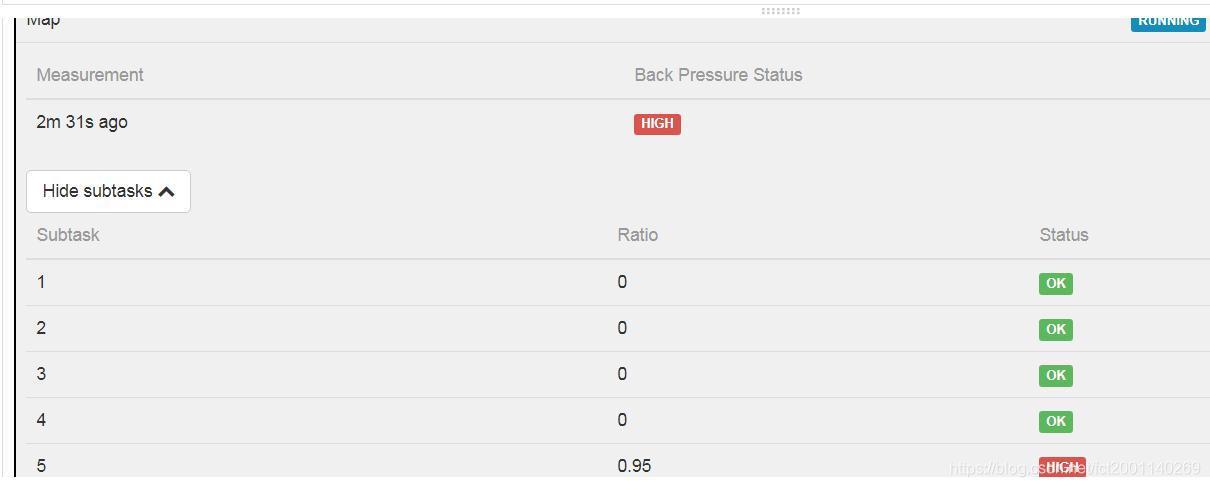
图4 部分算子反压表现(web ui)
如图4,可以看到当前算子的部分task(对应的算子,或者一线程)运行时反压很高,“Ratio”接近于1了,这是由于下一个算子处理速度过慢导致。
面对这种问题,我们首要是检查我们的应用中有没有特别耗时的操作,尤其是各种io操作等(如网络、磁盘、数据库等);
其次查看我们的内存和cpu负责情况(如图5)
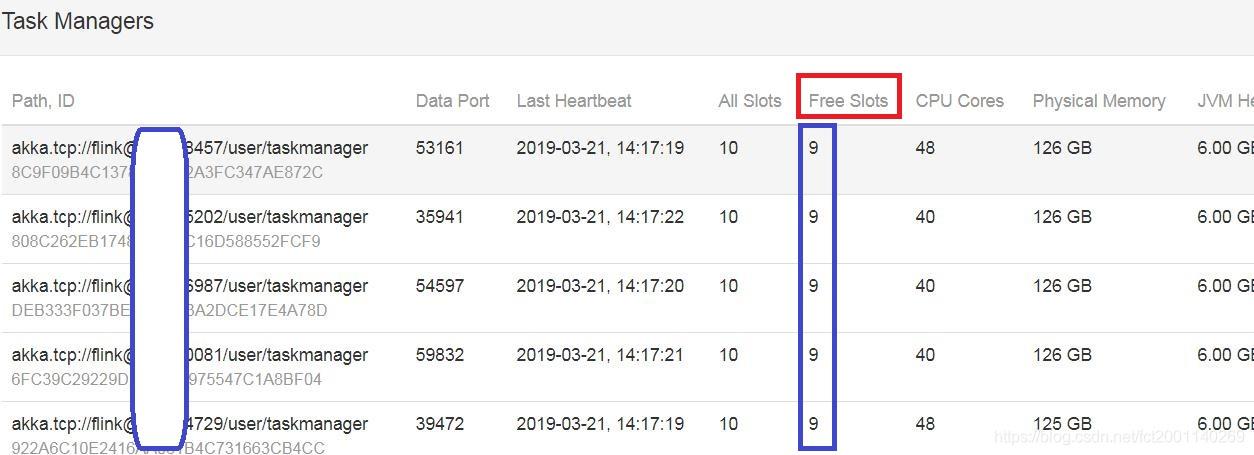
图5 当flink中并发数是5时候,其计算在集群中分布情况
最初的我的应用中由于在一个taskManager中启动了两个线程处理,导致两个线程solt分别持有各自的缓存(初始化加载2次,加载数据库中缓存中数据很多导致内存紧张,处理速度过慢)。
重新部署调整并发部署之后,运行正常!!
以上是关于FlinkFlink 反压机制 导致checkpoint 失败的主要内容,如果未能解决你的问题,请参考以下文章